
小样本下基于Wasserstein距离的半监督学习算法
2022-04-09 07:04:40马幪浩
计算机工程与应用 2022年5期
马幪浩,王 喆
华东理工大学 信息科学与工程学院,上海 200237
越来越多的机器学习模型,包括神经网络,开始关注最大化小样本条件下的未标记数据的效用。这些未标记数据独立同分布地从与有标记数据相同的数据源中采样,旨在帮助模型提高性能[1-3]。做出数据假设,例如流形假设和平滑假设,能够更好地利用未标记数据的隐含数据分布信息,因此是半监督学习中不可或缺的处理步骤。利用数据假设的生成方法通常假设所有数据都是由一个潜在数学模型生成,然后使用基于期望最大化算法的最大似然估计来解决问题[4-5]。然而,依赖没有先验知识的模型假设并不总是可靠的。半监督支持向量机和基于图的方法在过去的几十年里已经得到了广泛的研究。前者是一个混合整数规划问题,依赖于低密度分离假设[6-8]。后者必须解决复杂图规模和传播造成的大量开销[9-11]。基于分歧的方法在半监督学习中同样扮演着重要角色,有理论证明,当两个视图充分且条件独立时,分类器的泛化性能可以被未标记样本提升到任意高。当然,由于对视图和分类器的严格要求,这通常相当困难。基于分歧的方法依靠扰动来有效地调节模型的中间表示和输出,将模型预测训练成与在扰动下的预测一致。Särelä等[12]提出了一种框架,称为去噪源分离(DSS),决策支持系统在他们提出的框架中围绕去噪过程构建源分离算法。Ladder Network[13]利用无监督部分来补充监督部分。它产生噪声预测和干净预测,然后应用来自决策支持系统的去噪层从噪声预测中预测干净的预测。Cheng等[14]提出了一种保持多样性的协同训练算法。该方法在标记未标记数据的过程中不使用类别分类器,而是使用属性分类器对其进行凸聚类标记。Π模型[15]训练网络在相同输入的多个增强上保持一致,Mean Teacher[16]通过使用平均模型权重构建教师模型来改进Π模型,以将时间集成扩展到大数据集和在线学习。从贝叶斯的观点来看,一个好的模型应该适应各种不改变样本性质的扰动,即学习到扰动下的不变性以平滑输出。然而,这些方法有一个严重的缺点:强制一致性导致的神经网络崩溃,强制平滑使网络学习到最后过于相似。为了缓解这个挑战,Qiao等将多个深度神经网络训练成不同的视图,并使用对抗样本来实现视图差异[17]。后来的Tri-net[18]观察到深度协同训练中两个网络的局限性。因此,他们考虑在三个不同的网络下同时进行模型初始化、多样性增强和伪标签编辑。但是由于tri-net使用了额外的网络进行训练,因此具有较高的时间成本。
