
基于Jetson Nano+YOLO v5的哺乳期仔猪目标检测
2022-04-07 13:56丁奇安刘龙申沈明霞
农业机械学报 2022年3期
丁奇安 刘龙申 陈 佳 太 猛 沈明霞
(1.南京农业大学工学院, 南京 210031; 2.南京农业大学人工智能学院, 南京 210031;3.江苏智慧牧业装备科技创新中心, 南京 210031)
0 引言
我国养猪业向规模化、集约化发展,生猪养殖产业总产值在整个畜牧业所占比重最高[1]。将人工智能技术引入生猪养殖管理,有利于实现精细化养殖,提高生产质量与动物福利[2]。哺乳期作为猪只生命周期的第一阶段,能够影响猪只后续生长状态,实现智能化仔猪目标检测能够为进一步探究猪只个体行为,例如躺卧[3]、爬跨[4]、攻击[5]、采食[6]、饮水[7]、运动[8]和个体跟踪[9]等任务奠定技术基础。
采用形态学[10-11]方式进行仔猪目标检测对设备要求低,但仔猪目标为非刚性,易产生尺度和形态变化,因此需要为目标个体添加人工标记来保障检测的精度,导致该类方法不易在规模化猪场进行推广。而基于深度学习[12-15]的方法能够解决复杂环境下多尺度仔猪目标检测问题,逐渐成为该领域的研究热点。高云等[16]通过卷积神经网络构建仔猪识别模型PigNet,实现群猪图像分割,准确识别猪只个体;王浩等[17]对Faster R-CNN结构进行改进,通过识别猪只目标建立猪只圈内位置识别算法;沈明霞等[18]利用YOLO v3网络,实现对初生仔猪目标的实时检测。高云等[19]提出基于双金字塔网络的RGB-D群猪图像分割方法。基于深层卷积神经网络的仔猪目标检测算法,无论是检测精度还是速度都较传统机器学习算法有所提升,但是对硬件算力的依赖,限制了其在实际养殖生产中的应用与推广。
边缘计算模式具有分布式、高效率、低延时和低成本等特点[20]。随着规模化猪场的不断发展,哺乳期仔猪数量也会持续增长,将数据处理任务分布式部署至养殖系统中靠近设备侧,减轻数据中心的计算压力、保障数据安全至关重要。采用边缘计算模式的难点之一是如何优化模型结构,使算法能够在低算力设备上运行。
