
一种融合注意力机制与上下文信息的交通标志检测方法
2022-03-30 07:12张文卓
计算机测量与控制 2022年3期
王 林,张文卓
(西安理工大学 自动化与信息工程学院,西安 710048)
0 引言
目标检测作为计算机视觉领域的重要课题之一而备受关注。某种意义上来说,它的发展史也是计算机视觉发展史的缩影。交通标志检测技术是自动驾驶领域的关键技术之一,被广泛地应用于汽车辅助驾驶系统以及数据地图当中。因此,交通标志检测具有极高的研究意义和应用价值。
传统的交通标志检测方法以基于颜色[1]或者基于形状[2]为代表,但当面临光照变化、形变以及遮挡等问题时,检测效果欠佳。卷积神经网络(CNN,convolutional neural network)的出现使得目标检测得以迅速发展,文献[3]提出了R-CNN模型,为交通标志检测开辟了新的思路,随后在此基础上又提出了Fast R-CNN[4]和Faster R-CNN[5],这些方法被称为两阶段目标检测。虽然两阶段目标检测方法检测精度比较高但是实时性却比较差,针对这一问题文献[6]提出YOLOv1模型,这是一个端到端的模型,因此被称为一阶段目标检测方法,同时被称为一阶段目标检测的还有YOLOv2[7]、YOLOv3[8]、SSD[9]、DSSD[10]以及FCOS[11]等相关方法。近年来文献[12]提出一种基于CNN的模型,该模型采用多尺度滑动窗口策略的同时利用扩张卷积代替原卷积,取得了不错的检测效果。文献[13]按照并行检测原理,结合目标传感器与神经型卷积分类器,提出了一种基于卷积神经网络的行人目标检测系统。Zhu[14]等人提出一种端到端基于CNN的网络,可同时进行目标的检测和分类任务。
虽然现有的检测方法在交通标志检测上取得了不错的成绩,但小目标检测仍然没有达到预期效果。首先,现有的目标检测网络是以检测大目标为主导,这是小目标检测效果不佳的客观原因;其次,小目标在原图中尺寸较小且数量也比较少,而现有优秀的检测模型所使用的骨干网络都有下采样层,通过下采样层后小目标的像素达到了个位数,导致检测效果不佳。因此本文对检测网络进行改进,以优化模型在交通标志检测中存在小目标检测精度不高、漏检以及误检等问题。
1 相关理论
YOLO家族的网络虽然不是精度最好的网络,但在精确度与速度之间达到了理想的平衡。YOLOv3借鉴了YOLOv1和YOLOv2,虽然没有太多的创新点,但在保持YOLO家族速度的优势的同时,提升了检测的精度,尤其对于小物体的检测能力,这对于交通标志检测来说是十分友好的。
1.1 YOLOv3网络框架
YOLOv3使用Darknet-53作为骨干网络,相对于Res-Net[15]网络而言,使用卷积层替代池化层进行降采样操作,这样可以有效地减少浅层特征的丢失。如图1所示Darknet-53包含53个卷积层,DBL(Convolutional)单元包含了卷积层、批归一化[16](BN,batch normalization)和Leaky Relu激活函数,Residual模块由两个DBL单元进行残差操作,通过引入BN层和Residual模块,可以加快网络的收敛,同时防止随着网络层数的增加而出现的梯度爆炸、消失以及网络退化等问题。

图1 YOLOv3网络结构
YOLOv3在网络中借鉴了基于多尺度预测的特征金字塔结构,用多尺度对不同大小的目标进行检测,不同的是,没有采取对位相加的操作而是沿着通道进行拼接操作。首先输入大小为512×512的图像,通过DarkNet-53后得到32倍下采样的特征图,经相关卷积操作得到尺寸大小为16×16的特征图Y1;其次将32倍下采样获得的特征图,经卷积操作后进行两倍上采样,与从DarkNet-53中获取输出尺寸大小相同的特征映射沿通道进行拼接,经相关卷积操作后得大小为32×32的特征图Y2;最后同理Y2,获得大小为64×64的特征图Y3。YOLOv3共输出3个不同尺寸的特征图Y1、Y2以及Y3,其中Y1进行大目标预测,Y2进行中型目标预测,Y3进行小目标预测。3个特征图分别的通道数为所用数据集类别数(num_classes)加5之后与锚框数量(num_anchor)的乘积,5为置信度、大小和尺寸5个信息。
