
基于命名实体n-gram图的文本相似性度量
2022-04-14 03:27:06周显春贾树文
现代计算机 2022年2期
于 营,周显春,贾树文
(1.三亚学院信息与智能工程学院,三亚 572000;2.三亚学院容淳铭院士工作站,三亚 572000;3.三亚学院盛宝金融科技商学院,三亚 572000)
0 引言
文本比较算法是自然语言处理和文本挖掘任务的关键,如文本聚类、文本分类和自动文本摘要等。然而,理解两篇文章是在谈论同一主题还是以某种方式相关,仍然是自然语言处理面临的一个挑战。
自动文本比较的主要困难是词的语义歧义、句子之间的词汇和句法差异。Stavrianou等提出,在文本预处理过程中必须考虑到以下情况对文本相似性的影响:停用词和噪声数据(如拼写错误的单词)的去除、词干提取、词性标注、多词术语搭配、词语切分和文本表示。本研究的文本预处理旨在通过减少语义歧义和特征空间的维度来减少文档中的信息量。
向量空间模型(vector space model,VSM)把对文本内容的处理简化为向量运算,以空间上的相似度(如余弦相似度)来表达语义的相似度,常用于信息过滤、信息获取、信息索引,以及词的语义相关性的评估。潜在语义分析(laten semantic analysis,LSA)是一种文本话题分析的方法,特点是可以通过矩阵分解(SVD或者NMF)来发现文本与单词之间的基于话题的语义关系。此外,使用n-gram模型做文本表示的研究也有很多。n-gram是一种基于统计语言模型的算法,其基本思想是将文本内容按照字节进行大小为n的滑动窗口操作,形成了长度为n的字节片段序列。每一个字节片段称为gram,对所有gram的出现频度进行统计,并按照事先设定好的阈值进行过滤,形成关键gram列表,也就是这个文本的向量特征空间,列表中的每一种gram就是一个特征向量维度。
本文将命名实体的信息量与n-gram模型的表示能力相结合,以捕获词序列信息,并定义一个新的基于n-gram模型的文本相似性度量方法。本研究使用两个不同的数据集评估该方法在文本聚类任务中的性能。结果表明,术语选择可以提高n-gram相似性的性能,命名实体可以成为使用TD-IDF(term frequency-inverse document frequency,词频-逆文本频率指数)加权方案选择的术语集的有效补充。
1 相关研究
近年来,文本相似性度量的相关研究有很多。Giannakopoulos和Karkaletsis使用长度为n的滑动窗口将文本表示为n-gram模型,通过将相邻的n-gram与表示它们在给定文本窗口内共现频率的边连接起来,捕获文本中的词序,并检测文本形态中的部分相似性。该方法具有一定的抗噪能力,并且无需预处理。
尽管n-gram在文本挖掘任务中表现出了良好的性能,但对于大文本,其复杂性显著增加。为了解决这个问题,往往只关注信息量较大的术语,例如具有最高TD-IDF的术语或命名实体,从而在不丢失重要信息的情况下降低模型的复杂性。Kumaran等使用命名实体术语来提高“新事件检测”任务的性能,Toda等使用命名实体来聚类搜索结果,而Sinoara等和Montalvo等人在文本聚类中使用命名实体作为特权信息。Gomaa对文本相似性度量进行了调查,将其分为三类:基于字符序列的字符串度量,基于语料库的度量,基于知识的度量。Mihalcea等也使用了来自外部语义网络的信息,并为短文本定义了基于知识的相似性度量,与其他基于向量的相似度度量相比,文本语义识别的错误率降低了13%。Friburger等发现,使用“命名实体”向量和“所有词”向量并增加实体向量的权重,具有最佳的整体性能。Schenker等人使用图表示模型和基于图的相似性度量来执行文本聚类和分类任务。
