
基于单目视觉的车辆3D空间检测方法
2022-04-01 11:36顾德英孟范伟
东北大学学报(自然科学版) 2022年3期
顾德英, 张 松, 孟范伟
(东北大学秦皇岛分校 控制工程学院, 河北 秦皇岛 066004)
随着自动驾驶的兴起,基于2D图像的目标检测不能描述立体空间信息,这就对3D目标检测有了更多的需求. 当前3D目标检测算法主要有基于单目、激光雷达、激光雷达和单目融合等[1],虽然基于激光雷达检测有较高的检测精确率,但激光雷达非常昂贵,配置在每一个车上还不太现实.因此研究基于单目的3D目标检测具有现实意义.
基于单目的3D目标检测,国内外的学者进行了很多研究,取得一定的成果.Chen等[2]提出生成一组类相关的物体推荐候选框的方法,然后在一个CNN(convolutional neural network)中利用这组候选框提取出高质量的3D物体包围框.然而这种方法需要复杂的预处理,不适合在有限的计算资源下进行.Pavlakos等[3]用CNN定位关键点,并且利用关键点和3D坐标去复原位姿,但是这种方法需要配置标注的关键点来训练数据.Roddick等[4]引入一种将特征映射(基于透视图像)转换为鸟瞰图的正交变换,然后在鸟瞰图上自由地回归车辆的三维尺寸和方向.Brazil等[5]提出一个端到端的区域建议网络用于多类别的3D目标检测,统一2D检测和3D检测在一个框架内,避免引起持续的噪声.Weng等[6]从单目图像中提取深度信息转成伪激光雷达点云,然后利用基于点云的方法去回归3D属性.但是转换的伪激光雷达点云的密度比较低,进而导致检测出的3D包围框精确率也不是很高.Liu等[7]将单个关键点估计与回归三维变量相结合来预测每个对象的3D包围框,提出了一种构造三维包围框的多步分离方法,这种方法不需要复杂的预/后处理.综上所述,基于单目的3D目标检测虽然已经取得一系列研究成果,但是3D包围框检测精确率还是不理想,而且实现过程复杂,同时在提取特征阶段都是利用卷积网络提取深层特征图,虽然深层特征体现强语义特征,但特征的分辨率比较低,且特征图上小物体的有效信息较少,特征细节不丰富.
本文在Deep3DBox[8]两阶段方法的基础上,利用改进的FPN(feature pyramid networks)特征融合、 ResNet残差单元、全连接层组合成新网络,并在分割的KITTI验证集上进行了实验,结果表明此改进的方法提高了车辆3D包围框平均精确率(AP3D)这个性能指标.
1 改进的FPN、残差单元、全连接层网络
1.1 参数定义
处理基于单目的3D车辆检测问题,输入彩色图像X∈RH×W×3,检测输出左上和右下的2D框坐标A=(x1,y1,x2,y2)和3D框信息B=(h,w,l,x,y,z,θ).其中(h,w,l)代表车辆的高宽长,(x,y,z)代表车辆3D包围框中心点坐标,θ代表车辆的偏航角.在众多的车辆方向检测应用中,检测方向角为偏航角,而把翻滚角和俯仰角假定为零.
1.2 网络结构
