
基于深度神经网络数据集的关联处理方法研究
2022-03-29 00:49:32张翔张守震
客联 2022年1期
张翔 张守震

摘 要:基于深度学习方法对数据集进行特征提取。传统的残差神经网络有效解决了网络层数过深带来的梯度弥散问题,但是低网络层高分辨率对图像语义特征提取不足,高网络层低分辨率对图像细节特征提取不足,课题研究提出了一种多尺度特征融合的方式改进网络,以提升特征提取的质量。通过迁移学习的方式在PCB图像数据集上训练该网络并进行验证,相比于其他神经网络得到明显提升。对大规模数据集挖掘进行的研究有助于解决关联规则挖掘时的内存瓶颈问题,提高聚类算法的执行效率以及结果的质量,对以后相关的研究工作也有一定的借鉴意义。
关键词:神经网络;特征提取;深度学习
图像数据集的内容千变万化,想要通过单一的一种特征很难描述出图像完整的信息,借助某一个特征进行的图像检索的结果也并不十分满意,所以可尝试将不同的特征融合,采取多特征相结合的方式进行图像检测以提高准确率。不同的特征能够反映出不同部位的信息,整体信息和细节信息也都不一样,因此特征也可以被分为全局特征和局部特征。在数据挖掘和知识发现中利用约束信息可以提高挖掘的效率、精度等等。事实上,对于大规模数据集而言,可能蕴含着巨大的关联规则。如果盲目地进行挖掘,不仅效率很低,而且可能发现很多不相关的规则。利用约束,可以对具体的关联规则挖掘任务进行定程度的控制,从而使挖掘
工作向着我们期望的方向发展。
一、神经网络数据集处理和缺陷检测
PCB缺陷检测的研究对象即PCB裸板的图像数据,该图像数据是由工业相机拍摄所得,成像结果极易受到拍照时的光照条件、温度条件、空气条件的影响,此外传送带履带的抖动、拍摄相机的抖动都有可能导致 PCB 图像的质量,而 PCB 图像数据的质量直接影响了后续对于图像中的缺陷进行识别定位分类的准确程度,因此为了保证后续的深度学习算法的良好效果,需要对 PCB 图像数据进行图像预处理[1],这一步骤十分关键。
PCB 图像数据集来自于北京大学智能机器人开放实验室免费公开提供的印刷电路板瑕疵数据集(http://robotics.pkusz.edu.cn/resources/dataset/)。该数据集共包含 1386 张具有多种不同缺陷类型的原始 PCB 图像,用于 PCB 图像的缺陷检测、分类和定位等问题的研究。
二、图像数据集灰度化处理
三维颜色 RGB 空间由三原色红绿蓝(RGB)构成,图像可以理解为由三原色按照不同的比例叠加而成。对于相机拍摄得到的图像進行数字离散化,则图像中的每一个像素的像素值都在[0,225]的区间范围内,则图像就可以转变成一个三维数组[H,W,C],其中 H 代表图像的横向量,W 代表图像的列向量,C 代表图像的通道数量,在 RGB 颜色空间下即为 RGB 三个通道,当计算机对图像数据进行操作时,就需要计算三个通道的像素值,运算量太大,因此可以将三个通道的彩色图像转变成单通道的灰度图[3],参数计算量会大大减少,这便是图像灰度化,RGB 空间的灰度转换的公式如式1 所示:
Gray(i, j) =0.29xR(i, j) +0.59xG(i, j) +0.11xB(i, j) (1)
(一)灰度图像均衡化消除
图像直方图[3]反映了图像中不同亮度值的像素所占的比例,能够直观地看出图像的亮度分布,但是对于单通道的灰度图像来说,直方图则反映了该图像中不同灰度级出现的统计情况。图像的灰度直方图是一维离散函数,如式 2 所示:
h(k) =nk, k =0,1, , 255 (2)