与国外学者相比,国内学者在文本相似性度量方面的研究开展的较晚。金希茜基于VSM模型提出对文本进行特征提取,通过词汇的语义相似度进行文本特征提取,采用递归算法判断文本相似度。华秀丽通过《知网》对词频较高的文本特征项进行语义分析,达到获取文本语义相似度的效果。针对同义词,该方法采用将同义词进行词义合并,以某一个词来替代所以该类别的词,但该方法计算较复杂。唐凌志针对这个问题,采用本体相似性方法中的语义密度因子作为调节因子应用到文本相似性计算中,达到降低计算复杂度的效果。
本文在Giannakopoulos和Karkaletsis提出的文本相似性度量标准的基础上,通过TF-IDF区分命名实体和频数较高的术语,并相应地对n-gram模型进行加权。
2 研究方法
本文定义了一种文本比较方法,该方法识别文本中出现的命名实体,并将文本表示为ngram模型,使用图比较操作符进行比较。
2.1 算法原理
对于每一对输入文本T,T,相似度函数f将输出一个分数s=f(T,T),其中,{s∈R|0≤s≤1}表示两文本的相似程度。s的值接近1,表示文本之间高度相似;当s接近0时,文本不相似。过程如图1所示。
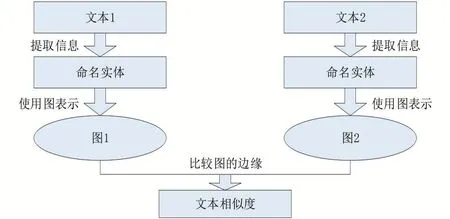
图1 算法原理
首先是信息提取,从文本中提取命名实体和使用TF-IDF权值较大的术语两种类型的术语,命名实体的提取使用Open Calais API完成;接下来是文本表示,所有实体都被替换为哈希值,该哈希值允许多词实体在词图表示中显示为单个词模型,其余的词都替换为占位符,本研究中选择大写字母“A”作为占位符。单个占位符的使用使得所有不重要的单词在词图中只有一个节点,这显著降低了n-gram的大小和比较运算的复杂度。同样,命名实体到哈希值的映射进一步减少了模型的内存占用,因为在大多数情况下,哈希值比完整实体名占用更少的内存。
2.2 n-gr am的创建和比较
为了创建单词n-gram图,使用JInsect工具箱。JInsect工具箱是一个基于Java的工具箱和库,它支持在自然语言处理应用程序中使用n元语法图,支持自动摘要,摘要评估,以及文本分类和索引,支持字符和词n-gram图并实现了多种图的相似性度量。
单词n-gram图是在单词上使用大小为n的滑动窗口创建的,这表示为文本中的每个单词或术语哈希值创建一个节点,并且图的边连接比较接近的单词(节点)。当距离≤d时,使用d=n表示。该图是加权的,权重表示在滑动窗口的距离内,两个单词彼此靠近的次数。
为了比较两个图,我们称它们为G和G,使用了四个相似性度量:值相似度、大小相似度、包含相似度和归一化值相似度,四个度量值的取值范围均为[0,1]。图G和G的比较描述如下:

3 实验
3.1 数据准备与处理
在实验中,使用了两个数据集。分别为:①AG_news数据集,含2000多个新闻源的新闻文章,其中包括120000条训练样本和7600条测试样本,每一条样本都是短文本,有4个类别(World、Sports、Business、Sci/Tec)。②MultiLing 2019_wiki数据集,多语言模型(42种)进行命名实体识别,直接挑选实体作为词条。对AG_news数据集,进一步排除掉OpenCalais API不支持或OpenCalais API处理超时的文档,最终的数据集中含10837个文本集;对MultiLing 2019_wiki数据集,筛选出英文版本的文档,得到3793个文本集。
本文使用k-Means聚类算法评估所提出的算法在文本聚类中的性能。该算法的输入是一个文本相似度矩阵,文本相似度矩阵通过以下方法创建:
(1)对文本数据进行过滤,提取命名实体与TF-IDF权值较大的文本。
(2)对获取的文本文件进行数据清洗,并将待处理的字符串分成单词序列,增加到n-gram模型中。
(3)使用TF-IDF和余弦相似度计算相似度模型VSM。
其中,命名实体是采用OpenCalais提取的,TF-IDF是Java程序计算的,n-gram图是通过JINSECT库构建的,使用JINSECT的图相似性度量功能对构建的n-gram图进行比较,以创建文档相似性矩阵。
3.2 聚类有效性指标