1 方法
1.1 方法概述
本文提出了一种半监督学习方法WCT,WCT首先最小化两个网络在无标记数据集上的预测之间的Jensen-Shannon散度来建模协同训练,同时在有标记数据上强制一致性输出,并不断为无标记数据分配伪标签,将半监督问题转化为监督问题。由于训练约束鼓励两个网络对有标记数据与无标记数据都做出类似的预测,这会导致神经网络崩溃,因为训练两个相同的模型不是有益的。为了防止协同训练的两个网络相互碰撞,WCT之后通过快速梯度符号攻击施加的对抗攻击来生成对抗样本以鼓励视图的差异,最后将Wasserstein距离作为网络视图差异约束的度量,以防止深度神经网络相互崩溃,使网络在低维流形空间上平滑输出。本文所提方法的整体框架如图1所示。
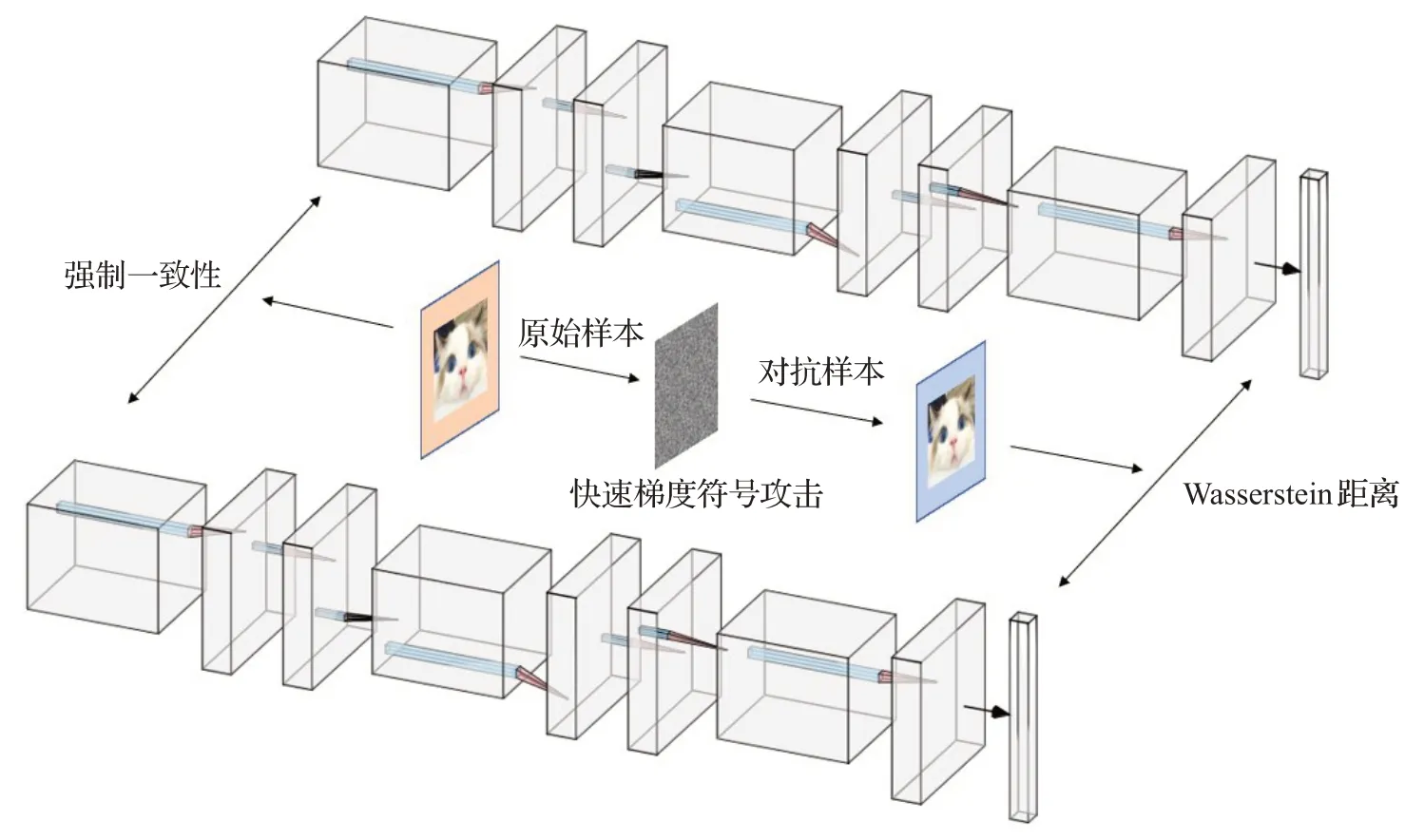
图1 WCT方法模型框架Fig.1 Framework of WCT model
1.2 Jensen-Shannon散度假设
本文首先学习由伪标签标记未标记数据产生的确认偏差的判别表示。然而,获取这样的表示并不容易,因为由模型生成的标签很可能是不正确的,并且可能导致伪标记样本具有错误的类别而阻止了新信息的学习。伪标签不能100%正确地反映真实标签。因此,实现本文策略的关键是平衡标记样本和伪标记样本之间的权重。随着分类网络的更新,伪标记数据的权重需要更新,以使网络的训练指向正确的方向。方法总体的目标函数是:

其中,α(t)是平衡目标函数的超参数。使用伪标签实现以激活进入饱和区域的方式来规范网络。这个过程相当于熵正则化,并促进了训练过程中表示的不变性或鲁棒性。伪标签也有助于类之间的低密度分离。本文将利用Jensen-Shannon散度假设来改进方法的训练。首先,在监督数据集上使用标准交叉熵损失:

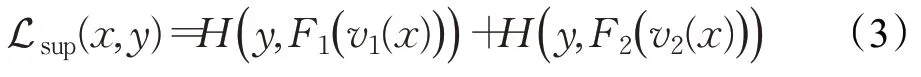
其中,H(p,q)是分布p和q之间的标准交叉熵,y是分布输入x的标签。在标准交叉熵损失下,通过从初始标记数据集构造监督学习部分。
对于未标记集合U中的x,最小化两个网络的预测分布之间的Jensen-Shannon散度,可以将其定义如下:
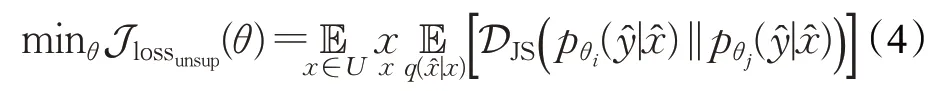
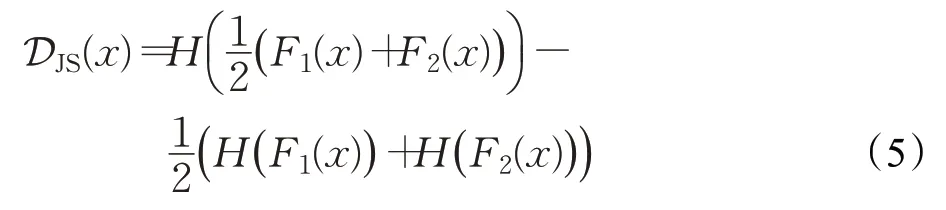
