
智能移动终端涉密信息监测系统
2022-03-24 04:00王本钰顾益军彭舒凡
科学技术与工程 2022年6期
王本钰, 顾益军,2*, 彭舒凡
(1.中国人民公安大学信息网络安全学院, 北京 102600; 2.安全防范技术与风险评估公安部重点实验室, 北京 102600)
信息时代,信息资源成了推动社会进步最重要的元素之一,信息资源的价值也越来越高,但随着技术的更新换代,涉密信息通过智能移动终端流出的可能性不断上升。
涉密信息[1]通常是指政府、科技、军队、公安等领域的绝密文件或者保密设施的信息及内容等,或者是企业单位的商业保密文件的信息内容等。为了防止涉密信息被泄露,相关部门通常会建立一套专门用于处理涉密业务、与互联网进行隔离的涉密办公网或者是在主机上安装涉密信息监测系统来防止涉密文件内部的泄露。徐建文[2]利用光学字符识别技术(optical character recognition ,OCR)技术设计实现了主机中电子文档的涉密信息监测系统。武越等[3]利用关键词字典、文件指纹、机器学习模型生成涉密数据特征,再通过监控网关对数据进行解析和检测实现了局域网中涉密信息监测系统。这些系统对于局域网中电子文档具有很好的监测效果,可以防止涉密信息的泄露。然而目前由于手机、平板电脑等智能移动终端的快捷性、便携性,使得涉密单位工作人员可以轻松偷拍涉密信息或者通过聊天软件上传涉密图片而不被察觉,如利用手机拍取文件材料、武器编号、重大会议等。因此如何有效地防止智能移动终端泄密事件的发生已经变得尤为重要。
近年来,光学字符识别(OCR)[4]由于其高效、便捷的特性已经被用于多个领域的图像文字识别当中去[5-7]。因此,在充分了解当前涉密单位对于涉密信息保护存在的漏洞后,现结合涉密单位的实际需求和应用场景,利用OCR技术实现一个智能移动终端涉密信息泄露监测系统。
传统OCR技术的核心步骤是特征提取[8],找出图像中候选的文字区域的特征,以此来实现文字识别。但是这种方法不仅耗时耗力,而且识别准确率低。目前,随着深度学习技术的不断发展,在计算机视觉领域都通过深度学习方法来实现OCR技术,得到的文字识别准确率高,效果非常好。虽然在OCR的研究领域里,基于深度学习的方法经常被用来解决自然场景中的复杂问题[9-10],但是很少关注真实文本背景下的文字识别,因此在真实背景干扰下的文本检测和文字识别效果不理想。针对上述问题,现合成具有真实背景干扰下的字符数据集,预处理真实背景纹理素材,合成仿真数据集,增加了识别算法的泛化效果。同时提出基于CTPN[11]+Tesseract-OCR[12]的复杂背景下的文字检测与识别方法:CTPN算法在文本检测方面具有较高的准确率,将搜集的数据集与真实场景的数据集结合,继续扩充检测训练集的丰富性,再对检测模型进行训练。使用合成的真实场景字符库对Tesseract-OCR字符识别引擎进行训练,降低部分字符因背景干扰引起的识别错误率。
1 系统设计
1.1 系统介绍
传统的涉密信息监测系统往往都是安装在电脑等终端中,仅仅只能防止涉密文件在电脑等终端中不被泄露。然而当前智能移动终端普及率高,办公便捷但保密形势严峻,一些办公人员及与涉密文件有直接接触人员的保密意识不强,通过移动终端相机拍摄涉密文件在社交软件中恣意进行传播,甚至存在通过终端拍摄涉密文件卖给他国的违法行为,造成重要秘密泄露乃至国家根本利益受损。基于此背景,涉密信息泄露报警系统应运而生。该系统的核心问题是为了减少手机等智能移动终端泄密事件的发生,在监测到使用者通过智能移动终端拍摄包含涉密信息的照片或者通过聊天软件拍摄或者上传涉密图片时进行警告并自动删除。该系统一方面是对涉密单位的信息进行保护,防止工作人员有意泄露涉密信息的行为发生;另一方面对于工作人员无意间泄露涉密信息的行为进行及时的补救和提醒。这款系统基于Java语言,利用全局和局部相结合、检索和识别分步走的模式,适用于各种版本的Android设备,由数字图像处理系统模块、文本图像检测系统模块、涉密敏感词匹配系统模块3个模块组成。它实现了针对智能移动终端上的涉密信息的实时保护功能,有效地防止通过智能移动终端涉密信息泄露事件的发生,填补了当前涉密单位对于智能移动终端管控的空白。该系统主要实现以下3个功能。
(1)全局扫描功能:管理员可以自定义设置涉密敏感词,并以此为依据搜索智能移动终端中的涉及此关键字的所有敏感信息。
(2)实时相机监察功能:对于相机实施实时监控,捕捉使用者使用相机操作的动作,对使用者拍取包含涉密敏感词的图片进行删除并警告。
(3)社交管控功能:可以实现对当前主流的聊天工具(QQ、微信)实时监控功能,实时扫描聊天记录中是否含有涉及涉密敏感词的图片。
1.2 整体架构
该系统设计了数字图像处理系统模块、文本图像检测系统模块、涉密敏感词匹配系统模块这3个模块,该系统结构图如图1所示。

