
基于深度受限玻尔兹曼机的个性化推荐算法
2022-04-14 06:33邓育林
数据采集与处理 2022年2期
谢 妙,邓育林,吕 洁
(1.玉林师范学院计算机科学与工程学院,玉林 537000;2.南宁师范大学计算机与信息工程学院,南宁 530299)
引言
互联网数据日益增长,用户从网络中获取有效数据的难度提升。从用户端来讲,用户需要花费更多的时间来完成有价值数据的全网检索,资源获取的便捷度难以改进,因此主流方法是从服务端改进,通过服务端的记录、统计和计算来实现用户的个性化资源推荐,以解决用户从海量数据快速获取价值数据的问题。当前,个性化推荐的方法广泛用于各个行业[1-3]。电商行业将商品的个性化推荐应用到了极致,为顾客提供便利;在线社交网络根据用户的访问习惯为用户推荐兴趣相近的资源及好友;网络学习平台根据学员的学习习惯为其推荐学习资源,以解决学员挑选学习资源的盲目性。
当前,关于个性化推荐的研究较多。邵英玮等[4]对电商平台的商品推荐进行互补性研究,可根据用户购物习惯推荐未来可能需要的物品;Zhang 等[5]采用图像处理算法对旅游景点进行位置识别,利用旅游图片为用户进行个性化旅游推荐;Gu 等[6]详细阐述了知识图学习算法在不同推荐场景中的运用优势。这些研究都采用了合适的推荐方法用于不同领域的个性化推荐,但是主要的训练对象大多为自有数据集,可迁移性较差,且推荐准确度仍有一定提升空间。作为一种在实际应用中使用最多的神经网络模型,基于概率无向图的受限玻尔兹曼机(Restricted Boltzmann machine,RBM)已广泛应用于图像和语音处理等领域。近期,人们开始尝试将RBM 应用于个性化推荐领域,并已成为一个很有意义的研究方向。例如杨宇环等[7]提出了融合关联规则FP-Growth 和RBM 的混合推荐算法并用于图书推荐,解决了推荐效率不高的问题。
但是,目前大多数将RBM 模型应用于推荐领域的研究都是采用算法结合方式,且侧重于提升推荐效率,推荐准确性不高。为了进一步提升推荐的准确率,本文尝试构建多层RBM 网络,来生成深度RBM 个性化推荐模型。所提方法根据用户和资源的特征,以及用户对以往资源的评分,并结合RBM的多次正反向更新,来最终获得稳定的RBM 模型。常用公共数据集上的测试结果表明,通过合理提取输入用户和资源特征,并利用用户对资源的评分结果,多层RBM 网络可以有效提高系统推荐性能。
1 个性化推荐模型
1.1 深度受限玻尔兹曼机