在训练阶段,训练集图片通过改进的FPN特征融合提取特征,然后通过三个分支分别回归出车辆的三维尺寸、残差角度(Δθ)和置信度.将整个方向范围2π平均分为n个bins区间,这样任何一个预测的局部角度(α)就至少属于一个区间范围.因此每个预测的局部角度(α)可以用区间(选取置信度最大的bins区间)的中心角度加残差角度(Δθ)来表示.在回归残差角度(Δθ)时并没有直接预测Δθ的绝对值,而是选择回归(sin(Δθ),cos(Δθ))二维向量,再由这个二维向量计算出实际Δθ的绝对值.在推理阶段,利用验证集中所属类别车辆的外接矩形的边框真值坐标,在已经训练好的模型中检测出所属类别车辆的三维尺寸和局部角度.结合车辆的外接矩形的边框真值坐标、车辆的偏航角、几何约束(车辆的外接3D包围框投影到图片上,其投影区域的外接矩形应与车辆在图像上的二维边框相互贴合)、相机内参矩阵,计算得到所属类别车辆3D包围框的中心点坐标.车辆的偏航角θ=α+β,β为车辆所在位置与相机所在位置的连线构成的射角.最后利用车辆的外接矩形的边框坐标、车辆3D包围框的中心点坐标、车辆的偏航角(θ)、相机内参矩阵,复原绘制出车辆3D包围框.本文网络结构图如图1所示,车辆三维尺寸和方向示意图如图2所示.
1.3 改进的FPN特征融合
为了增强语义性,传统的物体检测模型通常只在深度卷积网络的最后一个特征图上进行后续操作,原方法中采用预训练的VGG network[9]在最后一层特征图上操作且对应的下采样率比较大,造成小物体在特征图上的有效信息较少,特征图上的特征细节不丰富,进而影响其检测性能.2017年的特征金字塔(FPN)[10]方法融合了不同层的特征,使特征信息优势互补.FPN表示的网络结构图如图3所示.
在基于单目视觉的车辆检测中,小尺度车辆占据了较大的比例,对于大尺度车辆,其语义信息出现在较深的特征图中,小尺度车辆则出现在较浅的特征图中,随着网络的加深,其细节信息可能会完全消失.因此,本文在FPN的基础上提出多层融合的方法,其结构如图4所示.其中,C2特征图尺寸为56×56×64,经过第一个3×3卷积使其通道变为256,同时2倍下采样得到的特征图尺寸为28×28×256;经过第二个3×3卷积通道数保持不变,但是依然2倍下采样得到的特征图为14×14×256.C3特征图尺寸为28×28×128,经过3×3卷积使其通道变为256,同时2倍下采样得到的特征图尺寸为14×14×256;FPN中的P4特征图尺寸为14×14×256.这样,3个不同信息层的特征图尺寸都为14×14×256.通过通道拼接得到的特征图尺寸为14×14×768,为了降低网络参数量,使用1×1卷积使其通道数降低为512.最后经过3×3卷积作平滑处理和ReLU作非线性激活,最终的特征图尺寸为14×14×512,此融合方法称为FPN-FU.研究发现应用此改进的方法将不同层信息进行融合,把深层高语义信息传递到下一层,然后把底层和次底层的高分辨率的信息传递到上一层,优势互补,获得了高分辨率、强语义特征,特征细节更丰富.
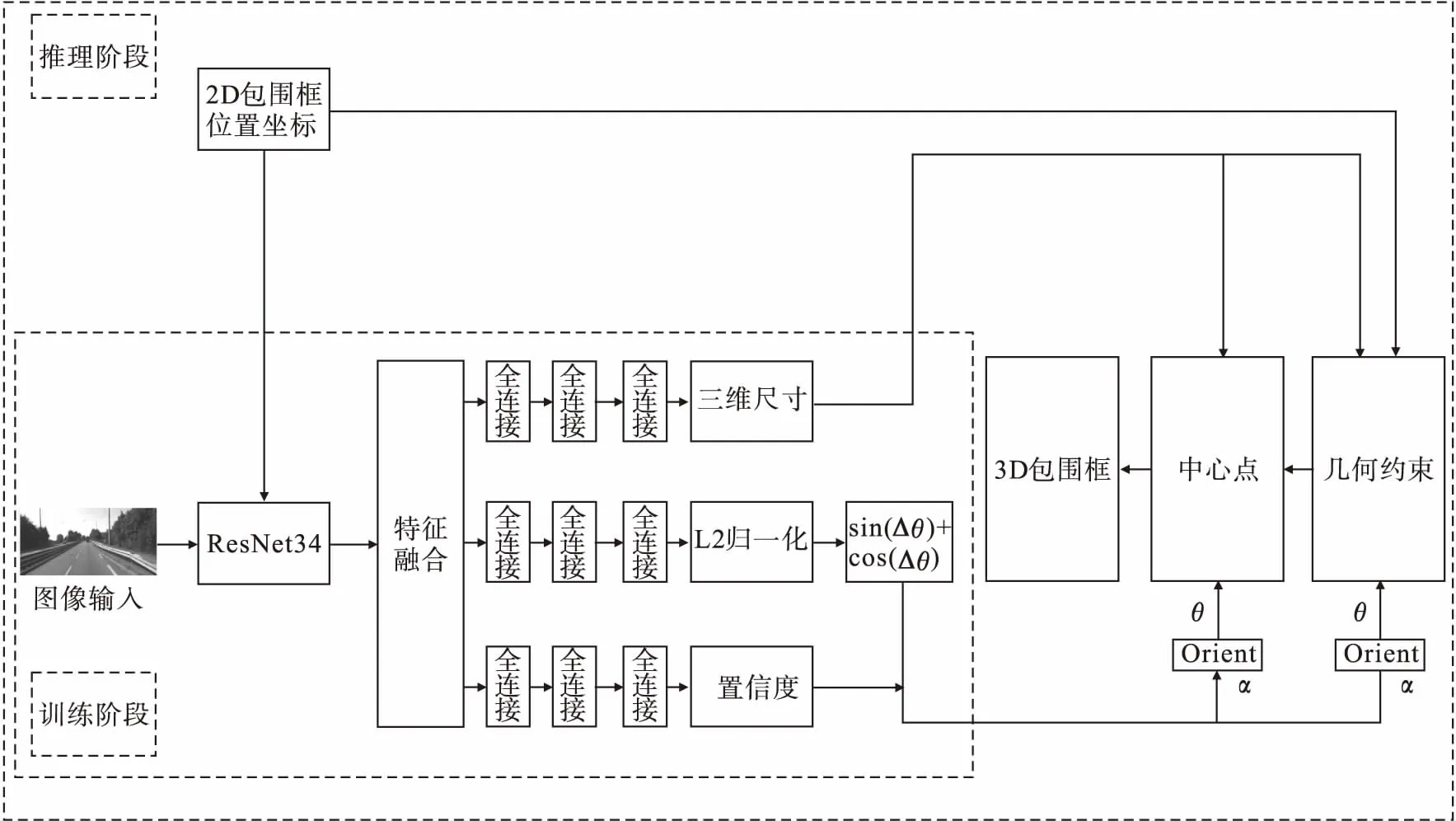
图1 网络结构图

