
基于机器学习的通风网络故障诊断方法研究
2022-03-28 11:50张浪张迎辉张逸斌李左
工矿自动化 2022年3期
张浪,张迎辉,张逸斌,李左
(1.煤炭科学研究总院,北京 100013;2.煤炭科学技术研究院有限公司 安全分院,北京 100013;3.煤炭资源高效开采与洁净利用国家重点实验室,北京 100013)
0 引言
随着智慧矿山建设和智能化开采的提出,矿井通风亟需向智能化、信息化方向转变升级[1-3]。研究矿井通风网络故障诊断对促进矿井通风智能化发展、提高通风系统安全保障能力具有重要意义[4-5]。
目前煤矿通风系统故障诊断方法主要是根据井下各类传感器监测数据进行分析判断,只能识别传感器所在巷道的故障。针对该问题,一些学者将机器学习算法[6-9]应用到煤矿通风系统故障诊断中,取得了一定成果。刘剑等[10-12]提出了基于支持向量机(Support Vector Machine,SVM)的矿井通风系统阻变型故障诊断方法,将风量-风压复合特征作为SVM的输入构建诊断模型,提高了故障诊断准确率。周启超等[13]提出采用改进遗传算法对SVM 参数进行优化,并用于通风系统故障诊断。黄德等[14]将风量、风压、节点压能等7 种特征作为观测特征进行组合试验,解决了故障诊断观测特征冗余无关的问题。刘彦青[15]提出了基于BP 神经网络的矿井风量预测模型,对待掘巷道摩擦阻力系数进行了预测。
机器学习算法通过对已知数据的学习来预测未知数据,现有通风系统故障诊断方法大多针对1 种机器学习算法进行研究,无法保证所选算法为最优。因此,本文对多种机器学习算法进行分析比较,选择SVM、随机森林和神经网络3 种算法,通过网格搜索和交叉验证相结合的方法对基于SVM、随机森林、神经网络的通风网络故障诊断模型进行参数寻优,最后采用3 种诊断模型进行实验和现场验证。
1 机器学习算法选择及原理
1.1 算法选择
对最近邻、线性模型、朴素贝叶斯、决策树、随机森林、梯度提升决策树、SVM、神经网络等8 种机器学习算法进行比较[16],结果见表1。综合考虑各种算法的优缺点,选择SVM、随机森林和神经网络3 种机器学习算法进行通风网络故障诊断研究。

