
基于Python爬虫的旅游网站数据分析与可视化设计分析
2022-04-02 01:25李轩宇,赵颖,肖忠良,李轩
电脑知识与技术 2022年33期
关键词:数据分析
李轩宇,赵颖,肖忠良,李轩

摘要:网站與搜索引擎中爬虫属于核心元素,网络爬虫可以在网络中快速抓取海量有用信息。为了对旅游网站中信息数据展开爬取,对网站中热门景点与热门地区进行分析,研究一种以SCRAPY框架为基础的网络爬虫,分析爬取的数据,借助第三方库对数据信息进行可视化处理。最终试运行结果显示,该程序可以对微博、马蜂窝与其他数据量密集网站进行有效爬取。
关键词:Python爬虫;旅游网站;数据分析;可视化设计
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2022)33-0058-03
当前,在线旅游已经成为人们新兴生活模式,发展迅速。在线旅游主要指游客借助网络为游客提供预订旅游服务或是产品,同时借助线下付费、网上支付,旅游公司借助网络营销旅游产品。此过程,游客借助搜索引擎对旅游信息进行浏览、查询。在出现海量数据之后,搜索引擎重要性开始显现出来,为了对所需信息进行快速搜索,Python爬虫开始引起民众注意[1]。
1 Python爬虫技术及语言优势
1.1 Python爬虫技术
网络爬虫,主要是根据相应规则对旅游网站中脚本或是程序进行自动抓取,在网站设计、搜索引擎等方面具有广泛应用。在舆情监控、Web安全、科学研究以及数据分析等方面应用广泛。在图像处理、机器学习以及数据挖掘等领域,借助脚本程序编写,在网上完成信息爬取,为研究活动提供良好数据支持。
1.2 Python语言优势
(1)Python语言具有较大灵活性与强大性特点,相比于Java、C++、C等语言,该语言语法简单,无须设置复杂代码即可以实现强大功能。比如,Java语言需要设置100行代码才可以实现相应功能,而Python仅需要设置50行代码即可以实现相应功能,充分减小学习难度。
(2)Python具有开源免费优势,即无须花费任何费用即能够使用,人们直接下载即可,同时可以修改其源码,具有良好便捷性[2]。
(3)效率高。Python第三方库较为强大,人们下载调用库,并以此为基础开展开发作业,即能够实现复杂功能,有效节省功能开发时间,防止重复开发现象。
(4)Python具有较强可移植性。因为Python开源性特点,所以Python可移植性良好,可以在其他平台移植Python,比如苹果、安卓、Linux、window等系统。
2 基于Python爬虫的旅游网站数据分析
2.1 旅游网站数据分类
(1)聚焦型爬虫网站数据。此类数据主要是基于网络爬虫,添加步骤与机制,进而实现特定功能。借助制定规则,将不需要或是已经抓取的旅游数据过滤掉,可以快速通过网络抓取海量有用信息,此种爬虫数据工作量小、目标明确。
(2)Deep web爬虫数据。涵盖depp web与surface web两种类型,前者主要是爬取动态网络;后者一般针对深层网络与表层网络,一般爬取静态旅游网站。
(3)增量式爬虫数据。对于已经爬取的旅游网站开展添加与更新操作,其难度较大,但是时间成本小,在算法方面具有较高要求。
(4)通用型爬虫数据。目标范围广泛,但是爬行效率低,无法保证旅游数据抓取质量。
2.2 Python爬虫下的数据分析