本文采用YOLO v5网络训练哺乳期仔猪目标检测模型,Jetson Nano开发板作为部署载体。其具有嵌入式端的GPU模块,能够更好地完成深度学习模型推理。将训练后的模型进行剪枝与量化,使得模型推理速度加快,形成能够在嵌入式端部署并精确检测目标的深度学习算法模型,实现哺乳期仔猪目标检测任务在边缘端的数据处理,使系统的部署更加灵活,满足不同规模的猪场需求,为构成适用于畜禽养殖领域的边缘计算模式奠定基础。
1 数据采集与预处理
实验数据采集于江苏省靖江市丰园生态农业园有限公司。选择两间面积同为7 m×9 m的母猪产房,每间产房有6个2.2 m×1.8 m的分娩栏,每个分娩栏中配有1个分辨率为2 048像素×1 536像素的海康威视(DS-2CD3135F-l型)摄像头,对分娩栏内的母猪进行俯拍,拍摄高度为3 m。视频采集时间为2017年4月24日—5月31日。
对视频进行截图,截图速率为1 f/s,截图完成后剔除数据集内异物遮挡严重以及相似度过高的图像,并保持夜间图像与白天图像数量一致,共计14 000幅图像。将图像缩放至500像素×375像素以减少内存占用,采用开源软件LabelImg对图像进行标注,标注格式为PASCAL VOC数据集标准[21],并按8∶1∶1将标注好的数据随机分配为训练集、测试集和验证集,图像中的仔猪数量范围为0~15,包括1 000幅无仔猪存在的母猪图像。采用Mosaic数据增强方式,在数据输入网络前进行随机缩放、随机裁剪和随机排布,图像的处理效果如图1所示。

图1 Mosaic数据增强效果Fig.1 Data augmentation effect by Mosaic
2 仔猪目标检测模型优化与部署
2.1 YOLO v5算法
受产房环境和哺乳期仔猪个体表征因素影响,哺乳期仔猪目标检测任务需要综合考虑检测精度与速度,而one-stage网络能够在检测过程中同时输出类别的锚框与概率,因此更加适合该任务场景。YOLO v3[14]能以3倍的推理速度取得与SSD相近的检测结果,YOLO v5比YOLO v3、YOLO v4[15]在检测速度与检测精度上有了进一步提升。所以本文基于YOLO v5算法进行优化,完成哺乳期仔猪目标检测模型的嵌入式端部署,YOLO系列模型进行仔猪目标检测的主要过程如图2所示。

图2 哺乳期仔猪目标检测流程Fig.2 Process of object detection for suckling piglets