表1 8 种机器学习算法比较Table 1 Comparison of eight machine learning algorithms
1.2 SVM 原理
SVM 主要思想是建立一个最优超平面作为决策曲面,使得正例与反例之间的间隔最大化。在样本空间中,超平面可描述为

式中:wT为法向量,决定超平面的方向;x为输入特征变量;b为位移项,决定超平面与原点之间的距离。
定义2 个标准超平面H1和H2,H1:wTx+b=1,H2:wTx+b=-1,2 个平面之间的距离就是分类间隔,可表示为
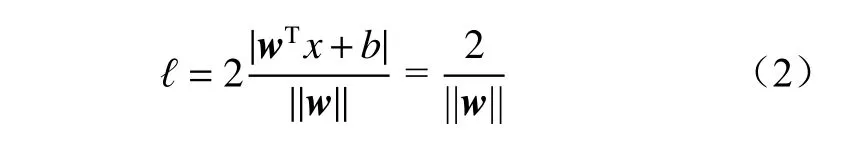
影响SVM 分类准确率的参数主要是γ和C。γ是控制高斯核宽度的参数,决定点与点之间的距离,γ越小,则决策边界变化越慢,生成的模型复杂度越低。C是正则化参数,限制每个点的重要程度,C越大,则对应的模型越复杂。
1.3 随机森林原理
随机森林是一种集成算法,实现步骤如下:
(1)从大小为N的样本数据集L中有放回地随机抽取N个训练样本,得到一个自助训练集Lk。
(2)用自助训练集Lk训练1 棵决策树,在决策树的每个节点需要分裂时,随机从每个样本的M个属性中选取M0个作为分裂属性,然后从这M0个属性中选择1 个进行分裂。
(3)每个节点按照步骤(2)进行分裂,直到不能够再分裂为止。
(4)按照步骤(1)-步骤(3)建立大量决策树,构成随机森林。
影响随机森林分类准确率的参数主要是决策树个数p和限制分支时考虑的特征个数q。p值越大,则对应的随机森林越复杂。q值决定每棵树的随机性大小,q值越小,随机森林中的树越不相同,一般默认其值与样本属性个数M的关系为

1.4 神经网络原理
神经网络是一种模拟人脑思维的计算机模型。神经网络无需事先确定描述输入与输出之间映射关系的数学方程,而仅通过自身的训练学习某种规则,在给定输入值时得到最接近期望输出值的结果。
影响神经网络分类准确率的参数主要有隐含层层数、隐含层节点数、正则化参数、迭代次数及激活函数等。隐含层节点数t越大,正则化参数α越小,表示模型复杂度越高。确定隐含层节点数的经验公式为
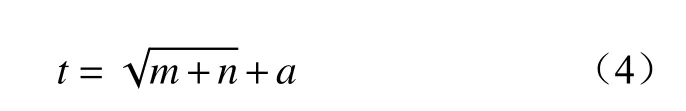
