
融合特征增强和自注意力的SSD小目标检测算法
2022-04-09 07:06:04张馨月降爱莲
计算机工程与应用 2022年5期
张馨月,降爱莲
太原理工大学 信息与计算机学院,山西 晋中 030600
小目标检测是指针对图像中像素占比较少的目标,借助计算机视觉在图像中找到并判断该目标所属类别的目标检测技术,目前已被广泛应用于国防军事、交通运输、工业等领域[1]。在复杂的现实场景中,由于拍摄角度不同、非目标物体遮挡、成像天气和光照条件各异,导致小目标不易定位,难以辨别[2]。同时,小尺寸目标缺乏区分自身与背景或相似类别的外观信息,且在深度卷积网络中极易丢失特征信息,在检测时容易出现漏检和误检的情况[3],因此在复杂场景中准确定位和识别小目标是计算机视觉中一项具有挑战性的任务。
随着深度学习的快速发展,目标检测取得了显著的进展。基于卷积神经网络的目标检测算法分为两类,分别是两阶段目标检测算法和单阶段目标检测算法。单阶段目标检测算法可以通过图像上规则和密集的采样网格来定位对象,实现了端到端的目标检测,相比于两阶段目标检测算法,具有较高的检测准确率和检测速度,如YOLOv3[4]和SSD[5](single shot multibox detector)等。为了能够检测尺寸差距很大的目标,SSD首次将特征金字塔的思想应用于目标检测,从多尺度特征图中检测具有不同尺度和纵横比的目标。但自底向上提取特征的模型,浅层特征图缺乏语义信息,深层特征图缺乏位置信息,导致小目标的检测准确率较低。因此,很多学者提出通过增强SSD模型的语义信息,达到进一步提高小目标检测的效果。DSSD[6]利用跳跃连接和反卷积层融合上下文信息,丰富了浅层特征图的语义信息,但由于模型参数量较大导致检测速度较慢。MDSSD[7]通过融合深层语义信息生成信息丰富的特征图,增强了特征图中小目标的语义特征。梁延禹等[8]提出采用密集连接结构提高主干的特征提取能力,并使用特征图空间和通道间的全局信息,增强浅层特征中小目标的上下文语义信息。Zhai等[9]提出了一种多尺度特征层次的融合机制,将网络结构中的浅层位置特征与深层语义特征有机地相结合。Huang等[10]提出使用跨尺度特征融合的方法增强了上下文之间的关联,但跨尺度特征图存在语义差异,直接融合可能导致位置偏移和混叠效应[11]。FPN(feature pyramid network)[12]引入自深向浅的语义信息传递路径,通过融合相邻特征图的方式增强浅层特征图的语义信息。Tan等[13]提出的双向特征金字塔网络,通过引入可学习的权值来学习不同输入特征的重要性,提高了小目标的检测准确率。
本文提出了一种不仅能增强浅层特征图语义信息,又能平衡特征图间特征信息的算法:融合特征增强和自注意力的SSD小目标检测算法FA-SSD,该算法具有以下4个特点:
(1)在SSD基础上添加一条自深向浅的递归反向路径,采用递归的方式融合上采样深层特征图与浅层特征图,从深层向浅层传递语义信息,增强浅层特征图的语义信息。
(2)提取并融合深层多尺度特征图的全局上下文信息、局部上下文信息和语义信息,增强深层特征信息的可鉴别性。
(3)采用亚像素卷积和逐层并联的膨胀卷积,扩大特征图的分辨率并提取目标周围的上下文信息,增强上采样后特征图的语义信息。
(4)利用自注意力机制自适应地调整融合了深层语义信息和浅层位置信息的特征图,增强特征图中关键信息的权重,缓解融合特征图产生的混叠效应和位置偏移。
1 相关工作介绍
1.1 SSD目标检测模型
