
融合评论文本特征和评分图卷积表示的推荐模型
2022-03-31 07:11:22冯海林张潇刘同存
通信学报 2022年3期
冯海林,张潇,刘同存
(浙江农林大学数学与计算机科学学院,浙江 杭州 311300)
0 引言
互联网的迅速发展带来了信息过载问题,这使用户从海量的信息中获取自己需要的信息极其困难,推荐系统作为解决信息过载的重要工具,可以帮助用户发现他们感兴趣的内容。推荐系统的评分预测可看作矩阵补全任务,即基于矩阵中已有的数据来填补矩阵中缺失的部分,然而观测到的用户行为数据是极其稀疏的,如何根据极其稀疏的观测数据来较准确地预测未观测数据一直以来都是推荐系统研究的关键课题。早期的方法主要是利用矩阵分解技术,仅仅利用用户对商品的评分来推断[1-2],但用户的反馈行为不仅有评分,还包含丰富的评论信息,这些评论文本能够体现出用户的购物偏好以及商品的属性吸引性,可以加强对用户和商品的表征学习能力,从而提高推荐系统的推荐质量[3]。
近年来,深度学习技术所具备的较强特征提取能力[4-7]使其在推荐系统中得到了广泛应用,也在一定程度上缓解了用户评分的稀疏性问题[8-9]。但是现有的基于深度学习的方法仍然存在可以改进的地方,比如在评分数据的处理上,脱离传统的矩阵分解方法,以其他方式学习评分特征可能会提升推荐模型的精准度;另外,不同的评论所包含的语义信息不同,如何对重要的评论进行选取和建模,也需要进行进一步的研究分析。
本文对以上提出的可改进的部分加以研究,提出了融合评论文本和评分图卷积表示(CRRG,combining review’s feature and rating graph convolutional representation)的推荐模型。该模型利用图卷积编码学习用户和商品的评分特征表示,首先获取用户-商品评分集(用户对商品的评分数据),根据用户对商品的评分等级,在用户-商品二部图上进行信息传递;然后获取用户评论集(用户对商品的评论信息)和商品评论集(商品中各个用户的评论信息),通过卷积神经网络分别提取用户和商品的文本卷积特征,引入注意力机制,利用用户(商品)在评分上的特征表示区分评论重要性,从而获取更准确的评论文本特征;最后将评论文本特征和评分特征拼接融合,将得到的用户和商品最终特征表示输入隐因子模型中产生推荐结果。本文所提CRRG模型的贡献可以总结为以下3 点。
1)本文提出的模型结合卷积神经网络和图卷积编码器对用户及商品评论文本以及评分数据进行联合建模,学习用户和商品的特征表示。