式中:m为 输入层节点数;n为 输出层节点数;a为调节常数,取值范围一般为1~10。
2 基于机器学习的通风网络故障诊断方法
采用SVM、随机森林、神经网络3 种机器学习算法建立通风网络故障诊断模型。采集通风系统数据并进行预处理,从处理后的数据中随机抽取75%作为训练集,25%作为测试集;通过网格搜索和交叉验证进行模型参数寻优,将测试集代入训练过的模型,根据测试集准确率进行最终评估。基于机器学习的通风网络故障诊断方法流程如图1 所示。
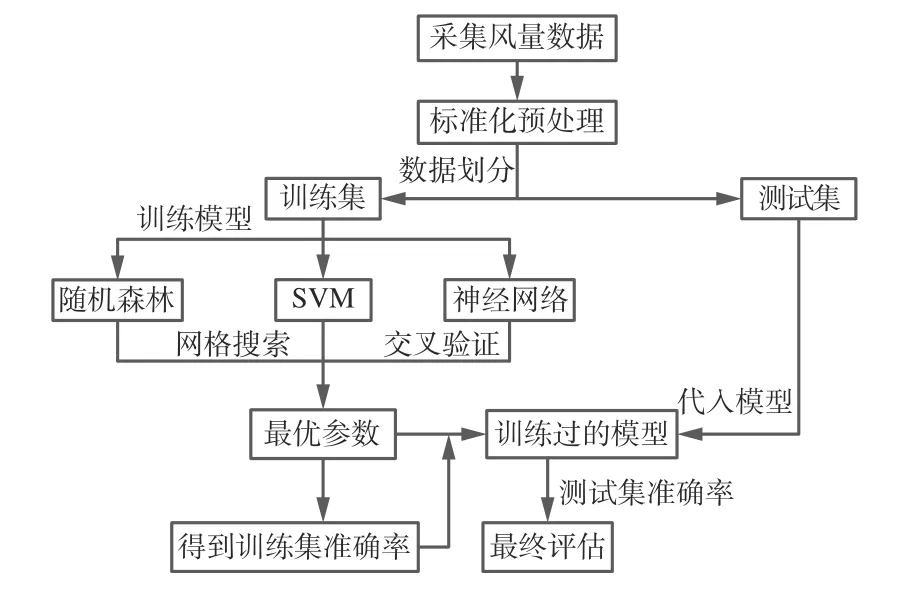
图1 基于机器学习的通风网络故障诊断方法流程Fig.1 Flow of fault diagnosis method of ventilation network based on machine learning
3 数据采集及预处理
3.1 数据采集
3.1.1 实验平台
根据矿井通风系统实际布局,按照几何相似、运动相似、动力相似准则构建通风网络管道模型,采用中央并列式通风方式和机械抽出式通风方法,主副斜井进风,回风立井回风,布置1 台2.5 kW 轴流式通风机作为通风动力装置,共布置2 个水平、2 个回采工作面、1 个备用工作面、4 个掘进工作面及3 处硐室型用风地点。
实验平台由通风系统网络管道子系统、通风系统传感器与调控设施子系统组成,如图2 所示,其中黄色部分表示自动蝶阀,蓝色部分表示风速传感器,红色部分表示温湿度传感器。通风系统网络管道子系统由直径为160 mm 的透明亚克力管道组成,通风管道总长度为75 m,管道网络分支为62 条,管道网络节点为38 个;通风系统传感器与调控设施子系统主要由16 台自动蝶阀、14 台压差传感器、18 台风速传感器、3 台温湿度传感器组成。

图2 通风网络故障诊断实验平台Fig.2 Experimental platform of fault diagnosis of ventilation network
通风网络如图3 所示,其中e1-e62为管道网络分支,为管道网络节点。
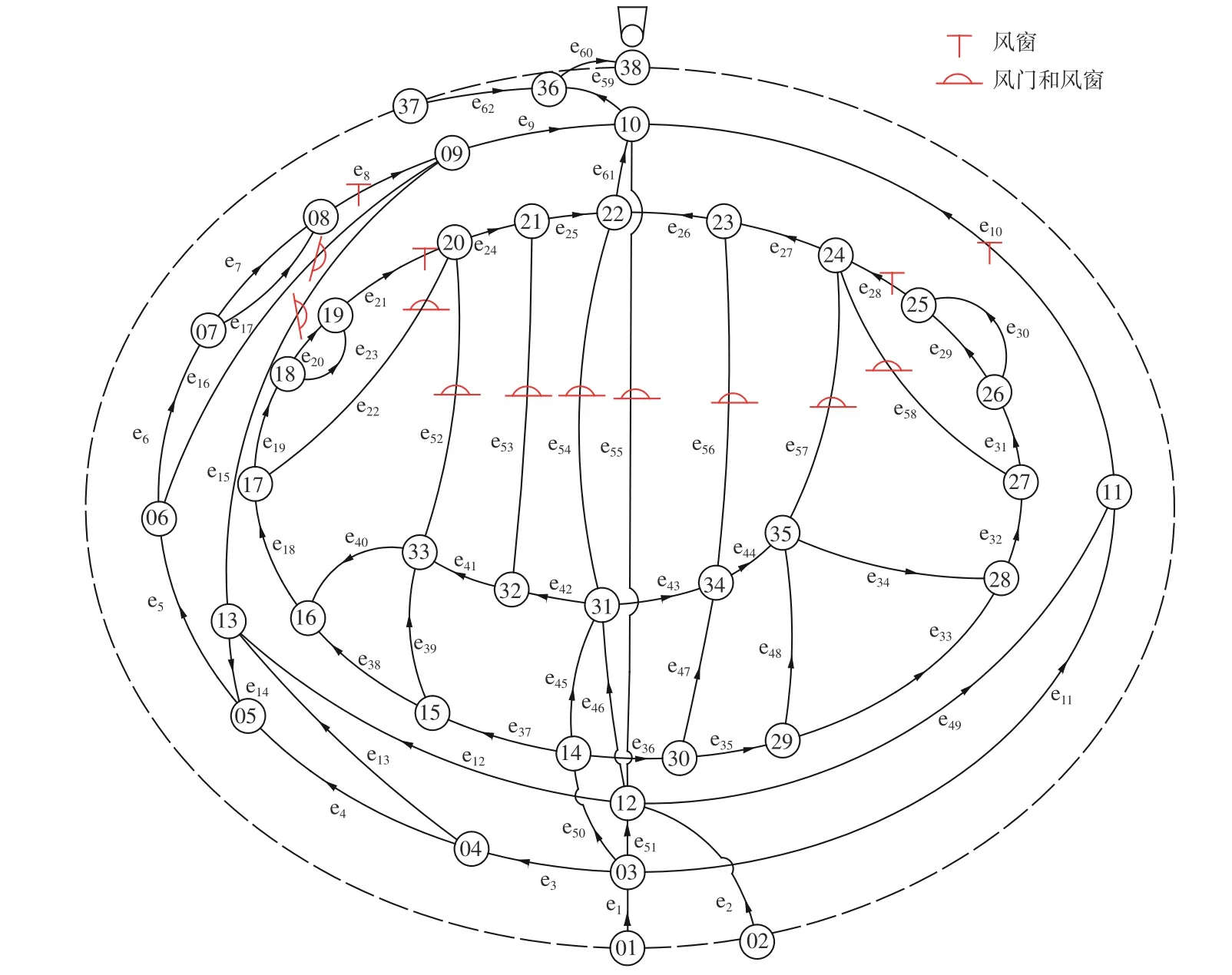
