
改进残差网络的字轮式数字表盘识别算法
2022-03-24 04:00王志威郑恭明
科学技术与工程 2022年6期
王志威, 郑恭明
(长江大学电工电子国家级实验教学示范中心, 荆州 434023)
随着现代通信技术的发展,远程抄表技术正在被广泛地应用在水表、电表、气表等计量表中[1-2]。但在农村地区或城市的老居民楼中,仍然使用的是传统的机械数字表,这需要派遣专门的抄表人员去进行人工抄表[3-4]。学者们利用人工智能的方法针对传统的机械数字轮式计量表计数的自动识别进行研究[5]。文献[6]采用模板匹配法,将图片的粗网格特征和穿越次数特征相结合作为特征向量,通过特征向量之间的欧式距离进行了字符识别。文献[7]针对字轮式仪表出现的双半字符数字情况进行了研究,提出利用改进的Hausdorff距离模板匹配法进行匹配识别,即通过比较上下字符的比例确定字符读数。文献[8]采用方向梯度直方图(histogram of oriented gradient,HOG)特征提取方法来提取待识别图片的特征,利用训练好的支持向量机(support vector machines,SVM)进行字符的识别。文献[9]采用改进的Lenet-5网络模型来识别数字字符,将对非对称卷积前后的组合特征进行融合,提高网络对双半字符的识别能力。文献[10]采用改进的VGG16网络模型进行数字字符的识别,同时通过迁移学习的方法对提高小样本集的识别率。
上述文献的研究取得了一些进展,但也还存在模型训练时间和预测时间较长、字符识别率不高、模型参数过大、终端部署成本高[11]等情况,因此,现提出一种改进残差网络的字轮式数字表盘识别算法。首先对采集的表盘图像进行图像预处理操作,将要识别的数字区域从图像中提取出来,并对其进行字符分割,为后面的数字识别做准备;然后依次将分割后的数字字符传入到改进的ResNet网络中进行数字识别,最后输出识别结果,实现对字轮式数字表盘的识别。以期为深度神经网络模型部署在轻量级嵌入式设备上提供理论基础。
1 图像预处理
以机械字轮式水表为例,通过感兴趣区域(region of interest,ROI)提取、分辨率调整、字符分割、数据增强等操作[12-13],对采集到的水表图片进行处理,处理结果如图1所示。