然而,通过直接使用Jensen-Shannon散度假设的协同训练过程会造成一个严重的问题:两个分类网络会在协同训练的过程中越来越相似。本文使用了不同的噪声和数据扩充来维持网络之间的多样性,而长时间的训练下网络间的差异性是不稳定的,容易出现网络的相互碰撞。在接下来的部分中,本文将在训练网络的过程中施加网络差异约束,通过对抗样本和Wasserstein距离来构建更好的网络。
1.3 对抗样本生成
本文的目标是以高精度标记样本,通过Jensen-Shannon散度建模协同训练得到了两个精确的分类网络,并且更有效率地利用了小样本条件下的有标记数据,之后通过伪标记无标签数据为模型带来了更大的改进。然而为了更好地指导这两个分类网络的学习,必须考虑到它们会越来越相似,因为它们都是从相同的数据训练得到。这是基于分歧的方法无法避免的问题。
为了防止F1网络和F2网络在训练中无限接近而导致的相互碰撞,本文建立了Wasserstein距离下的网络差异约束来解决这个问题。深度网络中一个众所周知的缺点是卷积神经网络特征经常被用作欧几里德距离的空间来近似感知距离。如果具有不可测量的小的感知距离的图像对应于网络表示中完全不同的类别,这种相似性将导致灾难性的后果。利用这一特点,通过快速梯度符号法生成对抗样本。主要利用对抗样本和Wasserstein距离来推动F1网络和F2网络分开。
神经网络易受对抗性扰动影响的主要原因是其线性性质。高维空间中的线性行为足以生成对抗样本。本文应用这种技术作为生成模型来生成对抗样本[19-22]。对于一个样本,生成它的对抗样本,这些对抗样本是通过对原始样本施加小而有意的扰动而形成的:

其中,θ表示模型的参数,y是输入样本x的标签或伪标签,δ是最坏情况扰动,||δ||p是ℓp-范数距离度量δ。之后计算生成对抗样本:
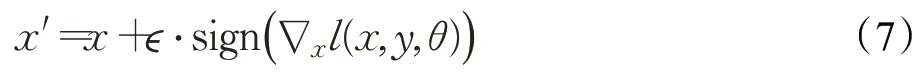
其中,l(θ,x,y)是损失函数。将扰动添加到梯度中,沿着梯度反向传播,以可靠地生成网络差异约束所需的对抗样本。这些对抗样本与原始数据样本非常接近,肉眼无法区分,但神经网络会对其所属类别做出完全不同的判断。
1.4 Wasserstein距离
上述协同训练成功的关键条件是两个网络的不同,在本文的建模中,使用了Jensen-Shannon散度假设使两个分类网络对无标签数据做出相同的预测。其次,在有监督部分,有标签数据使两个网络的训练向正确的方向收敛。这种强制一致性的方法可能会带来一个严重的问题:不能保证两个网络提供的视图是不同和互补的。只有在两个分类网络提供不同且互补视图的情况下,协同训练才是有益的,因为训练两个相同的分类网络是没有意义的。当无法保证这一点时,两个分类网络不再基于分歧,而是会不断趋于相似并碰撞。本文使用了对抗样本和Wasserstein距离来施加网络差异约束以防止深度神经网络的碰撞。