图3 实验平台通风网络Fig.3 Ventilation network of experimental platform
3.1.2 数据采集过程
根据矿井通风阻力定律,有

式中:hi为第i条 分支的阻力,Pa;ri为第i条分支的风阻,N·s2/m8;Qi为第i条 分支的风量,m3/s。
由式(5)可知,当某条巷道分支风阻发生改变时,会引起整个通风网络的风量重新分配。在实验平台中,用蝶阀代替通风构筑物风门、风窗,保持通风机动力不变,则蝶阀开度变化会造成其所在分支的等效风阻发生变化,进而引起风量变化。实验时随机选取分支e8,e10,e15,e16,e55模拟故障情况,具体步骤如下:
(1)将通风机频率调为50 Hz,记录各蝶阀初始状态下e1-e3,e7,e9-e12,e20,e24,e27,e29,e35,e37,e41,e44,e49,e60分支中18 个风速传感器测得的风速。
(2)调节分支e8中蝶阀开度,调节范围为0~100°,不包括初始角度50°,连续调节60 次,记录每次调节后网络解算得到的风速。
(3)按照步骤(2)依次调节分支e10,e15,e16,e55中蝶阀开度,并收集每次变化后18 个风速传感器测得的风速。
(4)测量管道网络的断面面积,将风速数据换算成风量。
18 个风速传感器均为同一型号,测量精度为±0.2 m/s+2%FS,且在出厂前均已标校完成,确保了风量数据的准确性。
实验共收集风量数据300 组,部分数据见表2。将18 个分支的风量作为故障诊断模型的输入变量,故障分支编号作为输出变量。
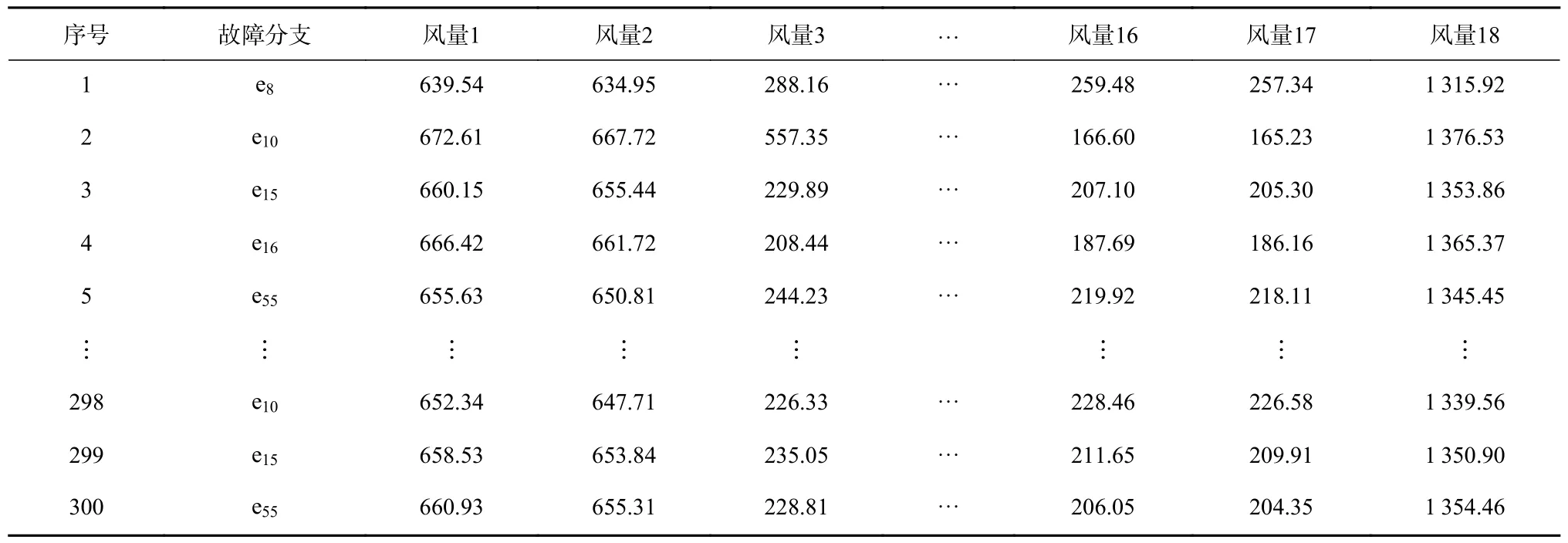
表2 部分风量数据Table 2 Part of the air volume data m3/min
3.2 数据预处理
为使18 个输入风量数据位于同一量级,采用标准化方法对数据进行预处理。标准化方法确保了每个特征的平均值为0,方差为1,计算公式为

式中:ynew为标准化处理后的数据;yj为第j个输入数据;为yj的平均值;σ为yj的方差;K为数据总数。