图1 系统结构图Fig.1 System architecture diagram
在整个系统实现过程中,管理者可以自定义设置涉密敏感词,并以此为依据搜索智能移动终端中涉及此涉密敏感词的所有信息,具有极强的可拓展性,可根据涉密单位不同需要进行功能扩充,来适应不同的工作环境。在数字图像处理系统模块中实现对智能移动终端拍摄的图片或者本地存储的图片进行数字化处理的功能;在文本图像检测系统模块中实现文本检测的功能;涉密敏感词匹配系统模块根据管理员录入的涉密敏感词生成涉密敏感字库与图片文本进行匹配,匹配成功即警告。该系统能够自动对比识别,具有实用性和实时性。在该系统运行条件下,系统将对移动终端画面、应用后台进行实时监控,实现全局扫描、实时相机监察和社交管控功能。
2 系统功能模块
2.1 数字图像处理系统模块
数字图像处理[13]系统模块是该系统中不可或缺的一个部分,由于图像在获取时容易因为环境亮度的明暗、是否是正面拍摄、文字资料的印刷是否清晰等因素而影响系统后续的工作,因此需要通过数字图像处理技术将原本不符合要求的图像转化为可以进行下一步操作的图像。数字图像处理系统模块将Android系统相机、聊天软件、图库获取的图像结合Android NDK技术和JNI接口进行数字图像处理。数字图像处理系统模块流程图如图2所示,包含灰度化处理、二值化[14]、图像降噪[15]、倾斜校正[16]和图像插值[17]等操作。
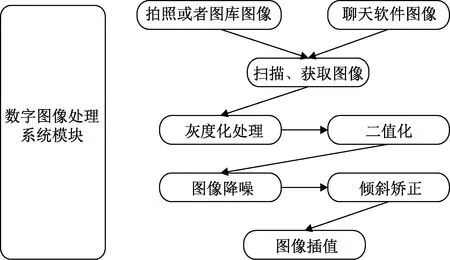
图2 数字图像处理系统模块流程图Fig.2 Flow chart of digital image processing system module
第一步,对所获得图像进行灰度化处理,将含有R、G、B三原色的原始图像变为只含有黑白点的处理后的图像。

(1)
式(1)中:v为灰度值;R′、G′、B′为灰度处理后的值,减少文本图像检测系统模块的计算量。
第二步,采用阈值法对图像进行二值化,将图像上的像素点的灰度值设置成0或255。