1.2 边界框
锚框(Anchor box)是边界框的先验,是基于数据集通过聚类预测得到。先验锚框的宽和高为(Pw,Ph),中心点为对应网格的左上角(cx,cy),通过YOLOv3模型预测得出(tx,ty,tw,th)和置信度5个值,tx,ty,tw,th分别为预测框的中心点坐标和尺寸,通过以上数据进行微调,计算公式如下:
bx=δ(tx)+cx
(1)
by=δ(ty)+cy
(2)
bw=pwetw
(3)
bh=pheth
(4)
其中:bx、by、bw、bh为调整后的锚框中心坐标和尺度大小,δ为sigmoid函数,使用sigmoid函数可以有效解决预测框可能会出现在图上任意位置这一现象,从而限制坐标位置,使得网络更加容易学习。
1.3 损失函数
YOLOv3的损失函数由置信度损失、分类损失和定位损失这三部分组成,计算公式如下:
L(o,c,O,C,l,g)=λ1Lconf(o,c)+λ2Lcla(O,C)+
λ3Lloc(l,g)
(5)
(6)
(7)
(8)
(9)
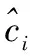
2 改进的交通标志检测网络
YOLOv3是目前应用最广泛的目标检测算法之一,具有较好的检测速度和精度,但直接应用到交通标志检测任务当中还存在一些不足。
2.1 改进的通道注意力机制ECA-A模块
SE-Net(Squeeze-and-Excitation Networks)通道注意力机制,因其复杂度低、新增参数较少以及计算量小,被广泛应用在各个模型当中[17]。核心思想是增强有用信息的通道,抑制信息较少的通道。SE模块通过两个全连接层降维操作来减少模型复杂度。但是,降维会对通道的预测产生副作用,得到的通道间的相关性也是低效且不必要的。同时,大量使用SE模块也会很大程度上影响网络的实时性。
2020年,(ECA-Net,efficient channel attention networks)提出一种无降维的局部跨通道策略,通过考虑每个信道及其k个相邻信道捕获局部跨信道交互,在保证实时性的同时也保证了准确性[18]。但对于大目标物体来说,取特征通道的全局平均值能够很好的反应特征通道的响应情况。不过对于交通标志检测来说,交通标志一般只占图片很小的区域,在剩下的区域当中会存在许多无关的背景信息,这些信息虽然单个响应不大,但是总的信息响应还是不能忽略。因此,对通道进行全局平均,并不能充分代表通道的信息响应,也应当考虑通道的极值响应。本文针对上述情况对ECA-net进行的改进如图2所示。
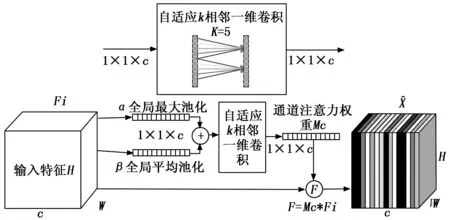
图2 ECA-A模块结构
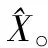
(10)
自适应k相邻一维卷积的使用即避免降维带来的低效性,也有效地捕捉跨信道交互信息。与SE网络相比参数也大大减少,保证了网络的实时性。将ECA-A模块加入到原DarkNet-53中的残差单元结构当中,更改后的残差模块如图3所示。

图3 改后的残差单元结构
2.2 空间金字塔
空间金字塔池化(SPP,spatial pyramid pooling)[19]是何凯明等人提出的一种多尺度特征融合模型。传统的神经网络只能接受以固定的尺寸作为输入,所以经常会对输入图片进行裁剪以及缩放等操作,以此来满足输入的要求,但这些操作会导致信息的丢失以及图像的失真,从而导致检测效果不佳。如图4所示,本文引入SPP模块以YOLOv3框架为基础,在DarkNet-53后面的第三至第四个DBL单元之间加入SPP模块,SPP模块是由4个分支构成,分别由步距为1尺寸大小为5×5、9×9、13×13的最大池化操作和一个跳跃连接,随后将4个分支进行拼接。这样可以获取多尺度局部特征信息,将其融入到后续的全局特征当中,从而得到更加丰富的特征表示,最终提高检测精度。

图4 SPP模块结构
2.3 增强上下文信息
对于目标检测而言,待检测目标不可能单独存在,它一定会和周围的其他目标或多或少存在某种关系,这就是通常所说的上下文信息。如何挖掘它们之间的关系,利用这个关系来增强特征的表示是上下文信息的核心问题。