各分支初始风量数据箱形图如图4 所示,从上至下分别为上边缘、上四分位数、中位数、下四分位数和下边缘,其中上边缘、下边缘分别表示每个分支300 个数的最大值和最小值,数据中75%低于上四分位数,数据中25%低于下四分位数,中位数则是按大小顺序排列后中间数的值。从图4 可看出,初始数据中分支e18的风量最大,都在1 000 m3/min 以上,分支e14的风量最小,最大值不超过200 m3/min,各分支风量数据差距较大。
预处理后各分支风量数据箱形图如图5 所示。通过对比发现,标准化后风量数据之间的差距大大缩小。
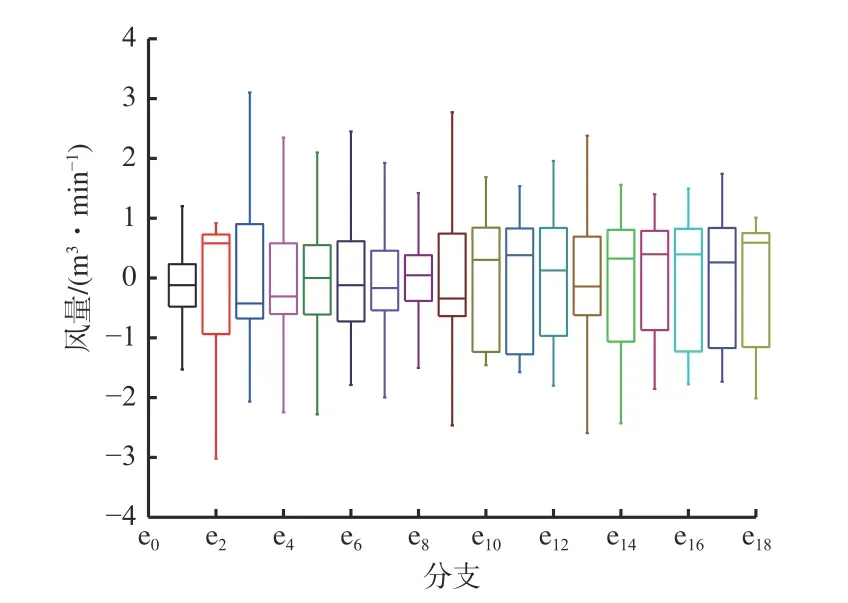
图5 预处理后风量数据箱形图Fig.5 Box plot of air volume data after preprocessing
4 通风网络故障诊断模型训练和测试
4.1 交叉验证与网格搜索
通过交叉验证和网格搜索对基于SVM、随机森林、神经网络的通风网络故障诊断模型进行参数寻优。
交叉验证是一种评估泛化性能的统计学方法。在交叉验证过程中,数据被划分为k折,训练模型时依次使用每一折作为测试集,其他k-1 折作为训练集,最后得到k个精度值。评价交叉验证精度的一种常用方法是计算平均值,通过k折划分使得所有类别的数据都能被训练,模型更稳定,数据更全面。
网格搜索是一种模型参数优化技术,其本质是对指定参数值的穷举搜索。对指定的不同参数作笛卡尔乘积,得到若干组参数组合,使用每组参数训练模型,挑选在交叉验证中表现最好的参数作为最优参数。
4.2 参数寻优
4.2.1 SVM 模型参数寻优
在基于SVM 的故障诊断模型中,设C={10,102,103,104,105,106},γ={10-5,10-4,10-3,10-2,10-1,1},经过网格搜索和5 折交叉验证,得到不同参数组合下SVM 模型交叉验证平均分数热力图,如图6 所示。可以看出,C=10,γ=10-5时,交叉验证平均分数最低,只有0.545 0;随着C和γ增大,交叉验证平均分数也不断增大,当C=104,γ=10-1时,交叉验证平均分数最高,达0.905 0;继续增大参数值,交叉验证平均分数不再增大,说明最优参数为C=104,γ=10-1,该参数下SVM 模型分类预测能力最优。该结果验证了参数值区间选取的合理性。