在云计算和大数据技术快速发展过程中,MongoDB数据库得到广泛应用。MongoDB主要是面向信息储存,其能够把数据信息储存成文档,信息结构由键值对构成,并且字段值能够涵盖其他文档数组与文档/数组。该数据库可以为Web提供可拓展数据库处理方案,具有易使用、易部署、可拓展、高性能等特点。
数据可视化可以将数据信息更加直接、有效地反映出来,保证数据分析质量,借助柱状图对各个地区旅游热度进行展现。旅游地区热度借助该地区景点的受关注情况进行体现,其参照点为热度与级别。按照热门景点实际出现频率,同时根据其热度对全国热门地区开展统计分析,按照地区热门景点出现频率,开展求和计算,进而得到该地区热度情况[3]。
3 基于Python爬虫的旅游网站数据的可视化设计
3.1 程序描述
本文Python爬虫代码系统涵盖3个代码段模块,就是操作预备、跟踪捕获与分析整理3个代码段模块。
操作预备模块核心功能如下:跟踪捕获数据初期,即限制完成data类型,在计算机中网络使用者的识别名称进行转变,或是对自动登录信息进行转变,实现多次访问。
对于跟踪捕获模块,核心功能如下:主体款框架,通过第一个定义的网站网络页面进行跟踪捕获,完成相应操作后进行筛选识别,通过返回数值相应范式将各个回调函数启动。
分析整理模块,主要承接上述操作,对data进行解构,评价data是否符合提前制定data范式要求,若是所获data为相同类型数据,可以通过MongoDB或是Not only sql进行储存,否则可以将其统一地址符向排列模块传输进行排列,用于跟踪捕获[4]。
3.2 程序架构与开发
(1)操作预备模块。在该代码模块中,需要限制data。此时研究人员可能使用IRM.PY文件,其属于data跟踪捕获容器,其对跟踪捕获操作中数据类型规则进行了定义。对于爬虫代码系统,编写人员针对所捕获数据根据以下方法对类型进行限制。
Class Score,对旅游网站中酒店评价数据范式进行限制。
Class Locatinon,对所捕获酒店地址数据范式进行限制。
Class Commeent,对所捕获酒店入住评论数据范式进行限制。
Class Facilities,对所捕获酒店的硬件设施信息数据范式进行限制。
以下是Facilities具体定义,可以选择Field()代码对data进行限制, 如下所示:
[Class FACILTIESItem:]
["酒店硬件"]
[_id=Field()#酒店识别号]
[Name=Field()#酒店名称]
[Key words=Field()#关键词]
[Web=Field()#网络设施]
[Transportation=Field()#交通设施情况]
[Children’s facilities=Field()#儿童设施情况]
[Breakfast fast=Field()#早餐信息]
[Pet=Field()#宠物信息]
[Room=RField()#房间数量]
[Open=Field()#开业时间]
(2)跟踪捕获模块。SPIDERS.PY文件中分布着该字段的程序表述,其是本文爬虫代码程序关键功能单元。在该功能单元中编码人员对Tourism Spinder类进行限定。
第一、HOST与NAME代码解释。HOST对跟踪捕获范围进行限制。NAME主要是对SPIDER称呼规范完成。
