
基于文本挖掘的公司股价崩盘风险预警
——来自年报MD&A的经验证据
2022-04-03 07:45:04赵甜甜
福建商学院学报 2022年6期
尉 昊,赵甜甜
(兰州财经大学 会计学院,甘肃 兰州,730020)
股价崩盘事件是金融界异象之一,一方面会给投资者带来惨重代价,危害资本市场健康发展,更甚者将引起金融危机;另一方面会使公司陷入财务危机,不利于公司长久发展,因此历来受到学术界和实务界的关注。不管是1929年美国股市大崩溃、1997—1998年中国香港股灾、还是2008年次贷危机,这几次影响重大的股价崩盘事件均在不同程度上造成了严重后果。以往关于股价崩盘风险的研究都是在定量数据的基础上进行因果推断,不仅忽视了文本信息,而且缺乏预测研究。机器学习的发展为预测股价崩盘风险创造了机遇,对于有效治理公司和防范经济危机具有重要的理论和实践意义。
一、文献综述
(一)关于股价崩盘风险预测的研究
上市公司股价崩盘风险预测一直以来备受关注,国外学者已经进行了大量研究。Li[1]以沪深300指数为研究对象,将时间跨度作为市场风险预警指标,采用LPPLS模型对崩盘临界点进行预测;Liao[2]利用神经网络的方法对股价崩盘进行预测,结果发现其预测精度要高于随机预测方法。除此之外还有学者发现,具有股票过去收益率高[3]、个股流动性增加[4]特征的企业在未来更容易发生股价崩盘。相比于国外,我国在股价崩盘风险预测方面的研究较为匮乏。荆思寒[5]等建立了中国股票市场个股崩盘概率预测模型,结合事件研究法检验了预测模型对未来发生股价崩盘的个股具有一定的识别能力;吴俊传[6]等首次将投资者情绪因素纳入到LPPL模型,采用文本挖掘技术构建LPPL-MS组合模型预警股市崩盘。
(二)文本信息对股价崩盘风险的影响
Jin[7]等从代理理论的视角出发,提出关于个股崩盘风险研究中最被认可的管理层捂盘假说,为股价崩盘风险的后续研究奠定了理论基础,同时也是股票崩盘风险可预测性的研究动机。该假说认为,上市公司内部管理者出于自利动机,更倾向于及时对外部投资者公布有利于公司的消息,而隐瞒不利于公司股价的消息;外部投资者由于信息不对称,缺乏对公司客观全面的认识,会高估该股票的真实价值,从而产生泡沫。管理层隐匿行为终究是“纸包不住火”,当负面消息累积到一定程度集中爆发,投资者大量抛售股票产生崩盘。而管理层捂盘行为一般反映在公司披露的文本信息中,相较于数据信息,文本信息具有更加灵活的披露特征,管理层可以通过文本复杂性、文本篇幅和文本语调等进行操纵。与此同时,虽然证监会对数据信息披露的监管越来越严,关于公司年报中文本信息披露的监管制度却相对欠缺,这也给予了管理层操纵文本信息的空间。
