
基于CTPN 与Tesseract的机载雷达视频字符识别
2022-03-31 12:02邢宝峻彭晓明王卫星
舰船电子对抗 2022年1期
邢宝峻彭晓明王卫星
(空军预警学院,湖北 武汉 430019)
0 引言
近年来,随着人工智能和深度学习技术的不断发展,计算机视觉技术已深入到人们生活的方方面面。在军事领域,随着技术的发展,雷达的应用也越来越广泛,而国内对于机载雷达视频的分析依然停留在人工分析阶段,不仅效率低,而且容易出现差错,部队迫切需要一种能够对机载雷达视频进行自动化分析和评估的手段,满足飞行训练复盘总结和飞行训练成绩评定的需要,促进部队实战化训练水平的提升。
连接文本提议网络(CTPN)是于2016 年在欧洲计算机视觉国际会议提出的一种基于深度学习的文字检测算法。CTPN 结合了卷积神经网络(CNN)与长短时记忆(LSTM)神经网络,可以有效地检测出复杂场景下水平分布的字符。Tesseract是惠普实验室在1985~1995年间开发的一个开源的光学字符识别(OCR)引擎,并于2006 年由谷歌进行维护,目前仍是业内识别精度较高的三大识别引擎之一。结合CTPN 与Tesseract对机载雷达视频中的关键字符进行识别,可以有效识别出机载雷达视频中的关键字符,为下一步机载雷达操纵评估提供依据。
1 基于CTPN 与Tesseract的机载雷达视频识别方法流程
采用CTPN 与Tesseract相结合的方法对机载雷达视频进行识别,首先要对视频进行预处理,将视频转化为图像,同时提高图像的质量,方便进行识别;然后将预处理得到的图像输入到CTPN 网络中,实现字符区域的检测;最后调用Tesseract对字符进行识别,得到文本进行输出。视频识别方法流程如图1所示。
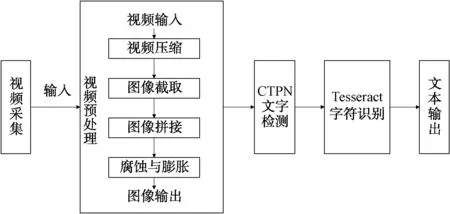
图1 基于CTPN 与Tesseract的机载雷达视频识别方法流程
2 机载雷达视频的预处理
由于本文对视频的识别主要基于已有的视频进行,所以采用后端视频识别方法,先将视频转化为图像,而后对图像进行识别。因此,需要对机载雷达视频进行分析,首先要完成对机载雷达视频的预处理。由于机载雷达视频通常占用空间较大,视频中存在一定的冗余信息,所以先要对视频进行压缩。其次,由于机载雷达视频画面呈现二值化特点,所以无需进行灰度处理,可直接将视频按帧截取成图像,达到将视频转化为图像的目的。