图2 车辆三维尺寸和方向示意图[8]
1.4 改进的ResNet残差单元
ResNet[11]有多个堆积的残差单元组成,每个单元(见图5a)表示如下:
(1)
其中:xl和xl+1为第l个残差单元的输入和输出;F是残差函数;h(xl)=xl为一个恒等映射;f为ReLU激活函数.ResNet的思想是引入一个深度残差框架来解决梯度消失问题,即让卷积网络去学习残差映射,而不是期望每一个堆叠的网络都完整地拟合潜在的映射.
图5a中高速通道信号和由残差函数产生的残差信号逐元素相加,在第二个卷积层之后,逐元素相加的操作在BN层和ReLU层之间进行.然而原始的残差单元有一个缺点是ReLU操作后的输出和逐元素相加不匹配,这主要因为ReLU激活函数的非负值输出,导致它仅能提高高速通道信号,而限制了残差函数的表达能力[12].为了解决这个问题,提出改进的方法如图5b所示,去掉ReLU激活函数,替换高速通道的捷径连接(h(xl)=xl)为h(xl)=ELU(xl),由于ELU输出值的范围为(-∞,+∞),残差函数输出值的范围为(-∞,+∞),这样两者逐元素相加不通过ReLU激活函数,可以优化不匹配问题,且替换成这个连接之后不增加参数量和计算时间.此改进方法称为FPN-FU-ELU.在实验(应用在FPN-FU的方法上)中应用这种方法,实验结果证明改进的方法可以优化原始残差模拟中ReLU操作后的输出和逐元素相加不匹配的问题,提高检测性能.改进方法表达式为
(2)
在深度卷积网络中ELU[13]不仅能缓解梯度消失问题而且能加速学习,这可以使深度卷积网络得到较好的分类精度.ELU单元的表达式如式(3)所示,其表示的特性见图6.