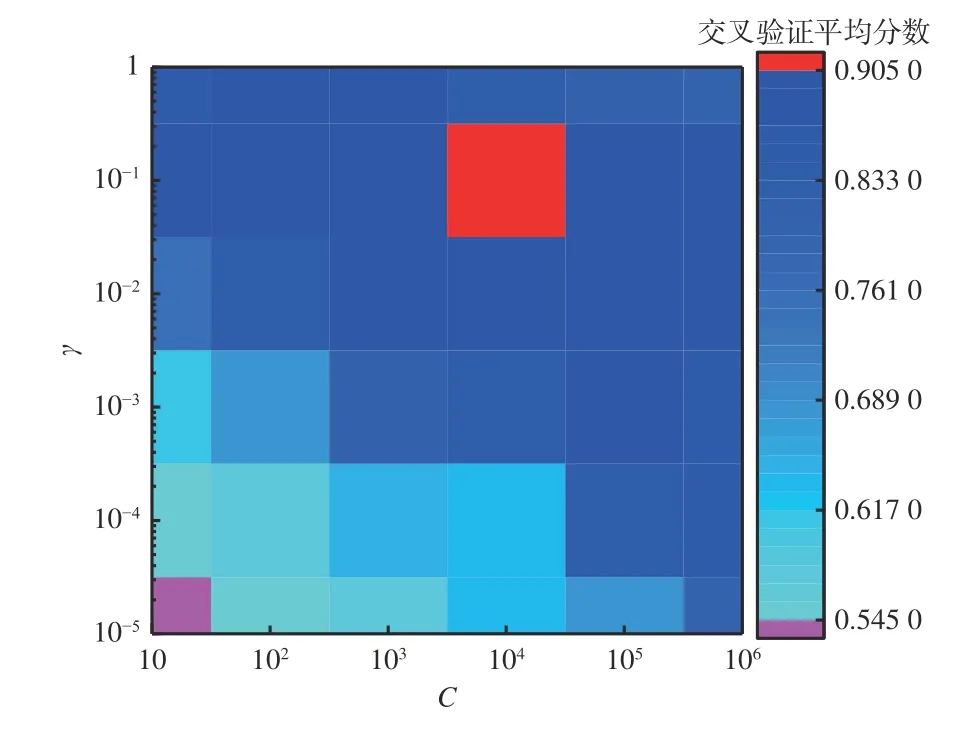
图6 SVM 模型交叉验证平均分数热力图Fig.6 The heat map of cross-validation average score of SVM model
4.2.2 随机森林模型参数寻优
在基于随机森林的故障诊断模型中,设决策树个数p={5,10,15,20,25,30,35},由于输入特征为18 个分支的风量,即M=18。根据式(3),令q={1,2,3,4,5}。经过网格搜索和5 折交叉验证,得到不同参数组合下随机森林模型交叉验证平均分数热力图,如图7 所示。可以看出,p=5,q=1 时,交叉验证平均分数最低,只有0.658 0,此时模型相对简单;随着决策树个数增加和随机性参数增大,模型逐渐复杂化,交叉验证平均分数不断增大,当p=15,q=4 时,交叉验证平均分数最高,达0.855 0;继续增大决策树个数和随机性参数值,交叉验证平均分数不再增大。
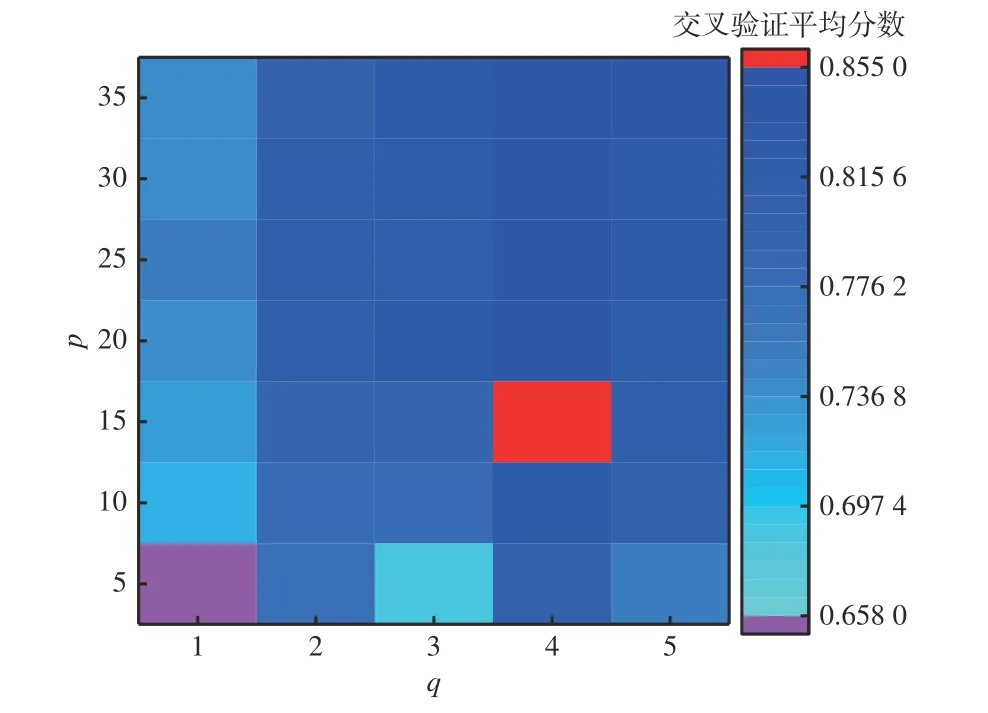
图7 随机森林模型交叉验证平均分数热力图Fig.7 The heat map of cross-validation average score of random forest model
4.2.3 神经网络模型参数寻优
通过实验研究单隐层条件下隐含层节点数和正则化参数对分类准确率的影响。输入数据为18 个风速传感器的风量,输出数据为5 个巷道分支编号,即m=18,n=5,根据式(4),设隐含层节点数t={6,7,8,9,10,11,12,13,14,15,16,17,18},正则化参数α={10-6,10-5,10-4,10-3,10-2,10-1}。经过网格搜索和5 折交叉验证,得到不同参数组合下神经网络模型交叉验证平均分数热力图,如图8 所示。可以看出,t=6,α=10-5时,交叉验证平均分数最低,只有0.828 0;随着隐含层节点数量增加,模型逐渐变得复杂,当t=14,α=10-5时,交叉验证平均分数最高,达0.915 0,此时神经网络模型分类预测能力最好。