由于图像数量较多,单个识别时间较长,为提高识别效率,采用图像拼接技术将截取的图像进行拼接,再对拼接后的图像进行识别。最后,由于机载雷达视频本身分辨率较低,且进行了图像的拼接,为提升识别准确率,利用形态学中图像的开运算,即先腐蚀后膨胀的操作(腐蚀操作可将图像中影响识别的孤立的微小“白点”去掉,膨胀操作可以将关键的字符进行“扩大”,易于识别,所以通过开运算可以起到在纤细处分离物体和平滑较大物体边界的作用),达到使需要识别的目标表面更加平滑的效果,便于进行分析与识别。机载雷达视频预处理步骤如图2所示。
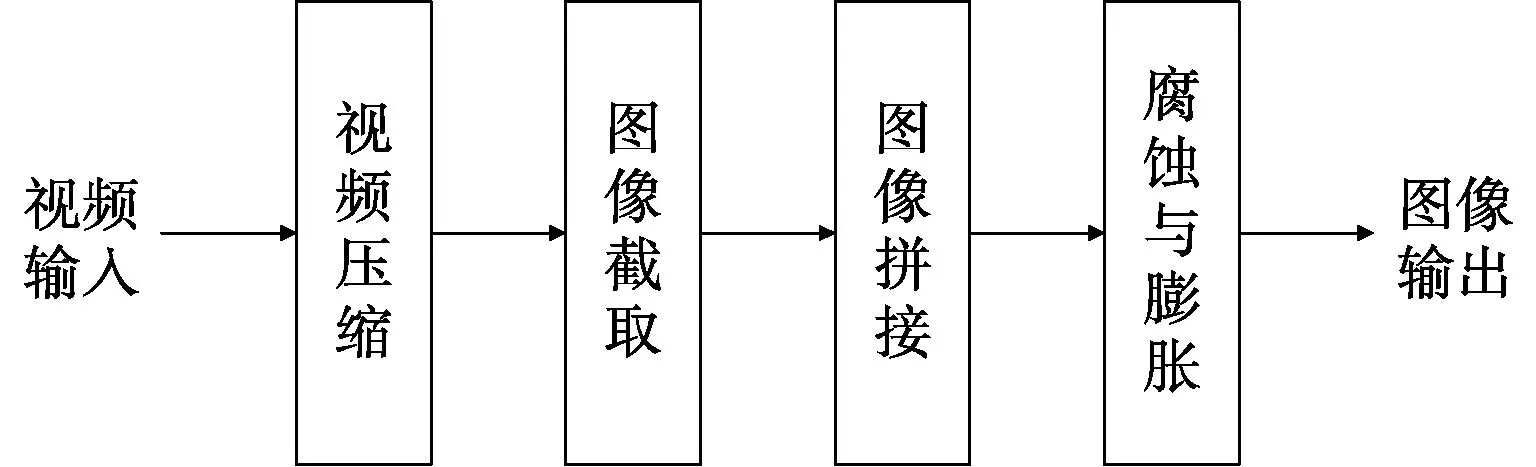
图2 机载雷达视频预处理步骤
3 基于CTPN 的字符检测
CTPN 创新性地提出了垂直锚,利用垂直锚的回归机制,将文本检测任务转化为一连串小尺度文本框的检测。同时,CTPN 还引入了双向长短时记忆(BLSTM)神经网络技术。BLSTM 可用于处理和预测序列数据,与CNN 结合后,能根据前后锚的序列来提取字符间的排列关系特征,找到文本与文本之间的联系,最终用文本线构造法将各个锚连接起来,得到文本行,以提升文本检测效果。此外,针对文本检测中文本边缘容易因评分过低而被丢弃的问题,CTPN 提出了利用边界细化来提升文本框边界预测精准度的方法,极大地提升了文本检测的精度。
CTPN 的具体过程如下:
(1) 利用VGG16 网络进行特征提取。VGG16网络中有5个卷积层,经过前4个卷积层的池化,特征图的大小与原图的比例变为1∶16,即在特征图上每移动1个像素位置,在原图上相对应移动16个像素位置。经过第5个卷积层后,可得到最终用于分类和定位的特征图,大小为××,这里的是宽度,是高度,是通道数。
(2) 对特征图上每个位置以3×3的窗口进行滑窗,每一行都可以得到个3×3×的特征矩阵,每进行一次滑窗,即水平方向每移动1个像素,则对应在原图水平方向上移动16个像素。而由于CTPN 固定了水平方向上的位置,对竖直方向上的高度进行了预测,所以每个滑窗在原图上对应个锚,这些锚在水平方向上都是一样的大小和位置,但在竖直方向上的高度各不相同。
(3) 将得到的特征矩阵按行输入到双向LSTM中,即每个双向LSTM 中输入个3×3×的特征矩阵,可以得到大小为×256的输出。
(4) 将LSTM 输出的×256输入到全连接层(FCL)中。
