
基于迁移成分分析的多风电机组运行状态识别方法
2022-04-06 08:13李林晏张雅洁陈阳李莉潘志强
分布式能源 2022年1期
李林晏 韩 爽 张雅洁陈 阳李 莉潘志强
(1.华北电力大学新能源学院,北京市 昌平区 102206;2.新能源电力系统国家重点实验室(华北电力大学),北京市 昌平区 102206;3.电能(北京)工程监理有限公司,北京市 朝阳区 100089)
0 引言
由于风电机组运行环境恶劣,各部件的机械强度和运行性能不可避免地随着运行环境和运行时间的变化而逐渐下降,从而导致风电机组发电性能下降、故障频发[1-2]。有效识别风电机组运行状态,对风电机组发电性能评估及风电场精细化管理具有重要意义。
现阶段,相关学者对风电机组运行状态辨识进行了研究。ZHAI等[3]利用数据采集与监视控制系统(supervisory control and data acquisition,SCADA)数据,基于多变量状态估计技术和滑动窗口构建风电机组齿轮箱故障辨识模型。LI等[4]基于SCADA数据和正常行为模型建立评估健康指标体系,通过概率密度统计来设计评估过程,提高预测风电机组发电机健康状况的精度。张帆等[5]采用多项式回归拟合方法,构建风电机组运行状态输入/输出参数数学模型,进而提出一种基于SCADA 参数的风电机组运行状态识别方法。CHENG 等[6]提出了一种基于模糊综合评价的风电机组性能评价方法,并采用因子分析法计算权重。HE 等[7]构建了风电机组部件级、装置级和子系统级运行状态评价系统,提出了风电机组实时可靠性分析模型。XU 等[8]基于最大互信息系数和反向传播(back propagation,BP)双隐层神经网络深度挖掘风电机组运行状态关键影响变量,提出了一种基于变量优选和机器学习的风电机组运行状态辨识方法。
综上所述,相关学者对风电机运行状态辨识进行了相应的研究,并取得了一定的研究成果。但是,现有研究着重于针对单台机组进行状态划分,而不同风电机组由于存在数据分布差异的问题,如果将已训练好的单台风电机组正常行为模型直接应用于多风电机组运行状态辨识,辨识精度较低。为了提高辨识精度,划分不同风电机组状态需要重新计算模型参数,存在计算资源浪费的问题。现有方法无法适用于多风电机组运行状态识别,存在辨识精度和效率无法同时兼顾的问题。因此,构建适用于多风电机组的运行状态划分模型至关重要。