如图1 所示,受限玻尔兹曼机为两层网络结构,主要由可见层(Visual layer,VL)与隐藏层(Hidden layer,HL)构成[8],W为可见层与隐藏层之间的连接权重。单个RBM 可以多个级联,组成深度RBM 网络结构,也就是说通过多层RBM 来构建深度RBM 模型。RBM 网络结构主要参数如表1 所示。
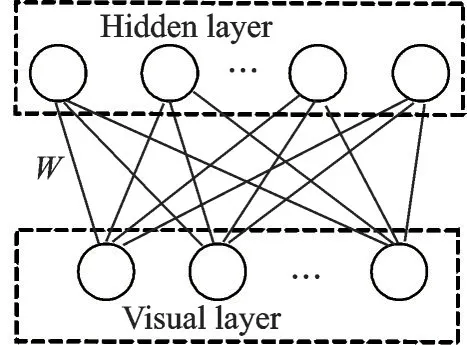
图1 RBM 结构Fig.1 RBM structure

表1 RBM 结构参数Table 1 Structural parameters of RBM

式中ε表示学习率。
1.2 用户-资源的RBM 建模

最后,求解用户u对资源i的评分为[12]

式中K表示评分的最大值。
1.3 个性化推荐流程
首先,输入用户和资源的特征变量并进行初始化。资源特征是指推荐系统目标优化时所涉及的主要属性,例如电影推荐系统中用户考虑的离家距离、大众评分数值和影院设施等。然后将特征变量输入RBM 网络,根据需要可构建多层RBM 网络,分别计算VL 和HL所有节点的激活概率,然后利用快速CD 法进行RBM 主要参数更新,最后通过多次训练,获得稳定RBM 推荐结构,主要流程如图2 所示。
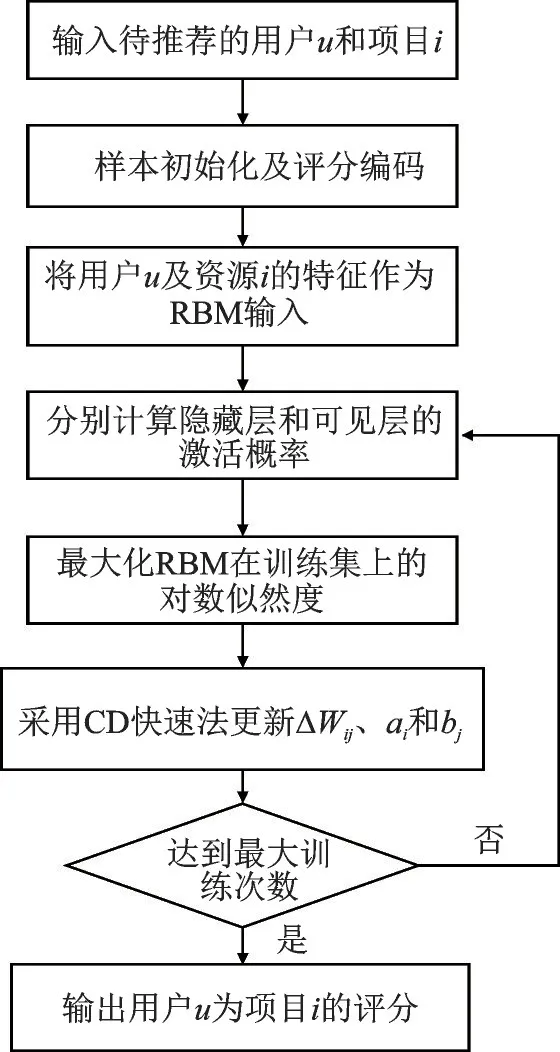
图2 基于RBM 的个性化推荐流程Fig.2 Personalized recommendation process based on RBM
2 实验仿真
为了验证深度RBM 在个性化推荐中的性能,进行实例仿真。本文采用的仿真数据样本均为公共数据集,具体如表2 所示。深度RBM 层数对RBM 规模及训练效果均有着重要影响,而层数最终会表现在HL 节点数目上,因此本文首先针对不同HL 节点数进行仿真,找出最适合于本文样本的HL 节点数;然后对参与训练的节点数,即不同样本稀疏度情况下进行推荐性能仿真;最后将常用算法和本文算法分别对表2 中的样本集进行性能仿真,比较其推荐RMSE 性能优劣。
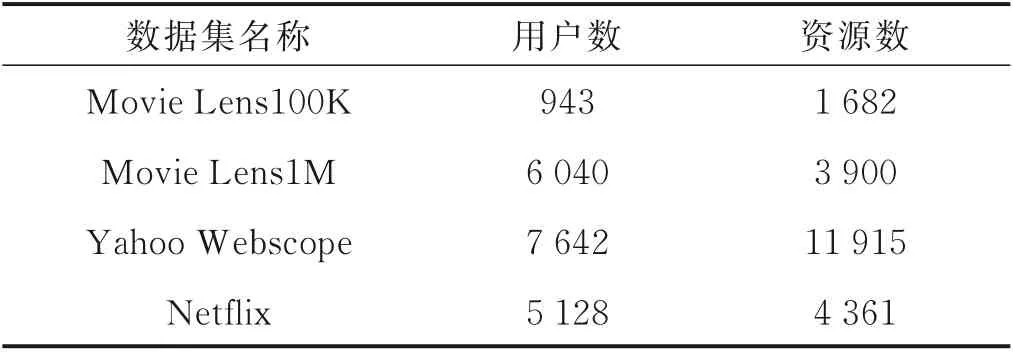
表2 仿真样本Table 2 Simulation samples
2.1 不同HL 节点数的均方根误差
分别设置不同的HL 节点数,验证不同节点数情况下的均方根误差(Root mean squared error,RMSE)性能,结果如图3 所示。