2)在评分数据上使用图卷积编码器并结合注意力机制对用户和商品特征进行表示,使模型在评论建模时可以区分评论的重要性,融合用户和商品评分特征及相应的评论文本特征,通过增强用户和商品的信息交互提升模型精度。
3)在亚马逊公共数据集上进行了对比实验,结果表明本文提出的CRRG 模型在评分预测上的均方误差(MSE,mean square error)低于现有的相关模型,证明了本文提出的模型的有效性。
1 相关工作
1.1 基于主题建模的推荐
早期的研究工作主要使用主题建模技术从用户的评论文本中进行语义分析,提取语义特征,将潜在的语义主题整合到学习模型中进行推荐。文献[10]提出了最早期的基于用户的评论数据进行推荐的方法,分别使用用户和商品的评论数据进行评分的预测;文献[11]使用每个用户对某个具体商品的评论建模,并且用不同的关联机制将用户和商品的表示和学到的主题模型进行关联;文献[12]将文本信息上的降噪自编码器(SDAE,stacked denoising autoencoder)[13]与隐式评分矩阵的概率矩阵分解(PMF,probabilistic matrix factorization)[1]紧密耦合,从文本中学习可解释的潜在因素。这些方法都优于仅依赖用户商品评分数据交互的模型,但是都属于词袋模型,忽略了单词顺序和局部上下文信息,导致评论中重要信息的丢失。
1.2 基于深度学习的推荐
国内外研究者提出了许多方法对评论的上下文信息进行建模,显著提高了推荐精度。例如,Kim等[4]提出了卷积矩阵分解(ConvMF,convolutional matrix factorization)模型,使用卷积神经网络从商品描述中提取商品特征,将上下文信息合成为连续的实值矢量表示;文献[14]模型从用户和商品文档中提取特征,利用该特征来校准学习模型中的潜在因子;深度协同神经网络(DeepCoNN,deep cooperative neural network)[5]模型使用并行的卷积神经网络从用户和商品文档中发现语义特征。这些方法的推荐效果优于基于词袋的方法,但它们仅以静态和独立的方式学习用户和商品的潜在特征向量,忽略了不同评论的重要性差异,以及评论内部不同单词的重要性差异。
最近的许多工作利用注意力机制从文本信息中学习上下文感知的潜在表示。例如,文献[15]利用Local和Global 这2 个注意力机制来识别评论文档中的重要单词;文献[16]利用基于指针的共同注意力方法,选出重要的评论及重要的单词;Chen等[8]提出NARRE(neural attentional regression model with review-level