SSD模型是一种基于卷积神经网络的单阶段目标检测模型,该模型使用VGG16网络作为骨干网络,将VGG16网络末端的全连接层转换为卷积层,并在此基础上新增额外的卷积层来获得更多的特征图,然后使用VGG16网络和新添加的卷积层中分辨率不同的特征图独立地预测。SSD的网络结构如图1所示,其首先对原始输入图像进行规范化处理,将其缩放至固定大小,作为模型的输入;其次,使用SSD网络提取输入图像的特征,得到尺寸大小为38×38×512、19×19×1 024、10×10×512、5×5×256、3×3×256和1×1×256的6个多尺度特征层,每个特征层侧重于提取特定尺度对象的特征信息,其中深层特征图关注大目标的特征,浅层特征图关注小目标的特征;最后,对不同尺寸的特征图设置不同长宽比和数量的先验框,通过两个3×3卷积层预测默认边界框的类分数和位置偏移量,使用最大值抑制分解(NMS)的后处理策略来获得最终的定位边界框[14]。
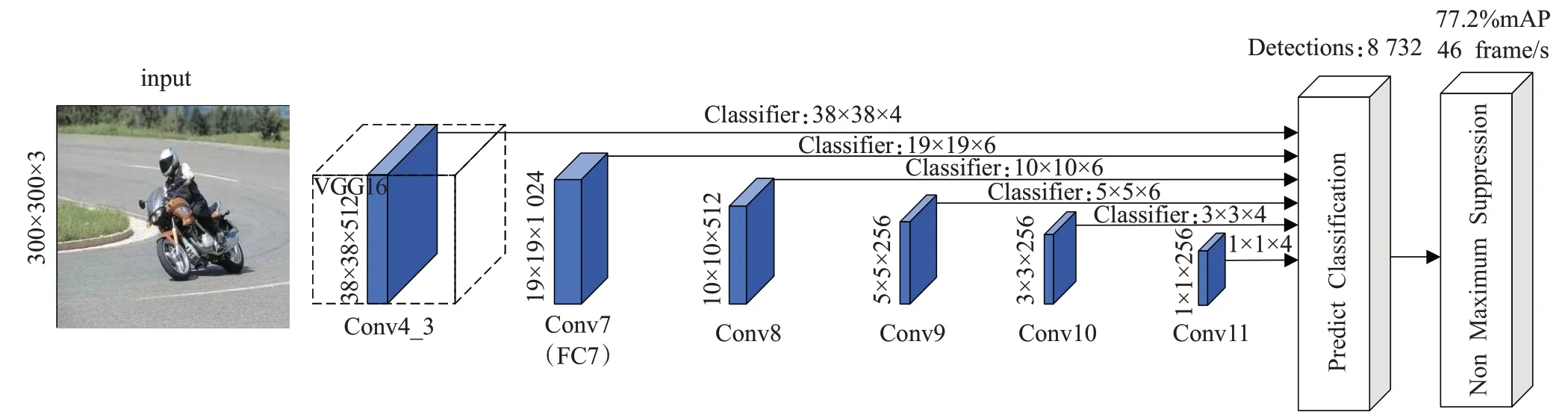
图1 SSD网络结构Fig.1 Network structure of SSD
SSD模型采用先验框机制,在特征图的每个单元格上设置不同长宽比的默认先验框。浅层特征图具有较小的感受野,包含了丰富的位置信息,能够准确地定位目标的位置,且分辨率大,像素点多,在每个像素点设置4个尺寸较小的先验框,适合检测尺寸较小的目标,但其语义信息表达能力弱,不利于目标的分类。深层特征图具有较大感受野,包含了丰富的语义信息,能够准确地对目标进行分类,且分辨率小,像素点少,生成的先验框尺寸较大,可以更好地对应尺寸较大的目标,适合检测大目标。
1.2 注意力机制
深度学习中的注意力机制从本质上讲和人类的选择性视觉注意力机制类似,核心目标是从众多信息中选择出对当前任务目标更关键的信息,能够有效提高感知信息处理的效率和准确性[15]。如今,将注意力机制应用在目标检测上的模型都取得了良好的效果。SENet[16]是经典的通道注意力机制,其通过学习信道之间的依赖关系,动态增强或者抑制各通道的特征,增强网络的表示能力。CBAM[17]结合空间和通道注意力机制,通过学习加强或抑制相关的特征信息,有效地帮助信息在网络传递。
自注意力机制是注意力机制的一个分支,它基于内部的相关性,依靠自身的输入生成注意力权重,减少了对外部信息的依赖。自注意力机制可以捕获特征图的全局信息,学习上下文间的相关性,获得更关键的特征信息,从而使网络能够更加准确高效地识别目标。Vaswani等[18]首次提出使用自注意力机制刻画输入和输出间的全局依赖关系,并将其应用于机器翻译。DANet[19]通过自注意力机制从全局视野自适应地整合了任何尺度的相似特征,将局部特征和全局的依赖性自适应地整合到一起。AFF[20]提出了注意力特征融合模块,将局部信道上下文添加到全局信道中,克服了输入特征之间的语义差异和尺度不一致问题。
2 提出的方法
SSD模型利用多尺度特征图进行多尺度预测,能够同时检测到不同大小的目标。但是,由于浅层特征图提取到的特征缺乏语义信息,导致SSD在检测小目标时会存在漏检和误检。为了有效地检测小目标,本文提出融入了特征增强和自适应特征融合策略的FA-SSD模型。该模型的整体网络结构如图2所示,其使用VGG-16作为主干网络,在SSD的基础上添加了一条自深向浅的递归反向路径,该路径将增强后的深层特征信息向前传递,采用递归的方式自适应地融合浅层特征图和上采样后的深层特征图,将深层的语义信息传递到浅层,使得浅层特征图能够同时利用浅层的强位置信息和深层的强语义信息。反向路径增加了模型对于小目标的感知能力,便于确定小目标的位置和类别,从而提升模型的小目标检测效果。