
基于BERT 的中文健康问句分类研究
2022-04-12 03:40徐星昊
电视技术 2022年3期
徐星昊
(昆明理工大学 信息工程与自动化学院,云南 昆明 650000)
0 引言
目前,智能医疗问答系统已逐步参与到医院的诊疗过程中,如何将用户所提出的问题进行准确分类是智能医疗问答系统的关键。例如问题“病情描述:高压196 低压139 血压严重吗?”的类别是“治疗”,而问题“病情描述:请问高血压能否吃银杏叶片?”的类别是“健康生活方式”。由此,能否正确识别用户问题的语义类别,是决定系统能否返回正确答案的重点,医疗健康问句分类尤为关键。
医学健康问句具有以下两个特点:第一,由于所有健康问句都是病人在平台中的口语化提问,其中涉及的语句大多数为短文本,而短文本包含的词项少,导致文本内容缺乏足够的上下文信息,极大地限制了短文本分类任务的完成。第二,健康问句具有较强的专业性和复杂性,病人在提出问题时会出现描述不准确、不全面等问题。对于短文本稀疏性问题的研究,陈等人[1]使用BERT、ERNIE 模型通过领域预训练提取先验知识信息,结合TextCNN模型生成高阶文本特征向量并进行特征融合来实现短文本分类。杨等人[2]提出了一种基于多特征融合动态调整模型特征的方法进行短文本分类。而对于问句中病人描述不准确、不全面的问题,将表述不清晰的医学关键词进行加强解释,有助于辅助健康问句的分类,如张等人[3]使用外部知识结合双层注意力机制的方法进行短文本分类。以上研究方法都只是简单地对特征进行融合。
健康问句的文本大多是短文本,词项少且存在问句描述不清晰的问题,上述的几种短文本分类方法都有一定的局限性,因此本文提出一种把基于变换器的双向编码器表征技术(Bidirectional Encoder Representations from Transformers,BERT)的字符级特征取平均与BERT 的句子级特征拼接的中文健康问句分类方法。本文的创新点是:通过将BERT 的字符级特征与BERT 的句子级特征融合,获取多维度特征知识来为分类任务提供基础,从而进一步改善多标签文本分类(Multi-Label text classification,MLTC)效果。
1 相关工作及理论
1.1 BERT 模型
1.1.1 BERT 模型概述
BERT 模型是以双向Transformer 为基础,面向掩码模型(Masked Language Model)和下一句判断(Next Sentence Prediction)任务构建的深度学习模型。当前,采用大量文本作为数据集预训练而成的BERT 模型已成为处理多项自然语言处理(Natural Language Processing,NLP)任务的通用架构。