本文通过快速梯度符号攻击方法生成对抗样本,由于图像的分布可以看作高维空间的低维流形,原始样本和对抗样本在高维空间的分布重叠可以忽略,这带来一个问题,使用传统散度作为距离度量的情况下,距离值可能为常数,无法实现对样本距离的有效度量。本文引入了新的衡量分布差异的方法——Wasserstein距离。使用Wasserstein距离度量F1网络对于原始样本的预测和由F2网络生成的对抗样本的预测的距离,以控制两个网络不会相互碰撞,距离评价方法为:

其中,F(x)代表两个网络对样本x的预测输出F∈1-Li pschitz约束着网络的平滑输出,使网络对于原始样本的预测和其协同训练网络对抗样本的预测不会无限放大导致训练无法收敛。对于Lipschitz函数的约束实现,约束F(x)的梯度,因为F(x)是受限于1-Lipschitz,那就表示对于所有的x,有:

其中‖∇x F(x)‖为F(x)的梯度,在上述近似下,距离度量等价于:
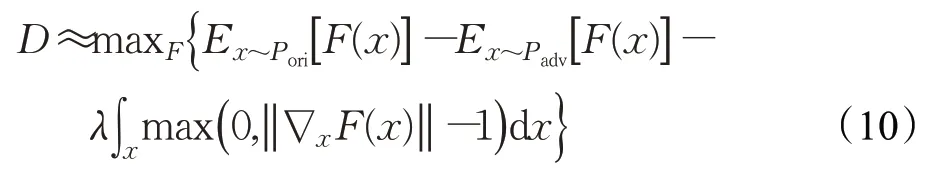
实际上,不能保证对于所有样本x都能施加上述约束。因此上式使用梯度惩罚进行等价转换:

其中,Ppenalty为原始样本和对抗样本中间区域的采样分布。参数是通过F(x)梯度进行更新,中间区域即为更新的方向。但是在实际实验策略下,直接使用max(0,‖∇x D(x)‖-1)进行惩罚过于直接,对于上式的梯度惩罚进一步优化为:
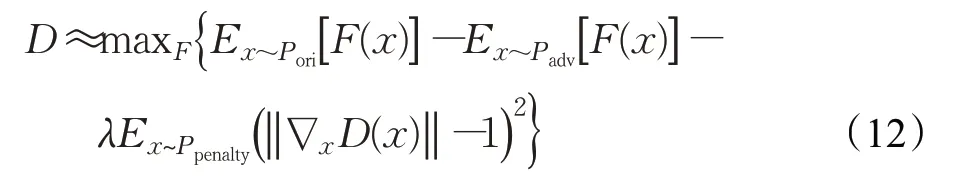
对抗样本可以作为正则化技术来平滑输出,收紧决策边界以抵御对抗攻击。本文通过使用网络对原始样本和对抗样本的预测差异约束协同网络以维持多样性,鼓励网络对其协同训练网络的对抗样本施加距离约束。
2 实验设置与结果
2.1 实验数据集
本文在MNIST、CIFAR-10和CIFAR-100三个公开数据集进行了相关实验与讨论。MNIST数据集是真实的手写图像数据集。它包含60 000张灰度训练图像和10 000张大小为28×28的测试图像。CIFAR-10是由10个类别的60 000个32×32的彩色图像组成,每个类别有6 000个图像。它有50 000张训练图像和10 000张测试图像。CIFAR-100类似于CIFAR-10,它包含100个类,每个类包含600张图像。每个类别有500张训练图像和100张测试图像。在本文实验中,为CIFAR-10使用了50 000张训练图像中的4 000张有标签的图像。对于CIFAR-100,使用50 000张训练图像中有标签的10 000张图像。对于测试部分,10 000张测试图像全部用于测试两个数据集。