对于文本信息的应用,学者们大多选择年报中的MD&A部分,主要包括上市公司年报中高管针对公司过去经营状况的回顾以及对未来发展趋势的展望[8]。对于缺乏专业财务数据分析的投资者,其了解公司经营状况的途径主要是依据MD&A信息。文本挖掘技术的日益成熟使得学者们分析文本信息成为可能。梁龙跃[9]等基于文本挖掘有效提取MD&A财务文本特征,提高了上市公司财务风险预警模型的预测能力。MD&A中管理层语调也为财务困境预测提供了新的信息,是对定量财务数据的重要补充[10]。
通过梳理相关文献,以往关于股价崩盘风险预警的研究大多基于物理模型,并未考虑文本信息增量对股价崩盘的作用,数据技术的推广使得采用机器学习与文本挖掘等方法预测股价崩盘风险成为可能。基于此,采用TF-IDF算法挖掘年报中MD&A部分的文本特征与信息披露特征,并且基于决策树模型(Decision Tree)、梯度提升树模型(Grandient Boost)、极端梯度提升树模型(XGBoost)以及前馈神经网络模型(MLP)探究文本信息增量对股价崩盘风险的预测效果,以期丰富股价崩盘风险相关文献,为公司治理与投资者防范风险提供理论依据。
二、研究设计
(一)数据获取与预处理
2005年我国证监会首次明确提出,管理层应当在公司年报中对财务报告以及报告期内已经发生或将要发生的重大事项进行讨论与分析[11]。考虑到年报中管理层讨论与分析披露的规范性,选取2010—2021年的沪深A股上市公司为研究对象,其中财务数据与股票交易数据均来自CSMAR数据库。年报数据来自东方财富网,运用Python软件提取年报中的“管理层讨论与分析(MD&A)”章节。为了去除文本资料的数据噪声,采用哈工大停用词表对MD&A文本进行停用词处理,利用jieba分词库切分文本内容,得到初步用于建模的文本特征。将文本数据与所有定量数据进行匹配,剔除缺失值,考虑到异常值对研究结果的影响,对所有连续型变量在上下1%处进行Winsorize处理,最终得到30 812条有效样本。
(二)变量定义
1.响应变量
造成股价崩盘的根本原因是管理层隐匿负面消息而导致信息不对称,进而造成信用危机。负面消息的积累需要一定的时间才会在市场上予以反映,所以在较长的时间节点上去定义股价崩盘风险更为准确。借鉴罗进辉[12]等的做法,定义股价崩盘的哑变量为Crash:
Wi,t≤Average(Wi,t)-3.09σi,t
(1)
其中,Wi,t为第i家上市公司第t年的特定周收益率,Average(Wi,t)表示第i家公司股票第t年的特定周收益率均值,σi,t表示第i家公司股票第t年特定周收益率标准差,3.09个标准差对应标准正态分布下0.1%的概率区间,如果一年时间里第i家公司股票的特定周收益率存在满足上式的条件,那就意味着这家公司在该年内发生了股价崩盘事件。