(2)
式(2)中:threshold为阈值。
第三步,采用高斯滤波对图像进行降噪操作,消除在图像采集过程中环境、亮度、文本资料等因素对于图像清晰度的影响。

(3)
式(13)中:(x,y)为图片中点坐标;σ为标准差。
第四步,利用霍夫变换对图片进行倾斜校正操作,解决实际拍摄过程中无法获得正面图像或者图像倾斜的问题。
b=-x×k+y
(4)
式(4)中:(x,y)为图片中点坐标;k、b为图片中直线参数。由于k、b是相对固定,因此可以在霍夫空间中得到多条汇聚于该点的直线,选择统计峰值最高的直线就可以完成图像的倾斜校正工作。
第五步,对图像进行插值操作,采用最近邻插值法使低分辨率图像变为高分辨率图像。即对于灰度值未知的插值点(x,y),如果(x,y)在灰度值已知的坐标点(x0,y0)的邻域内,则(x,y)的灰度值为(x0,y0)的灰度值。
2.2 文本图像检测系统模块
文本检测和文本识别是OCR系统的核心内容。文本检测更是OCR系统进行文本识别的先提条件。文本检测任务可以看作是特殊的目标检测,但是由于文本边界难以确定、文本行长度不固定、文本具有序列特征等特点,文本检测又不同于通常的目标检测。因此目标检测的通用方法并不适用于文本检测。传统的文本检测方法也没有考虑到上下文关系,是先将单个字符检测出来后再连接起来,这样导致文本检测的准确率十分低下。基于此类问题,欧洲计算机视觉会议(European conference on computer vision, ECCV)上提出了CTPN算法。CTPN算法首先采用CNN卷积神经网络用于特征提取,之后选取固定宽度的anchor检测小尺度的文本候选框,并将同一行anchor的特征串成序列输入双向长短期记忆神经网络中,接下来采用全连接层进行分类,并通过Side-refinement[18]算法过滤多余的文本框,最后通过文本线构造算法将一系列小尺度的文本框合成文本线。CTPN算法的具体实现步骤如下。
(1)在CNN部分选取VGG-16网络进行特征提取,得到大小为N×C×H×W的conv5特征图(N为特征图的数量,C为通道数,H为图片的高度,W为图片的宽度)。
(2)在conv5特征图上滑动3×3的窗口学习空间特征,输出大小为N×9C×H×W的特征图。
(3)将大小为N×9C×H×W的特征图reshape成(N×H)×W×9C的特征图。
(4)将每一行的特征向量输入到输入BILSTM中,学习每一行的序列特征,输出大小为(N×H)×W×256的特征,再经过一次reshape恢复形状,得到大小为N×256×H×W的特征。
(5)连接一个全连接层,经过类似于Faster R-CNN[19]的RPN网络,获得文本框。
(6)采用Side-refinement算法过滤多余的文本框。
(7)通过文本线构造算法将一系列小尺度的文本框合成文本线。
该系统选用CTPN文本检测算法来进行文本检测工作,所使用的文本图像检测系统模块流程图如图3所示,包含CTPN算法模型训练和CTPN算法文本检测两个部分组成。
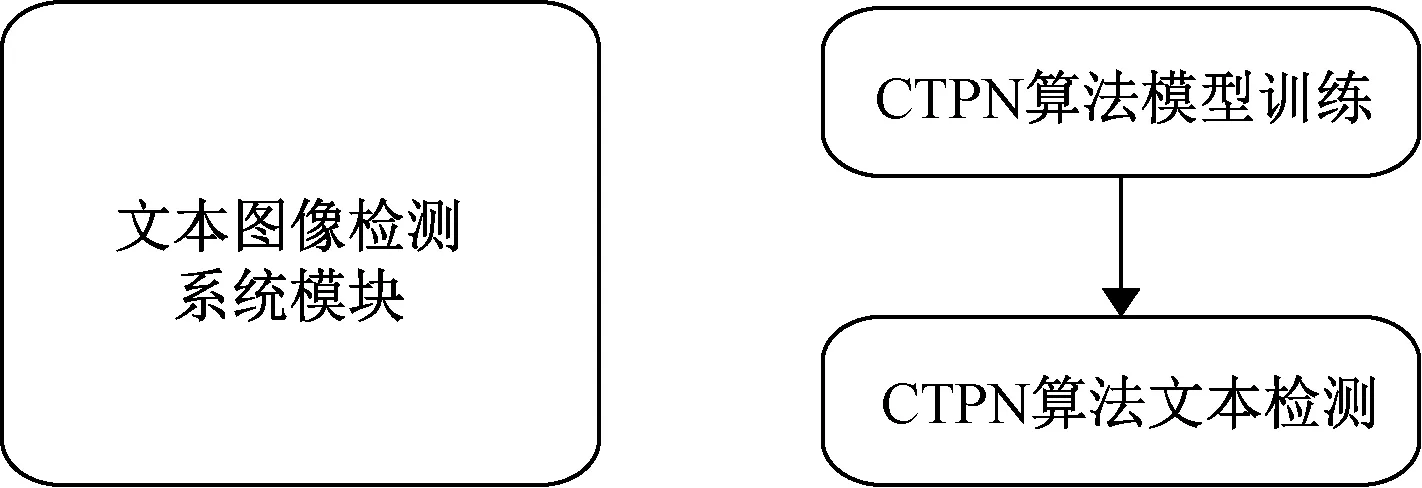
图3 文本图像检测系统模块流程图Fig.3 Module flow chart of text image detection system
CTPN算法是针对复杂场景的文本检测算法,具有泛化效果,但是在实际测试过程中,发现对于该系统所应用的特殊场景并不具备很好的文本检测效果,因此需要收集相应场景的图片对CTPN模型进行再训练,提高文本检测的准确率。本文模拟真实情境下通过智能移动终端拍摄文件材料、武器装备、会议场景,收集了5 421张图片并组成训练数据集。收集训练数据集样图如图4所示。