该路径包含设计的三个模块:深层特征增强模块(deep layerfeature enhancement module,DEM)、上采样特征增强模块(up-sampling feature enhancement module,UEM)和自适应特征融合模块(adaptive feature fusion module,AFFM)。AFFM由串联的通道注意力模块(channel attention module,CA)和位置注意力模块(positional attention module,PA)组成。
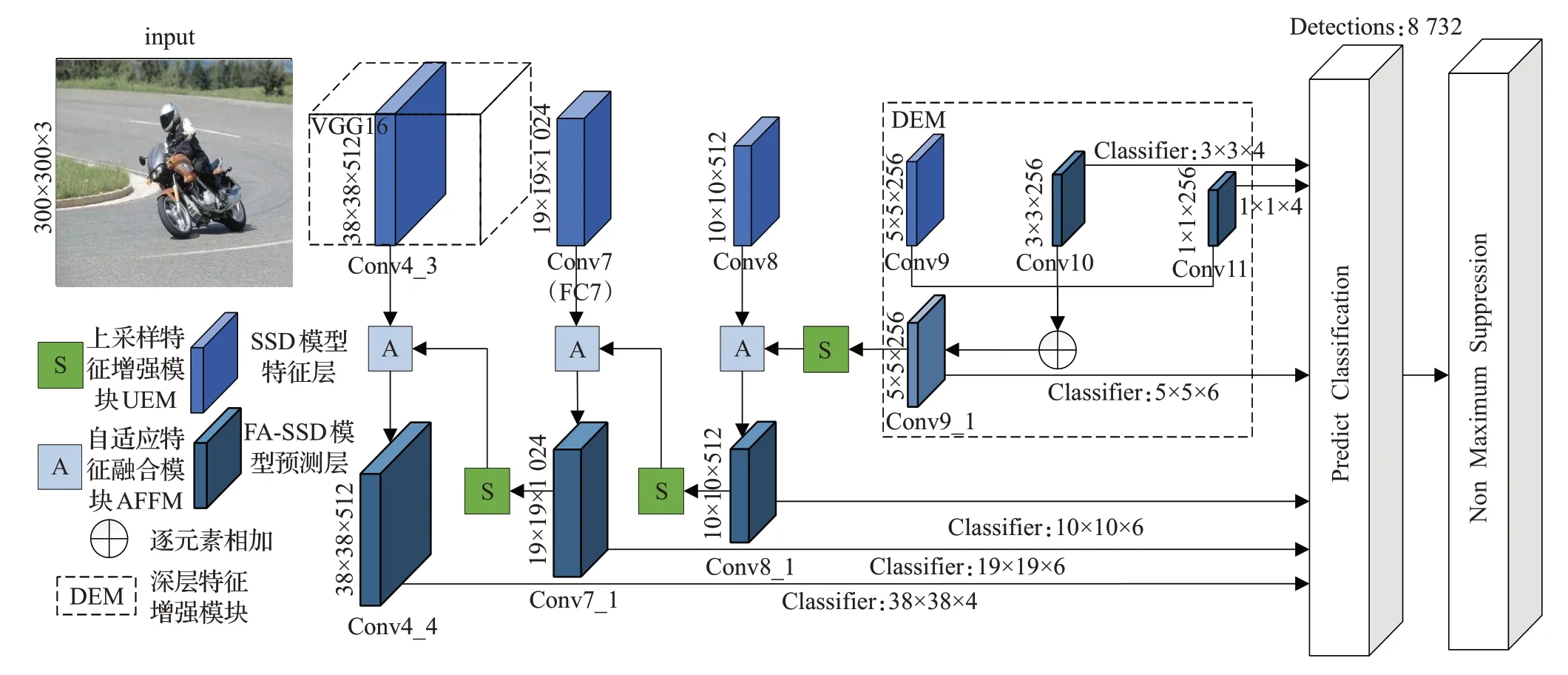
图2 FA-SSD整体网络结构Fig.2 Overall network structure of FA-SSD
2.1 深层特征增强模块
深度卷积网络在提取特征图信息时易丢失小目标的关键位置信息,使用目标的上下文信息可以指导定位区域的选择,提高检测准确率[21]。通常网络的最深层特征图仅包含单层的语义信息,导致浅层特征图通过反向路径获得的语义信息较少,不利于小目标的检测。为了增强深层特征的表达能力,本文设计了深层特征增强模块。DEM使用并行路径提取深层多尺度特征图的全局上下文信息和局部上下文信息,并融合最深层特征图的语义信息。全局上下文信息指整个场景的全局信息,有助于确定不同目标的准确位置,更好地解决局部模糊性问题;局部上下文信息指目标和周围部分的相互关系,有助于提高各个目标的分类准确率。
DEM结构如图3所示,Conv9-c包含使用3×3卷积在Conv9中提取的局部上下文信息;Conv9-g和Conv10-g分别包含使用全局平均池化(global average pooling,GAP)从Conv9和Conv10中提取的两个不同的全局上下文信息,同时使用可以使模型获得全面的全局信息;Conv11是SSD的最后一个预测层,包含了深层丰富的语义信息;Conv9_1是由Conv9-c和广播后的Conv9-g、Conv10-g和Conv11融合生成的,包含了全局上下文信息、局部上下文信息和深层语义信息。广播操作是对Conv9-g、Conv10-g和Conv11进行上采样,将三个1×1大小的特征图按照各个通道的值复制扩大为与Conv9-c维度相同的特征图。DEM通过结合深层多尺度特征图的上下文信息和最深层语义信息,增强了反向路径深层特征信息的可鉴别性,有助于确定目标的准确位置和提高目标的分类准确率。
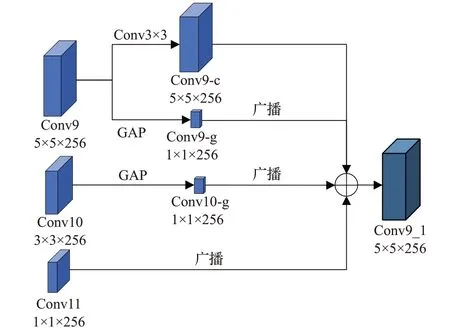
图3 深层特征增强模块结构Fig.3 Deep feature enhancement module structure
2.2 上采样特征增强模块
不同尺度特征图的分辨率不同,在进行特征融合前需对小尺寸特征图进行上采样操作。常用的上采样方法有最近邻插值算法和反卷积。最近邻插值法使用与填充位置最邻近的数字对其填充,导致图像出现明显的锯齿状;反卷积通过填充数字0扩大图像的尺寸,填充的是无效信息,导致特征图丢失了有效的语义信息。与传统的上采样方法不同,亚像素卷积(subpixel convolution)[22]通过多通道间重组的方式扩大特征图分辨率,能够将特征图不同通道中的特征重新排列组合为一个通道。在重组时使用的数字均来自特征图本身,不会产生无效信息干扰目标的检测,能够在提高特征图分辨率的同时保存更多的有效信息。亚像素卷积在数学上的定义为:
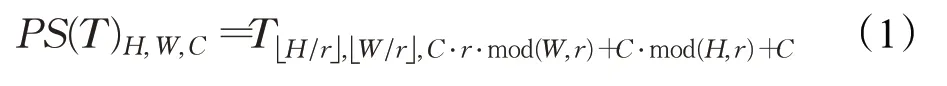