explanation)模型,通过评论级别的注意力机制来刻画每一条评论的权重,选择有用的评论进行评分预测;文献[17]应用词注意力机制对商品文本进行编码,从而更好地理解商品的内容;Zhou 等[18]提出了双头注意力融合自动编码器模型,应用早期融合模块,利用注意力机制选择与推荐任务相关的评论;Liu 等[19]提出一种个性化的注意力模型NRPA(neural recommendation with personalized attention),为不同的用户或商品选择不同的重要单词和评论;梁顺攀等[20]提出 SACR(self-attention capsule network rate)模型,通过自注意力胶囊网络来挖掘用户评论文档,对低质量评论进行编号标记。这些基于注意力机制的推荐研究考虑到单词或评论的重要性,更准确地学习到用户或商品特征表示,取得了较好的推荐效果。另外,还有一些基于深度学习的推荐方法,冯兴杰等[21]以及李昆仑等[22]提出的推荐算法都使用了预训练的双向编码器表示(BERT,bidirectional encoder representation from transformer)模型提取评论文本信息,构造评论文本的特征表示,提升了模型对同一单词在不同语义环境下具体含义的理解能力。
近年来,多视图的结构也被应用到推荐中,Gao等[23]构建了一个深度可解释网络的初始结构,利用注意力多视图学习对深度可解释网络中每层的参数进行优化,通过无监督的方式分析了用户是对低层特征感兴趣还是对高层特征整体感兴趣;图卷积矩阵补全(GC-MC,gragh convolutional matrix completion)模型[24]设计了一种对矩阵进行补全的图自编码器框架,将评分作为用户-商品图的链接边,通过在用户和商品的交互图上进行信息传递学习节点的嵌入,但是该模型并没有结合评论文本信息;Gao 等[25]将评论的辅助信息混合,提出了集合-序列-图的多视图方法,采用3 种方式编码器架构,共同学习用户和商品的表示形式。虽然这些研究在一定程度上提升了推荐的准确度,但在获取重要性评论方面仍然可以进行进一步的研究,并且可以继续探究融合评论文本和评分数据对推荐模型优化的有用性。
2 推荐模型
本文提出的CRRG 模型架构如图1 所示。CRRG模型共包括4 个模块:1)文本向量化,将用户和商品评论集分别通过嵌入层输出评论文本的嵌入向量;2)特征工程,首先将评论文本的嵌入向量通过卷积层利用卷积神经网络获取文本的卷积特征,再将用户-商品评分集通过图卷积编码获取用户和商品在评分上的特征表示;3)特征交互,通过注意力层将用户和商品的文本卷积特征与评分特征进行交互,得到用户和商品最终的评论文本特征,再通过连接操作和内积运算得到融合特征;4)评分预测,利用隐因子模型计算用户对商品的预测评分。