(3)

图3 FPN网络结构图
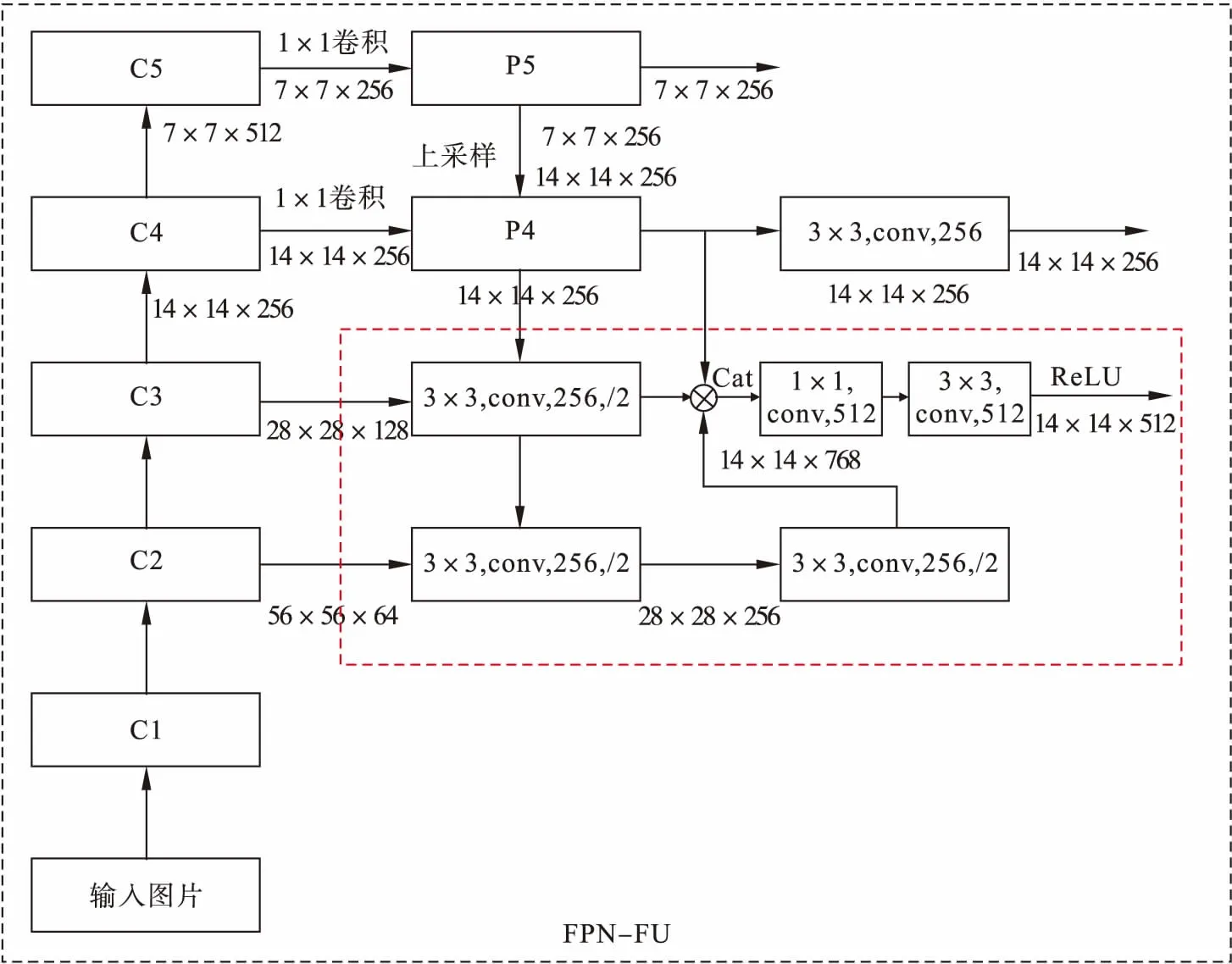
图4 改进的FPN特征融合
ReLU输出的是非负值,它的激活值的均值大于零.ELU输出有负值,它能推动激活均值更接近于零.当激活值的均值非零时,就会对下一层造成一个偏置,导致下一层的激活单元有偏置偏移.相比ReLU,ELU可以得到负值,这让单元激活值的均值可以更接近零,从而能减少偏置偏移,较少的偏置偏移能加速学习.ELU有软饱和特性,提高了对噪声的鲁棒性.

