
航行通告信息抽取方法研究
2022-04-14 03:27潘正宵罗银辉李荣枝
现代计算机 2022年2期
潘正宵,罗银辉,李荣枝
(中国民用航空飞行学院计算机学院,四川 618300)
0 引言
航行通告是以电信方式发布,告知飞行人员与飞行业务相关人员关于航空设施、服务、程序等的建立、情况或者变化,以及对航空有危险的出现和变化的通知。一份标准的航行通告报文应包括航行通告标志、Q项(限定行)、A项(发生地)、B项(生效时间)、C项(失效时间)、D项(分段时间)、E项(航行通告正文)、F项(下限)和G项(上限)。以上各项内容除E项外,均有标准的发布规范,而航行通告的E项报文属于自由文本,采用明语的形式编写来表达丰富的内容,故E项中的内容难以采用统一的格式进行处理。因此,如何自动化提取E项中所包含的重要信息一直是业界的难题。
文本信息抽取是自然语言处理任务中的一项。信息抽取(information extraction),即从自然语言文本中,抽取出特定的事件或事实信息,用于从海量的信息中,将内容自动分类,提取关键信息和重构。抽取出的信息通常包括命名实体(entity),关系(relation)和事件(event)。
基于神经网络模型进行建模的CNN和LSTM等方法广泛应用于信息抽取,然而神经网络的训练,依赖大量数据,这阻碍了它在小数据集上的运用。而符号主义,是一种将符号系统和有限合理性原理知识系统整合起来,形成公理体系的一种方式。利用符号进行知识表达的规则系统,及模式匹配系统,在少量数据集或需要明确解释性的场景中广泛使用。
由于航行通告信息没有公开的标注集,没有制定航行通告中实体的依存关系的关系图谱,故而在当前条件下无法使用深度学习等方法,只能在模式匹配技术的基础之上,实现信息抽取任务。
文本信息的抽取,具有较强的目的性,要求提取出来的信息具有一定的逻辑关联,能以指定的框架进行展示。本文根据识别出来的命名实体之间的位置,分析其依存关系,形成逻辑框架,并依照此框架,采用模式匹配的方法,抽取出航行通告中实体间的关系。本文的研究课题源于实习期间公司的航行通告信息处理同事的痛点,旨在促进航行通告信息的高效利用,开展对航行通告信息抽取的方法研究,提高航行通告信息处理的效率。该方法实现了航行通告中实体和关系的标注及抽取,并生成格式统一的标注数据集,具有工程实用价值与学术研究价值。
1 理论基础
1.1 令牌化
分词是NLP(nature language processing)的基础,分词的准确度直接影响了后续的词性标注,以及文本分析的质量。本项目主要处理AIP文件中的航行通告E项,以英文的形式呈现。英文语句使用空格将单词进行分隔,具有分词效果。但在航行通告中,存在诸如连词符等特殊字符,需要重新自定义分词逻辑。
在分词的工作中,采用令牌化思想。令牌化的作用在于处理的过程中,标记文本,基于某些预定义规则将文本转换为较小子文本,把句子拆分成单词、标点符号等元素。
令牌化分为词级标记,字符级标记与子字级标记。本文采用子字符级标记,属于前两种方式的综合形式。由于航行通告中大部分都是缩写且意义不连贯的单词,故采取词级标记,能取得较为良好的效果。但在有特殊字符的情况下,对特定字符采用字符级标记,可更精准地对所有词进行标记并分隔。
1.2 词嵌入与相似度
文本匹配是NLP中常见的一个问题,本文中命名体的识别,实际上就是一个文本匹配的过程,通过判断两个令牌之间的相似度,来判断这两个令牌是否属于同一个类别信息。
在识别特定的命名实体时,采取了词嵌入(word embedding)的方法。首先通过词向量算法,得到每个经由分词后单词的词向量,然后将已训练好的词嵌入模型迁移至任务中来,让原本的维度较高的词向量降维成维度较低的词嵌入向量,每一个词就是词嵌入模型空间中的一个点。这时,命名体识别的任务,就转变为了文本中每一个词嵌入向量v,与提取出来的每个类别的命名实体的样例词嵌入向量v之间的距离关系判别任务。计算其相似度的相似值sim(v,v)采用余弦相似度公式,如公式(1)所示。