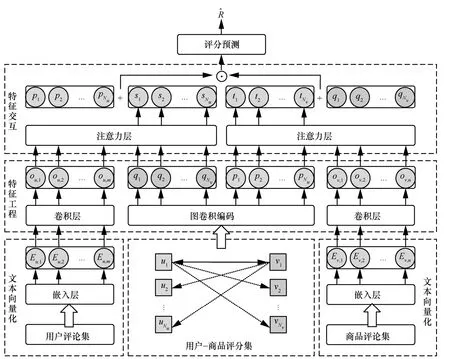
图1 CRRG 模型架构
2.1 文本向量化
对于用户u的评论集,合并所有评论形成用户文档Du=[w1,w2,…,wm],其中m表示用户u的评论数量,然后将文档中每条评论的单词进行嵌入表示,使用word2vec 进行词向量的预训练,得到用户u的评论文本向量化表示Eu为
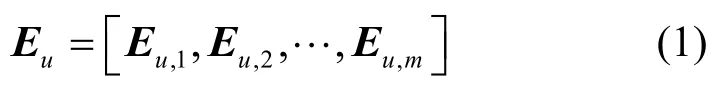
其中,Eu,j∈ℝc×d表示用户u第j条评论的嵌入矩阵,c表示该条评论的长度,d表示单词嵌入维度。同样地,可以用类似的方式获得商品v的评论文本向量化表示,其中n表示商品v的评论数量。
2.2 特征工程
2.2.1 卷积神经网络
首先,基于用户和商品的评论文本向量化表示,利用卷积神经网络提取用户和商品的评论文本卷积特征。卷积层由α个神经元组成,每一个神经元与卷积滤波器F∈ℝh×d关联,其中h表示滑动窗口,该滤波器通过在嵌入矩阵上应用卷积运算产生卷积特征。第k个神经元产生的局部特征zk表示为
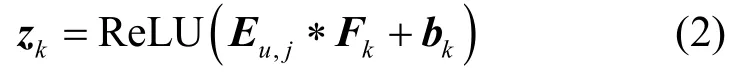
其中,bk∈ℝh表示偏置,*表示卷积运算符号,ReLU表示激活函数。
然后,执行最大池化操作,得到第k个神经元产生的最终特征ok,把α个神经元产生的特征根据滑动窗口h的维度进行连接,得到用户u第j条评论的文本卷积特征ou,j∈,最后得到用户u的所有评论文本卷积特征Ou∈,该过程表示为
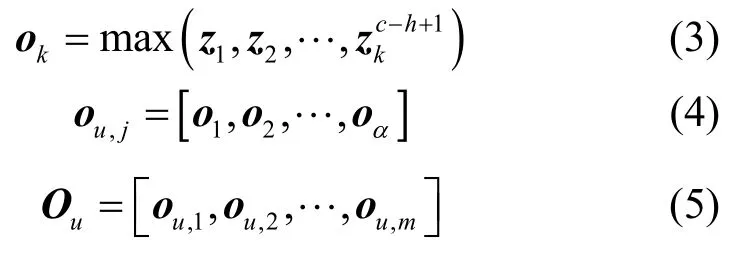
其中,z1,z2,…,表示第k个神经元在滑动窗口h上产生的特征。同样地,也可以生成商品v的所有评论文本卷积特征,其中,,ov,n∈表示商品v第n条评论的文本卷积特征。
2.2.2 图卷积编码
给定用户-商品评分集,构建图编码模型获取用户和商品的评分特征,相比于将评分矩阵分解为2 个低维矩阵的乘积,只能提取模型的浅层次特征,构建图编码模型可以在用户-商品二部图上进行信息传递,用户(商品)节点可以由与其交互过的商品(用户)进行表示。具体来说,将用户-商品评分集转换为评分矩阵M∈,其中,Nu表示用户数量,Nv表示商品数量,Mi,j表示用户i对商品j的评分。用户-商品的评分交互数据可以用二部图G=(ℑ,∂,ℜ)表示,其中,ℑ表示用户节点ui∈ℑu,i∈ {1,…,Nu}和商品节点vj∈ℑv,j∈{1,…,Nv)的集合,(ui,r,vj)∈∂表示二部图的边,携带表示评分等级的标签,如r∈{1,…,R}=R,R表示评分等级的最大值。本文借鉴GC-MC[24]的图编码模型进行编码,表示为