图4 CTPN训练数据集样图Fig.4 Sample map of CTPN training data set
在获取训练数据集后,需要对训练数据集中的图像进行标注,标注图像的时候采用的是顺时针方向标注,分别标注左上角坐标点,右上角坐标点,右下角坐标点,左下角坐标点,生成相应的xml文件。之后将标注好的文件数据输入到模型中,进行训练。运用CTPN算法和本文收集的训练数据集,即可训练出可应用于该系统所需的特殊场景的文本检测模型。

图5 敏感词匹配系统模块流程图Fig.5 Flow chart of the sensitive word matching system module
2.3 敏感词匹配系统模块
敏感词匹配系统模块主要由两个部分组成,分别是Tesseract-OCR字符识别引擎和LCS文本比对算法组成,系统模块流程图如图5所示。由于在实际测试过程中,将Tesseract-OCR字符识别引擎直接用作本文所需场景的图片识别时取得的效果非常差,因此该系统利用Tesseract-OCR中自带的字符训练工具结合本文设计实现的模拟真实场景字符库进行再训练,提高字符识别的准确率。在LCS文本比对算法中,该系统利用LCS算法对管理员输入的涉密敏感词和Tesseract-OCR识别的字符文本进行比对,匹配成功则警告并且删除图片。
2.3.1 Tesseract-OCR开源字符识别引擎
Tesseract-OCR是一款由HP公司于1985年研发成功的开源字符识别引擎,后来被Google公司接收进行不断的升级和优化。Tesseract-OCR可以用于多种语言文字的字符识别,对于英文字符和数字的识别准确率较高。Tesseract-OCR同时自带了一个基于LSTM长短期记忆网络的字符训练工具,可以高效地实现文字的特征提取和分类工作。
Tesseract-OCR的核心内容主要分为3个方面,分别是文本轮廓分析、文本字符定位和分割、文字识别。Tesseract-OCR采取嵌套的轮廓搜索算法来实现文本轮廓分析部分,将分析得到的文本轮廓组成文本块,之后将对文本块进行行列切分,最后将文本块切割成单个字符再逐个识别。
将Tesseract-OCR字符识别引擎直接用于本文所需场景的图片识别,但是所取得的识别效果非常差。分析原因,一方面是Tesseract-OCR采取的文本字符定位和分割算法不适用于复杂场景的文本检测工作,文本检测效果较差;另一方面,由于该系统应用场景的字符字体具有多样性、文本背景干扰因素多等原因,所以Tesseract-OCR自带的chi_sim.traindata字库的字符识别效果欠佳。因此,针对上述两个问题,本文尝试利用训练好的CTPN算法进行文本检测工作,取得的效果明显优于Tesseract-OCR文本检测效果。同时为了解决字符识别准确率低的问题,现结合真实应用场景下的字符种类、背景干扰等因素设计实现了模拟真实场景字符库,并通过Tesseract-OCR自带的基于LSTM长短期记忆网络的字符训练工具进行再训练,对于复杂场景下的字符识别取得了不错的效果。
目前中文字符的国家标准GB2312—80中收录了10个阿拉伯数字,52个大小英语字符,6 763个中文字符,合计共有6 825个基础字符。首先利用GB2312—80所收集的6 825个基础字符建立含有6 825标签类的基础字符库。然后选取文本材料、武器装备、会议等涉密场景最常用的仿宋体、黑体、楷体和Times New Roman 4种字体风格对基础字符库进行扩展,使得每个字体得到4张不同风格的字符图片。之后将真实背景纹理素材和每个字符图片合成得到模拟真实场景字符库。通过对比发现模拟真实场景字符效果非常接近真实场景下的字符效果,保留了真实场景下的字符背景干扰,具有很强的真实性、可信性和可行性。Tesseract-OCR模拟真实场景字符库如图6所示。
在得到模拟真实场景字符库后,需要利用Tesseract-OCR自带的字符训练工具对字符库进行训练,提高字符识别的准确率以满足该系统应用场景的需求。Tesseract-OCR字符库训练流程如图7所示。