2.特征变量
从市场交易层面与公司层面分别定义模型的特征变量。选取个股周收益率的标准差(Sigma)、个股收益偏度(NCSKEW)以及月均超额换手率(Dturn)三个变量作为衡量市场交易层面的特征。选取企业总资产自然对数(Size)用以衡量企业规模,采用净资产收益率(ROE)作为衡量企业成长性与盈利性的代理变量。
管理层对于MD&A信息披露的主观操纵可以减缓股价崩盘风险带来的市场冲击,影响利益相关者对公司负面事件的看法和态度。借鉴姚加权[13]等披露的金融情绪词典,并利用谢德仁[14]等的方法构建年报MD&A净语调(tone),公式如下:
(2)
其中Pos代表MD&A中的积极词汇,Neg代表MD&A中的消极词汇。
利用jieba分词库在去除停用词之后对MD&A文本词汇进行统计并取自然对数,得到文本总词数(word)用以衡量MD&A文本篇幅长度。关于年报MD&A可读性的衡量,借鉴徐巍[15]等的方法构建三个测度指标,readability1表示每个分句中平均字数,readability2表示副词和连词在每个句子中所占的比例,readability3表示每个分句平均字数与副词、连词所占比例的算术平均。考虑到文本可读性、语调以及篇幅构建MD&A信息披露特征测算体系,用以衡量管理层对公司文本信息的操纵情况。
文本特征采用TF-IDF算法确定关键词权重和数量。具体计算方式如下:
(3)
其中,tf-idf表示关键词权重;tfx,y表示词频,即某词汇x在文本总词数y中出现频率;log(N/dfx)表示逆文档频率,即语料库的文本总数N与包含该词x的文本数dfx比值的对数值,引入逆文档频率在统计文本关键词时可以避免通用词的干扰。tf-idf值越大,说明该词汇是高频词但不是通用词。将确定权重的文本特征向量化,同时为了避免特征变量维度灾难的发生,最终确定100维文本特征向量。响应变量与特征变量具体见表1所示。
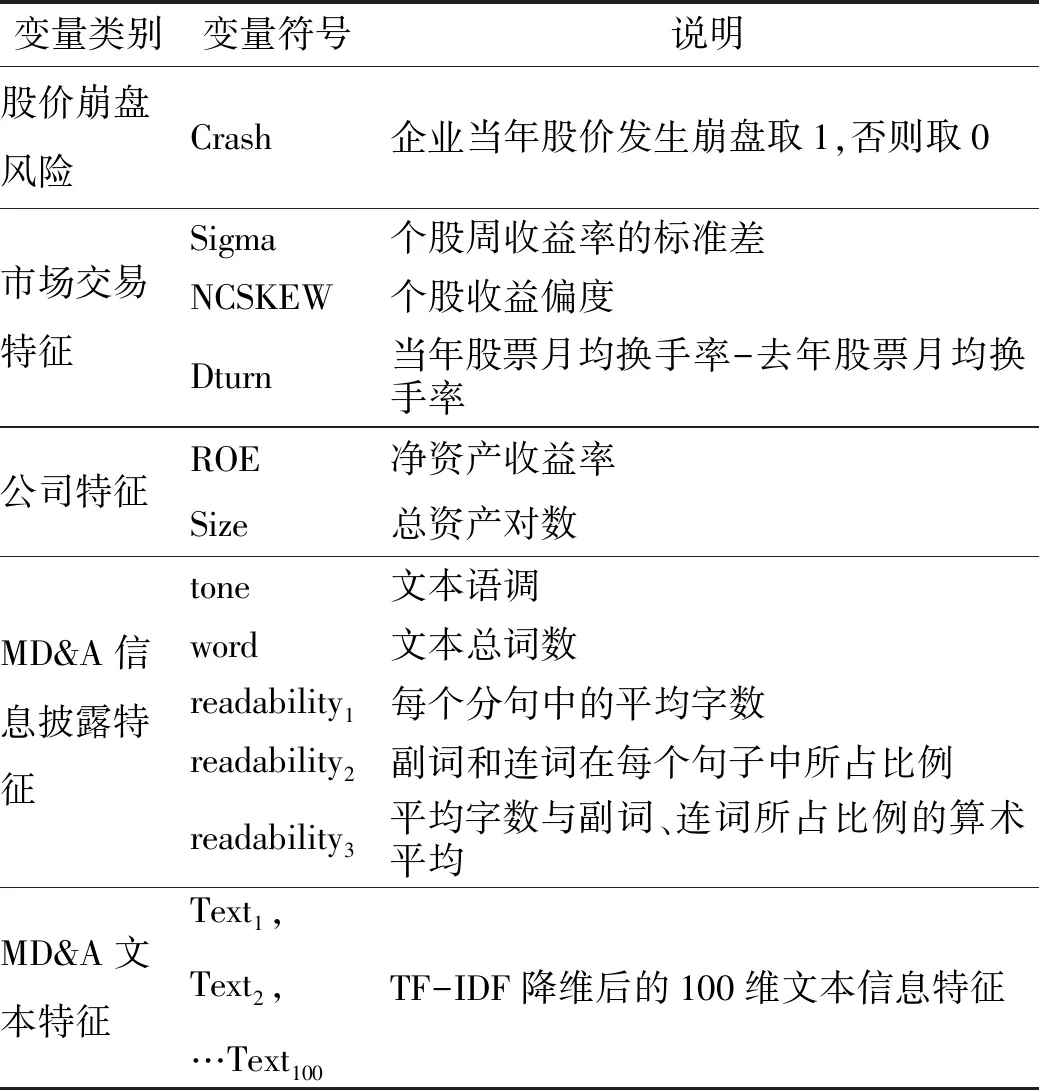
表1 变量定义表Tab.1 Variable definition table
(三)预测模型
1.模型设计
基于市场交易特征、公司特征、MD&A信息披露特征与MD&A文本特征构建决策树(Decision Tree)、梯度提升树(GBDT)、极端梯度提升树(XGBoost)与前馈神经网络(MLP)预测模型。在市场交易特征与公司特征的基础上分别加入文本信息特征,判断MD&A信息披露特征与文本特征能否显著提升模型预测准确度。