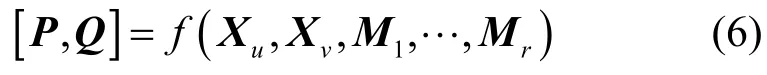
图编码模型可以有效利用图形中各个位置之间的权重分配,并为每种评分类型r∈{1,…,R}分配单独的处理通道。局部图卷积可以看作信息传递,其中特征值的信息被沿着图的边传递和转换,即用户可以用被它交互过的商品来表示,因此这里在二部图上进行信息传递,获取用户节点的评分边类型特征信息,表示为
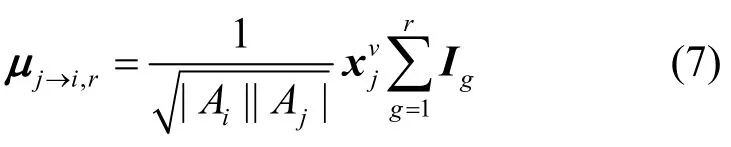
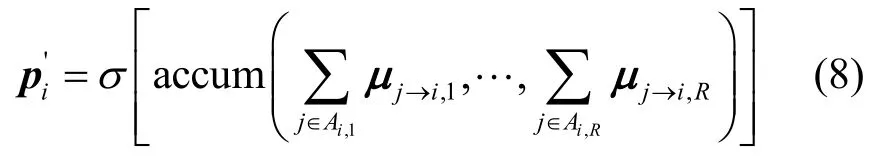
其中,accum(·)可以表示为向量总和sum(·),也可以表示为向量串联stack(·);σ表示激活函数ReLU。通过一个全连接层获取用户i的评分特征,即

2.3 特征交互
用户和商品评分交互数据经过图卷积编码后,能够获取到更准确的用户和商品的评分特征,将其和评论文本卷积特征相交互,对于辨别评论信息的有用性会更有效。因此对于商品建模来说,在输入商品v的第l条评论文本卷积特征ov,l后,结合该评论的用户评分特征pu,l,计算每条评论的重要性,即

在获得每条评论的注意力权重后,将商品v的特征向量计算为加权总和,通过一个全连接层,则经过注意力操作的商品v的评论文本特征可表示为

对于得到的用户u的评论文本特征以及评分特征,将2 个特征相连接,得到用户u的最终特征表示,类似地,计算获取商品v的最终特征表示,将用户和商品的最终特征表示通过内积运算进行组合得到,如式(13)所示。
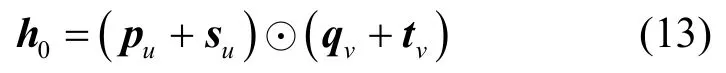
其中,⊙表示内积符号。
2.4 评分预测
在评分预测层利用隐因子模型(LFM,latent factor model)来完成最终评分的预测。LFM 是一种基于矩阵分解的算法,可获得用户u对商品v的预测评分,表示为
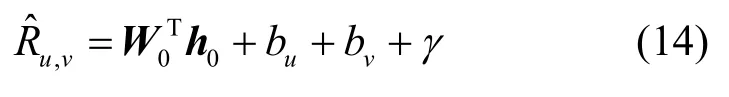
其中,W0∈表示参数,bu、bv、γ分别表示用户的偏置、商品偏置、全局偏置,将W0设置为1 即可恢复标准的隐因子模型。
本文的评分预测可以看作回归任务,使用MSE构建损失函数,表示为
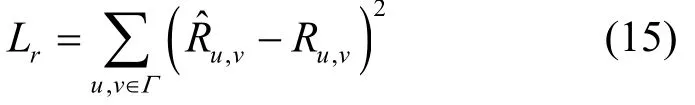
