
一种分布式数据存储方案设计与实现
2022-04-02 03:18余丹萍
电脑知识与技术 2022年33期
余丹萍



摘要:传统的基于关系型数据库的分布式存储主要通过引入中间件对数据进行水平或垂直拆分来实现,这类中间件主要适用查询主键存在单调递增或单调递减的情况,针对查询主键不符合该要求的,该文设计并实现了一种分布式数据存储方案,基于数据库号段模式生成单调递增的分布式ID作为关系型数据库的拆分主键,借助MongoDB存储查询键值和拆分主键的关联信息。实验结果表明,该方法可以有效实现海量数据的分布式存储。
关键词:关系型数据库;分布式存储;分布式ID;海量数据
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2022)33-0068-03
1 引言
目前比较常用的分布式数据存储[1]方案,主要是在关系型数据库中間加一层数据库分库中间件,通过将查询键值作为拆分字段,用一定的路由算法,将原始SQL进行解析后构建出新的SQL路由到指定的分节点,最后对结果集进行归并。比较常用的中间件有dble[2]、Sharding-sphere[3]等。dble是基于MySQL的高可扩展性的分布式中间件,是基于开源项目MyCat[4]的,但取消了许多其他数据库的支持,专注于MySQL,对兼容性、复杂查询和分布式事务的行为进行了深入的改进和优化,修复了MyCat的一些bug。ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar这3款相互独立的产品组成。他们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如Java同构、异构语言、容器、云原生等各种多样化的应用场景。这些中间件都有一个特点,主要适用于电商交易、金融交易等查询主键单调递增或单调递减的场景,选取这类主键作为拆分键,易于实现数据的均匀拆分。对于查询主键不具有单调递增或单调递减特性,一般通过一致性hash算法[5]进行路由分库,能做到数据的大致均匀拆分,但是当节点增加时,仍然需要重新迁移一部分数据以适应节点数量变化带来的路由结果改变。
针对上述问题,设计了一种分布式数据存储方案,基于高性能非关系型数据库MongoDB [6]存储查询键值和拆分键值的索引信息,实现针对查询键值为完全随机无序字符串的数据存储的均匀分布,有效降低海量数据[7]对单节点的压力,提升数据的读写效率,同时当节点增加时无须动态迁移数据,实现节点轻松扩容。
2 相关技术
2.1 分布式ID生成技术
分布式ID在业务系统中很常用,如电商交易、金融交易等业务系统中的订单号,这个ID往往就是数据库中的唯一主键,通常需要满足唯一性、有序性、可用性、安全性等特性:
唯一性:生成的ID全局唯一;
有序性:生成的ID按照某种规则有序,便于数据库插入和排序;
可用性:在高并发情况下能正确生成ID;
安全性:不暴露系统和业务的信息。
常见的分布式ID生成技术主要有数据库自增ID、UUID、REDIS[7]生成ID、SNOWFLAKE雪花算法等。
数据库自增ID使用数据库的ID自增策略,如MYSQL的AUTO_INCREMENT,该方案简单,生成的ID有序,缺点是在单个数据库或读写分离或一主多从的情况下,存在单点故障风险。