对于交通标志检测而言,大部分的交通标志都悬挂在交通标志杆上,交通标志杆就是交通标志的上下文信息。因此,学习交通标志杆与交通标志之间的潜在关系是十分重要的。YOLOv3原有的Y3特征图包含了两个拼接,但都是深层特征,缺乏浅层特征表示。为此本文在原来的基础上,从DarkNet-53中获取输出尺寸大小为128×128的特征映射,经过大小为3×3步距为2的最大池化操作后得到64×64的特征图,将得到的3个尺寸相等的特征图进行拼接,经相关卷积操作后得到新的Y-3特征图。选择最大池化操作是因为交通标志杆和周围的颜色区别很大,最大池化后能选取到更多信息。整体更改后的网络结构如图5所示。相当于拼接处共拼接3个特征图,包含了最深层的特征信息、中层特征信息以及相对浅层的信息,这样既能获得更细粒度的信息,也能获得更加丰富的上下文信息。
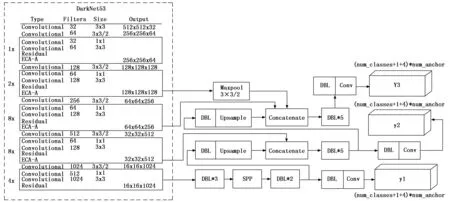
图5 更改后的网络结构
3 实验结果与分析
本文实验所使用的环境配置为Windows 10、CUD(Compute Unified Device Architecture)10.0、CUDNN(CUDA Deep Neural Network library)7.0。硬件配置为 Intel-CPU-i5-10400F 处理器,显卡为 Nvidia Ge Force GTX 1070Ti,调用GPU进行加速训练。
3.1 数据集与Anchor的重新设定
本文采用TT100K数据集[20],该数据集是由清华和腾讯联合打造。包含了中国各大城市的实景街拍交通标志图像。其中,交通标志共有150多种,本文选取实例数大于50的48个类别作为使用的类别,经删减和数据增强后,共得到15 800张图片,训练使用10 400张图片,测试使用5 400张图片。
Anchor值的设定对最终的检测性能至关重要,针对不同的数据集应当设定不同的Anchor值。合适的Anchor值能加快网络的收敛速度、降低误差。通过对TT00K数据集尺寸进行统计,发现55%左右的目标像素小于45像素×45像素,因此存在大量的目标相对尺寸较小的情况。使用K-means算法对参数进行重新选择,更改后的参数对比如表1所示。从表中可以看出修改后的Anchor大小比原来缩小了很多,这也符合TT100K数据集中的目标相对尺寸比较小这一情况。
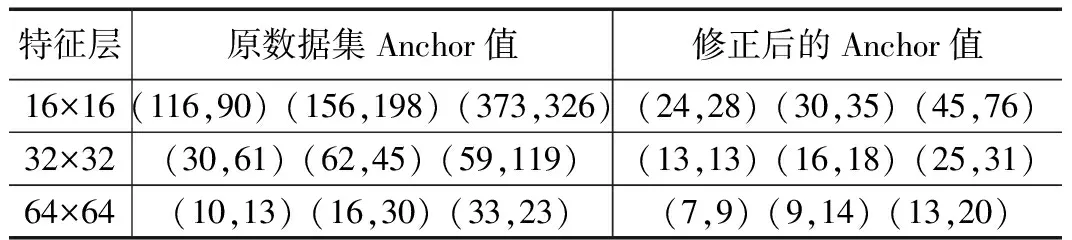
表1 Anchor值重定
3.2 评价指标与参数设置
实验指标采用平均精度均值(MAP,mean average precision)、小目标精度均值(AP-s,small object of average precision)、中型目标精度均值(Medium Object of Average Precision,AP-m)、大目标精度均值(AP-l,large object of average precision)以及画面每秒传输帧数(FPS,frame per second)。其中,MAP的数值越高表明模型的性能越好,FPS的数值越大表明模型的实时性就越好。在训练阶段,本文以YOLOv3作为基础框架,每种实验都进行100个epochs,初始学习率为0.001,动量和衰减分别设置为0.9和0.000 5,批处理数BatchSize设置为16。
3.3 结果与分析
本文首先基于YOLOv3对所提出的改进通道注意力机制压缩方式进行试验,找出最佳的α和β参数(α+β=1),实验结果如图6所示。结果表明在TT100K数据集中取α=0.6和β=0.4时模型的MAP达到最佳。后续实验的ECA-A模块都取α=0.6和β=0.4。
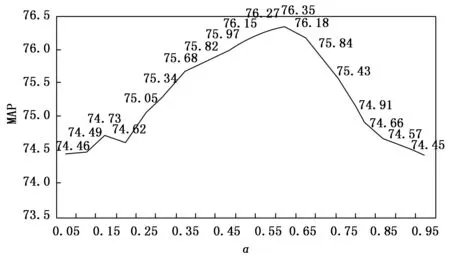
图6 参数选择
随后对于特征压缩方法的选择,在相同的实验环境下,本文所采用的方法与GMaxPool、GAvgPool以及GMaxPool和GAvgPool沿通道维度拼接这3个压缩方法进行对比,得到的MAP结果对比结果如表2所示。表明取α=0.6和β=0.4时的GMaxPool与GAvgPool沿通道相加的压缩方法性能最佳。