将一幅图像分成n×n网格(grid cell),如果某个目标(object)的中心点落在网格中,则该网格就负责预测这个目标。每层网络预测边框(Bounding box)的位置信息和置信度(confidence)信息,一个边框对应4个角点位置信息和1个置信度信息。
2.2 模型构建
模型的结构主要分为Input、Backbone、Neck和Prediction共4部分。Input为仔猪图像输入环节、Backbone主要实现仔猪图像特征提取、Neck主要实现仔猪图像特征融合、Prediction主要实现仔猪目标预测,主要结构如图3所示。
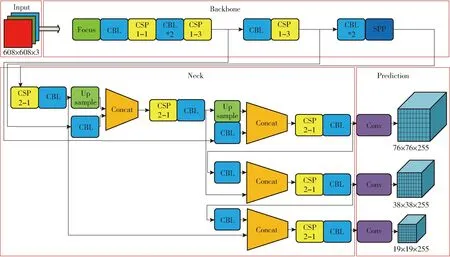
图3 YOLO v5主要结构图Fig.3 Main model structure diagram of YOLO v5
通过在Backbone结构中增加Focus结构与CSP结构,增强卷积神经网络(CNN)的学习能力,能够在轻量化的同时保持准确性。Focus的主要操作为图像切片操作,能够进一步提取仔猪目标特征,切片操作示意图如图4所示。
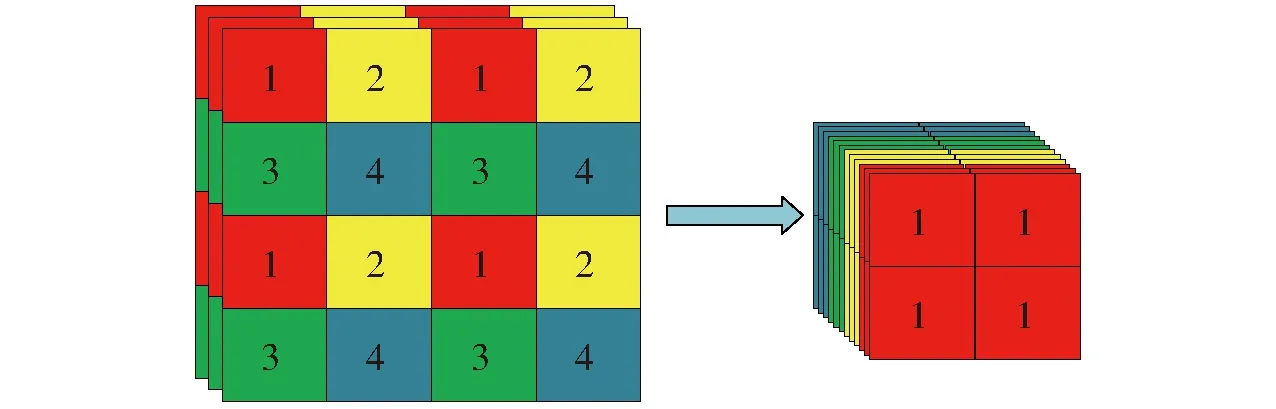
图4 切片操作示意图Fig.4 Operation schematic of slicing
在损失函数部分,主要计算3类损失函数,边框损失(Bounding box loss)、类间损失(Class loss)和目标损失(Object loss)。YOLO v5采用GIoU 损失值(Generalized IoU loss)作为Bounding box的损失函数,但哺乳期仔猪目标容易受到遮挡干扰,为提高模型对受遮挡仔猪目标的检测性能,将GIoU损失值替换为更加适合遮挡目标检测的CIoU损失值(Complete IoU loss)[15]作为边框损失的损失函数,CIoU损失值计算公式为
(1)
其中
(2)
(3)
(4)
式中LCIoU——CIoU损失值
A——预测框B——实际框
ρ——欧氏距离p——预测框中心点
pgt——目标框中心点
c——框之间的最小外接矩形的对角线距离
α——权重函数
IoU——预测框与实际框的交并比
ν——宽高比度量函数
w——预测框的宽h——预测框的高
wgt——目标框的宽hgt——目标框的高