其中,Γ表示模型训练数据集,Ru,v表示用户u对商品v的评分的真实值。为了优化目标函数,本文采用自适应矩估计(Adam,adaptive moment estimation)作为优化器,它是一个寻找全局最优点的优化算法,引入了二次梯度校正,相对于其他算法有一定的优越性。
3 实验
3.1 数据集和评估方法
本文在亚马逊公开的5-core 评论数据集上进行实验,选用亚马逊网站的用户ID、商品ID、评论信息和评分数据信息,其中评论数据中每个用户和商品至少有5 条评论,本次实验采用其中4 种类别的数据集,分别是Musical Instruments(MI)、Patio Lawn and Garden(PLG)、Automotive(Auto)以及Amazon Instant Video(AIV)。表1 显示了这4 种数据集的统计信息。

表1 数据集统计信息
实验采用MSE 作为模型的评估方法,这是一种常用的回归算法的评价指标,并且在相关文献中被广泛使用。在获取评分预测结果Ru,v后,求得其与真实值Ru,v误差的平方和再与所有测试实例数目N的比值,如式(16)所示。在本文实验中,MSE 的值越低,表示模型的预测评分越准确,模型的推荐性能越好;反之,表示模型的推荐性能越差。
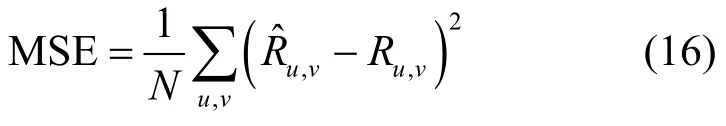
3.2 对比模型
本文将提出的CRRG 模型和以下推荐模型进行比较,检验模型的推荐效果。表2 展示了实验的对比模型使用的输入数据以及方法类型。
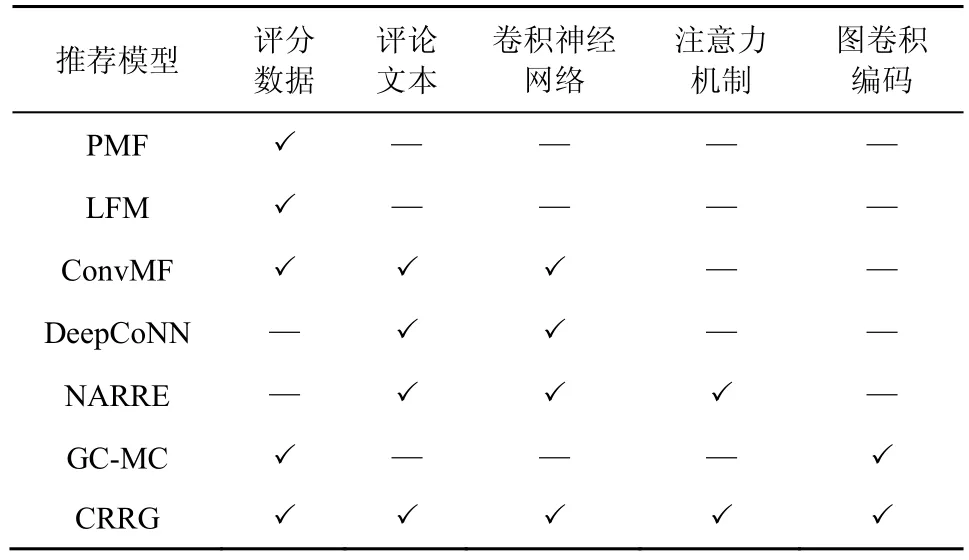
表2 模型比较
1)PMF[1]。经典的概率矩阵分解模型,只输入了评分数据。
2)LFM[2]。隐因子模型,通过矩阵奇异值分解(SVD,singular value decomposition)的方法预测商品评分,同样只输入了评分数据。
3)ConvMF[4]。利用卷积神经网络提取商品的评论文本特征,和PMF 模型相结合完成推荐任务,没有使用用户的评论文本信息。
4)DeepCoNN[5]。使用2 个并行的卷积神经网络,分别从用户和商品的评论文本中提取相应的特征表示来进行推荐。
5)NARRE[8]。在DeepCoNN 模型的基础上,考虑到不同评论的重要性不一致,在对评论文本进行建模的时候,引入了注意力机制,将用户和商品的ID 嵌入作为注意力分数计算的辅助信息来获取相对重要的评论。
6)GC-MC[24]。基于用户-商品的二部图,设计了一种图自编码器框架,从链路预测的角度解决推荐系统中的评分预测问题,仅输入了评分数据。
3.3 实验设置