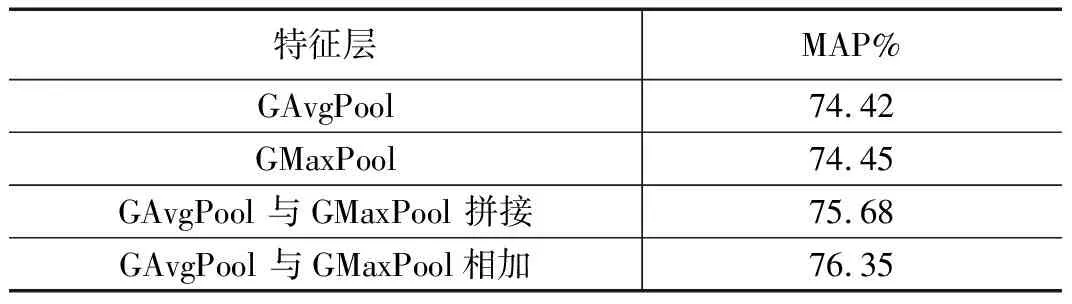
表2 各压缩方法对比结果
TT100K数据集相比于其他交通标志数据集来说,目标尺寸更小且图像分辨率更高,以YOLOv3为基础架构使用消融实验来验证改进与添加模块的有效性。评价指标分别采用IOU取值为0.5时的AP-s、AP-m、AP-l以及MAP,实验后的结果如表3所示。实验结果表明,单个模块中ECA-A对整体检测准确度的影响最大MAP提升了2.2%;SPP对整体都有提升;新的Y3特征图对小目标提升最大,提升了2.61%。YOLOv3在将3个改动全部添加后达到了最佳检测性能,MAP提升3.03%、AP-s提升4.59%、AP-m提升2.66%以及AP-l提升2.26%,可以看出整个改进后小目标检测的精度要优于单个改进后的精度。而后续的实验则使用改进后的网络。

表3 消融实验数据
将改进后的网络与其他主流方法进行实验比对,包括Faster R-CNN、SSD以及YOLOv3。取IOU值为0.5和0.75时的MAP和FPS作为评价指标。其中IOU为0.5时和IOU为0.75时的MAP分别为对检测能力和定位精度的有效评估指标。
从表4可以看出,当IOU取值为0.5时,改进后的YOLOv3的MAP值比第二的Faster R-CNN高出0.64%;当IOU取值为0.75时,改进后的YOLOv3的MAP值达到最佳,比第二的Faster R-CNN高出1.45%;在FPS指标上,改进后的YOLOv3只比最佳的YOLOv3每秒差5张图片,但高出YOLOv3-SE每秒11张图片。可以看出改进后的网络在模型性能、定位精度以及实时性方面都表现很好。

表4 4种检测网络对比
最后,为了进一步验证改进后的网络的模型性能,本文从数据集中选出三张图片进行测试,结果如图7所示,其中(a1)、(a2)、(a3)为YOLOv3网络的检测结果,(b1)、(b2)、(b3)为改进后网络的检测结果。

图7 实验测试结果
首先对比(a1)和(b1)的结果可以看出,两个都将目标完全地检测出来,(b1)在形变的交通标志上的预测框覆盖区域要优于(a1)的预测框;其次在(a2)与(b2)的结果上来看,(b2)检测出来而(a2)出现了漏检,这是由于这张图像上的目标与周边的环境相似,而改进后的网络丰富了上下文信息利用了交通标志杆这个信息,从而避免了这次漏检;最后对比了(a3)和(b3),(a3)出现了两个漏检(b3)出现了一个漏检,第三张图片的4个标志全都是像素小于10*10的,图中右边的两个目标边上的背景非常复杂,这也是YOLOv3都漏检的原因,而改进后的网络检测没有检测出“禁止鸣笛”的交通标志,原因可能是目标太小以及和周边背景颜色相近。综合来看,改进后的网络在小目标检测以及漏检方面要优于原YOLOv3。
4 结束语
本文主要介绍了改进后的交通标志网络,针对在目前检测算法中存在小目标检测精度不高、漏检及误检等问题,改进了ECA的压缩方式,将改进后的ECA-A加入到骨干网络DarkNet-53当中的残差模块,对通道进行重新标定,增强重要的通道抑制信息量较少的通道,显著地提高算法的检测性能;引入金字塔池化模块,以增强最终检测精度;重新拼接后的特征图包含了最深层的特征信息、中层特征信息以及相对浅层的信息,这样既能获得更细粒度的信息,也能获得更加丰富的上下文信息。实验表明改进后的网络在小目标检测、整体性能、定位精度以及实时性上的有效性。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
农业工程学报(2022年12期)2022-09-09
汽车实用技术(2022年9期)2022-05-20
计算技术与自动化(2022年1期)2022-04-15
上海师范大学学报·自然科学版(2019年5期)2019-12-13
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
中国新通信(2017年9期)2017-05-27
电子技术与软件工程(2016年24期)2017-02-23
小天使·一年级语数英综合(2016年8期)2016-05-14
小天使·一年级语数英综合(2014年7期)2014-06-26