从图3 可以看出,RMSE 值均随着节点数的增加先降后升,表明个性化推荐的RMSE 值受HL 节点数影响敏感度高。对比发现Movie Lens 和Netfix 数据集和最佳节点数为100 个,而数据集Yahoo Webscope 在节点数为140 时获得最优RMSE 性能,这表明训练Yahoo Webscope 数据集比其他3 种数据集需要更大的深度RBM 网络。从图3 也可以看出,本文算法对Movie Lens100K 的推荐性能最优,获得RMSE 约为0.8,对Netfix 的推荐效果最差,RMSE 值约为0.95。因此,本文针对Netfix 集训练时选择的HL 节点数为140,其他3 种数据集均选择100 个HL 节点参与运算。

图3 4 种样本的RMSEFig.3 RMSE of four samples
2.2 不同样本稀疏度的RMSE
深度RBM 网络个性化推荐的性能除了与RBM 结构规模相关,对训练样本量依赖性也较高,因此差异化设置参与训练的样本量,验证其推荐性能,结果如表3 所示。初始状态的训练和测试样本比例为8∶2。
从表3 可知,当参与训练的样本变少,4 种数据集的推荐RMSE 值均上升。当训练集占比从80% 降至20% 时,Movie Lens100K 集、Movie Lens1M 集、Yahoo Webscope 集和Netflix 集的RMSE 性能分别下降了34.02%、36.66%、30.25%和42.82%。对比发现,Netflix 集的个性化推荐对训练样本集的稀疏度最敏感,其次是Movie Lens 集,样本集稀疏度对Yahoo Webscope集影响最小。总之,当训练集占比为80%时,可获得最优的个性化推荐性能。
2.3 不同算法的推荐性能
为了验证不同算法对表2 中4 种数据集的个性化推荐性能,分别采用协同过滤[13]、典型RBM[14]、深度神经网络[15]和深度RBM 算法对4 种数据集进行训练,结果如图4~7 所示。RBM 的节点数选择参照根据表3 结果,4 种算法参与训练的节点数均为总样本数的80%。

表3 不同训练样本量的RMSETable 3 RMSE of different training sample sizes
从图4~7 可得,对于表2 中4 种数据集的个性化推荐,深度RBM 的RMSE 均是最低数值,这说明深度RBM 对这4种数据集具有最高的推荐准确率。个性化推荐的准确率高低排序为深度RBM 表现最优,深度神经网络次之,协同过滤和典型RBM 的RMSE 性能最差。从运行时间来看,协同过滤和典型RBM 最好,深度RBM 和深度神经网络表现较差,主要原因是深度学习框架的运行需要多次正反向更新,导致运算步骤耗时较高。此外,Yahoo Webscope集的运行时间最长,主要是因为该样本集所包含的样本量最大。