sim(v,v)越接近1则说明两个词越相似,文本中的词与样例间的相似值超过一个设定的阈值后,即可认为该部分文本属于此类别的命名实体。
1.3 模式匹配与改进KMP算法
由于命名体之间的距离及顺序是天然具有一定关系的,这就意味着,可以通过归纳一定距离内的命名实体的顺序,从而分析它们之间的关系,形成一种特定的逻辑关联,并将信息重新组合成一套固定的框架。
在匹配的过程中,相较于普通的遍历匹配,本文采用了字符串匹配中用的KMP算法并加以改进。KMP算法主要通过消除主串指针的回溯来提高匹配的效率,其核心思路是提取并运用了加速匹配的信息,即在模式串中加入next标签。采用这种方式,在每次匹配失败的时候,不需要回退到模式串开始匹配的位置往后一位重新匹配,而是往后k-1位开始重新匹配。
而改进的KMP算法是在此基础之上,将匹配串中也加入类似于next数组的标签。采用此改进方式,则可在原本的减少模式串回退的基础之上,进一步减少匹配串的回退过程,加快匹配速度。本文中由于匹配的是标签顺序,因此参考KMP算法匹配字符串的思想,匹配标签列表。
1.4 评价指标
在评估相似值是否符合预期要求时,引入精确率和召回率进行评估。其中精准率是针对预测结果而言,它表示预测为正的样本中有多少是真正的样本,用P来表示。P的计算如公式(3)所示。其中TP是准确地将正类预测为正类的数量,FP是错误地把负类预测为正类的数量。

而召回率是针对样本而言,它表示样本中有多少正类被成功预测了,用R来表示,R的计算如公式(4)所示。其中FN表示把错误地把正类预测为负类的数量。

在评判实体间距离与关系抽取准确率之间的关系时,引入F值作为评估标准,F的计算如公式(5)。

2 实现方法
针对航行通告数据的特点,使用自定义的规则对通告内容进行分词。采用词向量算法对分词进行向量化处理,并由词嵌入的方法,标记自定义分类的命名实体并抽取。从航行通告的实际意义出发,结合命名实体的位置关系,总结归纳出实体间的关系模式,采用改进的KMP算法,进行模式匹配,抽取航行通告中的重要信息。文章中的研究流程如图1所示。

图1 信息抽取流程
2.1 分词过程
(1)定义标记规则。未经处理的文本会被以空格进行分割。在标记之前,可以加入自定义的需要进行特殊标记的符号,如“-~”等,或是其余的基于词缀的标记规则。
(2)将文本从左到右根据定界符进行标记,初步形成子字符串。
(3)每一个子字符串需要再进行两个检测:该字符串是否匹配其他的特殊标记规则;该字符串是否有前缀、后缀或中缀。
(4)输出所有经由标记化后的令牌。
图2是标记化规则的示例,分词工作完成之后,将获得一段文本S,文本S如公式(6)所示,其中w为文本S中的第i个分词。

图2 分词示例

2.2 命名实体识别
本文主要提取了航行通告中五类信息,分别为空域关闭,危险区域开放,限制区开放,跑道启停,导航台航路点。在系统性分析航行通告信息后,从中划分出了六类命名体并自定义其标签,标签及其代表的意义如表1。
阿里知道他们在说他。他吃着饭,一忽儿偏头看看阿东,一忽儿又偏头看看父亲。突然就冒一句:“姆妈说了,阿里蛮乖。”

表1 自定义标签
每个命名实体可由如公式(7)所示的向量E来表示,其中E为该命名实体的词向量,E表示该向量的起始字符位置,E表示该向量的中止字符位置。

在获取到向量E之后,根据自定义的标签,将E转换为根据规则匹配上的标签E,随后将新的向量E′放入T命名体集合中,T如公式(8)所示,其中E′表示的第i个向量。

2.3 关系抽取
结合航行通告的实际意义,本文提出了五种类型的逻辑,如表2。其中action类别中的实体间距离无特殊关联,故忽略其距离关系。其他类别的关系中,关系的界定范围与命名实体间的距离有严格的关系,需要在匹配的过程中,加入对于距离的判断。

表2 逻辑关联意义
在提取出命名实体之后,根据设定的模式串,可以进行关系抽取,一个类别的关系,具有多个模式串,如表3中,展示的是抽取圆形区域和导航台区域时,出现的不同的模式串。

表3 模式串
采用模式匹配,可以将标签列表与模式串进行匹配,获取标签之间的关系,即形成三元组关系串<主体,客体,关系>。在航行通告中,一个关系串常常有多个客体,需要将对应的多个客体转换成一个向量来进行存储。
在2.2中获得输入T后,结合词间距信息,运用改进的KMP算法,与表2中的五类框架所形成的模式串进行匹配,从而实现关系抽取。
3 实验验证
实验基于Windows 10环境,编程语言为Python版本3.7,其中spaCy库的版本为2.3.5。实验的数据源于2020年航行通告。提取其中航行通告的E项信息213851条作为实验的数据。
3.1 命名实体抽取方法验证
项目共提取六类命名实体,其中subject和act这两个类别的对象根据实际经验总结,需要更为精准的匹配,其余类别因文本差异较大,不用过于精准。
使用人工标注命名实体的数据进行实验,精准率、召回率与匹配值的关系如图3所示。
从图3中可以看出,随着相似值的上升,精准率得到了提高但召回率明显下降。根据不同命名实体类别的要求,subject和act类对精准度的要求更高,而其他类要求在保证精确率的情况下,提高召回率,因此对于这两种要求,分别采用了不同的相似值,前两类的相似值为90%,其余类的相似值为85%。