决策树模型是从信息熵出发作为分类与回归的基本依据,信息熵的表达函数如下:
H(X)=-∑p(x)logp(x)
(4)
其中p(x)为事件发生的概率。信息熵是指基于事件发生的概率所反映的信息大小。
梯度提升树的数学模型可表示为:
fM(x)=∑T(x;Θm)
(5)
其中T(x;Θm)代表决策树,Θm体现决策树的参数,M代表树的个数。相比于决策树模型,梯度提升树模型还需考虑更多的参数,比如树的数量、学习率与子抽样比例等。
极端梯度提升树模型(XGBoost)显式地加入了正则项来控制模型复杂度,防止过拟合,提升了模型的泛化能力。同时XGBoost在算法上做出了许多改进。其目标函数如下:
(6)
其中l为损失函数,Ω(ft(x))是用于惩罚ft(x)模型复杂度的正则化项。
多层感知机(MLP)也叫作前馈神经网络模型,由一个输入层、多个隐藏层和一个输出层构成。其计算过程可表示为:
(7)
其中,wi表示第i个神经元的权重,xi表示第i个神经元的输入。
2.评价指标
首先需要对训练集和测试集进行独立的划分,将2010—2020年的样本划分为训练集,将2021年的样本划分为测试集。由训练集得到样本内预测准确率Score_Train,并将训练模型在测试集上进行拟合,由此得到样本外预测准确率Score_Test。具体而言,预测准确率的计算方法为:
(8)
其中TP为真正例即实际为正例且预测也为正例的样本,TN为真反例即实际为反例且预测也为反例的样本,FP为假正例即实际为反例但预测为正例的样本,FN为假反例即实际为正例但预测为反例的样本。TP与TN统称为预测正确的样本,而FP与FN统称为预测错误的样本,预测准确率反映的就是预测正确的样本在总样本中所占的比例。
其次评估模型的分类预测效果。用科恩的Kappa值来检测分类不平衡样本中预测准确率虚高的部分。Kappa值是以一致性作为考量分类问题预测值与实际值之间差异的一个指标,具体而言,首先定义观测的一致性P0:
P0=p11+p22
(9)
其中,P0表示“观测到的一致性”,p11表示TN,p22表示TP,也即预测正确的样本。在此基础上,定义p.1,p1.,p.2与p2.:
p.1=p11+p21
(10)
p1.=p11+p12
(11)
p.2=p21+p22
(12)
p2.=p21+p22
(13)
其中,p12与p21分别表示FP与FN,那么p.1就表示为样本中实际正例的比重,p1.表示样本中预测正例的比重,p.2表示样本中实际反例的比重,而p2.表示样本中预测反例的比重。定义“期望的一致性”:
PE=p.1p1.+p.2p2.
(14)
在确定了观测的一致性与期望的一致性的基础上,定义科恩的Kappa为:
(15)
其中,分子表示从随机一致性到观测一致性的实际改进,而分母表示从随机一致性到完全一致性的最大可能改进,实践经验表明,Kappa值大于0.4为可接受的范围。
最后,采用特征的相对重要性以及偏依赖图进行进一步分析。特征的相对重要性指的是给定模型中其他部分不变,在模型中加入该变量带来的平方误差的下降幅度。面对高维特征,变量的相对重要性可以说明哪些特征对模型的预测效果贡献更大。偏依赖图一般是以线性或非线性的函数图像反映特征变量对于响应变量的具体预测机制,这有助于研究者厘清各特征变量与响应变量之间的相关关系。
三、实证结果分析
(一)描述性统计
为了更好地了解特征变量与响应变量的分布情况,对所有变量进行描述性统计分析,限于文章篇幅,仅展示前三个文本特征变量。从表2中可以看出,个股周收益率标准差Sigma最大值为0.252,最小值为0.012,个股收益偏度NCSKEW均值为0.321,即个股之间收益波动巨大,且中国股票市场收益分布存在右偏现象。信息披露特征即MD&A文本语调tone、文本总词数word与可读性指标均值与标准差之间差异较大,说明在上市公司年报信息披露方面存在文本操纵行为,管理层捂盘现象普遍存在。文本特征Text1、Text2、Text3三个变量的最大值均在0.9以上,且最小值均为0,说明发生股价崩盘的公司与未发生股价崩盘的公司在文本信息披露方面存在较为显著的差异。

表2 描述性统计结果Tab.2 Descriptive statistics
(二)MD&A文本特征分析
发生股价崩盘的公司与正常经营公司的MD&A文本信息特征由词云图展示,图1与表3的结果可以看出,两类公司存在较为显著的差异。股价崩盘公司的关键词为“重大、减少、风险、调整、下降”等词汇,这与公司面临业绩下滑或经历重大危机有着密切关联,而正常经营公司的关键词为“增长、建设、募集、上年、同比”等词汇。通过对jieba分词结果与TF-IDF模型的权重统计结果分析,股价崩盘公司较正常经营公司的负面词汇多。

(a)股价崩盘公司

(b)正常经营公司图1 关键词词云图Fig.1 Keyword cloud chart

表3 jieba分词词频统计与TF-IDF模型关键词权重Tab.3 Jieba word frequency statistics and TF-IDF model keyword weights
(三)预测结果分析
利用决策树模型、梯度提升树模型、极端梯度提升树与前馈神经网络模型,分别实证检验信息披露特征、文本特征是否能够在较大程度上提高模型对公司股价崩盘的预测效果(见表4)。

表4 模型拟合结果Tab.4 Model fitting results