实验在每个数据集上随机选取80%作为训练集,10%作为验证集,10%作为测试集。对于需要输入评论文本的模型,使用GoogleNews 预训练的300 维词向量;对于使用卷积神经网络的模型,本文使用了基准模型DeepCoNN和NARRE中大部分参数设置,其中CNN 的卷积核大小在{3,4,5}中选取,每种卷积核个数为100,并对参数进行微调,在{4,8,16,32}中遍历寻找最佳的隐因子个数,选取最优结果进行展示。
3.4 结果分析
本文提出的CRRG 推荐模型和现有的几个模型在4 种数据集上MSE 的对比实验结果如表3 所示。
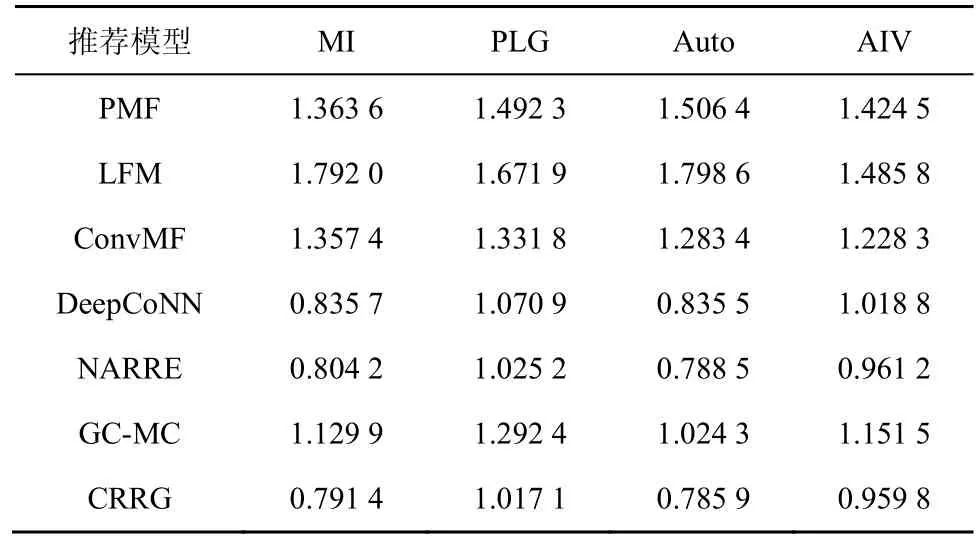
表3 MSE 的对比实验结果
通过分析以上对比实验,可以得出以下结论。①只考虑评分数据的推荐模型(PMF、LFM、GC-MC)的预测结果不如使用评论文本的推荐模型(DeepCoNN、NARRE、CRRG)效果好,因为评论文本中含有丰富的语义信息,可以对评分数据进行补充,更有可能得到相对准确的评分预测结果;②根据PMF、LFM、ConvMF 模型与GC-MC 模型的对比实验结果,使用图卷积编码对模型性能可以有实质性的提升,这是因为图卷积编码在用户-商品二分图上让节点进行信息传递,使用户和商品的特征表示更加具体;③使用了注意力机制的模型(NARRE、CRRG)比DeepCoNN 模型的推荐性能更优,因为注意力机制可以区分评论文本的重要性,获取更深层次的语义信息;④本文提出的CRRG模型在NARRE 模型的基础上,使用图卷积编码的方式对评分数据进行特征表示学习,从多维度特征交叉角度学习用户和商品的特征表示,增强了用户和商品的交互,获取了最好的评分预测结果。
3.5 模型性能优化
本文在模型的图卷积编码过程中,将式(8)中的函数accum(·)设置为向量求和函数sum(·)或者向量串联函数stack(·),以2 种不同的方式获取用户和商品节点的评分特征表示。实验为了优化模型性能,并且分析模型参数中的隐因子数量给模型带来的影响,分别比较了不同的隐因子个数在2 个不同的数据集上使用sum(·)或stack(·)给模型性能带来的影响,结果如图2所示,其中CRRG-ST 表示使用了向量串联函数,CRRG-SU 表示使用了向量求和函数。
通过图2 可以看出,在不同的隐因子数量下,模型的预测结果有很大的差别。在PLG和MI 这2 个数据集上,使用CRRG-ST和CRRG-SU 算法的预测结果表现最好时的隐因子数量也是不一样的,但是从 2 种算法最好的表现效果来看,使用CRRG-SU算法总体上比CRRG-ST算法得到的误差更小,表明使用向量求和函数比向量串联函数更好,因此,CRRG 模型在式(8)中最好使用向量求和函数。另外,随着隐因子数量的增加,使用CRRG-SU 算法得到的误差逐步上升,这可能是由于参数过多导致的过拟合现象。