2.2 网络架构
为了进行公平的比较,本文采用了深度半监督学习中通用的网络框架,如表1所示。其他半监督方法对该网络体系结构进行了或多或少的调整,例如使用不同的卷积核大小、不同的残差块和不同的深度,本文不会像其他方法那样改变体系结构。

表1 网络框架Table 1 Network framework
2.3 实验设置
在本文的实验中,最大训练轮数在CIFAR-10和CIFAR-100中设置为600轮,在MNIST中为100轮。在最初的80轮训练中,对平衡系数进行了预热。更具体地说,逐渐增加无监督部分的平衡系数α(t)=α(t)max·exp(-5(1-T/80)2),其中α(t)max=10。实验中使用动量为0.9,权重衰减为0.000 1的SGD。对于学习速率,本文考虑对每个批次进行余弦退火,如下所示:
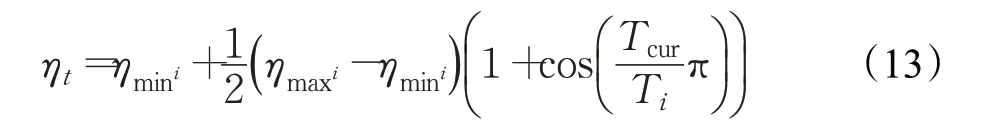
在本文的工作中,T是实验中的训练轮数,设置ηt=0.05×(1.0+cos((T-1)×π/600))。实验还使用了Batch Normalization和Dropout(p=0.5)。考虑了输入图像的随机平移和水平翻转,以及数据集输入层上的高斯噪声,batch size设置为100。
2.4 实验结果
为了公平比较,本文只报告所提模型的平均性能,即使在整个训练过程中有性能更好的模型输出结果,本文也不会集成方法的模型,另外本文也不使用预先训练好的模型。将所提方法与其他有代表性的半监督学习方法进行了比较:包括Ladder network、GAN[23]、CatGAN[24]、Improved GAN[25]、Triple GAN[26]、Πmodel、Temporal ensembling和Mean Teacher。本文方法优于其他代表性的方法。
在表2中,展示了在MNIST和CIFAR-10上的实验的主要结果。对于MNIST,本文仅仅使用了100个标记数据,CIFAR-10使用了50 000张中随机挑选的4 000张图像作为标记数据。总体而言,本文所提方法在这两个数据集的错误率指标上均排名第一。详细地说,在所有比较的方法中,在MNIST数据集中的改进是有限的。所提方法的错误率仅有0.85%。但是,所提方法在更有挑战性的CIFAR-10数据集上比其他方法好得多。在这种情况下,它获得了错误率仅有11.96%的最佳结果。对于其他比较方法,CatGAN、Improved GAN、Triple GAN都相对于GAN具有一定的提升,但是它们都缺乏明显的优势。