第二、START_URLS解释,其代表先启动原始资源符地址的排列顺序表,指引爬虫代码程序先跟踪的对象。代码程序即刻跟踪捕获网站信息页请求,实现跟踪捕获。基于此种场景,为了保证编写便捷性,选择域名代表号ui资源符地址进行表示。为了保证程序可以对正规、完整的url进行体现,可以借助限定方式对HOST限制域和域名代表号进行结合。
第三、[FINISH_ID:SET()]与[SCRAWL_ID]函数主要利用SET系统变量对所捕获url与基金捕获url进行替代,此种方式能够防止重复操作。
在[TOURISM SPIDER]中,编写人员对核心功能函数进行限制。包括[PARSE0()]、[START_REQUESTS()]函数。[START_REQUESTS()]主要是将网站信息页触发;[PARSE0()、PARSE1()]等与酒店评分、酒店地址、入住评论、硬件设施等数据相对应[5]。
(3)后续信息处理。SPIDERS.PY文件能够细致完成系统性、整套操作,可以将其作为信息处理系统,如下所示:
[class Mongo DBPiplelineobject:]
[def _init_(self):]
[clinet=pymongo.Mongo client“localhot”,27017]
[db=client["mafengwo"]]
[self.FACILITIES=db["COMMENT"]]
[self.LOCATION=db["LOCATION"]]
[self.SCORE=db["SCORE"]]
[defprocessitemself.item,spider:]
[if isinstanceitem,FACILITIES Item:]
[try:]
[self.FACILITIES.insert(dict(item))]
[except Exception:]
[pass]
SPIDERS.PY对Mondo Dbpipeline含义进行限制,涵盖2种方式,与MongoDB通信主要借助Pymongo字码段实现。
[clinet = pymongo.Mongo Client("localhost", 27017)]
进行与data客户端接口,在后续开启“mafaengwo”名称data库,各个代码段构建SCORE、LOCATION、FACILITIES以及COMMENT表格,主要功能就是对相关数据进行储备。
[PROCESS_ITEM()]可以对IEM结构范式进行评价,若是评价结果属于FACILITIES则向相应表格中插入。在此环节,可以进展到末端data处理[6]。
3.3 程序调试与运行
(1)试运行软硬件。选择Windows7系统,软件选择[Python 2.7 SCRAPY 1.0];硬件选择[INTEL COREI7-3317u @1.70ghz 8G ram],网络环境选择100兆的光纤宽带。
(2)爬虫工作状态。进行试运行时,选择马蜂窝网站中酒店信息进行跟踪捕获,其效率可以达到300万/d。试运行时,需要稳定频率对Cookies中用户信息进行变动,尽量预先存储足够用户信息。并且Mongo DB工作状况优良,在数据量处理方面符合要求。
(3)信息data的获取。启动代码程序,生成数据库,名称为Mafengwo,对四个表格进行存储。对酒店中的硬件信息、酒店入住评论信息与酒店地址信息、评价数据信息等进行功能性实施,本文对COMMENT和FACILITIES情形进行典型性阐述。