迁移成分分析(transfer component analysis,TCA)具有不需要数据独立同分布、不需要足够的数据标注、可以重用之前的模型等优点,能解决少数据,不同分布的问题。目前,相关学者对迁移学习和自己的领域结合进行了研究。杨毅等[9]基于迁移学习和深度学习理论提出一种输电线路故障选相方法,并通过仿真模型进行验证。REN 等[10]通过迁移学习,利用一个训练好的故障前动态安全评估模型评估多个未知故障,提高有效性和精度。兰雨涛等[11]提出一种基于TCA 的域自适应方法,用于轴承智能故障诊断,在标签数据难采集或可用数据稀少时,可识别旋转机械装备的健康状态。
本文提出一种基于TCA 的多风电机组运行状态辨识模型,以解决不同风电机组数据分布差异的问题,减少重复计算网络参数的资源和时间。首先,采用基于最大互信息系数和BP 双隐层神经网络的变量优选方法,从SCADA 数据集中筛选出和功率相关性高的关键影响参数;然后,以正常运行状态下的优选变量为输入,功率为输出,构建了基于BP双隐层神经网络的风电机组正常行为模型,并使用非参数核密度估计分析残差,将运行划分为正常、亚健康和异常状态;其次,基于TCA,构建多风电机组运行状态划分模型,实现多风电机组运行状态划分;最后,基于1.5 MW 风电机组SCADA 系统历史数据,验证所提方法的有效性和适用性。
1 基于变量优选和BP 神经网络的风电机组运行状态划分模型
对风电机组运行状态进行划分有利于风电场实时监测风电机组的运行情况,进行精细化和数字化管理,使风电场运行更安全。本文采用基于变量优选和BP双隐层神经网络的风电机组运行状态划分模型,实现风电机组不同运行状态的有效辨识。
1.1 最大互信息系数
最大互信息系数[12](maximal information coefficient,MIC)是用来衡量两个特征变量之间线性或非线性的相互关系,具有很强的普适性和公平性,在样本量足够大时,捕获的关联能均衡覆盖所有的函数关系。其主要思想是:如果2个变量之间存在一定的相关性,那么在这2个变量的散点图上进行某种网格划分之后,根据这2个变量在网格中的近似概率密度分布,可计算这2个变量的互信息,归一化后,该值可用于衡量这2 个变量之间的相关性。假设y为目标变量,x为待筛选变量,其离散化互信息计算方法为