为了实现最优类簇数和最优划分的选取,应当选择合适的聚类的有效性评价指标。一般来说,聚类有效性指标可以分内部有效性指标和外部有效性指标。内部有效性指标主要基于数据集的几何结构,从信息的紧凑性、分离性、连通性和重叠度等方面对聚类效果进行评价;外部有效性指标是指当数据集的外部信息可用时,通过比较聚类划分与外部准则的匹配度,可以评价不同聚类算法的性能。
在当前实验数据中,“ground truth”是对数据文档的实际分类,因此将“ground truth”选为外部指标。由于所有实验都是使用相同的聚类算法k-Means完成的,影响聚类质量的唯一因素是文本相似性度量,因此结果具有可比性。为了评估生成的聚类方案的有效性,本实验主要采用了查准率(Precision)、查全率(Recall)和F1度量值(F1-measure)指标。
3.3 实验结果
本实验使用4种不同的相似性度量方法来评估k-Means生成的聚类,即:
(1)使用TF-IDF算法计算的词频向量余弦相似度(TF-IDFVSM)。
(2)使用所有词的n-gram图相似度(All_graph)。

表2 MultiLing 2019_wiki数据集的聚类性能
(3)提取的命名实体的n-gram图相似性度(Ent_graph)。
(4)命名实体与TF-IDF权值较大的术语的结合方法(Ent&tf-idf_graph)。
表1总结了新闻组数据集的结果。从表中可以看出,所有方法的在查准率和F1值上都表现出较低的性能,这主要由于类别较多以及词的特征空间的稀疏性。但Ent_gragh仍然优于原始的TF-IDF VSM和All_graph方法;Ent&tfidf_graph更是在查准率和F1值上明显优于TFIDF VSM方法。采用在实体n-gram图中添加一些与高TF-IDF值相对应的节点的方法,显著改进了VSM和简单n-gram图模型的结果,且所有值都是在95%置信区间计算的。

表1 AG_news数据集的聚类性能
在MultiLing的多语言数据集中,Ent_graph方法在查全率Recall和F1值明显优于所有其他方法,命名实体似乎比文本中的其他词对结果的影响更为突出。这体现了本文所提出的基于图的相似性度量的一个主要优势,即处理多种语言文本的能力。实体提取机制仅将特征空间减少到命名实体,这些实体在语言之间经常保持不变,从而降低特征空间的稀疏性。另外,当TF-IDF权值比较高的术语添加到图中时,性能反而会下降,这是因为这些跨语言翻译的术语不匹配,从而降低了相应文档的图的相似性。
4 结语
本文提出了一种基于图的文本相似性度量方法,该方法利用命名实体的信息,提高了文本聚类任务的有效性。使用命名实体和TF-IDF权值较高的术语来构建的n-gram图,与全文ngram图相比,复杂度降低,更为简单,从而提高了使用所有文档信息的n-gram图相似性度量的复杂度。结果表明,该方法在文档中命名实体较多且实体空间重叠的情况下效果更加明显,这是因为实体的密度会降低特征矩阵的稀疏性。需要注意的是,该方法适用于多语言文本集合,因为与文档中的不同的词相比,命名实体受翻译的影响较小。当命名实体从一种语言翻译成另外一种语言时,语义差异很小,所以容易被词n-gram图模型捕获。
猜你喜欢
数学小灵通·3-4年级(2024年2期)2024-05-15 02:02:44
数学物理学报(2022年5期)2022-10-09 08:56:44
数学年刊A辑(中文版)(2022年4期)2022-02-16 08:18:02
河北画报(2020年8期)2020-10-27 02:54:20
数学年刊A辑(中文版)(2019年3期)2019-10-08 07:34:38
浙江大学学报(工学版)(2016年2期)2016-06-05 09:20:51
中国学术期刊文摘(2016年1期)2016-02-13 14:05:23
俄罗斯问题研究(2013年1期)2013-03-11 15:44:01
中国科技术语(2012年3期)2012-03-20 14:36:13
中国科技术语(2012年3期)2012-03-20 14:36:11