图5 原始和改进的残差单元

图6 ReLU和ELU(a=1)的特性比较
1.5 改进的全连接层
在图1的网络结构中,原方法中的三个独立分支都是两层的全连接层,本方法中全部换成三层的全连接层.把检测结果最好的方法(FPN-FU-ELU)应用在两层的全连接层进行实验,发现检测性能不如三层全连接层,且对比三层与两层全连接层的整个网络,发现三层的全连接层整个网络的参数量和训练时间与两层的全连接层整个网络的参数量和训练时间几乎相当.
2 实验结果及分析
2.1 数据集
本文的实验是在KITTI数据集上进行的,KITTI提供了7 481张图片用于训练,7 518张图片用于测试.由于测试集数据没有公开标注,通用的做法是把7 481张训练集图片分割为3 712张训练集和3 769张验证集[14],此验证集为Val1;另一种做法是分割成3 682张训练集和3 799张验证集[15],此验证集为Val2.Val1验证集中图片标号为000001.png,000002.png,000004.png等,Val2验证集中图片标号为000000.png,000002.png,000003.png等,相应的训练集内容也不一致,这样可以在不同场景来验证模型.KITTI对所有的目标物体按检测的难易程度进行分类,所有的物体分为三个等级:容易(easy),适中(moderate),困难(hard).这些等级根据每个物体被图像边界截断比例和被遮挡情况决定,具体标准如表1所示.

表1 KITTI物体的分类标准
2.2 结果分析
对于精确率(P)和召回率(R),其计算表达式如下:
(4)
(5)
其中:TP为正确检测出车辆3D包围框的三维尺寸和中心点坐标位置与真实框的三维尺寸和中心点坐标位置IoU(IoU计算的是 “预测的边框”和“真实的边框”的交集和并集的比值)≥0.7的样本数量;FP则为IoU<0.7的样本数量;FN为未检测到真实框的样本数量.
对于平均精确率AP,其计算表达式如下:
(6)
其中,ρinterp(r)表示在P-R曲线上,当r′≥r时(召回率r的区间点为R11={0,0.1,0.2,…,1}),找出召回率r′对应下的精确率P的最大值,AP则为这11个最大值的均值,则在本实验中利用AP计算的结果即为AP3D.
应用本文提出的改进网络检测到车辆3D包围框仿真图(见图7)以及数据结果(见表2,表3)说明如下:AP3D表示车辆3D包围框平均精确率;FC(3)表示利用改进的3层全连接层;FC(2)表示利用原始的2层全连接层.

图7 车辆3D包围框仿真图
(a)—改进的FPN、全连接层在验证集Val2下的仿真图; (b)—改进的FPN、残差单元、全连接层在验证集Val2下的仿真图; (c)—改进的FPN、残差单元和原全连接层在验证集Val2下的仿真图; (d)—改进的FPN、残差单元、全连接层在验证集Val1下的仿真图.

表2 基于改进方法的性能指标

表3 基于原方法的性能指标[5]
从表2可以看出,由改进的FPN特征融合、ResNet残差单元、全连接层组成的新网络(其最终确认使用改进方法为FPN-FU-ELU+FC(3))获得一个较好的检测结果,优于原方法下的性能指标.在验证集Val1下,调整学习率为0.000 1,0.000 01,0.000 001,选用0.000 01;在验证集Val2下调整学习率最终选用0.000 1.对于指标(AP3D)原方法与本文方法都是在Val2验证集上实验的.由于Val1和Val2验证集内容大部分不相同,因此可以验证模型在实际不同场景下的适应能力.
3 结 语
本文提出的基于改进的FPN特征融合、ResNet残差单元、全连接层组成的新网络在KITTI验证集上取得较好的检测结果.改进的FPN特征融合通过融合不同层的信息获得强语义、高分辨率特征,使特征细节更丰富,改进的ResNet残差单元通过在残差单元内的高速通道上引入ELU激活函数,且逐元素相加后去掉ReLU激活,优化了原始残差单元模拟中ReLU操作后的输出和逐元素相加不匹配问题,改进的全连接层几乎没有增加参数量和训练时间,且同等条件下检测性能优于原始2层全连接层.
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
网络安全与数据管理(2022年3期)2022-05-23
China’s foreign Trade(2021年6期)2021-12-26
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2020年10期)2020-11-14
电子制作(2019年13期)2020-01-14
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
汽车与新动力(2017年3期)2017-06-29