1.1.2 BERT 模型的输出
BERT 模型的输出有两种模式:一种是字符级别的输出,对应的是输入短文本中的每一个字符所对应的特征表示;另一种是句子级别的向量,即BERT 模型输出最左边[CLS]特殊符号的向量。BERT 通常将[CLS]视作整个句子的语义特征,如图1 所示。
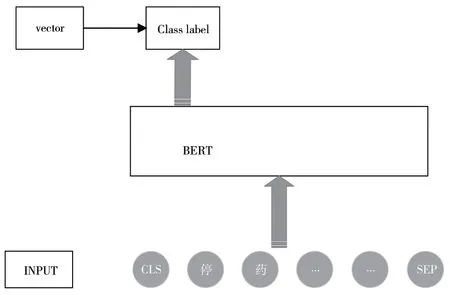
图1 BERT 输出模型
1.2 多标签文本分类
在自然语言处理中,多标签文本分类是一项基本且具有挑战性的任务。MLTC 的目的是为给定的文本分配多个标签。MLTC 已广泛应用于情感分析、意图识别以及问答系统等许多领域。随着深度学习的发展,单标签分类取得了巨大的成功。通过将问题视为一系列单标签分类任务,可以将单标签文本分类简单地扩展到MLTC 任务,但是这种过度简化的扩展通常会带来较差的性能。与常规的单标签分类不同,MLTC 各种标签之间存在语义依赖性。由于本文的数据集不考虑标签之间的语义依赖性,而是将问题视为一系列的单标签分类任务,因此本文的多标签分类流程如图2 所示。
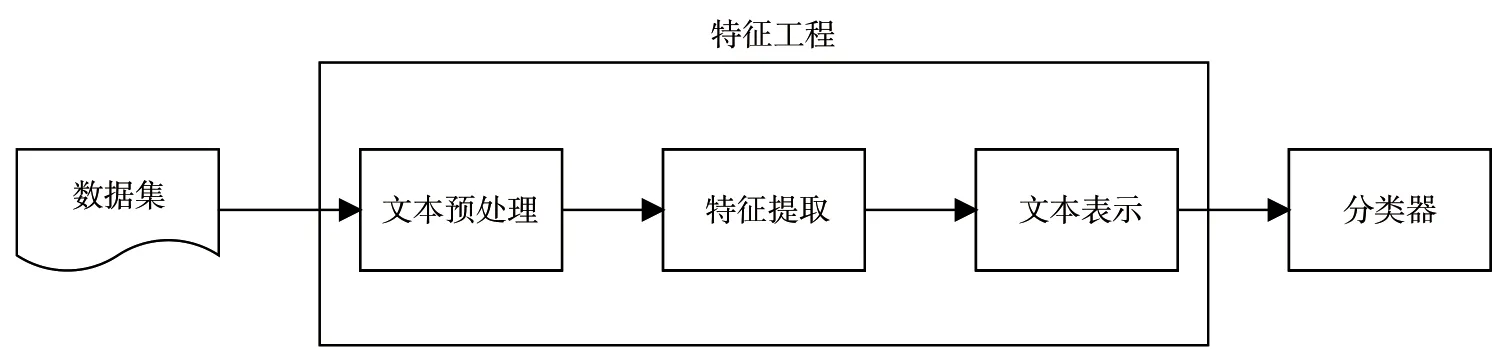
图2 多标签文本分类
2 模型设计
大规模的预训练语言模型开始出现在公众的视线之中,是因为这些预训练模型可以缩短人们花费在特征提取工作上的时间,使得自然语言处理走向另一个阶段。BERT 就是这类基于预训练任务的自然语言处理模型。这些模型往往基于大量的语料预训练任务,在有足够的算力的情况下,通过对下游任务的微调工作,能够产生优越的表现。通过对具体问题具体语料下的分析和模型结构的调整,预训练模型结构可以产生更加优异的效果。
由于本文数据集相与医学健康相关,因此采用Zhang 等[4]提供的mcBERT 预训练模型,在中文生物医学领域的大量语料上完成训练。
本文利用BERT 模型输出的Sequence_out 取平均并与Pooler_out 进行拼接,也就是将BERT 的字符级特征取平均与句子级特征拼接,该模型记为SQ_BERT。CLS 代表的是分类任务的特殊token,它的输出就是模型的Pooler_output。SQ_BERT 算法中,Pooler_output 对应的是[CLS]的输出,Sequence_output 对应的是所有其他的输入字的最后输出。算法的具体流程步骤如下。
(1)输入原始文本数据。
(2)对文本数据进行预处理。
(3)预处理好的数据按照[CLS]+句子A(+[SEP]+句子B+[SEP])的格式送入模型中。其中,[CLS]代表分类任务的特殊token,它的输出就是模型的Pooler output;[SEP]是分隔符,句子A 以及句子B 是模型的输入文本。句子B 可以为空,如果句子B 为空,则输入变为[CLS]+句子A。