首先通过模型纵向对比发现,将信息披露特征、文本特征单独加入模型后,拟合效果较基准模型都有了显著提升,其中最为明显的是MLP模型的Kappa值由原来的0.594 4上升到0.616 2与0.613 7,此结果初步显示出信息披露特征与文本特征对股价崩盘风险有预测效能。资本市场中投资者大多偏向于关注企业的财务数据进而做出投资决策,从而忽略了文本信息的作用,这并不意味着文本信息的价值低于财务信息,相反文本信息有着更大的挖掘价值。现有文献基于文本挖掘技术发现MD&A文本能有效预测公司财务风险。
进一步同时加入信息披露特征与文本特征,结果显示所有模型的拟合效果较之前又有了显著提升。这可能是因为虽然中国证监会对财务数据的监督制度越来越完善,但相比之下文本信息的监督还有空白,这使得公司管理层由传统的盈余管理转向文本信息操纵,尤其是有股价崩盘风险的公司更有动机操纵文本信息。管理层采取的印象管理手段主要包括年报篇幅、语调、文本可读性等,以往研究基于印象管理理论发现,管理层通常会在发生危机时对文本进行不同程度的操作以期美化公司实况,在一定程度上增加投资者粘性、减小损失。而本文发现模型中加入信息披露特征与文本特征后对股价崩盘的预测性能上升,这不仅印证了印象管理普遍存在于上市公司年报文本信息披露中,而且发现具有印象管理的公司在未来更有可能发生股价崩盘,警示投资者除了关注企业的数据信息外,对文本非结构化信息的价值也不容小觑。
其次对模型进行横向对比,四个组别中MLP模型的Kappa值都大于其他模型,显示出MLP模型对股价崩盘风险预测的优越性。
(四)预测机制分析
MLP模型虽然具有良好的预测效果,但其缺乏解释能力,而树模型的一个最大优点是对预测“黑箱机制”进行解释。表5是XGBoost模型特征重要性排序结果,个股收益偏度(NCSKEW)权重为0.402 8,是最为重要的特征变量,此变量反映了股价崩盘具有股票获得异常负收益这一低概率事件的基本特征。除此之外,MD&A部分文本特征与MD&A部分信息披露特征在前20个特征重要性当中
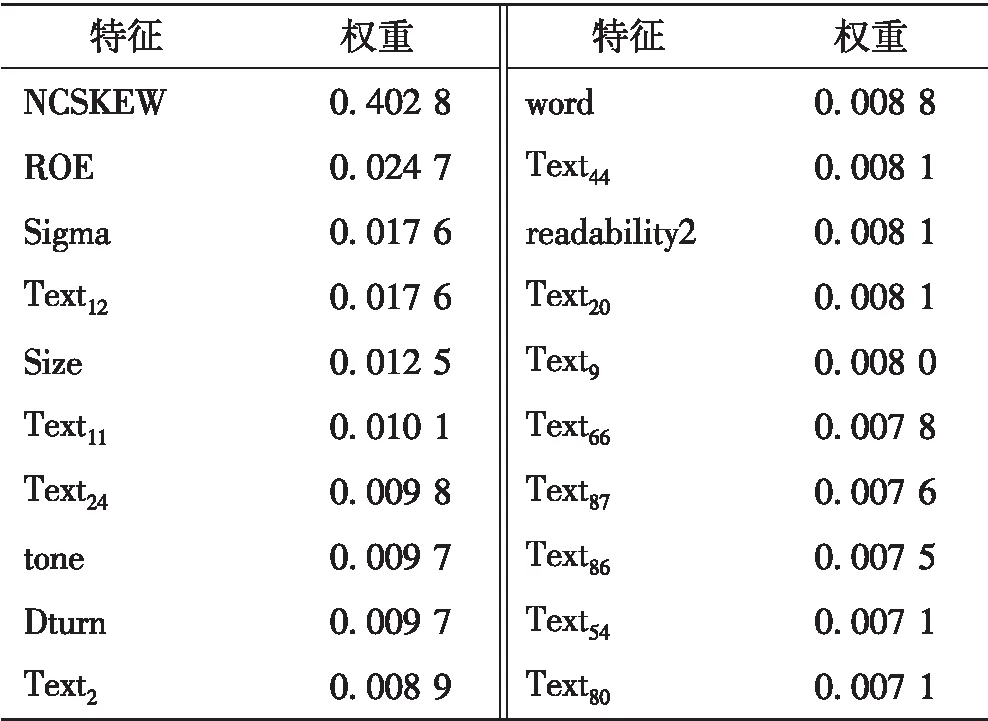
表5 特征重要性排序(前20个)Tab.5 Feature importance ranking (the first 20)
占有一定的权重,其中,MD&A可读性(readability2)、MD&A篇幅(word)与MD&A语调(tone)排名分别位于第十三名、第十一名与第八名,由此可以猜测管理层出于自利动机在公司股价崩盘风险发生之前存在文本操纵行为,以期减少股价崩盘所带来的损失,影响市场交易情绪。