公式(1)中,PS表示将特征图从H×W×C·r2转换为r·H×r·W×C,H、W、C分别表示特征图的高度、宽度和通道数,r表示上升因子,T表示输入特征。
上采样后的特征图会丢失一部分特征信息,使用膨胀卷积(dilated convolution)扩大感受野,能够提取目标的上下文信息。但膨胀卷积无法对空洞部分进行采样,会导致提取到的信息不具有连续性。本模块设计的逐层并联的膨胀卷积,逐层并联了不同膨胀率的膨胀卷积。不同大小的感受野能够检测不同尺度的目标,小感受野的膨胀卷积可以提取小目标的位置细节信息,大感受野的膨胀卷积可以提取小目标上下文信息和大目标的深层语义信息。使用逐层并联的联接方式可以逐次拼接膨胀率相近的膨胀卷积,避免了因膨胀率相差过大带来的信息偏差,能够更好地填补膨胀卷积的空洞部分,增强提取到信息的连续性,提升网络对小目标特征的提取效果。
本文设计的上采样特征增强模块结合了亚像素卷积和逐层并联的膨胀卷积,扩大了特征图的分辨率和感受野,利用目标的上下文信息,增强了网络对小目标的敏感度。UEM分为3个部分:亚像素卷积层、特征增强层和连接层。其中,亚像素卷积层使用亚像素卷积进行上采样操作,调整特征图的尺寸大小,减少特征图通道数;特征增强层由三个逐层并联的膨胀卷积组成,膨胀卷积的膨胀率分别为1、3、5,其中膨胀率为1、3的膨胀卷积适合检测小目标的位置信息,膨胀率为5的膨胀卷积能够提供小目标的上下文信息。逐层并联不同感受野的膨胀卷积,能够交互多尺度的特征信息,增强特征信息的连续性;连接层将特征增强层输出的特征图通过级联(Concat)的方式连接起来,保留了不同感受野特征图的特征信息。
UEM结构如图4所示,首先将输入层Di+1输入到亚像素卷积层,使特征层分辨率扩大2倍的同时减少特征层4倍的通道数;然后将上采样特征图分为三路,通过逐层并联的方式经过膨胀率为1、3、5的膨胀卷积,得到三个感受野大小不同的特征图;最后通过拼接通道数的方式聚合三个特征图,并使用1×1卷积改变特征层的通道数,将其完全合并,生成分辨率扩大两倍通道数不变的特征图Si,其中Di+1是指FA-SSD自浅向深第i+1个预测层,Si是指FA-SSD自浅向深第i个UEM的输出层。
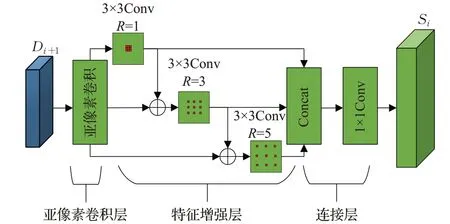
图4 上采样特征增强模块结构Fig.4 Up-sampling feature enhancement module structure
2.3 自适应特征融合模块
特征融合的常见方法是通过连接特征图的通道或者逐元素相加的方法来合并特征。逐元素相加可以在维度不变的情况下使特征图的信息量增多,且计算量小于级联。但由于多尺度特征图的感受野大小不同,导致特征信息存在差异,使用这些方式无法反映不同尺度下通道特征的相关性和空间特征的重要性,会导致混叠效应和位置偏移,从而混淆定位和识别任务。为了避免特征融合产生的冗余信息对检测结果带来的负面影响,本文提出了一个自适应特征融合模块。该模块利用自注意力机制学习特征图通道间的相关性和目标间的空间依赖关系,优先将更多的注意力放置在对当前任务目标有意义的关键信息上,自适应地调整逐元素相加后的特征图。
2.3.1 通道注意力模块
通道注意力模块若仅使用全局平均池化提取特征图的上下文信息,对不同通道进行权值重标定,可能会导致同一通道内关键特征和背景特征均分权重,削弱了小目标的特征。本文提出的通道注意力模块利用并行的全局平均池化和全局最大池化(global maximum pooling,GMP),提取不同的通道间全局信息。通过学习到的通道间依赖关系,能够有选择地更新通道的加权值。