(5) 全连接层特征输入到3个分类或者回归层中:2个纵向坐标,2个分数和个的水平偏移量。由于一个锚用中心位置的高(坐标)和矩形框的高度2个值表示,所以1个锚用2个纵向坐标输出。而分类层将数据分为有字和无字2类,所以有2个分数。个的水平偏移量可以称之为文本框边缘细化,这部分主要用来精修文本行的2个端点,表示每个候选框的水平平移量。
(6) 使用基于图的文本行构造算法,将得到的文本段合并成文本行。
CTPN 架构图如图3所示。

图3 CTPN 架构图
4 Tesseract字符识别
2005年,惠普将Tesseract贡献给开源社区,美国内华达州信息技术研究所获得该源码,同时,谷歌开始对Tesseract 进行功能扩展及优化。目前,Tesseract作为开源项目发布在谷歌计划(Google Project)上,提供自定义字符库训练方法,可以通过持续的训练增加字符库,不断增强图像转换为文本的能力,最终,Tesseract成为了目前公认最优秀、最精确的开源OCR 系统。
如图4所示,Tesseract对字符进行识别通常由5个部分构成:页面布局分析、查找目标块区域、定位文本行和单词并进行分割、2次字符分析识别、模糊区域改进。

图4 Tesseract识别架构[5]
(1) 页面布局分析。通过对文本进行页面布局分析,将图像中的文本和非文本区分开,同时提取出文本区域,得到图像中文本区域的排列布局和分布方式,并检测出文本区域中的字符轮廓。
(2) 查找目标块区域。Tesseract可以通过对文本区域中的排列布局进行分析,得到一个或多个相互关联的“块”状连通区域,这些“块”状区域即目标块区域。
(3) 定位文本行和单词并进行分割。在定位完成目标块区域后,Tesseract通过对区域中相邻字符之间的垂直重叠关系进行检测,可以得到处于水平状态的文本行。对字符间的水平关系进行检测并根据字符间隔对文本行进行分割,可得到单词。
(4)
2次分析识别。Tesseract采用自适应分类器依次对每个单词进行分析,并将分类后的字符分别与相对应的字典中的样本进行对比,找出相似度最高的样本字符进行确认。同时,自适应分类器本身具有“学习能力”,可以将先前分析得到的满足条件的单词作为训练样本,增加后面字符识别的准确率。
(5) 模糊区域改进。对于相互粘连的字符形成的模糊区域,Tesseract会根据字体形状的几何体顶点作为备选分割点进行分割,并根据识别置信度来判别字符。如果都失败,就认为字符破损不全,则对字符进行修补,而后利用A算法搜索最优的字符组合,得到识别结果。
5 实验验证