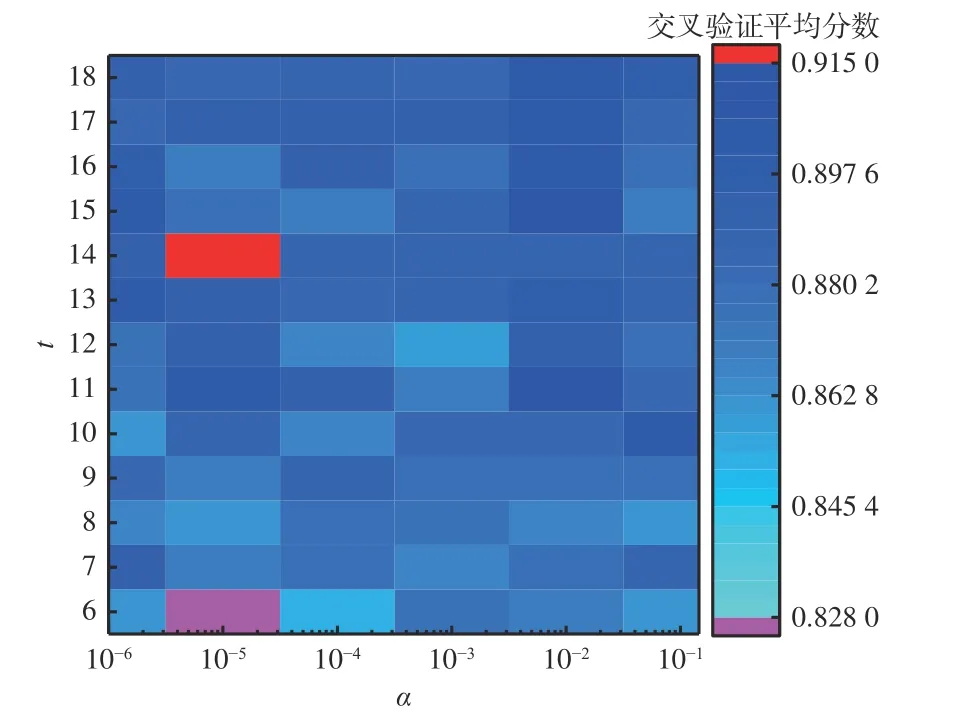
图8 神经网络模型交叉验证平均分数热力图Fig.8 The heat map of cross-validation average score of neural network model
4.3 结果对比分析
3 种故障诊断模型在训练集和测试集上的准确率见表3。可看出基于神经网络的通风网络故障诊断模型效果最好,泛化能力最强。

表3 故障诊断模型准确率比较Table 3 Comparison of accuracy of fault diagnosis models
3 种故障诊断模型在测试集上对分支e8,e10,e15,e16,e55的预测准确率如图9 所示。可以看出,神经网络对5 个分支的预测准确率均为最高,进一步验证了神经网络模型优秀的泛化性能。

图9 故障诊断模型在各分支上的预测准确率Fig.9 Prediction accuracy of fault diagnosis model on each branch
5 现场验证
为了进一步比较3 种故障诊断模型的准确率,在陕煤集团神木张家峁煤矿进行现场验证。依次调节22201 运输巷风窗FC-2-2-001、22202 运输巷风窗FC-2-2-002、22203 运输巷风窗FC-2-2-003 过风面积,监测不同状态下2-2煤风窗附近8 个测风站的风量,共获取160 组数据。将其中的75% 划分为训练集,25%划分为测试集,对3 种故障诊断模型进行训练和测试,结果见表4。可以看出,神经网络模型在训练集和测试集上的准确率均为最高。
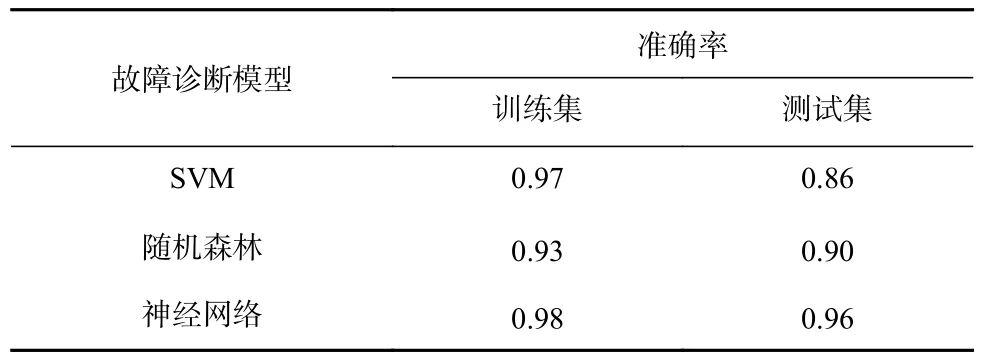
表4 3 种故障诊断模型准确率Table 4 Accuracy of three fault diagnosis models
随机调节2-2煤运输巷3 个风窗的过风面积,监测风窗附近8 个测风站的风量,共收集120 组新数据,输入神经网络模型进行预测,3 个风窗故障位置诊断结果散点图如图10 所示,其中风窗序号1,2,3 分别表示FC-2-2-001,FC-2-2-002,FC-2-2-003。