图6 Tesseract-OCR模拟真实场景字符库Fig.6 Tesseract-OCR simulation of real-life scenarios character library
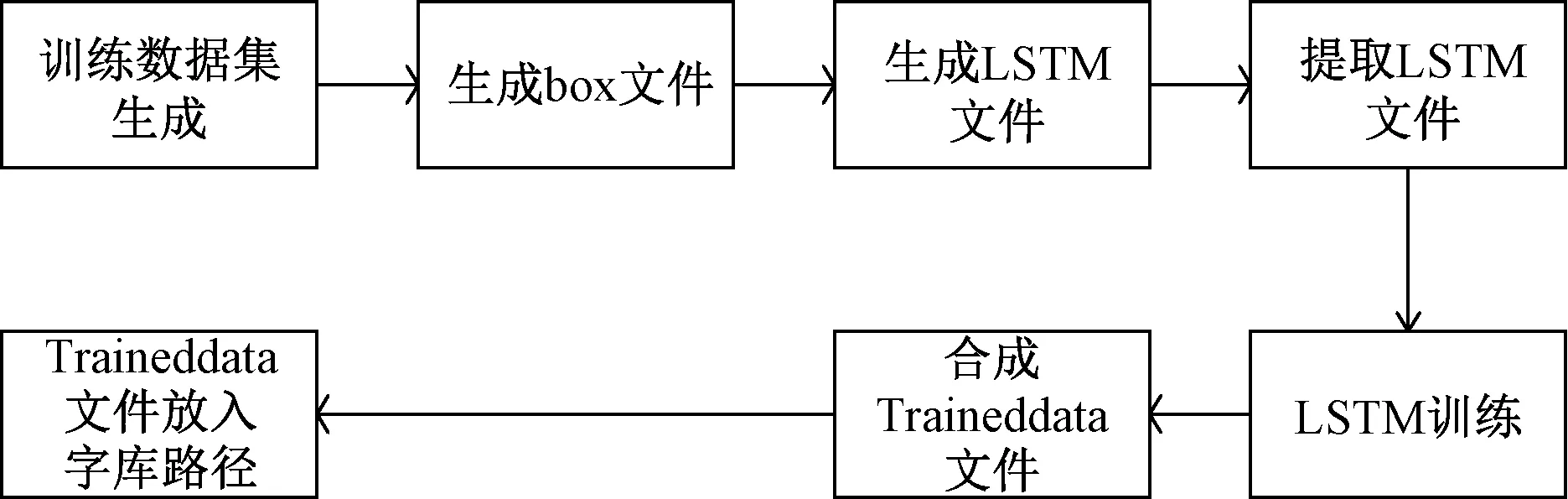
图7 Tesseract字符库训练流程图Fig.7 Tesseract character library training flowchart
2.3.2 LCS文本比对算法
当通过Tesseract-OCR字符识别引擎识别图片文字信息后,该系统通过LCS算法[20]来实现敏感词和图片文本这两个文本之间的比对工作。LCS算法是采用动态规划的方法来求解两个字符串之间的最长公共子串长度。
LCS算法用c[i,j]记录序列Xi和Yj的最长公共子序列的长度。其中Xi=
c[i,j]=
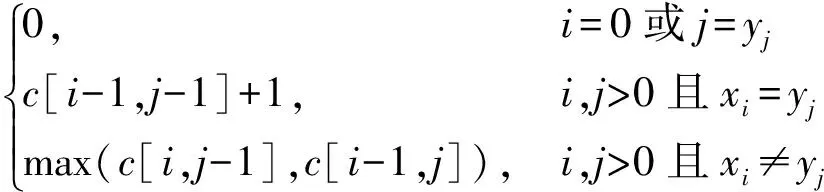
(5)
设用户自定义输入的敏感词为A,系统识别图片中的文本信息为B,显然当c[A,B]=Len(A)时,其中Len(A)表示敏感词A的长度该系统识别图片中的文本信息含有涉密敏感词,判定为涉密照片,应对图片进行删除操作。
3 系统测试
3.1 测试环境
为保证测试结果真实可信、具有参照性,测试数据对安卓基带内核版本不同、安全补丁不一的各类原型机都具有可信度,因此对智能移动终端涉密信息监测系统的测试分为虚拟大环境广度测试与实际机型对照测试。
(1)虚拟环境测试平台:在Android studio3.0.1环境搭建下,使用到Intel HAXM引擎,调用X86架构的安卓虚拟机,启用安卓虚拟设备(android virtual device,AVD),创建Android EM ulator-5.1_WVGA和Android Emulator-4.1_WVGA进行虚拟环境平台下的普遍性测试。
(2)实际机型对照测试:为了规避由各生产商进行的操作系统定制开发,而造成的权限获取失败、文件指针指向错误等不确定因素,采取多机型、多品牌、多系统的测试环境,以华为荣耀系列20、30、X10,努比亚Z17S进行对照测试。
3.2 不同场景的图像文本识别测试
在不同场景的图像文本识别测试中,使用该系统扫描识别各类复杂场景下的图片,测试该系统对于不同背景、不规范字体条件下的字符识别率。测试中使用不同测试环境对不同测试类型的图片分别测试200次之后取平均值。测试结果如表1所示,由测试结果可知,该系统可以有效识别各类复杂场景下含有文字信息的不规则图像,且文字信息识别率均在较高水平。