CA结构如图5所示,首先将Ci和Si逐元素相加得到生成特征图Ni∈RH×W×C,其中,Ci为SSD模型自浅向深的第i个预测层,Si为FA-SSD模型自浅向深第i个UEM的输出层;其次,并行使用全局平均池化和全局最大池化生成了两个特征图Ni1和Ni2,{Ni1,Ni2}∈R1×1×C,分别提取了特征图各通道间的全局信息,可以分别表示为:
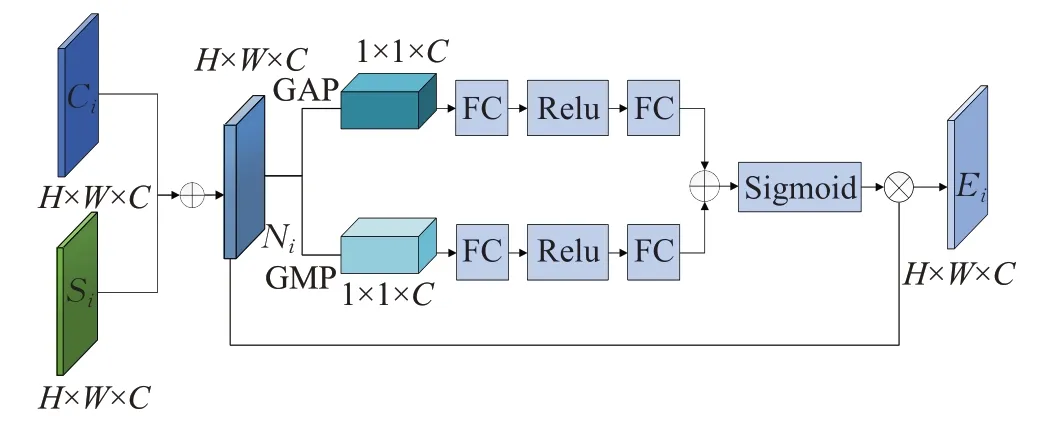
图5 通道注意力模块结构Fig.5 Channel attention module structure

公式(2)中的AvgPool()指全局平均池化函数,公式(3)中的MaxPool()指全局最大池化函数。
随后分别将特征信息传递到全连接层和Relu激活层,两个全连接层分别用来减少和增加通道的数量,Relu激活层则学习不同通道之间的非线性关系。然后,聚合两个不同的通道信息,并利用激活函数(Sigmoid)为每个通道生成权值集合,权重反映了通道之间的相关性,该过程可表示为:

公式(4)中CA()指通道注意函数,∂()指sigmoid函数,FR()指全连接层和激活层函数。
最后,将特征图Ni与通道权重逐元素相乘,得到通道注意力特征图Ei,该过程可表示为:

公式(5)中Ei指FA-SSD自浅向深第i个CA生成的通道注意力特征图。使用通道注意力模块,能够增强网络中有用的特征并抑制背景特征,减轻融合特征带来的混叠效应,从通道特征的角度关注目标。
2.3.2 位置注意力模块
通道注意力模块关注的是特征图中哪些通道更有意义,并没有考虑特征图上哪些部分更重要。本文提出的位置注意力模块,利用浅层特征图丰富的位置信息,提升了自注意力机制捕捉特征图任意两个位置间的空间依赖关系的能力。通过对重点位置特征的加权,有选择地聚合每个位置的特征。
PA结构如图6所示,首先将浅层特征图Ci和通道注意力特征图Ei级联,合并特征图的通道数,生成特征图Mi∈RH×W×2C,并经过两个并行带有BN层和Relu层的1×1卷积NJ和NK,生成两个特征图J和K,{J,K}∈RH×W×C;随后将J通过重塑(reshape,R)和转置(transpose,T)操作转为矩阵JT∈RC×N,将K通过Reshape操作转为矩阵K′∈RC×N,其中N=H×M;然后,将JT与K′进行矩阵乘法,生成相关矩阵:
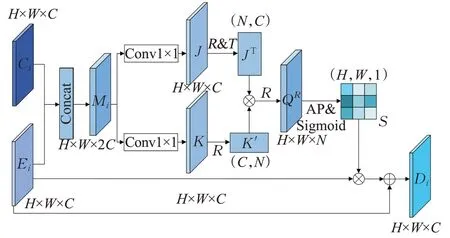
图6 位置注意力模块结构Fig.6 Positional attention module structure

公式(6)中,Q∈RN×N。随后对Q进行reshape操作转换为特征图QR∈RH×W×N,之后使用激活函数和平均池化(average pooling,AP),得到注意力矩阵S∈RH×W×1。最后,将生成的注意力矩阵S与Ei逐像素相乘后再逐元素相加,得到富含目标位置信息的位置注意力特征图:

公式(7)中,Di∈RH×W×C是空间注意力模块的输出,作为FA-SSD模型自浅向深的第i预测层。位置注意力模块旨在学习任意两个特征之间的关联,突出目标空间区域的重要性,能够增强深层特征图关键位置信息的表达能力。
3 实验与结果分析
3.1 数据集和评价指标
数据集:本文在目标检测领域数据集PASCAL VOC和小目标交通标志数据集TT100K[23]上进行实验。PASCAL VOC数据集,包含20个类别(加背景类21类),训练集为包含16 000图像的VOC2007和VOC2012,测试集为包含5 000图像的VOC2007。TT100K是一个交通标志检测和分类的数据集,该数据集包含10万张高分辨率图像和30 000个交通符号实例,其中物体大多数都是小物体,92%的实例的覆盖面积在整个图像中占比不超过0.2%,易被树木遮挡,受光照、天气条件影响严重,且场景复杂,是复杂场景小目标检测的优秀数据集。本文选择其中含有实例最多的20个类,训练集包含31 107张图片,测试集包含3 073张图片。