类间损失采用交叉熵损失函数(Binary cross entropy loss,BCEloss),BCEloss计算式为
l(x,y)=L=∑(l1,l2…,lN)
(5)
其中
lN=-ω[ynlgxn+(1-yn)lg(1-xn)]
(6)
式中l(x,y)——交叉熵损失函数
lN——单批样本交叉熵损失值
N——一次训练的样本数
xn——第n次输入的预测值
yn——第n次输入的实际值
ω——相关系数,取值为1/N
object loss采用BCElogitsloss(Binary cross entropy with logits loss),即在BCEloss的基础上结合sigmoid函数,将式(6)变为
lN=-ω[ynlgS(xn)+(1-yn)lg(1-S(xn))]
(7)
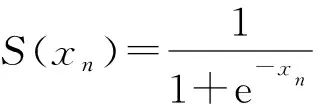
(8)
式中S(·)——sigmoid函数
由于哺乳期仔猪为非刚性目标,易产生多尺度边框,因此采用自适应锚框计算方式[15]。
2.3 模型迁移
2.3.1模型优化
通过CSP结构来轻量化网络,但最终网络结构也较为复杂,模型在嵌入式端进行部署的效果并不理想,需要对网络结构进行优化,减少网络的复杂度,提升推理速度。将Conv、BN和Activate Function层进行融合[22]。
可以将BN层视为输入与输出通道数相同的1×1卷积层。由于BN层位于Conv层之后,因此二者合并为新的卷积层。
Activate Function层是在网络中的BN层后增加的非线性单元,维度尺寸需要与前一层相同,同理能够将Activate Function层与Conv+BN层进行融合。
Concat层的主要作用是实现多输入的合并,将输入为相同张量和执行相同操作的部分进行融合即可代替Concat层,减少数据传输环节,实现对网络模型的量化和剪枝,具体操作示意图如图5所示。
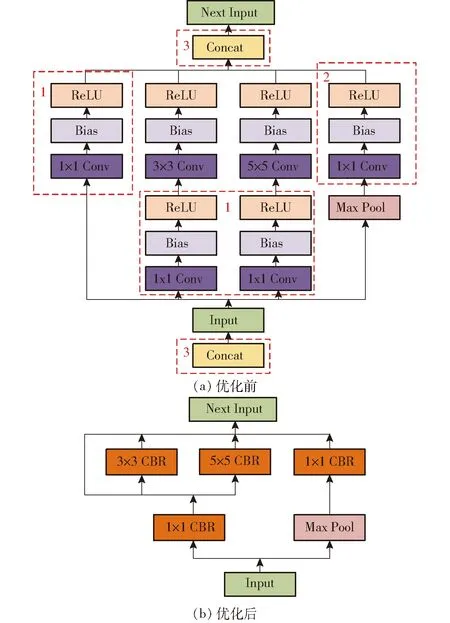
图5 网络优化操作示意图Fig.5 Network optimization operation schematic