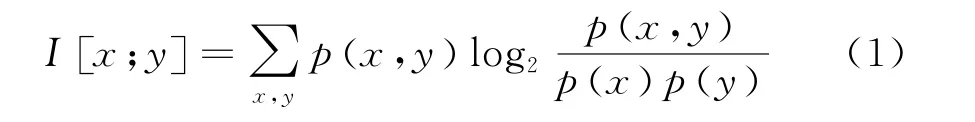
式中:p(x,y)是x和y的联合分布概率;p x()和p y()分别是x和y的边际分布概率。
联合分布概率估算可得到x和y的散点图,用方格分割散点图,特征变量落入方格的概率近似为联合分布概率。最大互信息系数计算方法为
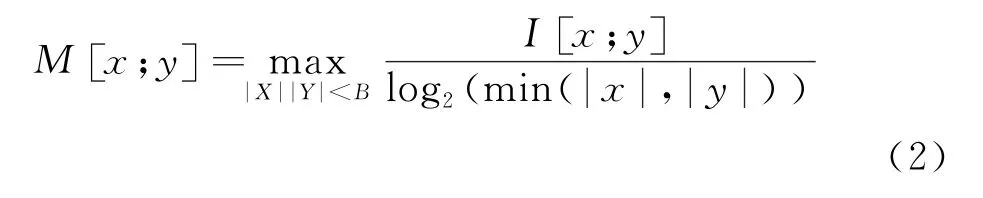
式中:|x|和|y|分别为x轴和y轴上划分网格的数量;B为总方格数,即分辨率,大小设置为样本量的0.6次方。
1.2 BP 双隐层神经网络
BP神经网络是一种按误差逆向传播算法训练的多层前馈网络,根据预测误差调整网络权值和阈值,从而使BP 神经网络预测输出不断逼近期望输出,BP神经网络模型拓扑结构包括输入层、隐藏层和输出层。常用的单隐层BP神经网络需要较多的隐层节点,既增加了训练时间,又易出现过拟合现象[13]。因此,为了提高神经网络的训练效率和泛化能力,使用网络结构增长型方法确定神经网络隐含层节点数,即先设置较少的隐藏层节点数,对网络进行训练,并测试学习误差,然后逐渐增加隐藏层节点数,直到取得相对优的精度。
1.3 基于变量优选和BP 神经网络的风电机组运行状态划分模型构建
基于变量优选和BP神经网络的风电机组运行状态划分模型具体流程如图1所示。
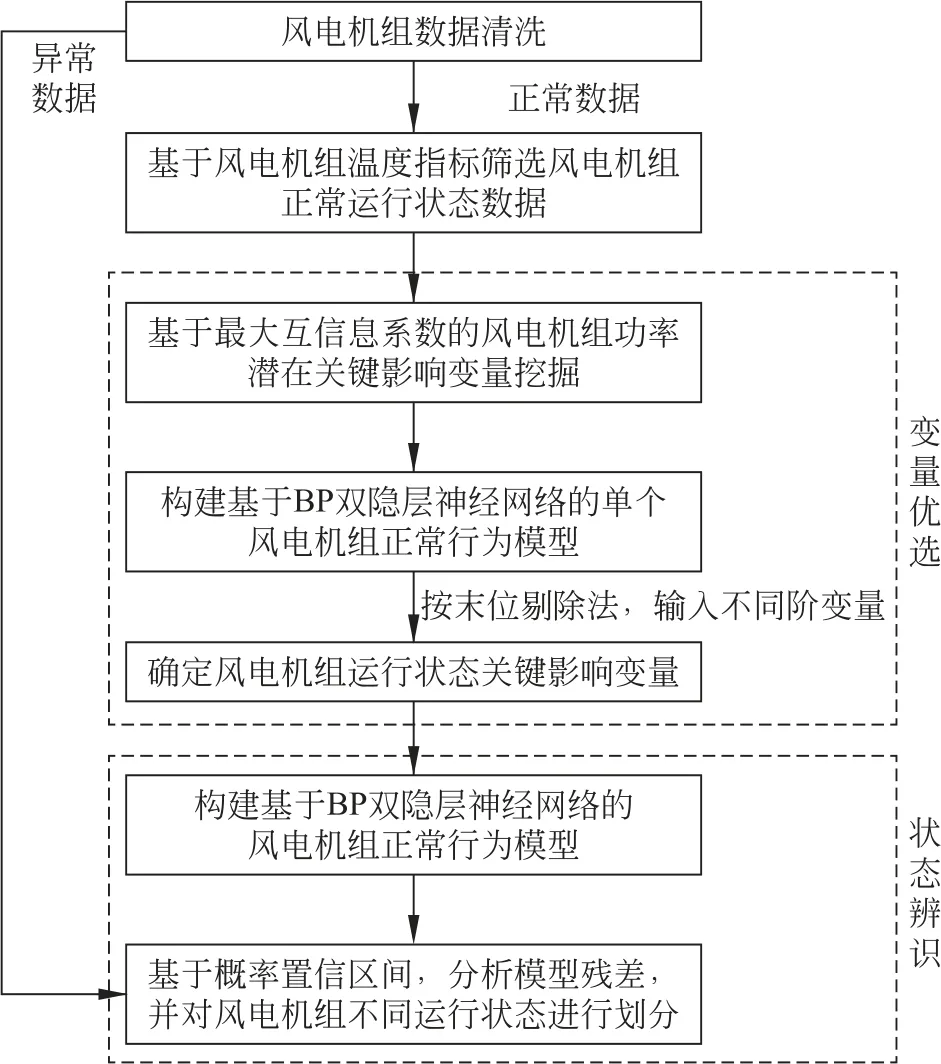
图1 基于变量优选和BP神经网络的风电机组运行状态划分流程Fig.1 Wind turbine operating condition classification based on variable preference and BP neural network
(1) 采集风电机组SCADA 系统历史数据,采用双向四分位法[14-16]对风电机组运行数据进行数据清洗,并对异常数据进行标记。
(2) 基于温度指标,筛选风电机组正常运行状态下的历史运行数据。
(3) 计算风电机组不同变量与功率间的最大互信息数。
(4) 构建基于BP 神经网络的风电机组正常行为模型。