评价指标:本文遵循两个数据集定义的标准协议,在PASCAL VOC和TT100K两个数据集上,采用平均精度均值(mean average precision,mAP)和每秒传输帧数(frames per second,FPS)作为评价指标。平均精度均值为所有类别平均精度(average precision,AP)的平均值,用来评估模型的检测精度,如果预测框与真实框的交并比(IOU)大于0.5,则预测结果是正确的。每秒传输帧数评估模型的检测速度。
3.2 实验设置
本文实验使用随机梯度下降算法(stochastic gradient descent,SGD),初始学习率设置为0.000 35,前500次迭代学习率逐渐上升,促进模块的快速收敛,权值衰减为0.000 5、动量为0.9。实验中使用两种分辨率不同的输入。当输入图片分辨率的大小为300×300时,模型的批处理大小为设置为16,学习率在120 000和140 000次迭代时分别下降10倍,迭代180 000次得到最终的网络模型。当输入图片分辨率的大小为512×512时,模型设置批处理大小为8,学习率在140 000和160 000次迭代时分别下降10倍,迭代200 000次得到最终的网络模型。实验均在型号为NVIDIA RTX 2080Ti的显卡上进行。
3.3 算法性能分析与比较
3.3.1 PASCAL VOC数据集性能检测对比
为验证本文算法的有效性,将FA-SSD与目前先进的两阶段目标检测算法和单阶段目标检测算法进行对比,所有比较的方法均在PASCAL VOC2007和PASCAL VOC2012训练集上进行训练,在VOC2007测试集上测试,实验结果如表1所示。
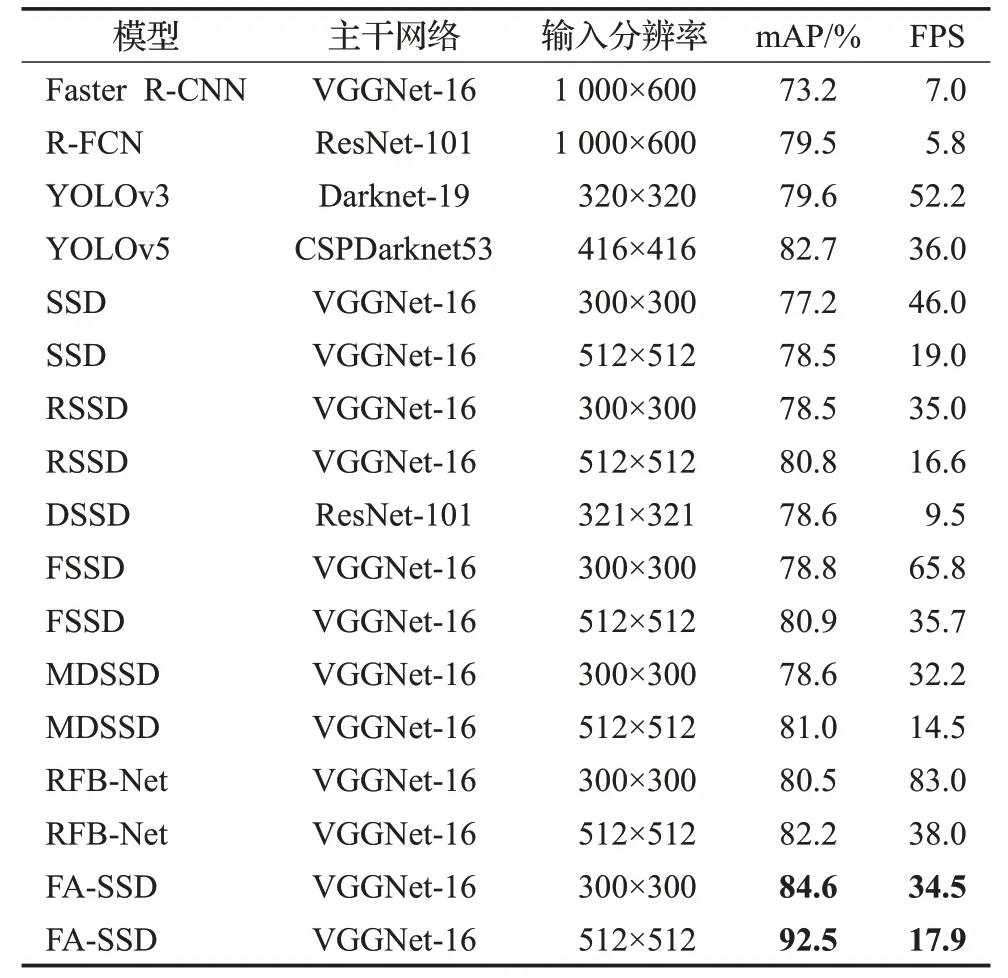
表1 不同算法在PASCAL VOC数据集性能对比Table 1 Comparison of performance of different algorithms in PASCAL
由表1可知,当输入图像分辨率大小为300×300时,FA-SSD的mAP可以达到84.6%,检测速度为34.5 frame/s。与两阶段的目标检测算法Faster R-CNN和R-FCN相比,FA-SSD的mAP提升了11.4个百分点和5.1个百分点,FPS提升了27.5和28.7,说明本文算法在检测准确率和检测速度上均优于两阶段算法。与YOLOv3和当前性能和运行效率均最优的YOLOv5相比,FA-SSD增强了浅层特征图的语义信息,mAP分别提升了5个百分点和1.9个百分点,说明本文算法的检测准确率优于目前先进算法,但由于增加了模型参数量导致检测速度有所下降。与SSD及其改进RSSD、DSSD、FSSD、MDSSD和RFB-Net相比较,FA-SSD的mAP提升了7.4个百分点、6.1个百分点、6个百分点、5.8个百分点、6个百分点和4.1个百分点,提升效果显著,证明通过添加反向路径增强浅层语义信息,能够提升模型检测小目标的效果。当输入为512×512时,FA-SSD的mAP为92.5%,检测速度为17.9 frame/s,与相同输入大小的SSD及其改进RSSD、FSSD、MDSSD和RFB-Net相比较,FA-SSD的mAP提高了14个百分点、11.7个百分点、11.6个百分点、11.5个百分点和10.3个百分点,说明当输入图像分辨率越大时,FA-SSD的检测效果提升得越明显。分析结果可知,本文提出的算法通过增强特征图的特征信息和自适应的融合特征,有效减少了小目标的漏检和误检,明显改善了小目标的检测效果。