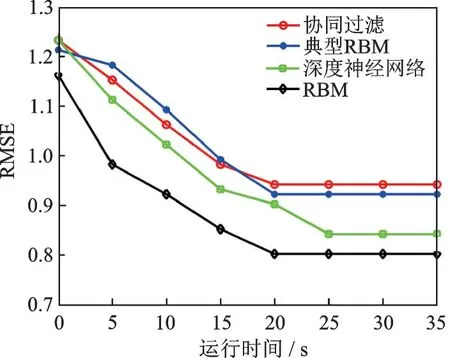
图4 4 种算法的RMSE(Movie Lens100K)Fig.4 RMSE of four algorithms (Movie Lens100K)
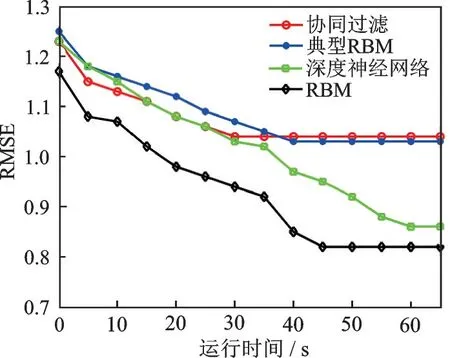
图5 4 种算法的RMSE(Movie Lens1M)Fig.5 RMSE of four algorithms(Movie Lens1M)
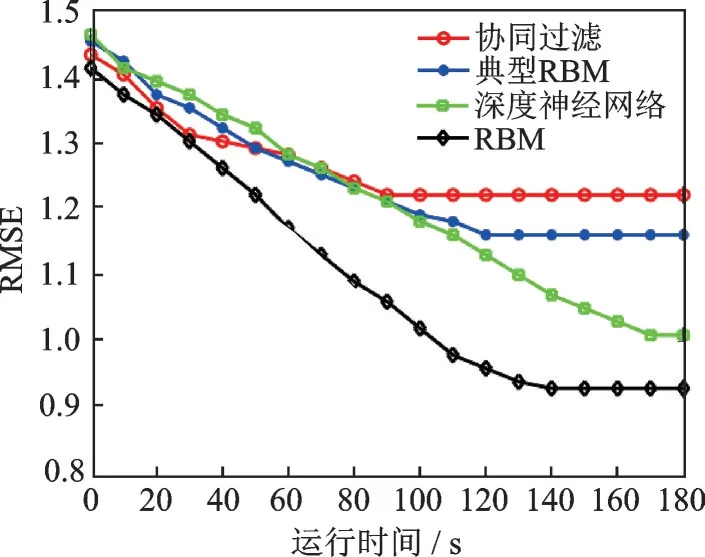
图6 4 种算法的RMSE(Yahoo Webscope)Fig.6 RMSE of four algorithms (Yahoo Webscope)
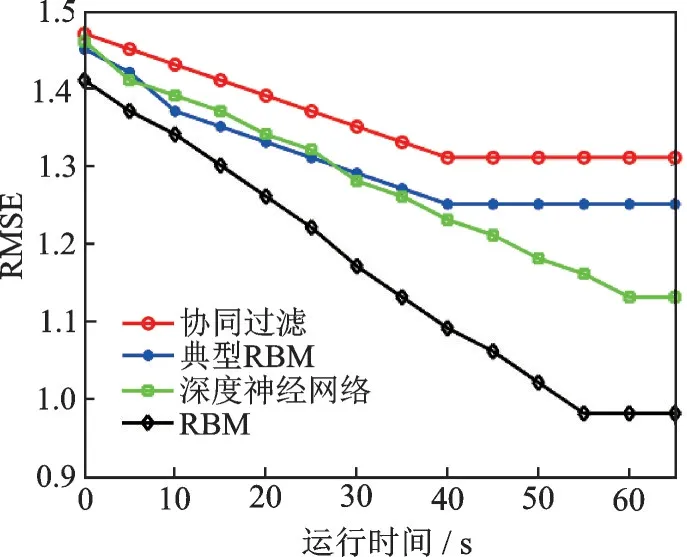
图7 4 种算法的RMSE(Netflix)Fig.7 RMSE of four algorithms(Netflix)
3 结束语
将深度RBM 应用于个性化推荐系统,根据用户和资源的特征,以及用户对以往资源的评分,并结合多次正反向更新,来最终获得稳定的深度RBM 模型。实验结果表明,在训练样本量充足时,合理设置深度RBM 的规模及隐藏层节点数,相比于常见个性化推荐算法,本文算法能够获得更好的推荐RMSE 性能。后续研究将进一步对深度RBM 的主要参数更新进行优化计算,以提高推荐效率,提高该算法在个性化推荐中的适用度。
猜你喜欢
快乐学习报·教育周刊(2022年16期)2022-05-01
成都信息工程大学学报(2021年3期)2021-11-22
中学生数理化·高一版(2021年2期)2021-03-19
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
文苑(2020年4期)2020-05-30
福建基础教育研究(2019年6期)2019-05-28
领导决策信息(2018年16期)2018-09-27
数学学习与研究(2017年3期)2017-03-09
汽车与新动力(2016年6期)2017-01-04
小天使·四年级语数英综合(2015年7期)2015-07-06