(5) 按照最大互信息系数末位剔除法,组成不同阶(n阶、n-1阶、n-2阶、…)潜在关键影响变量,并基于回归误差评估指标,确定风电机组运行状态关键影响变量。
(6) 以风电机组运行状态关键影响变量为输入,构建基于BP 双隐层神经网络的风电机组正常行为模型。
(7) 基于置信区间,分析风电机组功率残差,对风电机组运行状态进行划分。
2 基于TCA 的多风电机组运行状态划分模型
由于地理位置、风资源条件及机组健康状况不同,不同风电机组的SCADA 数据分布差异明显,如果将已训练好的单台风电机组正常行为模型直接应用于多风电机组运行状态辨识,辨识精度较低。为了提高辨识精度,需要针对每台风电机组正常行为模型进行重复性训练,工作量大,耗费时间长。现有方法无法适用于多风电机组运行状态识别,存在辨识精度和效率无法同时兼顾的问题。针对上述问题,提出了基于TCA 的多风电机组运行状态识别。
2.1 TCA 原理
TCA 是一种无监督的学习方法,又名边缘分布自适应[17]。TCA 的思想是假设存在一个特征映射φ,使得映射后数据的边缘分布大致相等。TCA 假设当源域数据的边缘与目标域数据的边缘分布接近时,则2个领域的条件分布也会接近,其原理如图2所示。与传统最大均值差异嵌入方法相比,TCA 避免了求解半正定规划问题,计算更简单,效率更高。
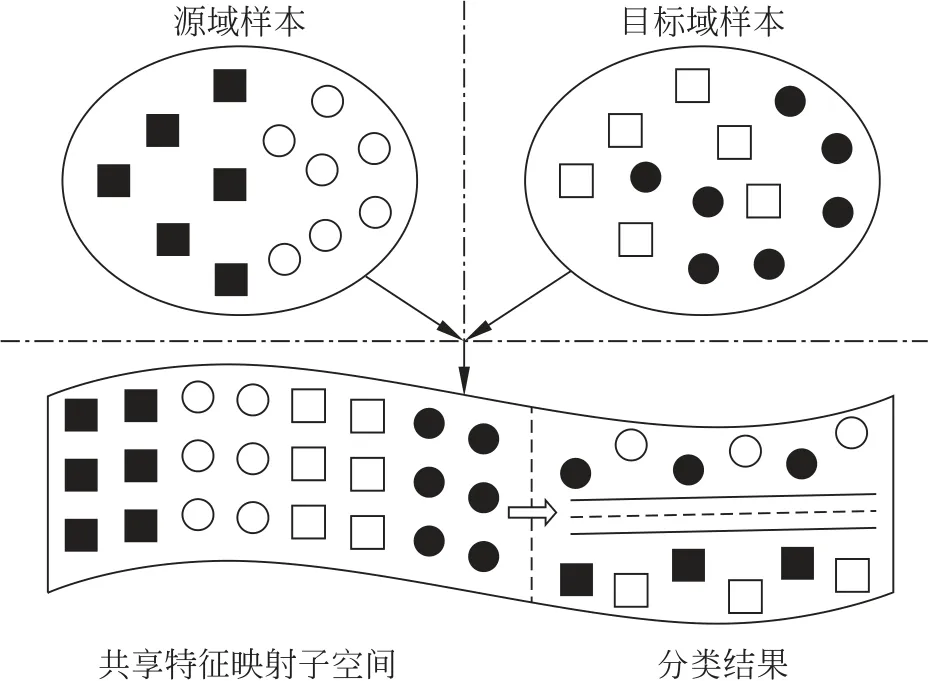
图2 TCA算法原理Fig.2 Principle of TCA
TCA 的原理是利用源域和目标域的相似性,缩小源域数据和目标域数据的边缘概率分布的距离,从而使二者的条件分布减少,实现TCA。具有实现简单,没有过多的限制使用条件等优势。其表达式为
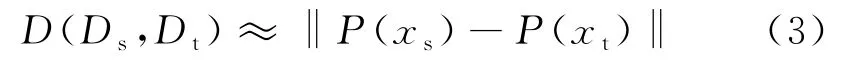
式中:Ds、Dt为源域和目标域数据;Ps、Pt为源域和目标域数据的边缘分布。
2.2 基于TCA 的多风电机组运行状态划分模型
TCA 具有不需要数据的独立同分布、模型可以在不同数据中迁移等优点,可以极大缩小不同风电机组的数据分布,从而提高相同模型精度和效率,也减少重复计算网络参数的资源和时间。基于TCA 的多风电机组运行状态划分流程如下:
(1) 采集风电机组SCADA 系统历史数据,对风电机组运行数据进行数据清洗,并对异常数据进行标记;
(2) 基于温度指标,筛选风电机组正常运行状态下的历史运行数据;
(3) 基于TCA,构建多风电机组运行数据分布同化模型;
(4) 以1.3节中所确定的风电机组运行状态关键影响变量为输入,构建基于BP 神经网络的风电机组正常行为模型;
(5) 计算风电机组功率残差,基于置信区间,对风电机组运行状态进行划分。
基于TCA 的多风电机组运行状态划分流程如图3所示。计算风电机组功率残差时,采用平均绝对误差和均方根误差作为回归误差分析的指标;二者的值越小,模型越精确。
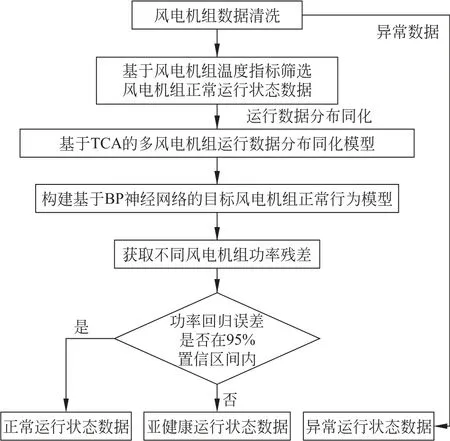
图3 基于TCA的多风电机组运行状态划分流程Fig.3 Operational state classification process of multi-wind turbines based on TCA
3 算例分析
基于国内某风电场2台1.5 MW 双馈型风电机组SCADA 数据进行算例分析,该型号机组切入风速为3.5 m/s,切出风速为27 m/s。风电机组SCADA 系统历史数据主要包括风速、功率、风向、发电机转速、主轴转速、叶片角度、齿轮箱中间轴驱动端轴承温度、网侧L1相电压等26维变量。风电机组运行数据时间分辨率为1 min,数据时间长度为1个月。
3.1 基于变量优选和BP 神经网络的风电机组运行状态划分
目前,筛选风电机组正常运行数据的方法尚未统一。本文采用油温明显正常部分数据训练BP神经网络,将所有数据测试,通过滑动窗口计算均方根误差的变化趋势,将均方根误差值小于阈值的数据设置为正常数据。以1号机组为例,结果如图4所示。
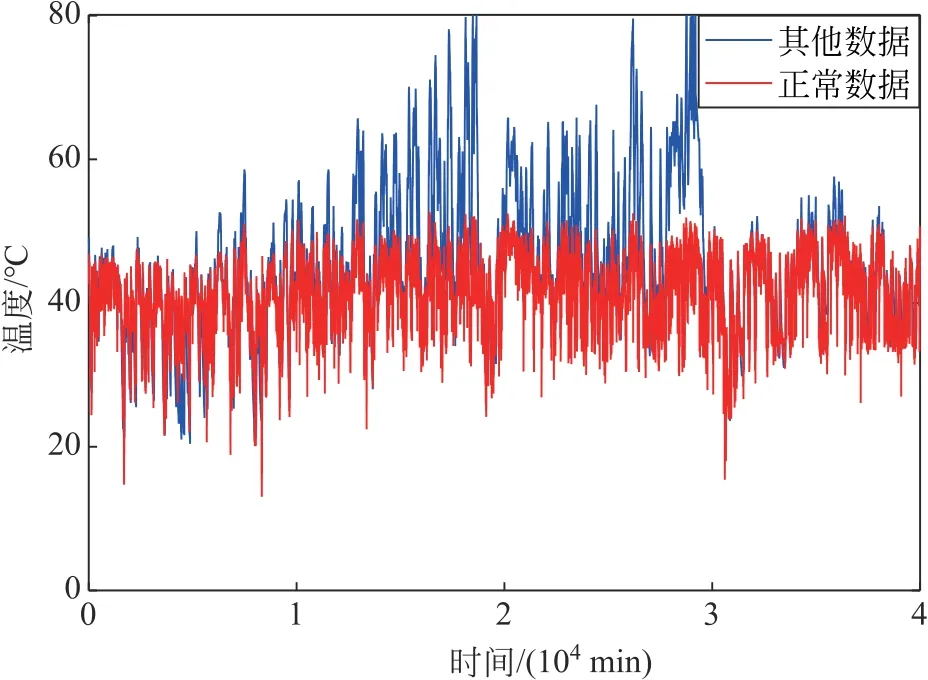
图4 风电机组正常运行状态筛选Fig.4 Wind turbine normal operating condition data screening
基于风电机组正常运行状态数据,计算不同变量与功率之间的最大互信息系数,如表1所示。选择最大互信息系数大于0.4的发电机转速、主轴转速、风速、叶片角度、齿轮箱中间轴驱动端轴承温度、齿轮箱中间轴非驱动端轴承温度、齿轮箱分配器位置油压、齿轮箱油泵吸油口油压等8维变量作为潜在关键影响参量。