特征偏依赖图能表现出关键特征与股价崩盘风险之间非线性的预测关系。MD&A信息披露可读性、文本篇幅、文本语调与股价崩盘风险之间的动态变化关系由图2、图3与图4反映,其中,可读性指标(readability2)与股价崩盘风险呈现出类似指数曲线的关联关系,这说明管理层会在股价崩盘之前操纵文本信息,通过在文本中加入更多的无关词汇干扰年报信息使用者对信息的解读,且随着可读性指标的不断增大,即文本愈发晦涩,对股价崩盘风险的正向影响越强烈。文本篇幅指标(word)与股价崩盘风险呈现出负向影响的关系,虽然在中段出现了波动,但整体上保持着负向影响,即文本篇幅越短,股价崩盘风险越大,反映出管理层可能在股价崩盘风险发生之前刻意隐匿公司的不良业绩和表现,以期减少利益相关者对公司的质疑。文本语调(tone)与股价崩盘风险之间呈现出较为复杂的关系,在0.2~0.55区间段内,呈现出正向影响关系,即在股价崩盘风险发生之前,管理层会使用积极的语调试图转移投资者的注意力,通过一些战略噪声或管理层的美好愿景去掩饰公司业绩不良的本质表现;但指标取值在0.55之后,文本语调对股价崩盘风险会产生负向影响,这说明管理层对预期股价崩盘的辩解强度是在一定的范围之内,临近股价崩盘时过于积极的语调反而适得其反,对于利益相关者面临的巨额亏损,管理层也会做出审慎的决定,相对客观地对MD&A信息进行披露。
四、结论与启示
利用文本挖掘技术对上市公司年报中的文本信息——管理层讨论与分析(MD&A)进行分析,通过TF-IDF算法提取出文本特征并利用词典法与jieba分词工具构建信息披露特征指标,结合相关市场交易特征与经营特征对公司股价崩盘建立风险预测模型。研究发现:发生股价崩盘的公司与正常经营公司的MD&A文本特征存在显著差异;相比于决策树模型、梯度提升树模型与极端梯度提升树模型,前馈神经网络模型对股价崩盘风险的预测效果最优,这一结果在加入MD&A信息披露特征与文本特征之后更为显著;文本信息可以预测股价崩盘风险,文本可读性会正向影响股价崩盘风险,文本语调和篇幅会负向影响股价崩盘风险。
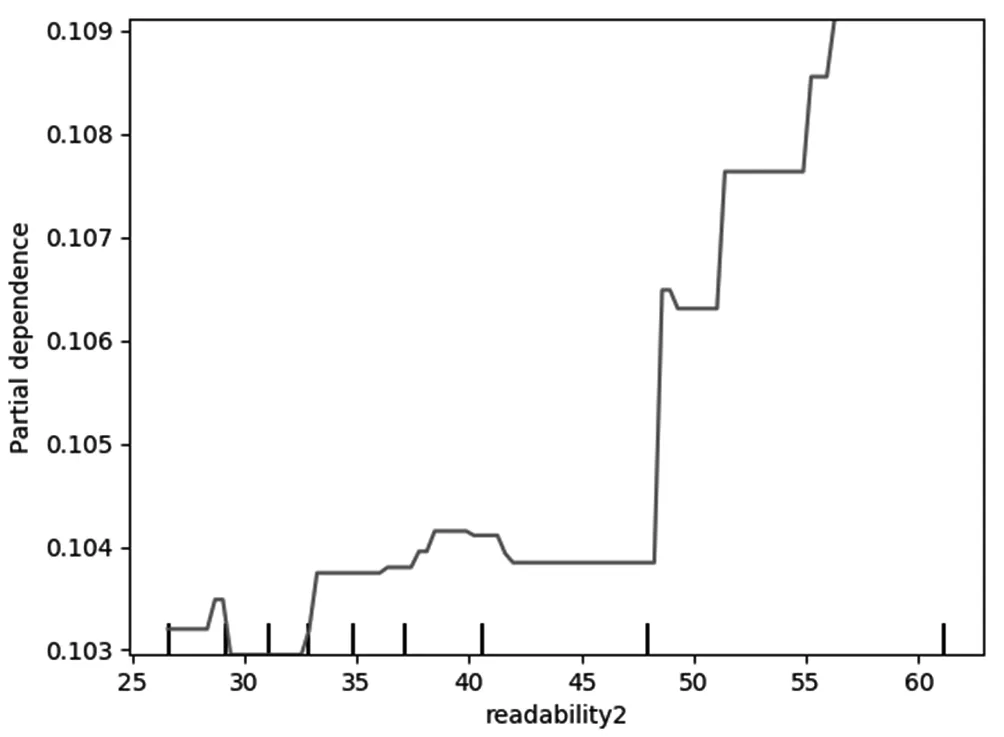
图2 MD&A信息披露可读性与股价崩盘风险偏依赖图Fig.2 Readability of MD&A information disclosure and partial dependence of stock price collapse risk
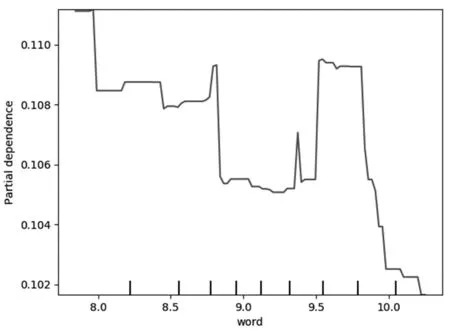
图3 MD&A文本篇幅与股价崩盘风险偏依赖图Fig.3 MD&A text length and stock price crash risk dependence chart