图5a中,红色虚线框1表示将Conv、BN和Activate Function层进行融合,红色虚线框2表示将相同张量和操作进行融合,红色虚线框3表示将Concat操作删除,但对于卷积核不同的层无法进行相应的融合。图5b为优化后的网络结构,其中CBR表示Conv、BN和Activate Function层融合得到的新的卷积层。该优化方式是针对推理阶段进行数据处理推导过程的融合,在模型训练阶段不进行网络层的修改,因此能够保证训练过程的精度。
2.3.2模型部署
采用Jetson Nano进行模型迁移部署,Jetson Nano测试图如图6所示。在深度学习主机上将训练好的YOLO v5s、YOLO v5m、YOLO v5l、YOLO v5x模型传入Jetson Nano开发板,在Jetson Nano开发板上优化并编译相应的YOLO v5模型文件,完成后进行模型转换,转换格式过程为Pytorch格式(Pt)—开放神经网络交换格式(Onnx)—TensorRT格式 (TRT),转换时模型计算精度为半精度计算,采用C++程序接口实现API调用,模型运行图像如图6所示。
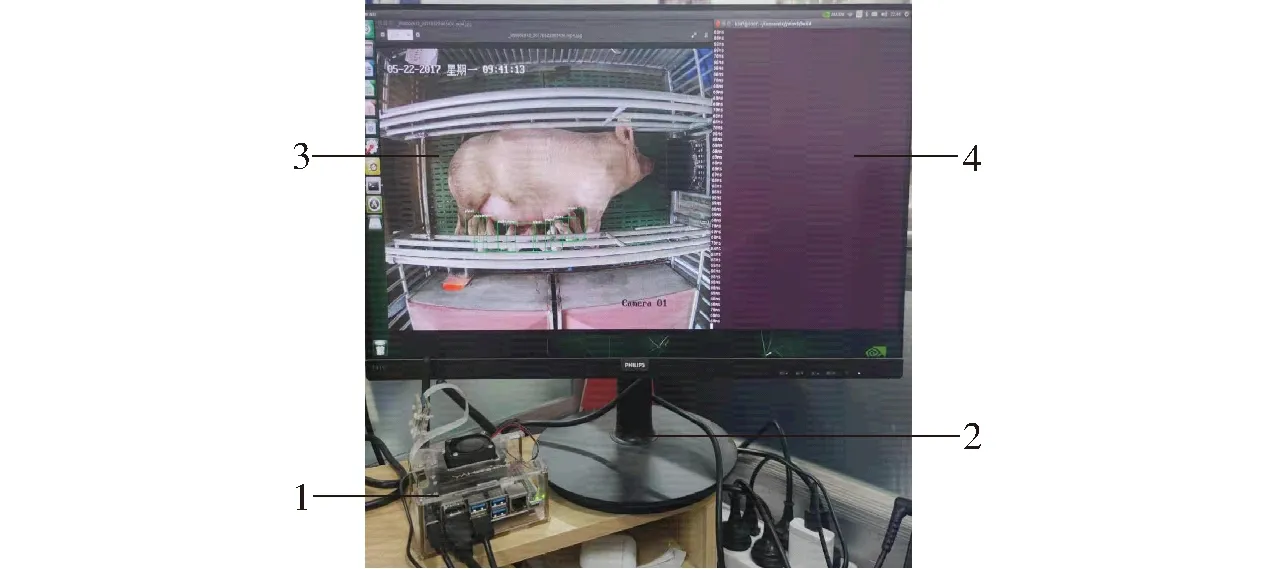
图6 Jetson Nano测试图Fig.6 Experiment diagram on Jetson Nano1.Jetson Nano 2.外接显示器 3.检测图像 4.运行界面
2.4 模型评价指标
模型性能评价指标为单帧图像推理时间、精确率(Precision)和召回率(Recall)。
3 结果与分析
3.1 训练与嵌入式平台
模型训练平台使用Intel i9-10900k处理器;GPU采用NVIDIA GTX3090型显卡,显存为24 GB;操作系统为Ubuntu18.04;在Pytorch深度学习框架上进行模型训练。
模型优化后的推理过程在Jetson Nano开发板上进行,GPU为128-core Maxwell,CPU为Quad-core ARM A57 @ 1.43 GHz,内存为4 GB、64位LPDDR4。相应配置系统为ARM版Ubuntu16.04操作系统,模型运行环境的配置为JetPack4.4、Python 3.8、Pytorch 1.6、Cuda 10.1和TensorRT 7.1。
3.2 训练参数设置
对各个网络模型的参数设置均保持一致,其中迭代周期设置为350,批量大小设置为16,初始学习率设置为0.001,初始冲量设置为0.98,初始权重衰减系数为0.1,每个迭代周期保存一次模型,最终选取最优的模型。