图1 预处理结果示例图Fig.1 Sample graph of preprocessing result
ROI操作主要是先对水表图片进行自适应二值化,二值化效果如图1(a)所示。然后对图像中的数字区域进行提取,得到的结果如图1(b)所示。其作用是简化深度神经网络在提取特征时的复杂度,同时提高网络的识别速度和准确率。
分辨率调整是为了解决ROI操作时,提取的数字字符区域大小不同,从而使得字符分割不均、残缺等问题。字符分割则是利用固定规则的静态边界法对水表数字区域进行分割,其主要依据水表数字字符的宽度、字符间的间隔等固定参数将水表数字字符单个分割出来,分割结果如图1(c)所示。
数据增强主要是通过对分割后的字符图片进行随机亮度、对比度调整,以及大小缩放、翻转、平移等操作,对训练样本进行扩充,提高网络模型的泛化能力以及鲁棒性,防止在训练中出现过拟合情况。
2 网络模型的构建
2.1 ResNet网络
ResNet网络是由He等[14]提出,在2015年的ImageNet图像识别挑战赛夺冠,深刻影响了后来的深度神经网络设计。该网络主要是解决当深度神经网络的层数加深时,容易出现梯度弥散或梯度爆炸,从而导致网络模型的准确率降低的问题[15-17]。
该网络模型主要是通过多个残差模块组成,残差模块如图2所示。在网络训练中,当网络模型的准确率收敛时,该模块可以将后面的神经网络层变为恒等映射层,从而使得网络保持最优状态[18],避免训练精度随着网络神经层数的增加反而降低的问题。
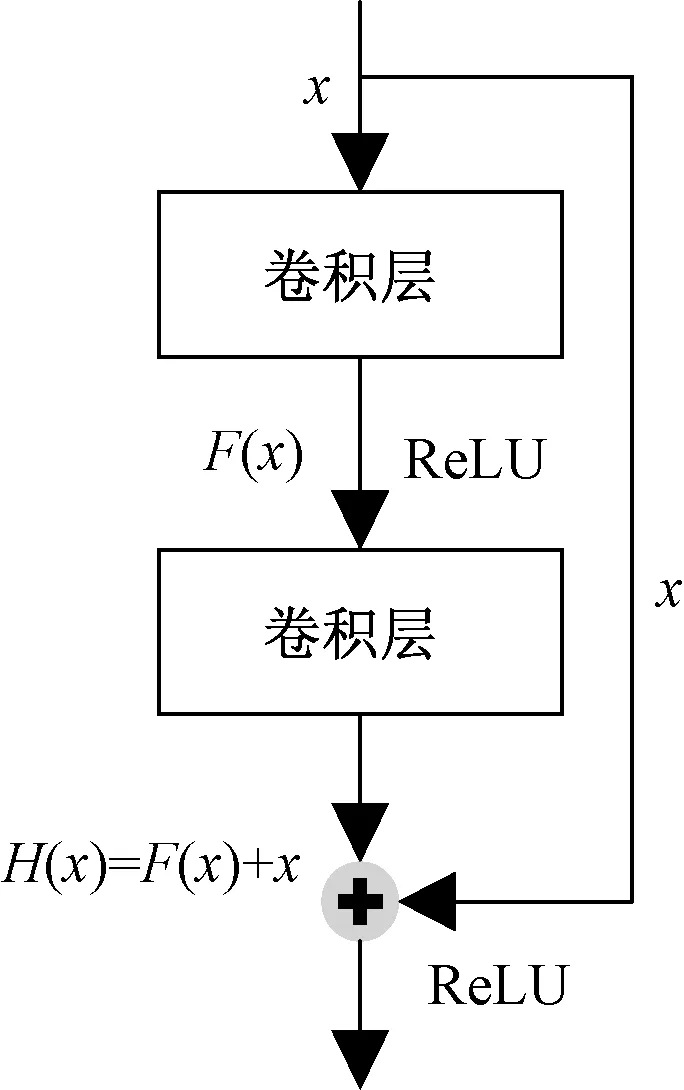
x为模块输入特征;F(x)为残差映射;ReLU为激活函数类型; H(x)为残差模块输出值图2 残差模块示意图Fig.2 Sample graph of residual module
从图2可以看出,残差模块的输出结果为
H(x)=F(x)+x
(1)
恒等映射就是当F(x)=0,使得H(x)=x。同时由式(1)能推出残差映射公式为
F(x)=H(x)-x
(2)
从式(2)可以得出,当F(x)无限趋近于0时,即网络达到了最优状态,即使随着网络层数的加深,网络模型的训练精度也不会下降。