图2 不同隐因子数量下函数accum(·)设置对模型性能的影响
3.6 消融实验
为了验证图卷积编码在评分特征表示学习上的有效性,本文在CRRG 模型基础上进行消融实验,设计了以下变体算法。
1)CRRG-G1。在注意力层进行注意力分数计算时,将对应评论的用户或商品特征改为它们的ID嵌入特征。
2)CRRG-G2。在最后进行评论文本特征和评分特征的融合时,将通过图卷积编码获取的评分特征改为相应的用户或商品的ID 嵌入特征。
在2 个不同的数据集上对CRRG-ST、CRRG-SU、CPPG-G1、CPPG-G2 以及没有引入评分图卷积表示的NARRE 模型进行对比实验,实验结果如图3 所示。
通过图3 可以看出,虽然在不同的数据集上变体算法的表现不尽相同,但是总体都比NARRE 模型效果更好。通过分别比较CRRG-G1、CRRG-G2变体算法和NARRE 的实验结果可知,图卷积编码获取的评分特征能够提高判断用户和商品重要性评论的准确性,对融合评论文本特征的有效性也有所提升。另外,将通过图卷积得到的评分特征在注意力层和最后的融合部分与评论文本特征都进行交互,能够最大程度地发挥作用,提升推荐效果。
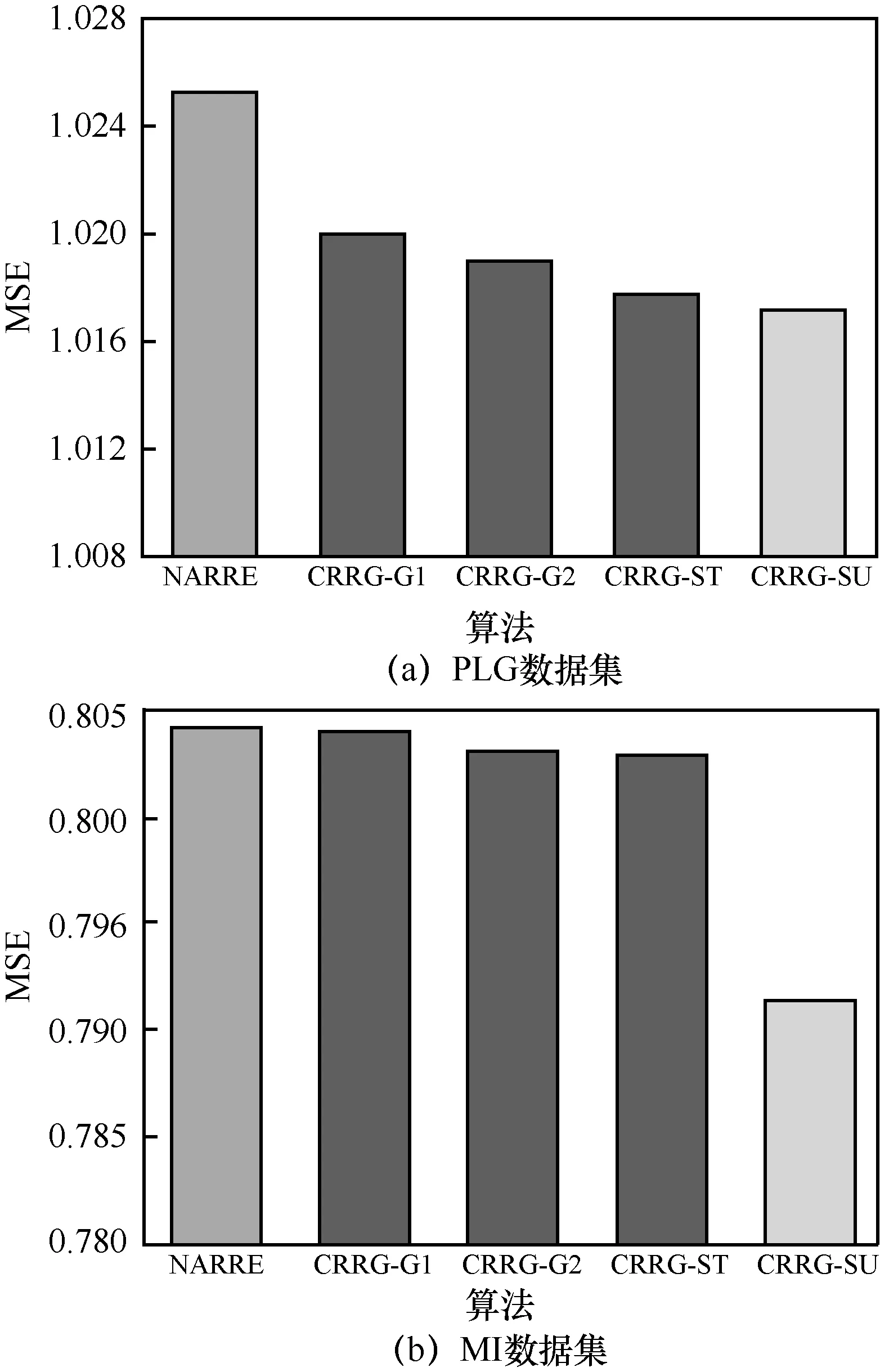
图3 消融实验
4 结束语
本文提出了融合评论文本和评分图卷积表示的推荐模型CRRG,该模型使用卷积神经网络以及图卷积编码分别学习用户和商品的评论文本与评分的特征表示,并通过注意力机制结合2 种特征获取更有效的评论信息,融合评论文本特征和评分图卷积表示的特征得到了用户和商品更准确的表示。在亚马逊公开数据集上进行对比实验,实验表明本文提出的推荐模型能够进一步降低评分预测的误差,提升推荐效果。今后的研究可以探索通过用户和商品的其他交互行为,比如用户对商品时序偏好、点击率等来提升推荐性能。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
电子制作(2019年11期)2019-07-04 00:34:38
当代陕西(2019年10期)2019-06-03 10:12:04
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
电视技术(2014年19期)2014-03-11 15:38:20