UUID通常根据平台提供的生成API,按照开放软件基金会(OSF)制定的标准计算,生成的ID性能非常好,全球唯一,产生重复的概率非常低。缺点是UUID无法保证趋势递增,并且往往是使用字符串存储,查询效率比较低、存储空间比较大、传输数据量大。
REDIS生成ID是利用REDIS的原子操作INCR和INCRBY来实现,性能优于数据库,ID有序,缺点是需要编码和配置的工作量比较大,增加系统复杂度。
SNOWFLAKE雪花算法是Twitter开源的分布式ID生成算法,在生成ID中引入了时间戳,按照时间在单机上是递增的,性能非常好,缺点是在分布式环境中,依赖于系统时间的一致性,可能会出现ID冲突。
2.2 分库策略
在分库策略的选择上,比较常用的分库策略有范围分片、has取模分片、一致性hash分片等。每种分片策略都有其自身的优缺点。
范围分片:拆分键值为自增ID,指定一个数据范围来进行分库,每一定数量条记录分为一个库,这种分片策略优点是扩容非常方便,只需增加新节点,创建数据库和表即可,不需要对旧的数据进行分片迁移。缺点是可能存在IO瓶颈,当业务的大部分数据读写都在新节点的时候,会对新节点造成比较大的压力。
hash取模分片:根据拆分键值的hash值mod一个特定的数值得到的结果即为对应的库,这种分片策略优点是能保证数据比较均匀地分散在不同的库中,减轻数据库的IO压力。缺点是扩容麻烦,每次扩容的时候都需要对所有数据按照新的路由规则重新计算分片进行迁移分配到不同的库中。
一致性hash分片:一致性hash算法是将整个hash值空间映射成一个虚拟的圆环,整个hash空间的取值范围为0~232-1,将拆分键值使用hash算法算出对应的hash值,然后根据hash值的位置沿圆环顺时针查找,第一个遇到的节点就是所对应的库。这种分片策略克服了hash取模分片的不足,当扩容的时候,只需要重定位环空间中的一小部分数据。
3 方案设计
一种分布式数据存储方案基于数据库发号算法实现生成分布式ID作为数据库拆分键,利用MongoDB存储查询键值和拆分键值的索引信息,实现针对查询键值为完全随机无序字符串的数据在关系型数据库存储的均匀分布。
该方案有3个关键之处:一是生成全局分布式ID,二是利用MongoDB存储与查询索引信息,三是分库实现。
3.1 分布式ID生成
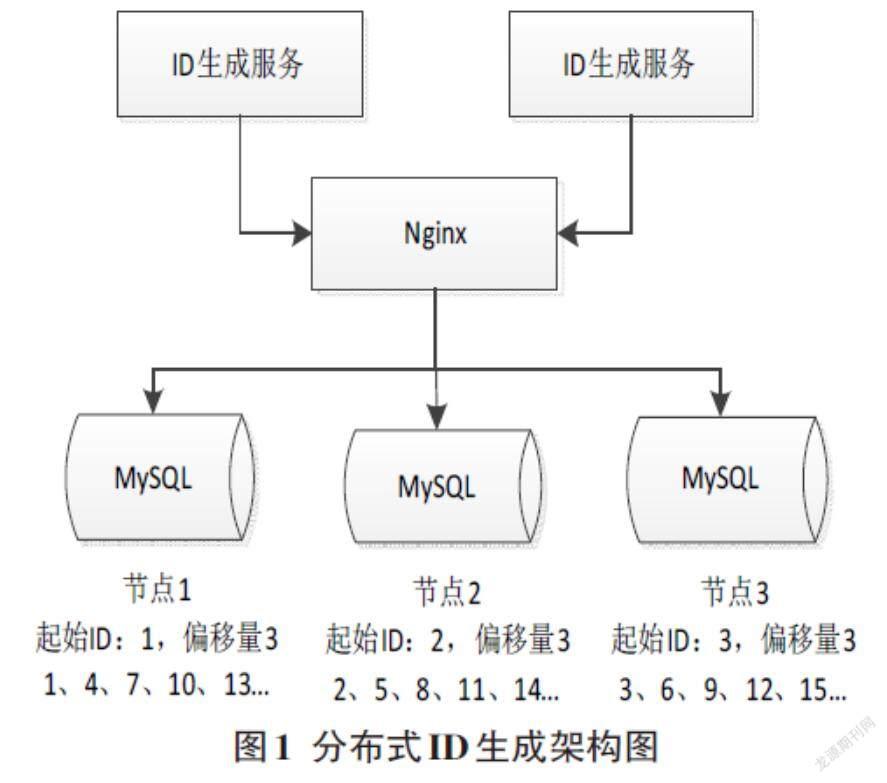
设计一种分布式ID生成方案,简单来说就是数据库中保存了可用的ID号段,系统将可用的号段加载到内存中,之后生成的ID会直接从内存中产生,当内存中的ID用完时,更新数据库可用ID号段,如此反复。为了解决数据库单点问题,可以配置多节点,每个节点指定一个不重复的起始ID,按照指定的偏移梯度生成ID。
图1为分布式ID生成架构图,有3个数据库节点发号,节点1起始ID设置1,节点2起始ID设置2,节点3起始ID设置3,每个节点按照3的梯度进行ID生成,那么节点1生成的ID为1、4、7、10、13……,节点2生成的ID为2、5、8、11、14……,节点3生成的ID为3、6、9、12、15……,这样可以保证每个节点生成的ID都不重复,并且当有节点宕机的时候生成的ID仍然趋势递增。
3.2 索引关系存储与查询
由于业务中的查询键值为完全随机的字符串,不适合直接用来做分库拆分键,因此设计首先生成分布式ID作为业务主键,同时作为分库使用的拆分键值,利用MongoDB存储该拆分键值和查询键值的索引关系,如图2所示,指定查询键值作为_id字段,与拆分键值建立唯一对应关系存储于MongoDB中。