3.3 模型训练结果与分析
训练350个迭代周期的边框损失值和目标损失值曲线如图7所示。图7中,YOLO v5s的损失值在迭代周期0~70之间下降了约0.008,而在迭代周期70~350之间仅下降了0.002,YOLO v5m、YOLO v5l和YOLO v5x的损失值曲线在约70个迭代周期之后每50个迭代周期平均下降0.002。由于本研究中的类别总数为1,所以类间损失值出现无限接近于0的情况,此处不做说明。训练数据集的精确率、召回率和平均精度均值(mAP)曲线如图8所示。
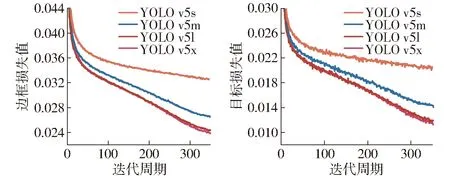
图7 边框损失值和目标损失值曲线Fig.7 Results of bounding box loss and object loss
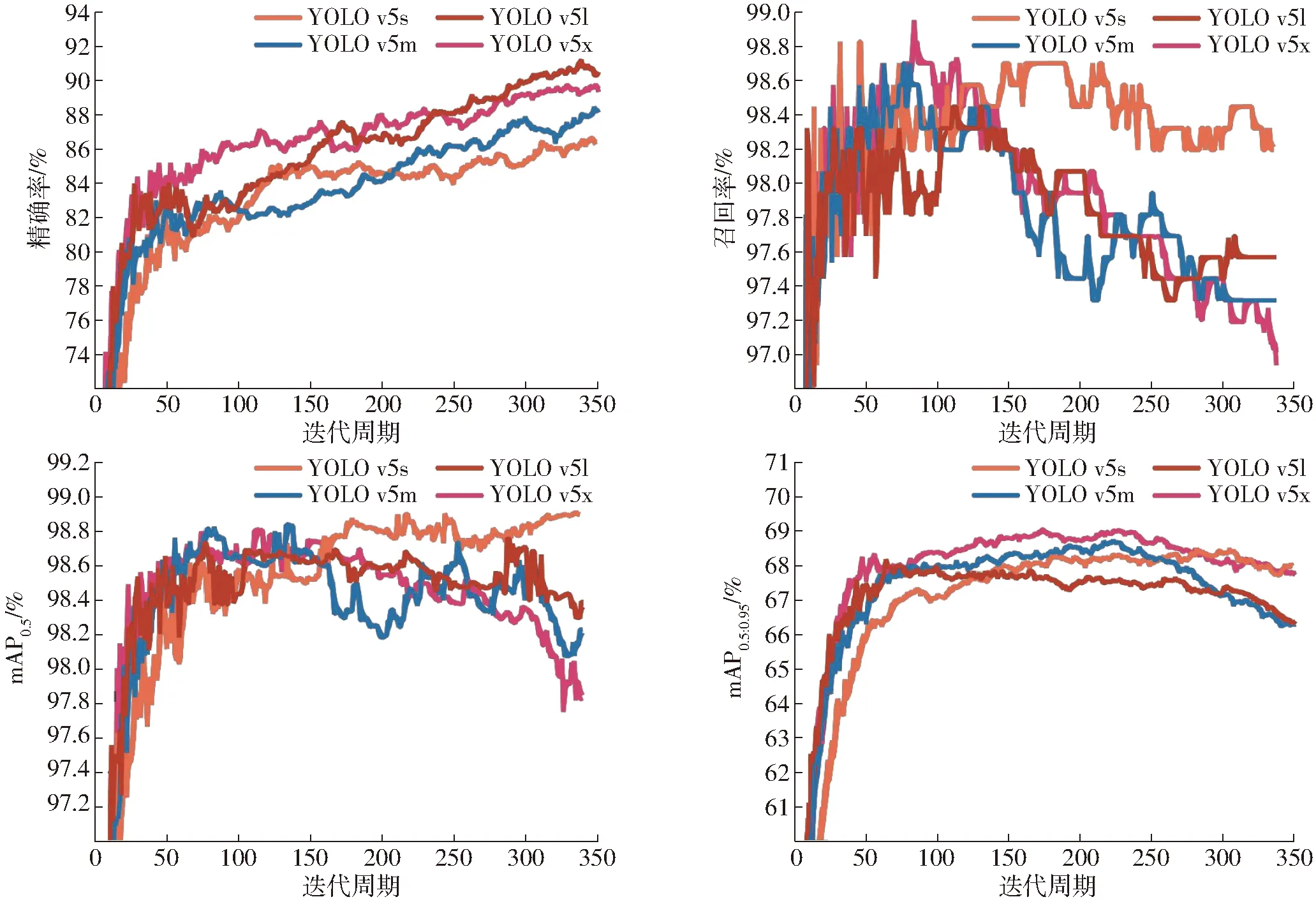
图8 模型测试效果Fig.8 Model tested effect diagrams
图8中,平均精度均值(mAP)表示所有类别平均精度的平均值,本文类别数为1。mAP0.5表示交并比阈值为0.5时的mAP,mAP0.5∶0.95表示交并比阈值在[0.5,0.95]之间每隔0.05取一次mAP,然后取的平均值。
由图7可知,虽然模型的损失值曲线在350迭代周期内未完全拟合,但是由损失值下降频率判断,损失值曲线已经趋于拟合。结合图8可知,模型精度随着训练次数增加不断上升,但是网络模型的召回率在迭代周期70~85时开始下降。这表明在约70个迭代周期之后,模型训练效果将不再随着迭代次数的增加而上升。因此,综合考虑mAP0.5与召回率的变化情况,选取350个迭代周期权重模型中的最优权重模型,选取权重模型的测试性能如表1所示。
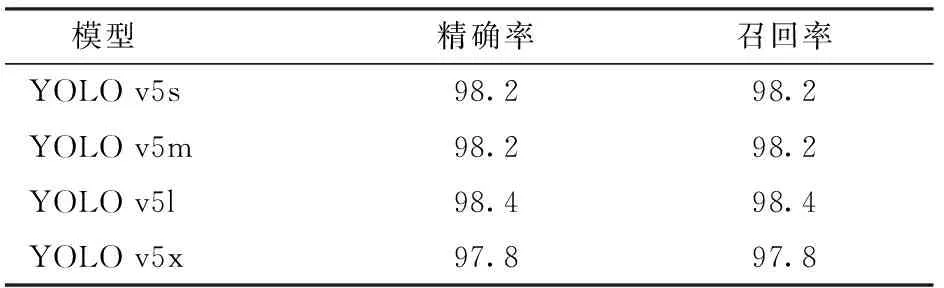
表1 模型测试结果Tab.1 Results of model tested %
3.4 模型部署测试结果与分析
该优化方法虽然能够保留训练精度,但是由于模型在推理阶段的网络结构融合会使模型在加速时牺牲一部分检测精度。因此为验证模型转换后的有效性,将模型转换前后的效果进行对比,模型转换前后在RTX3090显卡与Jetson Nano上的测试效果如表2所示。