其中, nk 表示为图像的灰度值为 k 的像素点的个数,图像的灰度级有 256 种。其中p(k)表示图像像素中灰度值为k出现的概率。分别计算PCB数据集的原始图像和灰度图像的直方图,得到的结果如图1所示。
三、训练数据集的图像实验块选择
与那些在人工标注真实角点位置的实际拍摄棋盘数据集上进行训练的基于深度学习的棋盘角度检测方法不同[3],我们的网络在带有真实亚像素角点位置的合成训练集上训练。
如果在训练时,我们仅对每个真实亚像素角点所在像素,取其15×15邻域作为输入图像参与训练 (cn与 pc在同一像素内),那么训练时的亚像素角点坐标偏移量真实值 dx和 dy应该在 [0.5,0.5) 范围内。在测试时,如果第一步的整数角点定位获得了正确的整数位置,我们的网络能够正确进行后续的亚像素精调。但是如果测试时第一步的整数角点定位包含错误结果 (一般情况下是不可避免的),此时出现了训练时没有的情况,输入网络的 15×15 图像块的中心像素并没有包含亚像素角点,这种情况下我们的网络将无法进行亚像素位置精调。
(一)测试数据集合成测试实验
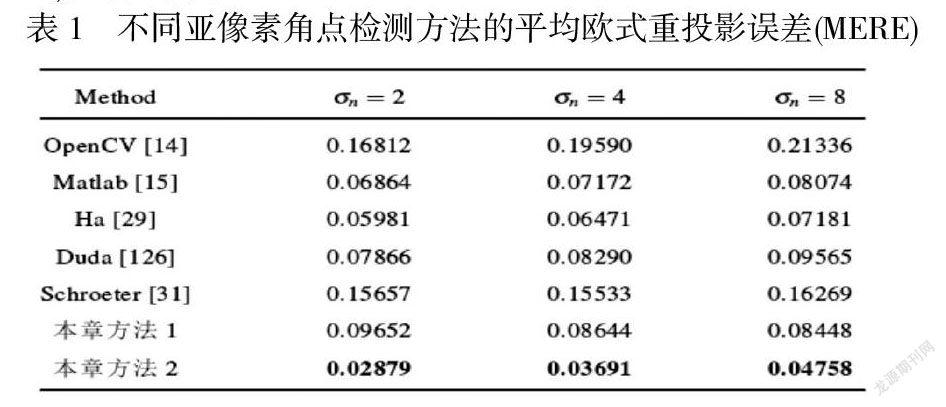
由于合成棋盘数据集的真实亚像素角点位置是已知的,我们能够计算平均角点定位误差MELE,此外我们也比较了棋盘角点检测算法中最常用的MERE。我们首先对合成测试集进行了不同下采样系数δ的双三次下采样,用来测试网络的输入图像尺寸对结果的影响。在测试图片具有不同分辨率,15×15的网络输入大小具有最低MED误差,因此我们选择15×15作为网络输入图像块的大小。不同亚像素角点检测方法在不进行模糊,不同噪声等级的合成测试集上的平均欧式重投影误差 (MERE)如表1所示。
四、总结
对于原始的数据集图像,往往因成像条件不同导致图像特征不明显,并伴随产生很多噪声,不能直接用于特征提取。本文采用将图像灰度化,以摒弃色彩信息干扰,再对灰度图进行直方图均衡化以增强前景与后景的对比,最后通过高斯滤波等方式降低图像的噪声干扰,实现了神经网络数据集图像突出特征,过滤噪声的目的。由于用于训练神经网络的图像数据集规模较小,且采用迁移学习的方法进行训练,而深度学习模型对于数据集的规模需求较大,因此训练的效果有限,后续可以对数据集进行全方位补充。
参考文献:
[1]Zakria. 基于深度学习的快速车辆再识别研究[D].电子科技大学,2020.DOI:10.27005/d.cnki.gdzku.2020.004719.
[2]刘皓. 基于深度学习的行人再识别问题研究[D].合肥工业大学,2017.
[3]吴国清. 科学计算时变数据集的数据挖掘算法研究[D].中国工程物理研究院,2019.
猜你喜欢
电子制作(2019年19期)2019-11-23 08:42:00
电子制作(2018年19期)2018-11-14 02:37:08
自动化学报(2017年11期)2017-04-04 02:52:58
新教育时代·教师版(2016年23期)2016-12-06 06:02:38
法制与社会(2016年32期)2016-12-01 15:25:53
软件导刊(2016年9期)2016-11-07 22:20:49
软件工程(2016年8期)2016-10-25 15:47:34
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
海军航空大学学报(2015年4期)2015-02-27 13:45:47