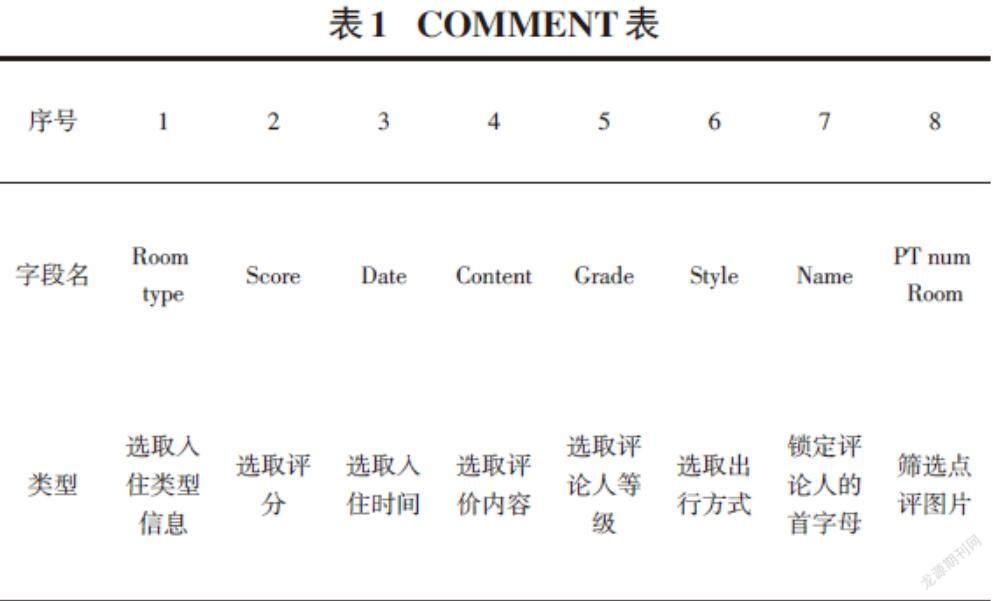
基于直观对比数据的考虑,导出爬取结果,建立Excale文件。按照上述爬取能够获得COMMENT表。见表1所示。
同理,获得FACILITIES表。
(4)爬取數据的价值。本程序爬取旅游网站数据之后,借助这些信息对网站流量、网站中酒店数量、酒店详细信息、用户对于酒店的评价等进行分析。比如,彩虹云霄酒店的ID代号是14777,借助已经爬取信息,相关人员能够获得该酒店的关键词是“海景、美观、舒适、时尚”等,附近交通设施是“免费停车场”,网络条件是“Wi-Fi”等,评论区中为“适合观海,酒店与海边的步行距离为半小时”“网速快”“隔音效果非常棒”“早餐丰富”“服务态度非常差,不及时换床单”等。通过上述信息,游客能够了解酒店基本信息与客户的入住体验,另外,可以根据相应顺序具体编排这些信息,能够为到该地区游玩的游客提供酒店参考,具有良好商业价值[7]。
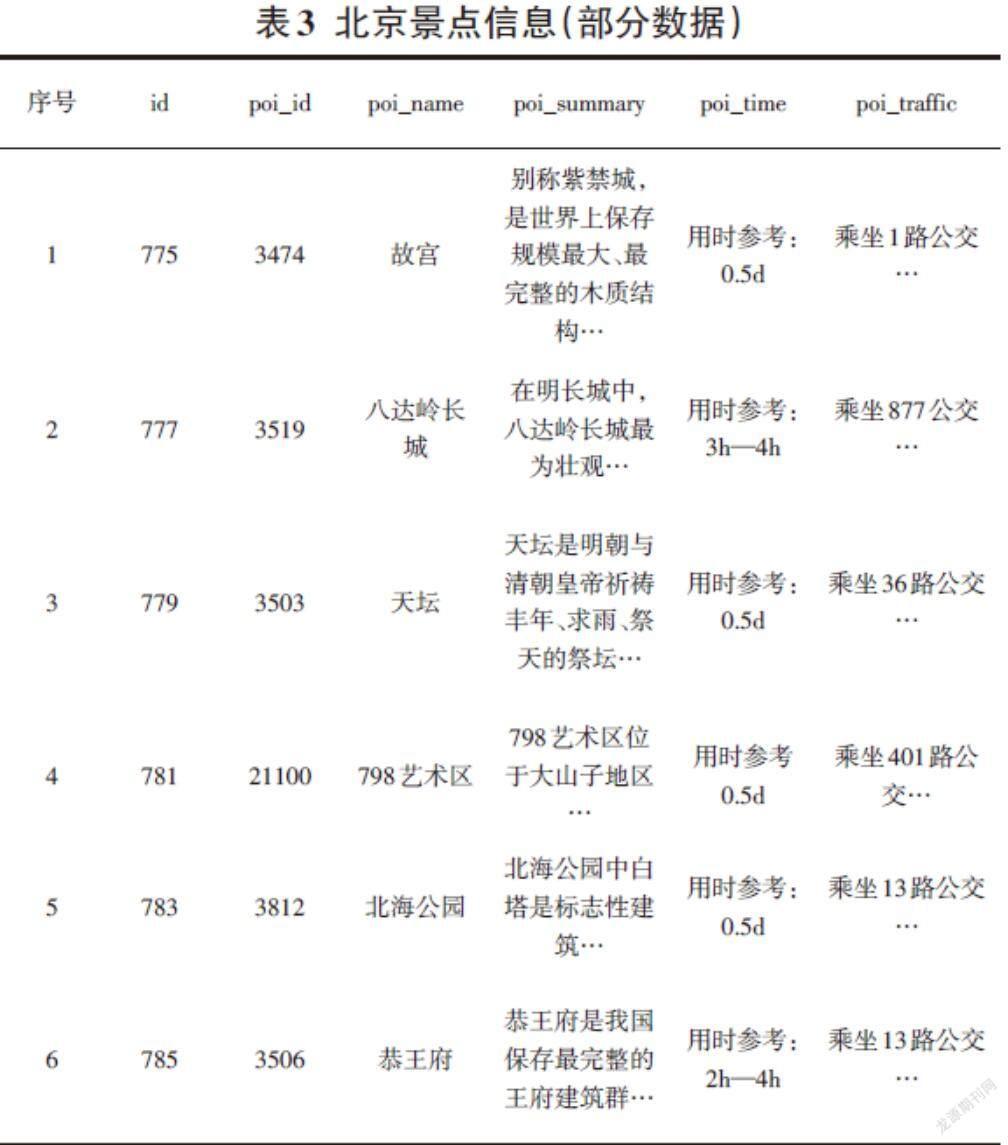
(5)其他结果。爬取马蜂窝网站中酒店信息之后,爬取马蜂窝网站中北京旅游景点数据。借助网站信息能够浏览景点介绍。涵盖景点经纬度、门票、交通、开放时间与用时参考等,如表2所示:
之后爬取微博数据,观察微博中“周日”词条出现概率, 能够发现,周日为2020年2月2日,具有较高的出现频率,但是2月1日出现频率为何减小呢?主要是由于一些人会说“明天”。
结合上述爬取数据信息,该程序可以对微博、马蜂窝以及其他数据量密集的网站进行有效爬取。
4 总结
综上所述,本文以Python语言等为基础架构,建立高度拓展面、高度自定义的爬虫程序体系。该程序系统可以跟踪捕获各个网站中酒店信息,对酒店相关信息进行捕获。通过测试可以发现,SCRAPY程序结构编写爬虫程序,可以为用户带来良好体验,节省精力和时间。同时基于此种方式建立爬虫程序系统在工作时具有优秀的表现。
参考文献:
[1] 刘娟,管希东.基于Python爬虫的职位信息数据分析和可视化系统实现[J].软件工程与应用,2020(4):317-325.
[2] 贾艳平,翟晋刚.基于Python爬虫技术的游客评论数据可视化分析[J].安阳师范学院学报,2021(5):51-54.
[3] 方德涛.基于Python爬取POI在城市地理国情监测中的应用[J].地理空间信息,2021,19(6):79-82,I0002.
[4] 李超,唐义杰.基于案例的大数据分析课程教学研究——以网络数据收集和数据可视化教学内容为例[J].白城师范学院学报,2019,33(6):56-61.
[5] 曾诚.基于Python的网络爬虫及数据可视化和预测分析[J].信息与电脑,2020(9):167-169.
[6] 张俊威,肖潇.基于Python爬虫技术的网页数据抓取与分析研究[J].信息系统工程,2021(2):155-156.
[7] 王子予,郝艳华,关涵文,等.基于Python网络爬虫技术可视化分析公众应对暴雪冻雨气象的反应[J].中华卫生应急电子杂志,2021,7(6):379-381.
【通联编辑:唐一东】
猜你喜欢
商情(2016年40期)2016-11-28
科技资讯(2016年18期)2016-11-15
考试周刊(2016年84期)2016-11-11
商场现代化(2016年22期)2016-10-18