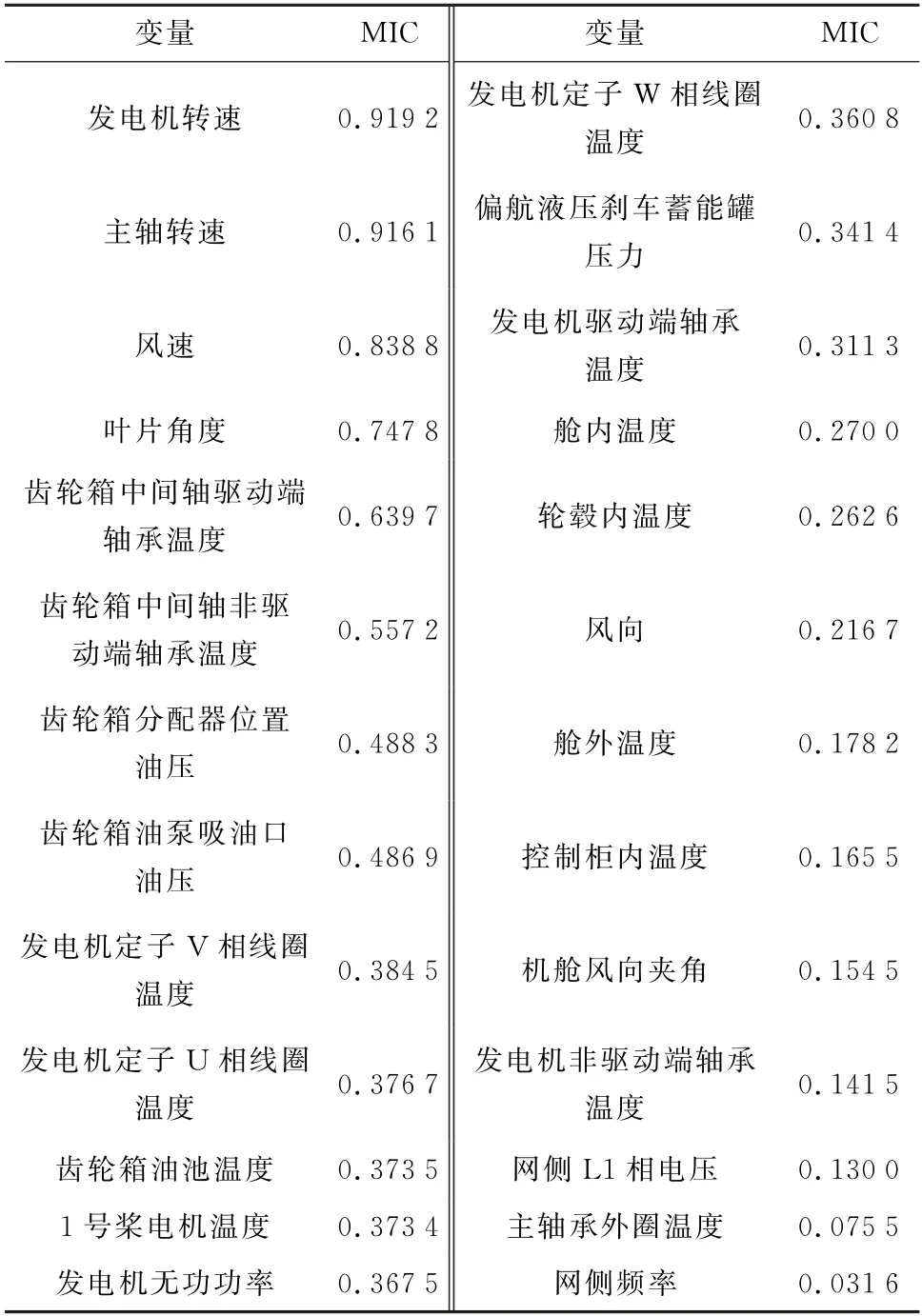
表1 不同变量与功率的最大互信息系数Table 1 MIC of different variables and power
按照最大互信息系数末位剔除法,组成不同阶(8阶、7阶、6阶……2阶)潜在关键影响变量,分别以正常运行状态下的不同阶潜在关键影响变量为输入,风电机组功率为输出,分别构建基于BP双隐层神经网络的风电机组功率回归模型,不同阶关键影响参量作为输入的功率回归均方根误差指标如图5所示。
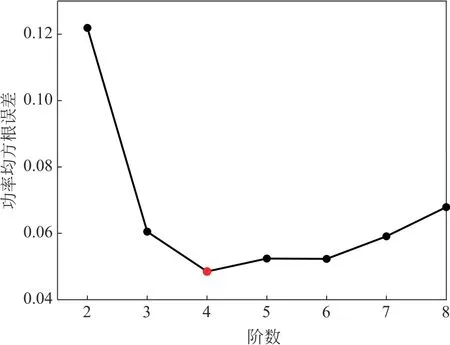
图5 不同阶数变量输入的功率回归误差Fig.5 Power regression errors for different orders of variable inputs
如图5所示,风电机组功率回归误差随着关键影响参量阶的增加,呈现先下降后上升的趋势,在4阶时回归误差最小;表明仅基于最大信息系数的变量优选方法所确定的潜在关键影响变量存在信息冗余,无法有效挖掘风电机组运行状态关键影响变量,验证了所提的变量优选方法的有效性和适用性。因此,本文确定4阶潜在关键影响变量,即发电机转速、主轴转速、风速、叶片角度为风电机组运行状态关键影响变量进行后续的风电机组运行状态识别。
将正常运行状态下选定的4阶风电机组关键影响参量为输入,功率为输出,训练BP双隐层神经网络,用排除异常数据后的风电机组运行数据进行测试,获得风电机组功率回归残差。采用非参数核密度估计分析残差;当残差大于0时,说明风电机组运行状态优于平均水准,故只考虑残差小于0的部分,确定95%下置信区间,如图6所示,其区间范围为[-98.41,+∞),将区间内的数据划分为健康运行状态数据,区间外的数据划分为亚健康运行状态数据,结合双向四分位清洗出的异常运行状态数据,完成风电机组运行状态划分。
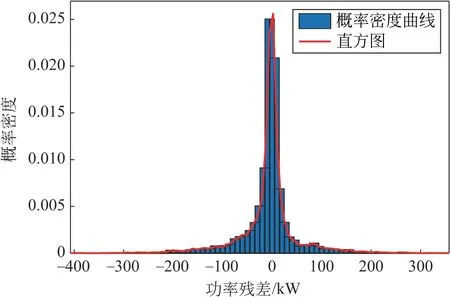
图6 基于概率置信区间的回归残差分析结果Fig.6 Results of regression residual analysis based on probabilistic confidence intervals