现有的经典ResNet网络模型类别根据网络层数不同可分为ResNet-18、ResNet-34、ResNet-50、ResNet-101和ResNet-152[19]。
2.2 深度可分离卷积
深度可分离卷积(depthwise separable convolution,DSC)是由逐通道卷积 (depth wise,DW)和逐点卷积(point wise,PW)组成,用来提取图像特征,其原理图如图3所示。
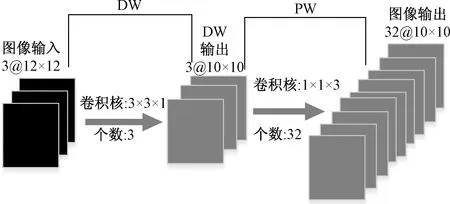
图3 深度可分离卷积原理图Fig.3 Schematic diagram of depthwise separable convolution
首先DW部分是对输入图像进行逐通道卷积,即一个卷积核卷积一个通道;图3中的卷积核大小为3×3×1,则该部分产生的参数个数为30个,乘法运算次数为2 700次;然后PW部分是通过尺寸为1×1×M的卷积核进行逐点卷积,其中M为输出通道数;如图3中使用的是1×1×3的卷积核,则产生的参数个数为 128个,乘法运算次数为9 600次。可见使用深度可分离卷积将一张尺寸为12×12×3的图像经过特征提取成尺寸为10×10×3的图像,其中产生的参数个数为158个,乘法运算次数为12 300次。若是使用传统的卷积方法,则会产生的参数个数为896,乘法运算次数为86 400次。
由此可见深度可分离 卷积与传统的卷积相比,其参数量和乘法运算次数均大幅减少,提升网络运算速度同时降低网络参数量。
2.3 Dropout函数
Dropout函数主要作用是在深度学习的训练过程中,按照一定的概率让网络神经单元结果被丢弃,即输出置0、不更新权重。由于Dropout是随机丢弃网络神经元,则使每次训练后的网络结构都可能不相同,因此可以将Dropout函数理解成模型平均,其含义就是将训练后所生成的不同模型的预测结果通过相应的权重进行平均。其作用如图4所示。
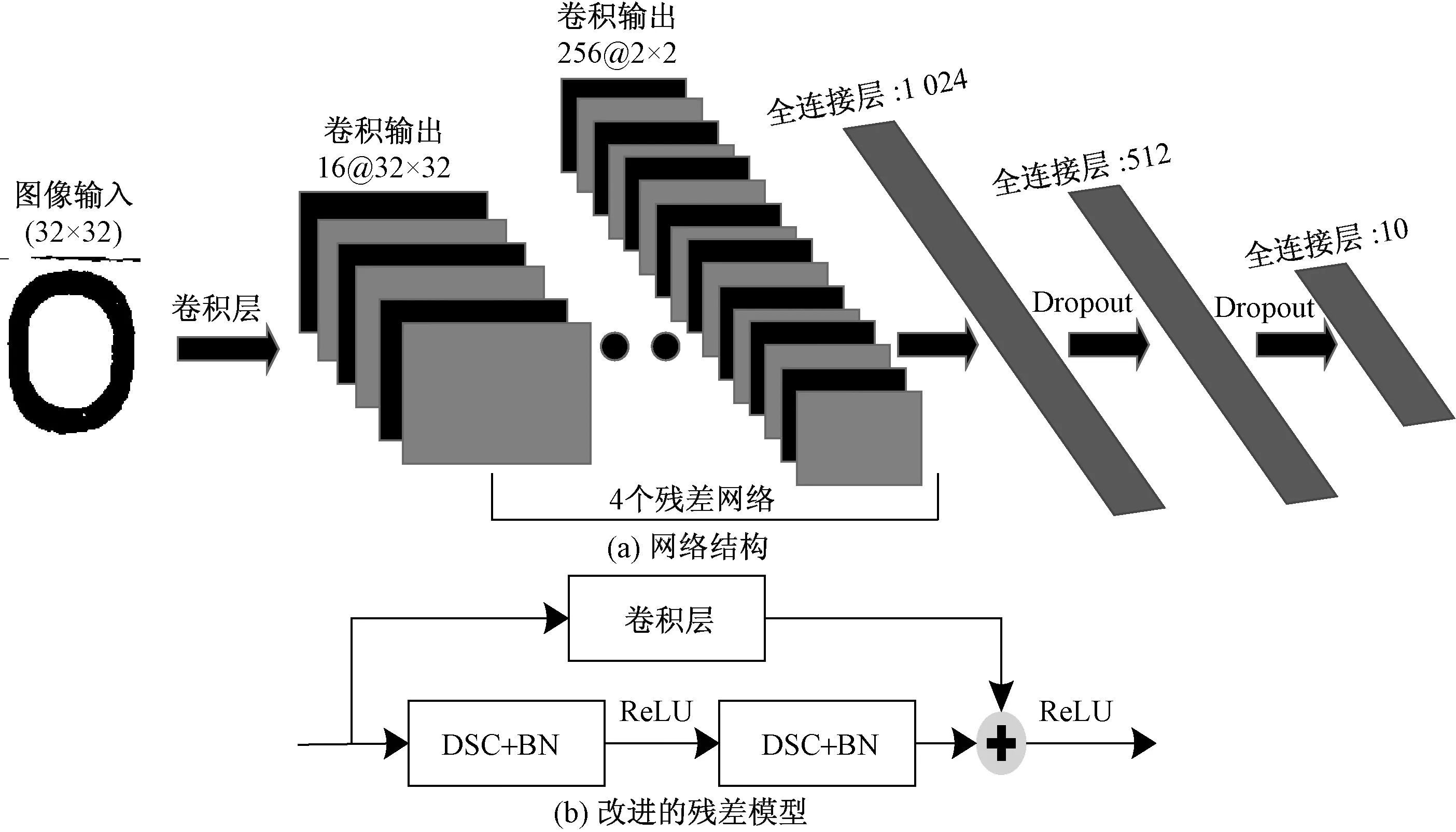
图5 本文网络结构Fig.5 Structure oftext network