关系型数据库中存储的业务数据如图3所示,拆分键值作为业务数据表的主键,其他字段则存储查询键值和其他业务数据。
当存储业务数据的时候,首先获取分布式ID作为业务数据关系数据表的主键(拆分键值),同时建立该主键ID与业务数据查询键值的索引关系表存储于MongoDB中,当索引表在MongoDB中存储成功后,再对该主键ID按照分库算法,将业务数据路由到指定的关系型数据库中进行存储。当通过查询键值查询该条业务数据的时候,首先在MongoDB的索引表中查找出与该查询键值对应的拆分键值,再对该拆分键值按照与插入时一致的分库算法,将业务数据从路由到的关系型数据库中查询出来。同样的,当需要根据查询键值更新或删除业务数据的时候,先根据该查询键值在MongoDB中查询得到对应的拆分键值,然后根据同樣的分库算法路由到对应的关系型数据库中,对对应的业务数据进行更新或删除。
3.3 分库实现
结合我们的业务特点,我们选择范围分片对我们的业务数据进行水平拆分。因为范围分片扩容简单,而且扩容的时候不需要对原有数据做任何迁移,只需要创建新的节点数据库和数据表就可以,并且由于我们的业务数据和电商交易、金融交易的数据特点不同,电商交易、金融交易等业务大部分读和写都会访问新数据,会造成新的数据节点的压力过大,而我们的业务数据主要特点为:
1)数据体量大,单库单表不做拆分的话,数据量能达到上亿条,这对关系型数据库的压力非常大。
2)读数据没有热点效应,所有数据访问概率相同,对读取数据性能要求较高。
3)写数据的压力不如电商交易等平台,最大瞬时压力单节点完全可以支撑。
综合考量,范围分片可以作为这种业务数据特点的首选,如图4所示,拆分键值为分布式自增ID,每1000万条记录分为一个库,那么主键为1到10000000对应的业务数据在节点1,主键为10000001到20000000对应的业务数据在节点2,依此类推。
4 总结
文中设计了一种分布式数据存储方案,实现针对查询键值为完全随机无序字符串的业务数据在关系型数据库的均匀拆分存储,结果表明该方案能有效降低海量数据对单节点的压力,提升数据的读写效率,当节点增加时无须动态迁移数据,实现节点轻松扩容。
参考文献:
[1] 宋云奎,吴文鹏,赵磊,等.基于Redis的分布式数据存储方法[J].计算机产品与流通,2020(8):106.
[2] DBLE分布式中间件[EB/OL]. https://github.com/actiontech/dble-docs-cn
[3] ShardingSphere概览[EB/OL].https://shardingsphere.apache.org/document/legacy/3.x/document/cn/ove-riew
[4] 陈宇收.基于Mycat的分布式数据存储研究[J].中国新通信,2018,20(22):63-64.
[5] 李宁.基于一致性Hash算法的分布式缓存数据冗余[J].软件导刊,2016,15(1):47-50.
[6] MongoDB[EB/OL]. https://www.mongodb.com/docs/
[7] 王艳松,张琦,庄泽岩,等.面向海量数据的存储技术发展分析[J].通信管理与技术,2021(5):12-15.
【通联编辑:梁书】