表1 不同场景的图像文本识别结果
3.3 社交软件涉密敏感词捕捉测试
在社交软件涉密敏感词捕捉测试中,对时下常用聊天交友工具实施监测。测试内容是对“交友”过程中发送或接收涉密敏感词图像的行为经泄密判定算法判定后,该系统成功警告并删除图片的概率,即敏感信息捕捉比率。测试中使用不同测试环境分别对腾讯QQ、微信两款聊天交友软件进行测试,计发图片次数各为1 000次,统计每次识别结果。测试结果如表2所示,结果显示在交友软件中发送涉密图片,该系统成功捕捉概率较高,并且在测试中微信端监测效果要好于QQ端。

表2 社交软件中敏感涉密词捕捉结果
3.4 系统性能指标测试
在系统性能测试中,启动系统全局扫描功能,记录扫描所有本地的图像素材的总共用时,重复上述步骤1 000次,同时查看终端实时CPU占用率,以每秒记录一次,每次实验取100组有效取值。计算单张照片识别平均时延,与常态终端CPU占用率。之后切换系统界面,进入其他软件界面,进行日常办公娱乐操作,观察后台运行该系统是否对手机运行各类软件流畅度有影响,检查机身发热情况。测试结果如表3所示,由测试结果可知,该系统内存占用小,识别效率高,且不会给手机终端造成负担,没有出现发热、卡顿等情况,运行稳定,可以满足日常工作需求。