为验证该方法的有效性,本文利用已有的机载雷达视频进行检测。首先将视频分为样本集和测试集2类,其中,样本集中的视频要包含所有需要进行识别的关键字符。其次,结合Tesseract提供的自定义字符库的训练方法,结合样本集,挑选出需要进行识别的关键字符,并进行训练,形成机载雷达视频关键字符库。然后,根据本文介绍的方法对测试集中的视频进行识别,主要检测识别方法的可靠性。如图5所示,根据本文所提方法创建了机载雷达视频识别软件,右侧为机载雷达视频,左侧根据雷达视频中的内容对视频中的字符进行区分,对测试集中的视频进行识别后,由人工对视频中每一帧识别结果的正确与否进行检验,对视频中需要识别的共50 435个字符进行统计。结果表明,本文研究的方法对机载雷达视频关键信息识别的准确率达到86.25%。绝大部分关键字符识别正确,少数字符在识别过程中出现错误,主要原因是在视频中非字符部分与字符部分产生了交叉重叠,在CTPN 进行字符的检测和分割后,Tesseract无法在字符库中找到与之相匹配的字符,影响了该字符的识别。随着所识别的视频数量的增加和训练数据的完善,识别的准确率也会逐步提升。
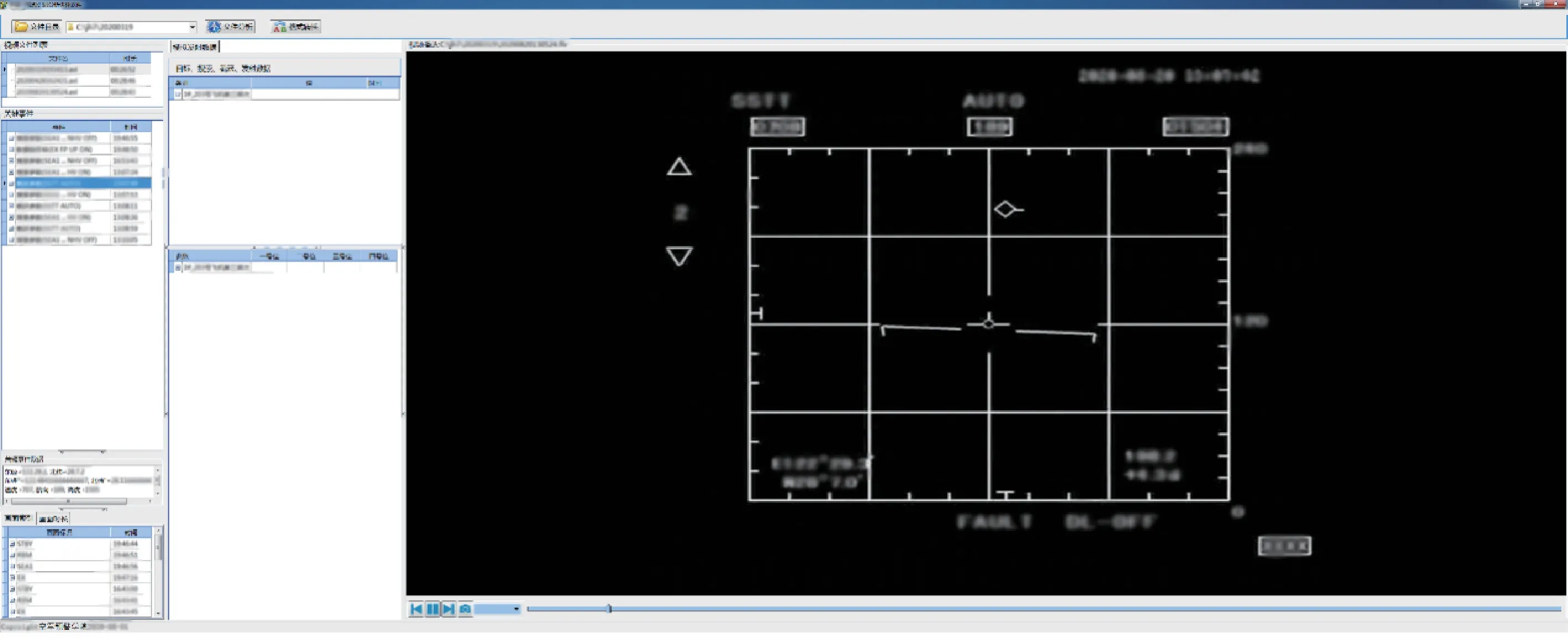
图5 视频识别软件图
6 总结与展望
本文针对机载雷达视频,提出了基于CTPN 和Tesseract相结合的视频识别方法,通过视频压缩、图像截取、图像拼接、腐蚀与膨胀等预处理,借用CTPN 对字符进行检测,再调用Tesseract进行识别,最终输出关键字符的文本。通过实验,验证了该方法的有效性。但该方法也有一定的缺陷,随着视频的运行,部分字符可能存在与非字符部分交叉的情况,在下一步研究的过程中会加入视频的语义分析,根据视频前后帧之间的关联关系进行判断。同时,在得到输出文本后,将来还可以加入对关键字符的检索,有利于快速得到评估飞行员雷达操纵水平的数据。
猜你喜欢
化工进展(2022年8期)2022-08-29
农业工程学报(2022年8期)2022-08-08
健康体检与管理(2022年4期)2022-05-13
化工进展(2022年3期)2022-04-12
电脑报(2021年41期)2021-11-04
电脑知识与技术(2019年29期)2019-12-16
电脑爱好者(2019年8期)2019-10-30
初中生世界·九年级(2018年12期)2018-12-22
读者(2015年9期)2015-05-04
农机使用与维修(2014年10期)2014-10-23