(4)对步骤(3)所得到的结果Sequence_output取平均且与Pooler_output 进行拼接。
(5)将步骤(4)的结果作为输入送入Sigmoid分类器进行分类。
3 实验分析
基于提出的模型与算法,对问句的主题进行分类(包含A 诊断、B 治疗、C 解剖学/生理学、D流行病学、E 健康生活方式、F 择医共6 个大类)实验[5]。由于C 解剖学/生理学这一类数据集中仅含有一个问句数据,无法保证实验的全面性和有效性,因此在实际实验中将问句主题分为5 类,即诊断、治疗、流行病学、健康生活方式以及择医[6]。
3.1 数据集和评价指标
3.1.1 数据集
本文所用的数据集为Kesci 的公众健康问句分类比赛数据集和中文公众健康问句数据集。Kesci的公众健康问句分类比赛数据集的各项基本信息如表1 所示,中文公众健康问句数据集[7]基本信息如表2 所示。
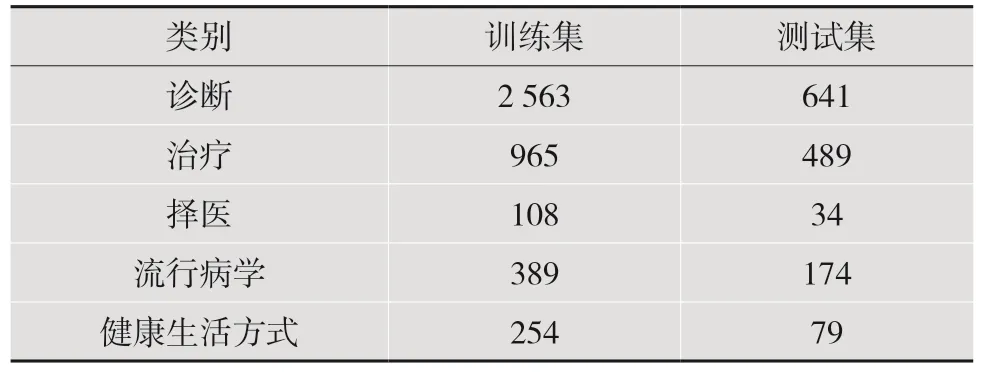
表1 Kesci 公众健康问句分类数据集
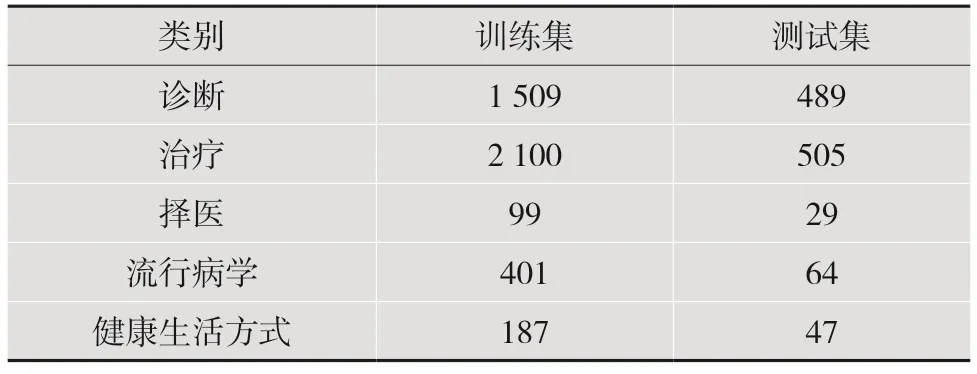
表2 中文公众健康问句数据集
3.1.2 评价指标
本文实验的评价指标引入文本分类模型常用的评价指标,包括精确度(Precision,简称P)、召回率(Recall,简称R)以及F 值(F-Score,简称F)。
3.2 实验设置
3.2.1 实验平台
本研究中所有的代码都由Python 语言编写,模型基于Pytorch 搭建。设备操作系统为Windows,配备GeForce RTX 1650,内存为16 GB。
3.2.2 数据预处理
对于Kesci 公众健康问句分类数据集,通过每一类数据量的比较发现解剖学/生理学这一类别数量分布极度不平衡。为保证数据集在训练和测试的过程中的合理性,将于解剖学/生理学这一类别剔除掉。由于该数据集包含5 000 条有标签的数据,将数据集按4∶1 的比例分为训练集和测试集[12]。
对于实验参数设置,在训练模型中,初始学习率设置为2×10-5,epoch 设置为5,并且利用K 折交叉验证法(实验中K=5)。由于BERT 的最大处理长度为512,因此在处理长文本的过程中使用截断法。从数据集可以看到,由于问句基本集中在尾部,因此可以将头部长度设置为127(稍短),尾部长度设置为383(稍长)。具体参数设置如表3 所示。
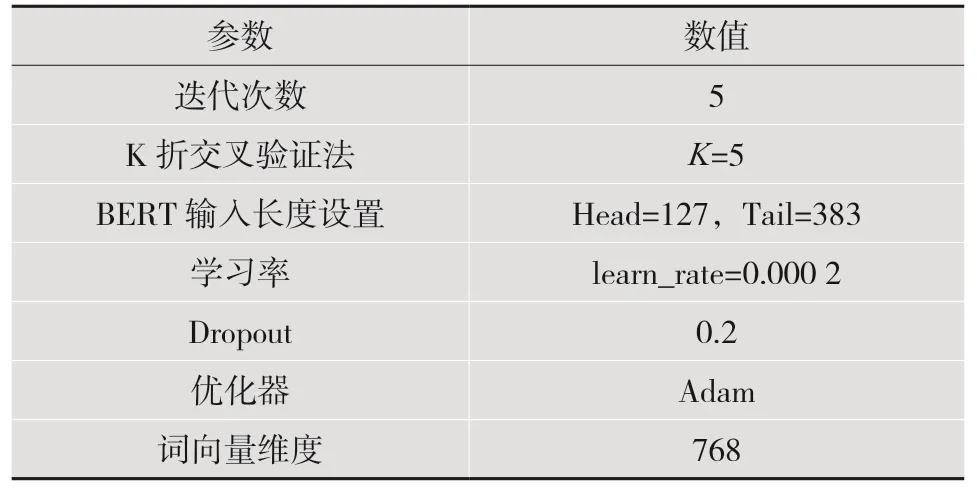
表3 参数设置