图3 精准率与召回率
对于出现的FP,如表4所示,可通过正则匹配或人工筛查的方式对数据进一步地筛选,精准率得以进一步的提高。最终提取出的内容如表5所示。

表4 错误样例

表5 命名实体提取
在实验结果样例中,需要被识别的信息被//包裹、分割开来用以展示,提取出来的命名实体按照类别分别储存展示。从结果可以看出,所有应该被识别的信息都得到了有效的识别,分别打上了标签,且都记录了字符串在原文中所处的位置,为后续的关系识别提供了输入文本基础。
3.2 关系抽取方法验证
在本文中,采用了改进的KMP算法替代传统遍历,在遍历速度上得到了提升,时间对比如表6所示。

表6 运行时间对比
在实验过程中,发现航行通告中命名实体之间的距离,与它们是否产生关系具有较强的关系,定义命名实体之间的距离为D,定义当距离大于D时,两命名实体之间不再产生关系。根据2.2中E的值,可计算出D。使用人工标注了关系的数据进行试验,
由图4可以看出,当D等于5时,F1值最高,在后续的关系抽取实验中,引入参数D,对关系自动抽取进行约束。
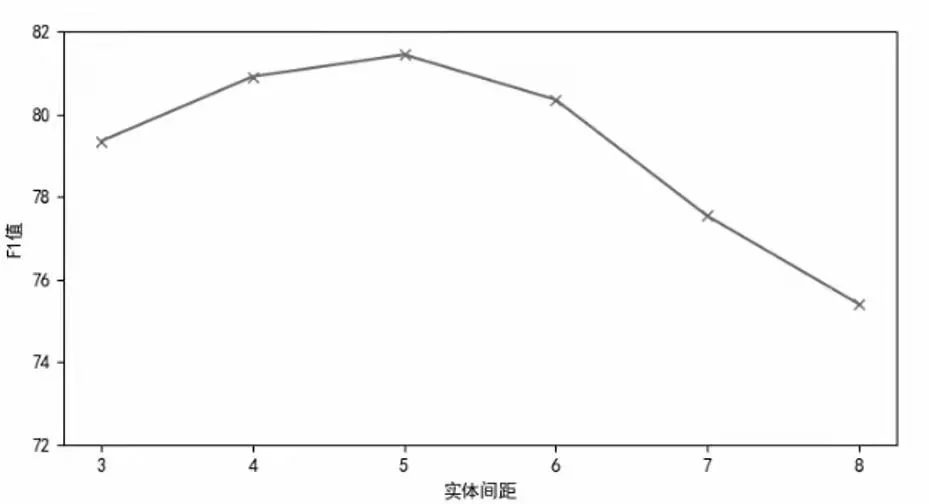
图4 F1值与距离的关系
关系抽取后,根据工程需求对信息进一步提取重组,信息重组之后的内容如表7所示。

表7 关系提取
将被标识出的命名实体经由它们之间的关系,进行信息重组之后,逻辑性大大加强,能够快速对重组后的信息进行理解。
4 结语
本文研究了航行通告信息提取的方法,由于航行通告E项中的信息不具备严格语法特征,且在此之前,无任何公开的标注数据集,相比基于标注数据集进行训练的模型,本文所使用的方法更具实用性。
本文实现了对于航行通告信息之间的关系抽取,实现了在该领域内,关系标注从无到有的突破,可为后续无监督条件下的信息提取技术奠定基础。其余类型的航信通告信息需要重新建立关系逻辑框架,这是本文所使用的方法的局限性所在。如何针对航行通告信息弱语法的特征建立更好的关系抽取模型,需要继续深入研究。
猜你喜欢
校园英语·月末(2021年13期)2021-03-15
儿童故事画报(2020年7期)2020-08-03
小学科学(2020年6期)2020-06-22
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
语文世界(小学版)(2019年3期)2019-03-18
创新作文(1-2年级)(2017年7期)2017-12-26
中文信息(2017年9期)2017-11-08
小品文选刊(2014年6期)2014-05-08
文苑·感悟(2008年11期)2008-11-27