X1、X2 、X3 为输入神经元;Z1、Z2、Z3、Z4、Z5为隐层神经元; O1、O2为输出神经元图4 有无Dropout的网络对比Fig.4 Comparison of networks with or without Dropout
从图4中可得,无Dropout函数的网络中,隐层神经元为Z1、Z2、Z3、Z4、Z5。而加入Dropout函数后的网络中,隐层神经元只剩下Z1、Z2、Z4。在实际应用中Dropout函数是随机丢弃网络神经元。因此减弱了网络神经元节点间的联合适应性,增强了泛化能力和鲁棒性,有效地降低过拟合概率。
2.4 算法模型搭建
网络结构如图5所示,其中图5(a)为改进的残差模块结构图。在ResNet-18网络结构基础上,做了以下几点改进:①减少了残差模块数量,只使用了4个残差模块,降低网络的复杂度;②如图5(b)所示,在残差模块中,使用深度可分离卷积替换传统卷积,同时在残差模块的上方分支中添加了一层卷积核尺寸为1×1的卷积层,并且在DSC层后面添加批归一化层(batch normalization,BN),提高网络的运算速度和收敛速度以及泛化能力;③在全连接层之间添加Dropout函数,减少过拟合现象的发生。输入的图像尺寸为32×32,通道数为1;经过卷积层之后,图像尺寸不变,通道数变为16;随后经过4个残差模块,图像尺寸变为2×2,通道数变为256;最后经过3个全连接层以及Dropout函数和softmax函数,输出10个类别的概率,其中概率最大的数字即预测值。
网络模型的主要参数如表1所示。
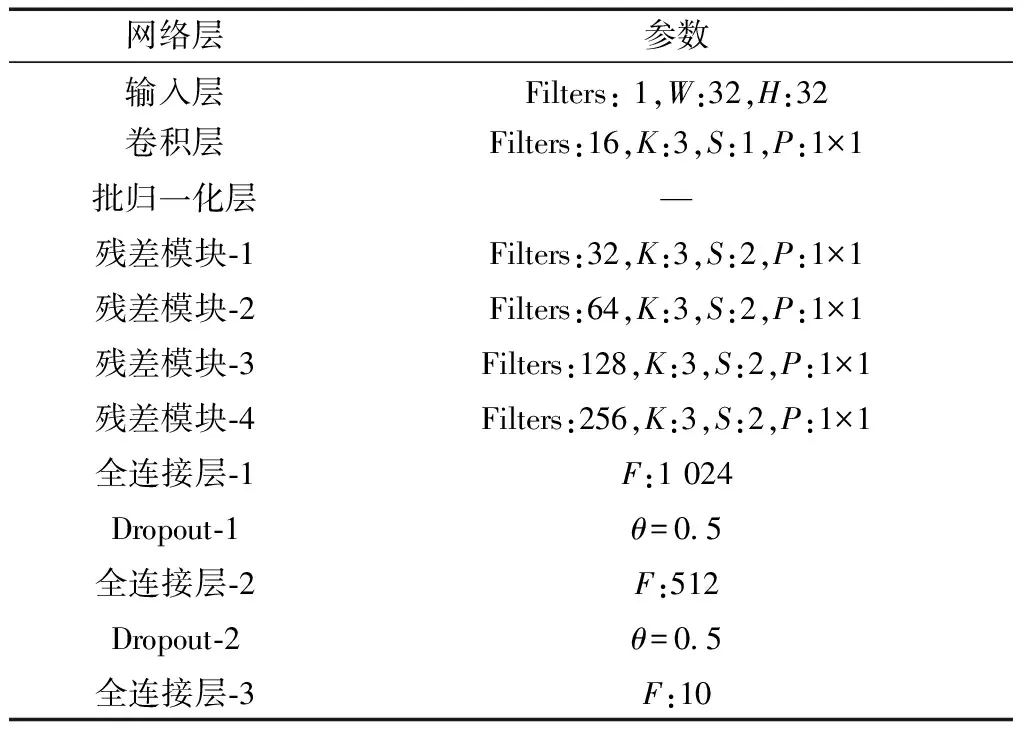
表1 网络模型主要参数
3 实验结果及分析
3.1 实验环境介绍
实验在PaddlePaddle深度学习框架下进行,所用的硬件环境为百度AI Studio平台提供的GPU:Tesla V100 16 GB显存。
数据集是利用OV5640摄像头在模拟字轮式数字水表正常工作的场景下,对数字表盘进行图像采集,总共采集了25 000张表盘图像,数据样本如图6所示。
在对图像经过预处理之后,选用其中15 000张水表字符图像作为数据集,图像大小为32×32,其中完整的字符图像和双半字符图像各占50%。训练集数据和测试集的比例为8∶2,并且训练集和测试集中完整的字符图像与双半字符图像数量各占50%。