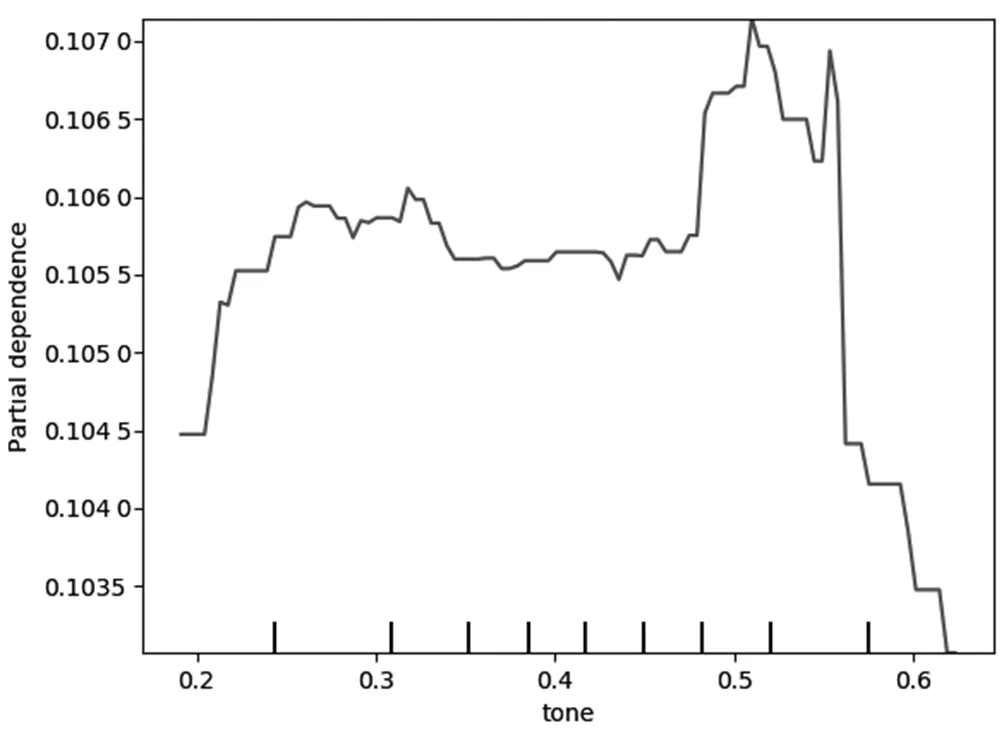
图4 MD&A文本语调与股价崩盘风险偏依赖图Fig.4 MD&A text intonation and stock price crash risk partial dependence chart
从公司内部视角来看,在降低公司投资活动风险与完善内部治理机制时,非财务信息越来越受到利益相关方的关注,企业年报中的文本信息披露在缓解投资者与股东的信息不对称问题中发挥着重要作用。利用文本挖掘的方法构建文本信息指标预测公司股价崩盘风险是对非财务信息预测性能的有益探索,有效防范股价崩盘风险有利于公司的可持续经营,更好地提升公司业绩。
从债权人、投资者视角来看,由于信息不对称,利益相关方是信息链条的接收方,在信息获取方面处于劣势地位。股价崩盘风险预测模型为其提供了一种新的判别方式,改变了以往通过财务数据进行决策的单一路径,债权人以及投资者能够通过企业年报中MD&A部分的文本信息提前预测企业发生股价崩盘的风险,避免不必要的损失。
从监管视角来看,我国资本市场起步较晚,监管机制也在不断完善,近年来随着公司年报披露内容和方式的改变,文本信息披露在年报中所占的比重日益加大,但是对文本信息的监管却不到位,让管理层操纵有机可乘。鉴于此,监管机构应尽快出台相应的文本信息披露监管制度,更好地保障资本市场健康运行。
机器学习方法的日益成熟为大数据挖掘提供了更为有效的工具,在今后的相关研究中,可以更多地利用机器学习或是深度学习建模关注文本信息对于预测公司业绩、经营风险的作用,比如通过公司年报其他章节、社会责任报告、公司研报或投资者评论等进一步挖掘文本信息和文本特征的使用价值。
猜你喜欢
理财周刊(2023年11期)2023-11-08 00:37:19
小学生学习指导(高年级)(2021年4期)2021-04-29 02:17:10
河北理科教学研究(2020年2期)2020-09-11 06:15:48
股市动态分析(2019年42期)2019-11-13 01:55:04
劳动保护(2019年7期)2019-08-27 00:41:22
股市动态分析(2016年2期)2016-09-27 21:22:52
财经界(学术版)(2015年13期)2015-12-19 05:55:15
湖湘论坛(2015年4期)2015-12-01 09:30:02
数学年刊A辑(中文版)(2015年2期)2015-10-30 01:56:14
新高考·高二数学(2014年7期)2014-09-18 00:42:02