表2展示了不同算法在VOC2007测试集上单个小目标类别的测试结果。实验证明,在输入图像分辨率大小为300×300时,FA-SSD检测帆船、瓶子和盆栽等小目标的检测效果明显优于其他检测算法。

表2 小目标类别不同算法测试结果Table 2 Test results of different algorithms for small target categories %
3.3.2 TT100K数据集性能检测对比
本文在TT100K数据集上,设置输入图片的分辨率大小为512×512。表3展示了本文算法和其他主流的目标检测算法在TT100K测试集的测试结果。由图3可知,FA-SSD的mAP达到80.2%,检测速度为13.6 frame/s,与YOLO系列的YOLOv3和YOLOv5相比分别提高了9.4个百分点和5.6个百分点;与相同输入大小和主干的SSD、RFB-Net和MDSSD相比分别提高了11.5个百分点、5.8个百分点和2.6个百分点与相同输入大小和主干的SSD、RFB-Net和MDSSD相比分别提高了11.5个百分点、5.8个百分点和2.6个百分点。,证明在SSD上添加自深向浅的递归反向路径,能够有效提高小目标的检测准确率。同时,与输入图片分辨率的大小均大于512×512的目标检测算法Faster R-CNN、Mask R-CNN和FPN相比,FA-SSD的mAP分别提高了27.3个百分点、9.4个百分点和10.3个百分点。实验结果证明,通过扩大感受野结合小目标周围的上下文信息,并自适应地融合特征图来增强特征信息,有助于复杂场景中缺乏信息的小目标更好地定位和分类,能够提升小目标检测的准确率。
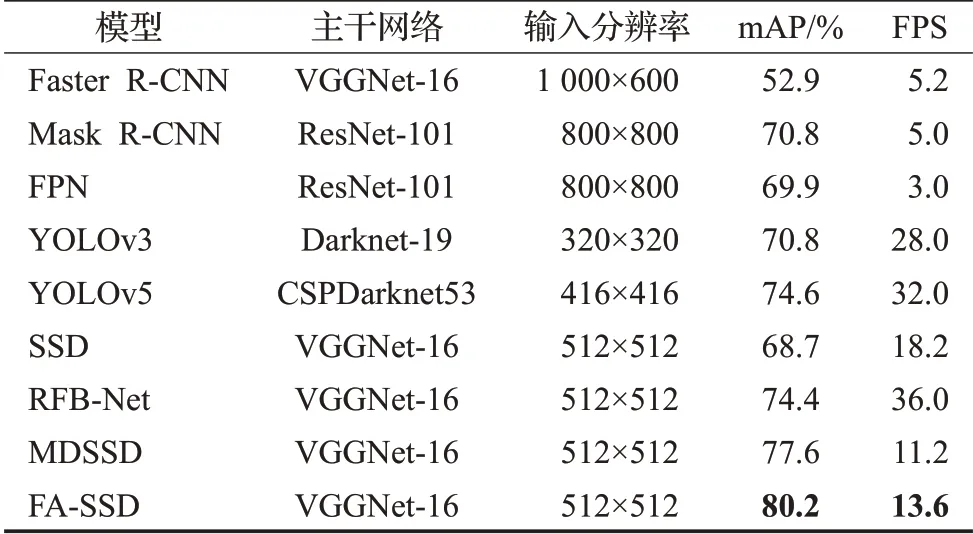
表3 不同算法在TT100K数据集性能对比表Table 3 Performance comparison of different algorithms in TT100K dataset
3.4 消融实验
为了证明FA-SSD在小目标检测上的有效性,本文选择在TT100K数据集上进行消融实验,在SSD模型上逐步添加深层特征增强模块(DEM)、上采样特征增强模块(UEM)和自适应特征融合模块(AFFM),并通过比较检测精度的差异,分析FA-SSD每个模块的性能。总体消融实验报告见表4。
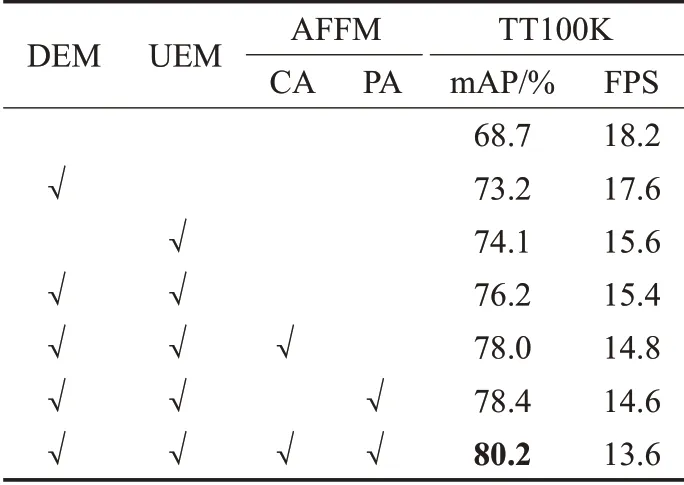
表4 消融实验结果分析Table 4 Analysis of ablation test results
为了验证DEM的有效性,本文设置实验以传统SSD为基线,在模型深层特征图单独添加DEM,增强了特征层的上下文特征信息,模型的mAP比SSD增加了4.5个百分点,FPS下降了0.6,证明了与单一特征图相比,融合的多尺度特征图包含了更多有用信息,对小目标检测有益,同时提取多种特征信息增加了少量的网络参数,降低了模型的检测速度。
为了验证UEM的有效性,设置实验在传统SSD上添加三个UEM,通过逐元素相加的方式将上采样的特征图和SSD预测层融合,生成新的预测层,单独添加时模型mAP比SSD模型提高了5.4个百分点;同时添加DEM和UEM时,模型的mAP比SSD模型提高了7.5个百分点,证明UEM使用膨胀卷积获得不同感受野的上下文信息,增强了浅层特征层的语义信息,提高了小目标的检测准确率。