基于变量优选和BP双隐层神经网络的风电机组运行状态划分的风速-功率散点图如图7 所示。由图7可知,绿色的亚健康状态数据,在相同风速下,其功率较低,此时风电机组出力和发电量比同风速时段相对较差,所得各运行状态的数据分布符合风电机组实际运行状况,验证了所提模型的有效性和适用性。
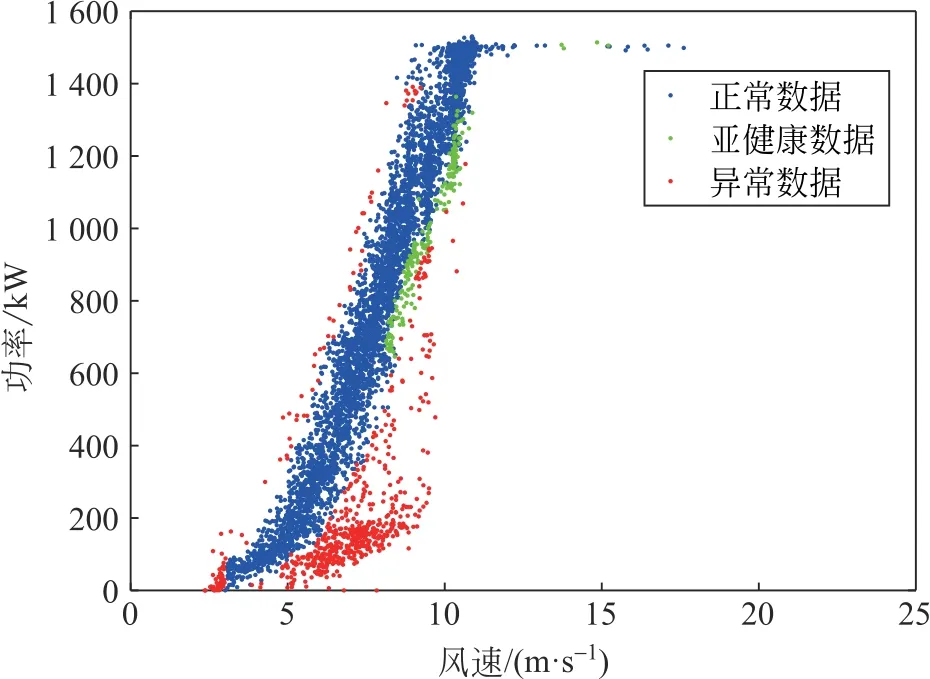
图7 风电机组运行状态辨识结果Fig.7 Wind turbine operating condition identification results
3.2 基于TCA 的多风电机组运行状态划分
对于1号机组,构建其基于变量优选和BP 双隐层神经网络的风电机组运行状态划分模型。以1号机组的数据为源域数据,2号风电机组数据为目标域数据,获取风电机组运行数据分布同化数据集;将迁移前的2号机组数据集和迁移后的2号机组数据集分布输入根据1号机组数据分布构建的风电机组运行状态划分模型,所得风电机组运行状态划分的风速-功率散点图如图8所示。
对比图8(a)和图8(b)可知,迁移前,由于不同机组所处的地理位置不同、机组之间存在尾流效应的影响等,不同风电机组的数据分布差异明显。因此根据1号机组数据集分布构建的状态划分模型无法很好地适应2号机组数据集分布,将恒功率阶段的正常数据误识别为异常数据,而经过迁移后,拉近了1号机组和2号机组的数据分布,状态辨识结果正常,符合风电机组的实际情况。TCA 使不同机组的数据可以使用相同的模型,减少重复计算网络参数的资源和时间,提高效率和精度。
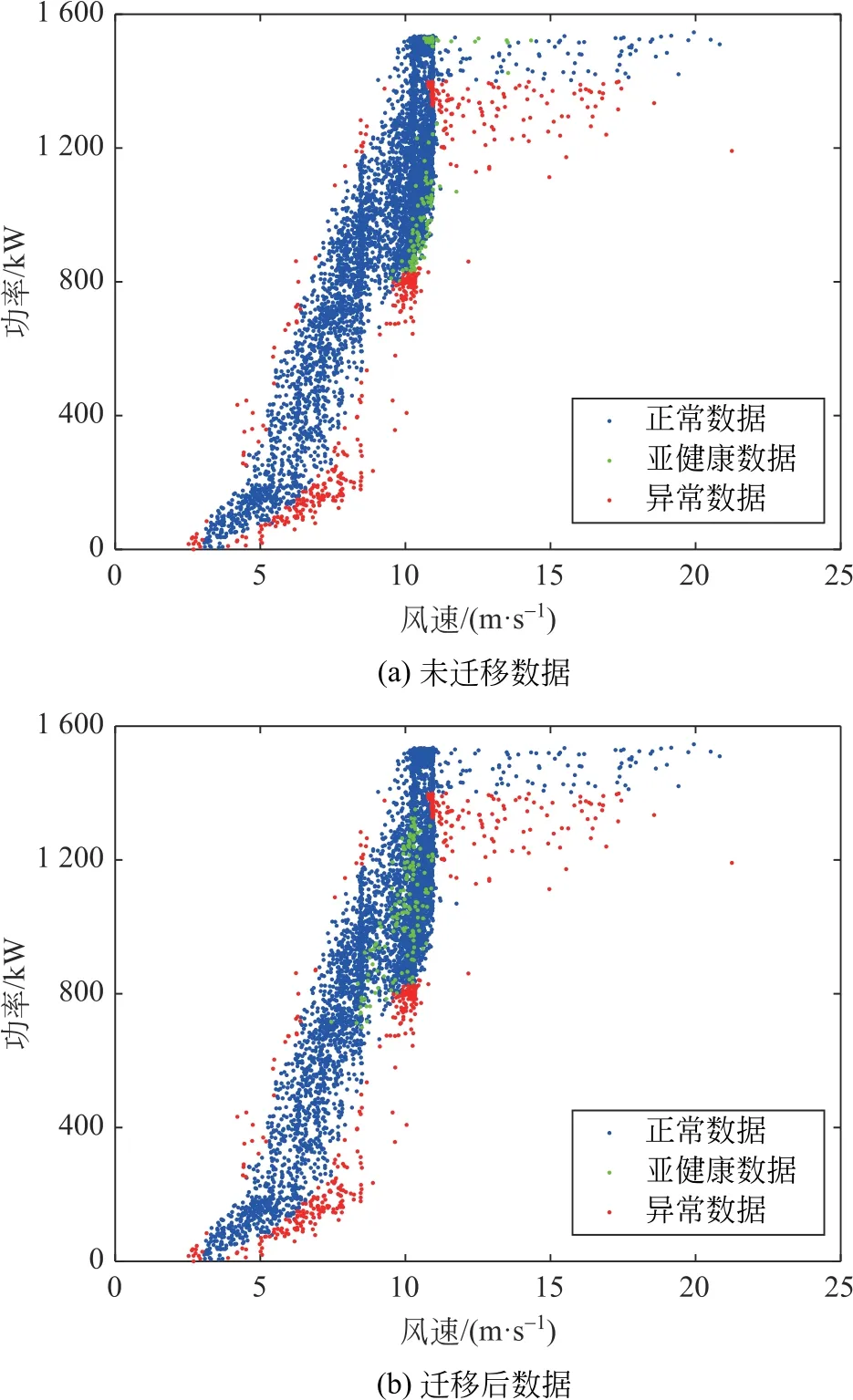
图8 TCA前后的风电机组运行状态辨识结果Fig.8 Wind turbine operating condition identification results before and after TCA
统计迁移前、后风电机组不同运行状态的个数,结果如表2所示。对比经过迁移前、后功率残差的均方误差、平均绝对误差指标,结果如表3所示。
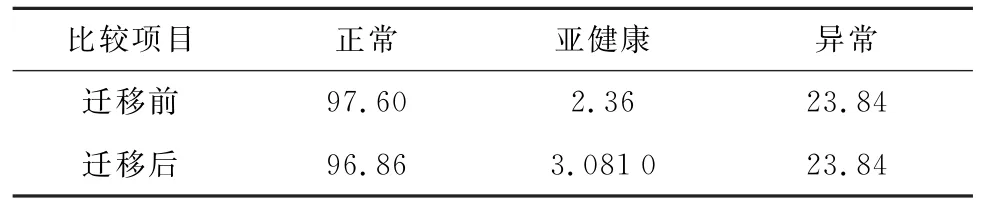