基于扰动的三个方法:Πmodel、Temporal ensembling和Mean Teacher,作为最著名的半监督的学习方法,在CIFAR-10数据集上都获得了明显高于其他方法的结果。Ladder network似乎很难通过有限的数据来拟合监督部分和非监督部分,与其他方法相比,Ladder network的性能相对较差。

表2 MNIST和CIFAR-10上方法的错误率Table 2 Error rates of methods on MNIST and CIFAR-10%
表3展示了CIFAR-100上的方法结果。CIFAR-100是深度半监督学习领域的一个难点数据集,包含100类图像。从表3的结果可知,本文所提方法在使用数据增强与不使用数据增强两个实验中都有了一定的准确率上的提升,在不使用数据增强的条件下,相较于Πmodel提升了0.76个百分点。在使用数据增强的条件下,分类错误率为38.44%,相较于Πmodel和Temporal model分别提升了0.75个百分点和0.21个百分点。在标记数据更少的情况下,使用仅仅2 500个标记数据时,所提方法通过更复杂的预训练、网络框架的微调和输入增强方法,可以具有更好的性能。这些结果证明了所提方法的有效性。
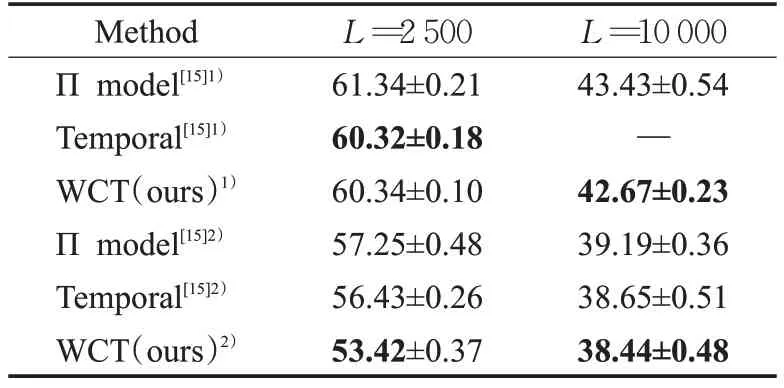
表3 CIFAR-100上方法的错误率Table 3 Error rates of methods on CIFAR-100%
2.5 扰动依赖分析
所提方法通过对两个分类网络在扰动下进行强制平滑来学习扰动下的不变性以提升泛化性能。这实际上是一种隐式的自集成,这种策略依赖于扰动来维持训练过程。为了正确探索不同扰动带来的效果,本文设计了消融实验来检测本文的训练策略是否对扰动敏感。在每个实验中,只移除噪声,增强和dropout中的一项,并计算每个设置下的五次运行的平均值。结果如图2所示。可以看到,在每种情况下,在所有实验数据集上,移除不同扰动都会给性能带来较为显著的下降。
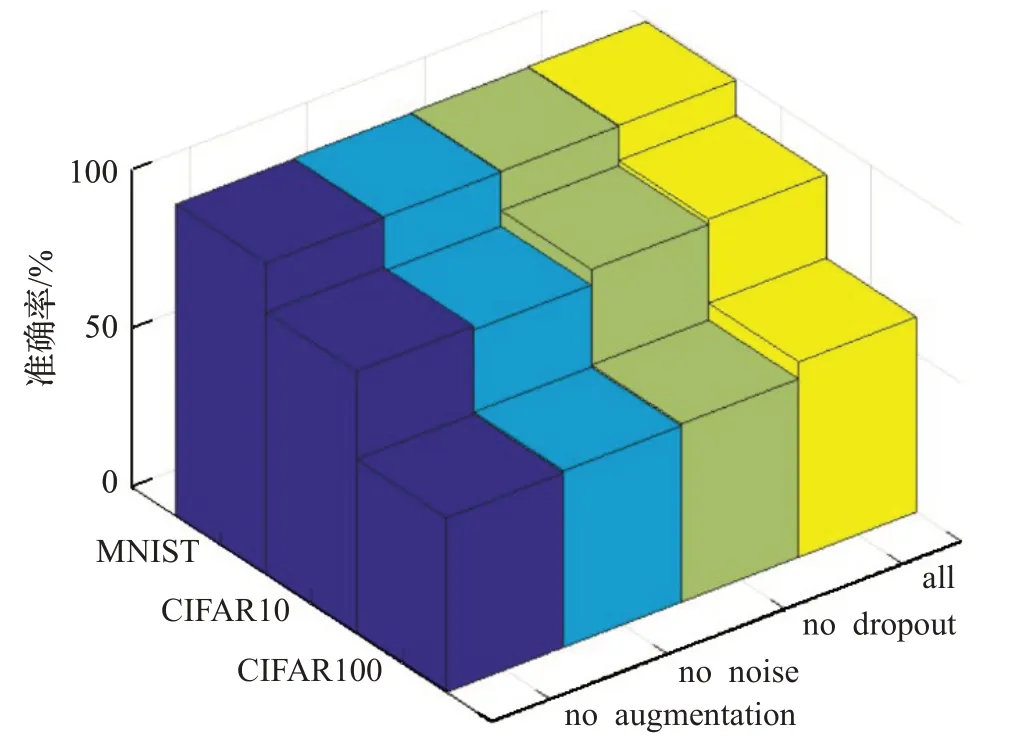
图2 消融策略Fig.2 Ablation strategy
2.6 时间复杂度分析


2.7 超参数分析
WCT依赖于两个关键超参数:平衡目标函数中有监督和无监督权重的α(t),以及对1-Li pschitz约束进行等价转换时的λ。为了更好地探究所提方法对超参数的敏感性,在CIFAR-10上进行了4 000个有标签数据的验证实验,一次改变其中一个超参数,同时保持其他所有参数变量不变。统计了训练不同时期下的实验结果,结果如图3所示。