表3 系统性能指标测试结果

图8 终端UI界面Fig.8 Entry of sensitive words and activation methods
4 系统实现
智能移动终端涉密信息监测系统终端UI界面如图8所示,该系统基本功能展示如图9~图12所示,所有展示以华为荣耀X10为演示对象。
录入敏感词及启动方式:打开系统,在此系统中,左边功能键是可以扫描本地的所有图片信息,查找手机等智能移动终端中是否含有涉密敏感词的图片,右边功能键为录入涉密敏感词库,可以依据涉密单位的实际需求录入相关的涉密敏感词,录入涉密敏感词后,打开系统进行涉密信息监测,功能实现如图9所示。
全局扫描功能:打开检测后,该系统会开启全局扫描功能,后台扫描图库中的图像信息,并判定是否含有涉及涉密敏感词的图像信息,如果发现含有涉密敏感词信息的图像,该系统便发出警告,并删除涉及涉密敏感词信息的图像,如图10所示。

图9 录入敏感词及启动方式Fig.9 Entry of sensitive words and activation methods
实时相机监察功能:当使用相机拍摄含有涉密敏感词的文件图像时,该系统会对拍摄的图像进行识别判定,确定为含有涉密敏感词图像时,该系统会警告提示,并删除图像信息,如图11所示。
社交管控功能:该系统可以后台实时监控社交软件,实现社交管控功能,捕获用户的浏览、保存、发送涉密图像等动作。以主要的聊天程序微信为例,当聊天时发送了涉及涉密敏感词的图片时,该系统就会发出警告提示,并删除本地浏览图片缩略图,如图12所示。
5 结论
智能移动终端涉密信息监测系统采用成熟的OCR技术原理,性能稳定,可靠性强。在数字图像处理方面采用了灰度化处理、二值化、降噪、倾斜矫正、插值处理,为后续OCR系统的实现奠定了良好的基础。在文本检测方面,采用CTPN算法进行文本检测工作,利用真实涉密场景收集的图片对于CTPN模型进行再训练,提高CTPN模型对于复杂场景下的文本检测准确率。在涉密敏感词匹配方面,采用Tesseract-OCR字符识别引擎对复杂背景下的文本进行端到端的识别,使用合成的真实场景下的数据集对Tesseract-OCR进行训练,解决了部分字符因背景干扰而识别错误的现象,提高了字符识别准确率。利用LCS算法进行文本比对,算法耗时低,满足快速比对的需求。智能移动终端涉密信息监测系统以全局扫描,实时相机监察,社交管控三大功能为立足点,防护于源头,服务于岗位。通过数字图像处理系统模块、文本图像检测系统模块、涉密敏感词匹配系统模块3个系统模块,实现了对智能终端“涉密敏感信息”的识别清除,对终端的涉密信息做到实时全面监控清查。通过该类监测手段可保护涉密内容特别是对“红头机密文件”办公领域等有重大的保护作用及意义,且对目前网络新兴的“图片谣言”等舆论监察有着极大的应用前景,可为特殊岗位人员定制集成于系统应用之中移动终端。该软件具有操作方便、简约高效、针对性强、拓展性好、可靠性高。等特点,能够极大地保护信息安全,减少失泄密事件的发生,推广应用前景十分广阔,符合当前中国特殊行业的需求。

图10 全局扫描功能Fig.10 Global scan function

图11 实时相机监察功能Fig.11 Live camera monitoring function

图12 社交管控功能Fig.12 Social control functions
猜你喜欢
现代装饰(2020年8期)2020-08-24
汉字汉语研究(2020年2期)2020-08-13
小学生学习指导(低年级)(2019年12期)2019-12-04
铁道通信信号(2019年9期)2019-11-25
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
铁道通信信号(2018年4期)2018-06-06
现代电子技术(2016年22期)2016-12-26
软件导刊(2016年11期)2016-12-22
科学与财富(2016年28期)2016-10-14