表2 运行状态划分结果对比Table 2 Comparison of operation status classification results%
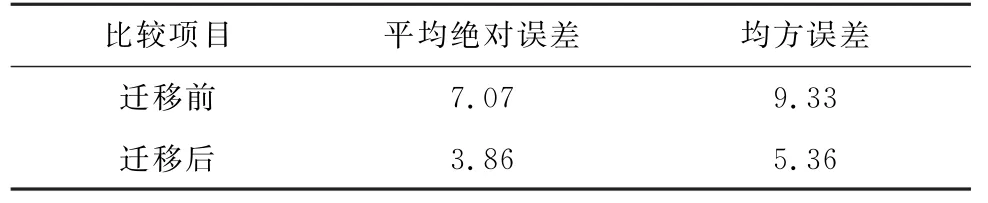
表3 功率残差误差分析指标对比Table 3 Comparison of power residual error analysis indexes%
定性分析风电机组状态划分结果,由表2可知迁移后,正常状态的数据量差距很少,亚健康状态数据少量增多,总体改变小。定量分析风电机组状态划分结果,由表3可知:迁移后,平均绝对误差和均方根误差指标显著下降,说明TCA 提高了模型精度,让模型更加稳定,验证了所提模型的有效性和适用性。
4 结论
本文提出了基于TCA 的风电机组运行状态识别方法。首先,基于变量优选和BP 双隐层神经网络,实现风电机组运行状态辨识,构建风电机组运行状态划分模型;其次,基于TCA 处理不同机组清洗后的数据,使数据独立同分布;然后,将迁移后数据输入根据源域数据构建的风电机组状态划分模型中,实现多风电机组运行状态划分,构建多风电机组运行状态划分模型。所得结论如下:
1) 基于变量优选和BP双隐层神经网络的风电机组运行状态辨识方法,深度挖掘了风电机组的关键影响变量,提高了回归残差的精度,将运行划分为正常、亚健康和异常状态,有助于风电场进行精细化管理,提高风电场的安全性和稳定性。
2) 基于TCA 的多风电机组运行状态划分模型,解决了不同风电机组数据分布差异的问题,节省了重新调整神经网络参数的时间和资源,同时兼顾了模型的精度和效率。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
电子乐园·下旬刊(2022年5期)2022-05-13
中国核电(2021年3期)2021-08-13
舰船科学技术(2021年12期)2021-03-29
科学导报(2020年50期)2020-09-09
海峡姐妹(2020年8期)2020-08-25
伙伴(2018年7期)2018-05-14
中学生数理化·八年级物理人教版(2016年5期)2016-08-26
中学生数理化·八年级物理人教版(2016年5期)2016-08-26
新高考·高一物理(2015年3期)2015-08-20