可以看出,风窗FC-2-2-002 的40 个故障样本全部预测正确;风窗FC-2-2-001 的40 个故障样本中,有1 个样本被误判为风窗FC-2-2-002 的样本,其余全部预测正确;风窗FC-2-2-003 的40 个故障样本中,有1 个样本被误判为风窗FC-2-2-002 的样本,其余全部预测正确。对3 个风窗故障位置的诊断结果统计见表5,可见,基于神经网络的通风网络故障诊断模型准确率达0.98,进一步验证了其可靠性。
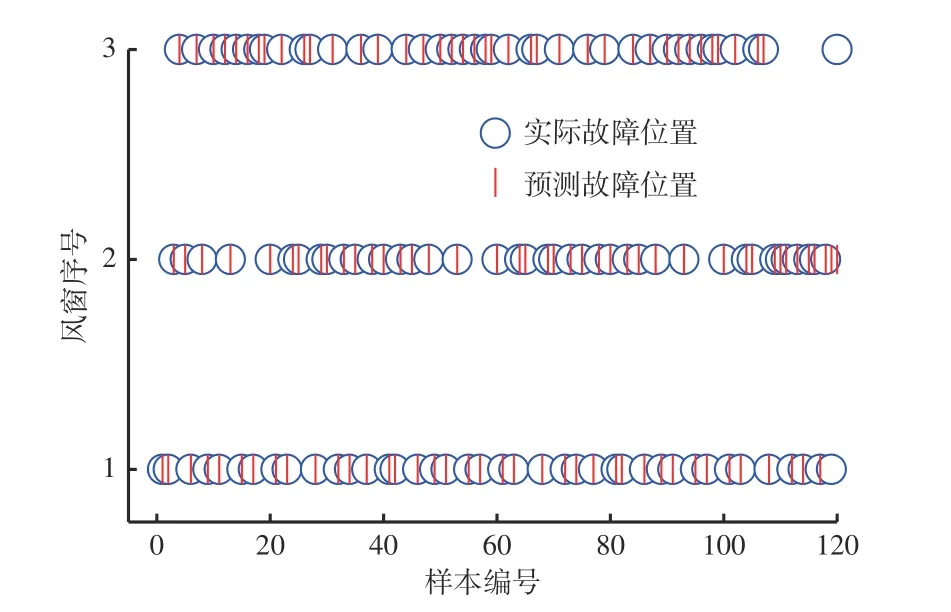
图10 故障位置诊断结果散点图Fig.10 Scatter plot of fault location diagnosis results

表5 故障位置诊断结果统计Table 5 Statistics of fault location diagnosis results
6 结论
(1)在通风网络管道模型实验平台上收集通风数据,分别建立基于SVM、随机森林、神经网络的通风网络故障诊断模型,并运用网格搜索对参数进行遍历寻优,得出神经网络模型在隐含层节点数量为14、正则化参数为10-5时,故障诊断准确率最高,泛化能力最好。
(2)将基于SVM、随机森林、神经网络的通风网络故障诊断模型应用到张家峁煤矿现场数据集,得出3 种模型在测试集上的故障诊断准确率分别为0.86,0.90 和0.96。收集120 组新的通风数据并输入神经网络模型进行故障预测,准确率达0.98,进一步验证了神经网络模型的准确性和可靠性。
猜你喜欢
西安工程大学学报(2022年4期)2022-08-27
汽车实用技术(2022年12期)2022-07-05
黑龙江大学自然科学学报(2022年1期)2022-03-29
计算机系统应用(2021年10期)2022-01-06
今日农业(2021年12期)2021-11-28
电力与能源(2021年4期)2021-09-07
学生天地(2019年28期)2019-08-25
初中生世界·八年级(2019年6期)2019-08-13
中国矿山工程(2019年2期)2019-01-10
小学生导刊(低年级)(2016年9期)2016-10-13