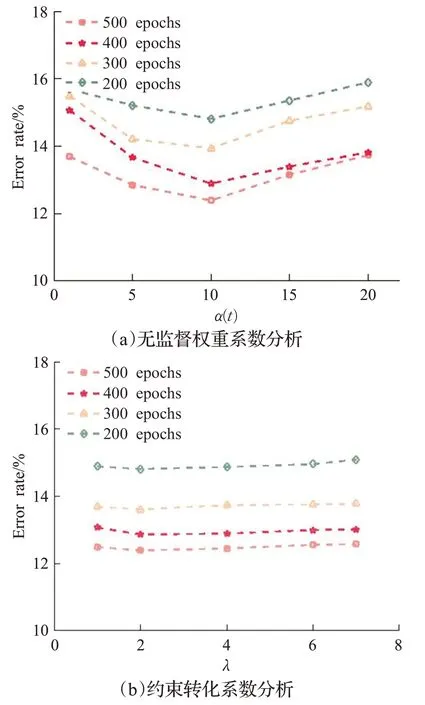
图3 超参数评估Fig.3 Hyperparameter evaluation
对于α(t),本文使用的方案是不等权分配。首先给伪标签数据分配一个较低的权重,在训练的早期阶段,有标签数据的权重占主导地位。随着训练的进行,伪标签数据的权重逐渐增加。在改变α(t)最大值的情况下可以看出,标记样本和伪标记样本之间的训练平衡对于网络性能至关重要,在α(t)取值为10时模型性能最优,良好的取值在5到15之间,范围之外的取值为导致性能的迅速降低。对于实现约束转换的λ,可以看出在不同训练时期时WCT性能对λ均不敏感,模型性能只会随着λ的改变轻微波动。这也证明了使用梯度惩罚进行等价转换的鲁棒性。
3 结束语
本文提出了一种小样本条件下的半监督学习方法WCT,通过聚集充分的视图信息,并将其集成到一个鲁棒的训练中,实现防止网络崩溃和提高分类泛化性能。首先通过Jensen-Shannon散度来模拟协同训练,使用一致性增强鼓励两个分类网络做出相似的预测,再利用对抗攻击生成的对抗样本,在Wasserstein距离下构造网络差异约束,以保持协同训练网络之间的多样性,从而实现稳健的训练过程。为了验证该方法的有效性,本文在常用的图像分类数据集MNIST、CIFAR10和CIFAR100中开展了相关实验研究,实验结果验证了本文所提方法的优秀性能。
本文首次使用Wasserstein距离作为强制一致性平滑下的网络距离控制,这种策略很容易训练两个差异化的网络。如何防止协同训练的网络相互崩溃是基于分歧的半监督学习未来有趣的研究方向。
猜你喜欢
中学生数理化·高一版(2021年2期)2021-03-19 08:32:00
人大建设(2020年4期)2020-09-21 03:39:12
车迷(2018年11期)2018-08-30 03:20:32
知识经济·中国直销(2018年8期)2018-08-23 09:16:16
海峡姐妹(2018年3期)2018-05-09 08:21:02
人大建设(2017年2期)2017-07-21 10:59:25
数学学习与研究(2017年3期)2017-03-09 18:12:42
人大建设(2017年9期)2017-02-03 02:53:31
公民与法治(2016年10期)2016-05-17 04:12:58
中国老区建设(2016年1期)2016-02-28 09:32:00