由表2可知,模型在转换后的精确率并没有太大的下降,但推理时间极大减少,YOLO v5s与YOLO v5m
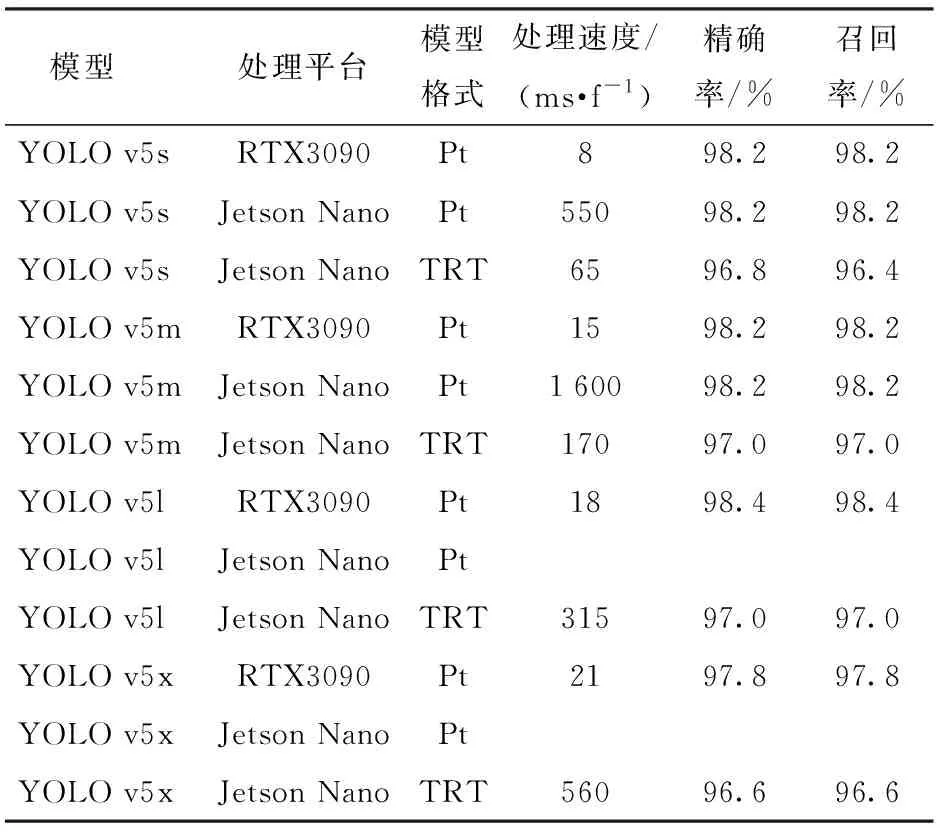
表2 模型测试效果对比Tab.2 Comparison of model measuring effects
模型在Jetson Nano开发板上的运行时间分别缩短为原先运行时间的65/550和17/160。同时,在未转换模型前,YOLO v5l与YOLO v5x模型难以直接在Jetson Nano开发板上直接运行,模型转换后可以在开发板上运行,将主机端与Jetson Nano端的运行效果进行对比,结果如图9所示。

图9 检测结果对比Fig.9 Contrast of detection results
图9中每组图像的左侧图像是加速前的检测效果,右侧图像是加速后的检测效果。由图9可知,本研究构建的YOLO v5网络能够精准地检测出哺乳期仔猪个体,优化后的模型在利用TensorRT加速时,能够在提升仔猪目标检测速度的同时保持有效检测精度。
进一步分析模型在Jetson Nano上的实际运行效果,为后续边缘计算模式下的模型部署提供理论依据。对Jetson Nano运行YOLO v5模型时的GPU利用率进行可视化,可视化结果如图10所示。
由图10可知,Jetson Nano在运行不同网络深度和宽度的模型时,GPU达到高负载的持续时间也是不同的,网络结构越复杂的模型占用的GPU资源也就越多,随着模型复杂度的增加所需要的算力也是不断提升的。为了更好地在嵌入式端运行相应的模型,综合考虑模型复杂度与检测精度,优化后的YOLO v5s在Jetson Nano设备上的运行效果最好。图11为优化后的模型在Jetson Nano上检测不同环境条件下的仔猪目标结果。在光照充足的条件下,能够准确检测出仔猪聚集、阴影干扰情况下的仔猪目标;在无光照的条件下,仍然能够实现仔猪目标检测并应对异物遮挡问题,但是相较于光照条件下的检测效果,存在部分漏检情况,后续需要对该问题进行优化。
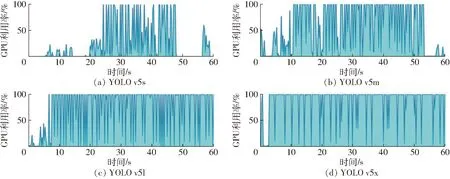
图10 Jetson Nano的GPU利用率Fig.10 GPU utilization of Jetson Nano