3.3 实验结果与分析
3.3.1 实验结果
实验结果分为两部分,一个是Kesci 公众健康问句分类数据集对比实验,另一个是中文公众健康问句数据集对比实验。第一部分实验分别为CNN[8]、LSTM[9]、BiGRU+Attention[10]以 及BERT 与本文模型在实验中的效果对比,实验结果如表4所示。
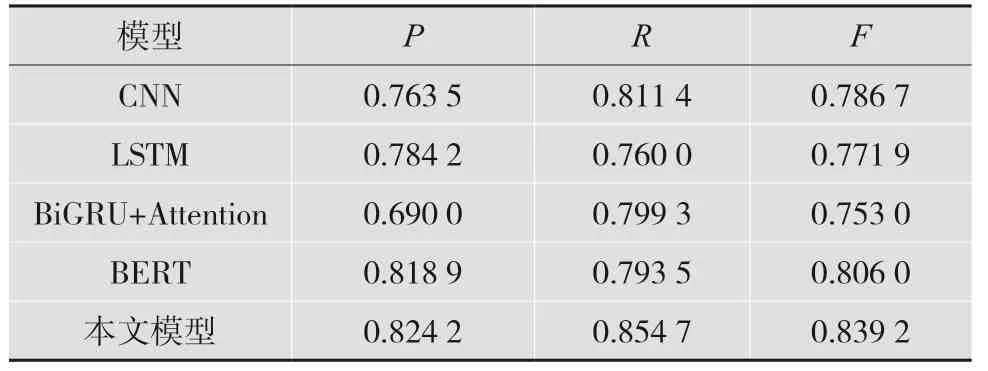
表4 实验效果对比
第二部分实验分别为CNN、LSTM、SA-CIndRNN 与本文模型在实验中的效果对比。本文模型相较于一般的基线模型对比实验效果有显著提高,与同样使用特征融合的模型SA-C-INDRNN 进行对比,效果也略高于SA-C-INDRNN 模型。实验结果如表5 所示。
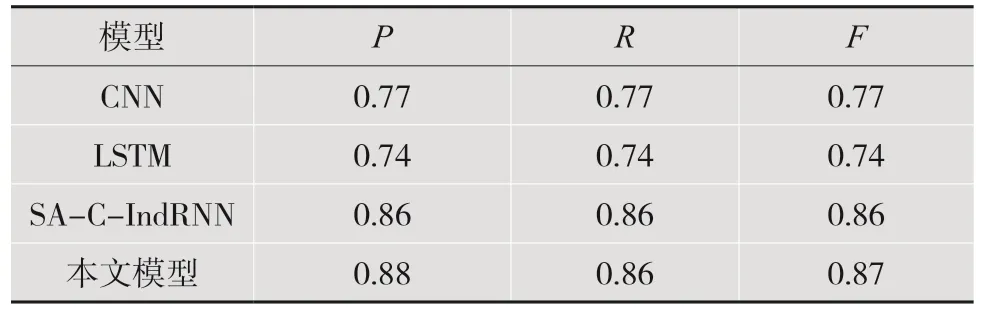
表5 对比实验结果
3.3.2 实验分析
由表4 的实验结果可知,本模型的效果优于LSTM、BiGRU 以及CNN 等传统文本分类深度学习模型。相比于BERT,本文模型的F1 值上升了3.3%。通过效果分析可知,将BERT 的字符级特征取平均与句子级特征拼接的效果优于BERT。由表5 结果可知本模型相比于传统的深度学习模型有或多或少的提升,并且比SA-C-IndRNN 模型的结果F1 值上升了1%。
4 结语
针对患者在提出健康问句时描述不明确、不全面以及短文本分类存在特征少且稀疏等问题,本文提出了通过将BERT 的字符级特征拼接于BERT 的句子级特征的方式进行分类。实验结果表明,所提的方法在医学中文健康问句数据集分类中取得了较好的效果,相较于传统的深度学习方法有着明显的提升。
本文方法提升了健康问句在问答系统中的分类效果,使问答系统能够对健康问句进行更高效、便捷的分类,也可为其他领域的短文本分类模型构建提供借鉴。未来将对不同语料库内容进行对比,优化关键词词典;尝试在语义层面深度提取医学短文本关键词,从而深度提取关键词,更好地实现医学短文本分类。另外,尽管将BERT 的句子级特征与字符级特征拼接取得了较好效果,但是特征提取方面依旧不足,可进一步改善特征提取效果,从而使健康问句的分类更准确。
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
时代英语·高二(2018年7期)2018-12-03
车迷(2018年11期)2018-08-30
时代英语·高二(2018年3期)2018-06-06
海峡姐妹(2018年3期)2018-05-09
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