为了验证AFFM的有效性,设置实验在添加了前两个模块的SSD模型上,首先仅添加CA并使用输出的通道注意力特征层作为预测层,模型的mAP比SSD模型提高了9.3个百分点,比添加前提高了1.8个百分点,证明了通道注意力模块可以缓解特征融合产生的混叠效果;接着仅添加PA并使用输出的位置注意力特征层作为预测层,模型的mAP比SSD模型提高了9.7个百分点,比添加前提高了2.2个百分点,证明位置注意力模块可以学习到小目标精确的位置信息;最后添加AFFM,模型的mAP达到了80.2%,比SSD模型提高了11.5个百分点,比添加AFFM之前提高了4个百分点,证明AFFM能够有效地进行特征融合,缓解特征图之间的信息不平衡问题。
3.5 定性分析结果
为了更直观地分析本文的检测结果,图7和图8分别可视化了当输入图像分辨率为512×512时,SSD和FA-SSD在PASCAL VOC数据集和TT100K数据集上的测试结果,图中第一行是SSD的检测结果,第二行是FA-SSD的检测结果。对比图7展示中的检测效果可知,SSD在分辨率低的目标上检测效果差,大部分小目标都没有检测出来,而FA-SSD能够检测到更多数量的小尺寸的人(图7中第二、四和五列)、船(图7中第一列)和盆栽(图7中第三列)。图8中的交通标志图像存在遮挡、光线变化和标志较模糊等情况,受此影响SSD在检测小目标时出现严重漏检现象,而FA-SSD则能够检测出更多的小尺寸交通标志且置信度较高,如图8中第一、二、三、四列图像中最右侧的蓝色交通标志,以及第五列图像的绿色交通标志。综上,FA-SSD可以检测到更多数量的小目标,降低了小目标漏检率,提高了小目标的平均准确率,具有更好的小目标检测效果。

图7 PASCAL VOC数据集可视化结果Fig.7 Visualized results of PASCAL VOC dataset

图8 TT100K数据集可视化结果Fig.8 Visualized results of TT100K dataset
4 结束语
针对浅层特征图缺乏语义信息带来的SSD小目标检测准确率低的问题,本文提出一种融合特征增强和自注意力的SSD小目标检测算法FA-SSD。该算法的核心思想是在SSD的基础构建一条自深向浅的递归反向路径,在此路径上利用深层特征增强模块增强深层特征信息的可鉴别性;通过上采样特征增强模块增强反向传递过程中特征图的语义信息;使用自适应特征融合模块自适应地融合深层语义信息和浅层空间信息,增强浅层特征图的语义信息,进而提高小目标的检测准确率。实验结果表明,该算法对于复杂场景下的有遮挡和不清晰的小目标,具有较好的检测效果。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
水利规划与设计(2020年1期)2020-05-25 08:01:34
开放教育研究(2020年2期)2020-03-31 01:54:14
铁道通信信号(2018年1期)2018-06-06 02:27:37
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
现代语文(2016年21期)2016-05-25 13:13:44
中国卫生(2015年1期)2015-11-16 01:05:58
大连民族大学学报(2015年2期)2015-02-27 08:28:11
浙江伦理学论坛(2014年0期)2014-03-01 02:48:48