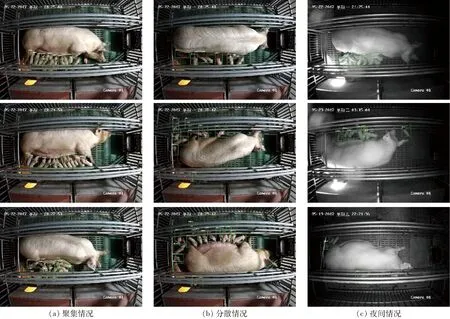
图11 优化后YOLO v5s检测效果Fig.11 Results of detection with optimized YOLO v5s
4 结论
(1)构建哺乳期仔猪个体数据集,建立YOLO v5系列网络,训练哺乳期仔猪目标检测模型。在RTX3090的环境测试YOLO v5s、YOLO v5m、YOLO v5l和YOLO v5x 4种不同复杂度的网络模型,对比测试结果表明,YOLO v5s模型拥有最快的处理速度,且4种模型的检测精确率均高于97%。
(2)对基于YOLO v5的哺乳期目标检测模型进行量化与剪枝,实现模型在嵌入式设备Jetson Nano上的部署。在Jetson Nano上运行的YOLO v5s哺乳期仔猪目标检测模型的单帧图像处理速度仅需要65 ms,YOLO v5m、YOLO v5l和YOLO v5x在测试集上的平均检测时间分别为170、315、560 ms,检测精确率分别为96.8%、97.0%、97.0%和96.6%。因此,综合考虑YOLO v5s、YOLO v5m、YOLO v5l和YOLO v5x模型在Jetson Nano上的运行速度和检测精度,优化后的YOLO v5s模型拥有更好的实际处理效果,能够实现哺乳期仔猪目标准确检测。
(3)规模化养殖使用边缘计算的基础是将算法模型部署至边缘设备。本研究提出一种基于Jetson Nano的哺乳期仔猪目标检测方法,能够为后续边缘计算在生猪养殖中的应用奠定基础,为智慧养殖提供技术支持,有助于加速生猪养殖的智能化进程。
猜你喜欢
今日农业(2022年4期)2022-11-16
今日农业(2022年2期)2022-11-16
基层中医药(2022年5期)2022-10-24
导航定位学报(2022年5期)2022-10-13
机械工业标准化与质量(2022年8期)2022-10-09
健康之家(2021年19期)2021-05-23
人人健康(2018年8期)2018-08-23
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
农家顾问(2016年11期)2017-01-06
职业·中旬(2009年12期)2009-06-01