图6 数据样本Fig.6 Sample of data
3.2 实验测试与结果
设置网络模型训练轮数为50轮次,学习速率为0.001 2,Dropout函数的参数设置为0.5,每批次训练的图像数量为120张,训练得出的准确率曲线如图7所示。从图7中可以看出,该网络模型具有收敛速度快、精度高、稳定性好等优点。
在训练集和测试集之外,随机选取了200张字轮式数字表盘图像作为验证集,将其输入到本文网络模型中,进行数字表盘字符识别。其识别结果与图像实际数值一致,部分预测结果如图8所示。

图7 准确率Fig.7 Accuracy rate

图8 部分预测结果示例图Fig.8 Some examples of prediction results
3.3 实验分析
3.3.1 图像分辨率分析
为选取输入图像的最优分辨率,表2给出了输入图像的分辨率为32×32、112×112、224×224时,网络模型的字符识别率、参数大小、训练速度以及推理速度。从表2可以看出,当输入图像分辨率为32×32时,网络模型的性能最优。

表2 图像分辨率分析
3.3.2 网络参数分析
为表明深度神经网络中的卷积核大小、Dropout参数值的合理性,表3给出了卷积核大小为3×3、5×5,Dropout参数为0.2、0.5、0.7时表盘字符识别准确率。由表3可以看出,本文网络所选择的3×3卷积核以及Dropout参数为0.5是效果最好的方案。
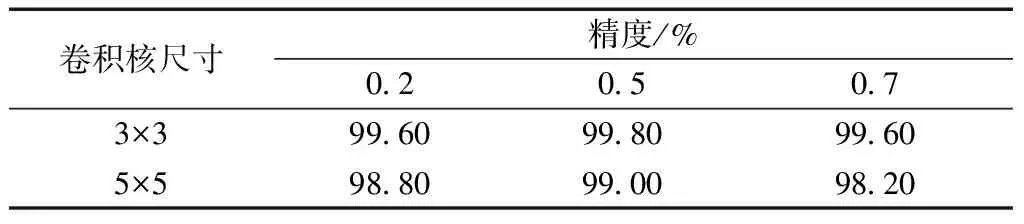
表3 网络参数分析
3.3.3 深度可分离卷积分析
为验证深度可分离卷积在减少网络模型参数量,提高网络模型运算和推理速度方面的优越性,表4给出了使用传统卷积的网络和使用深度可分离卷积的网络在网络参数大小以及训练和推理速度方面的对比。由表4可以看出,深度可分离卷积能有效地减少网络模型参数量,提高网络模型运算和推理速度。

表4 深度可分离卷积分析
3.3.4 训练参数分析
为说明网络模型在训练时所选取的学习速率、迭代次数的合理性,表5给出了网络模型在学习速率为:0. 000 5、0. 001 0、0.001 2、0.001 5、0.002 0,迭代次数为:30次、50次、70次时,表盘字符识别准确率。由表5可以看出,本文网络所选的学习速率和迭代次数能使网络具有最优性能。

表5 训练参数分析
3.3.5 不同网络模型分析
为验证网络模型在识别数字表盘字符方面所拥有的准确率高、模型参数少、训练速度以及推理速度快等方面优点,将本文网络模型与ResNet-18网络模型以及文献[9]中的网络模型进行以上4个方面的对比,其对比结果如表6所示。

表6 不同网络对比结果
从表6的实验结果中可以看出,本文网络在准确率上与ResNet-18网络和文献[9]网络模型相比,有显著的提升。同时本文网络的单张图像运算和推理时间相对于另外2个网络模型而言,均大幅度减小,具有较快的运算和推理速度。最后在网络模型参数方面,本文网络模型的实际参数大小只有7.71 MB,便于部署在轻量级的嵌入式设备中。
4 结论
为提高字轮式表盘中的字符识别率和识别速度、减少模型参数量,提出了一种改进残差网络的字轮式数字表盘识别算法。
(1)该算法在传统的ResNet-18网络基础上,引入深度可分离卷积对残差模块进行优化;同时使用Dropout函数降低网络模型出现过拟合现象的可能性,增强网络模型的鲁棒性。
(2)经过验证对比,本文算法在识别的准确率和速度方面有较大提升,同时模型参数大小也有显著减少;为深度神经网络部署到轻量级的嵌入式设备提供了可能,同时为实际的工程应用打下了基础,具有良好的实用前景。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2020年10期)2020-11-14
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年13期)2020-01-14
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
自动化学报(2019年6期)2019-07-23
电子制作(2019年11期)2019-07-04
