
基于随机森林与长短期记忆网络的电力负荷预测方法
2022-03-22 06:36董彦军王晓甜马红明王立斌李梦宇岳凡丁袁欢
智能电网 2022年2期
董彦军,王晓甜,马红明,王立斌,李梦宇,岳凡丁,袁欢*
(1.国网河北省电力有限公司,河北省 石家庄市 050081;2.国网河北省电力有限公司营销服务中心,河北省 石家庄市 050081;3.西安交通大学电气工程学院,陕西省 西安市 710049)
0 引言
电力系统以向各用户提供达到质量标准的电能为主要任务,以满足社会各类负荷的用电需求,其稳定运行需要实时动态平衡发电量与负荷变化。然而当前电能的大量存储难以实现,负荷波动具有明显的非线性及随机性[1],因此需要对电力负荷进行准确预测,从而合理分配用电负荷,保证电网经济稳定运行[2]。
非线性和时序性是电力负荷的两大特点[3]。对于电力系统负荷的预测,国内外研究方法主要分为两类:传统方法与新型人工智能方法[4]。传统方法以时间序列法为代表,如傅里叶展开法[5]、多元线性回归法[6]等。这些方法具有充分考虑电力负荷数据的时序性、计算速度快等优点,然而其数据回归能力较弱,且要求数据时间序列具有较好的平稳性,因此无法对具有非线性关系的数据进行准确预测。新型人工智能方法则能够较好地拟合非线性数据,文献[7-8]使用较为普遍的反向传播(back propagation, BP)神经网络进行负荷预测,但BP神经网络的学习能力相对较差,预测精度有待提高。文献[9-10]使用了模糊推理法,但该方法的计算速度过慢且精度较低。文献[11-12]使用了支持向量回归(support vector regression,SVR)算法预测负荷。文献[13]通过决策树进行预测。然而这些算法都没有考虑电力负荷的时序性,在预测中需要人为添加时间特征才能在一定程度上保证预测的精度。长短期记忆网络(long short-term memory,LSTM)兼顾了数据的时序性和非线性,训练时间短且预测精度高,因此被广泛应用于电力负荷的预测。
此外,随着电力大数据的发展及能源互联网的建设不断深入,海量的电力数据为负荷预测提供了坚实基础。电力负荷受时间、日期及天气等众多因素影响,但在负荷预测的特征集之中,并非特征因素越多预测精度就越高,过多的特征量会增加预测模型的复杂度,降低预测精度。目前关于负荷预测的研究大多未对特征因素进行筛选,或仅采用主观选择的方式确定预测特征集中的特征因素,而对特征因素的选择会直接影响预测结果。因此,为了避免特征量过多及人为主观筛选特征量对负荷预测精度造成的不利影响,需要通过科学合理的方法对特征量进行筛选。随机森林(random forest, RF)算法作为一种鲁棒性高、学习能力强的智能分类算法,具备度量变量重要性的能力,能够分析复杂且相互作用的特征,因此被广泛应用于高维度数据特征的选择。为实现电力负荷的准确预测,本文提出一种基于随机森林算法和长短期记忆网络的混合模型负荷预测方法,即RF-LSTM混合模型。该模型结合了随机森林和LSTM各自的特点,先将天气因素、日期因素等高维特征集输入随机森林模型进行重要性评估,筛选出重要特征变量后输入LSTM预测模型进行负荷预测,从而兼顾负荷数据的非线性和时序性,提高负荷预测精度[14-16]。结合河北电网某台区的实际数据,利用该混合模型进行负荷预测,结果表明,本文提出的模型可以有效提高负荷预测的精度,降低预测误差。
1 电力负荷预测特征集
特征集对模型的预测结果有着决定性的影响,高精度的负荷预测结果要以合理的特征集作为前提。影响电力负荷的特征因素非常多,就目前研究分析结果来看,主要的影响因素除历史负荷外还有时间日期因素、气候因素等[17]。然而模型预测精度并非绝对与特征因素数量呈正相关,模型输入的特征量维数过多时易造成模型结构复杂,甚至降低预测精度。因此本文提出在对负荷正式预测前先对高维特征量进行筛选。首先构建高维特征集从而为后续筛选特征量提供充足的备选,具体如下。
1)时间日期因素:节假日、双休日及时刻等时间因素对电力负荷的影响较大,因此构建包含月、日、是否为节假日、是否为工作日、周日期、当日的具体小时共6维时间日期特征。
2)气候因素:不同的温度、湿度和天气对于电力负荷均有一定影响。考虑气候因素,构建包含风力、湿度、当日最低温度、当日最高温度、露点温度、天气类型、空气质量、日照时数共8维气候特征。
本文构建的包括时间日期因素、气候因素在内共14维特征向量如表1所示,为后续特征向量筛选提供特征集。
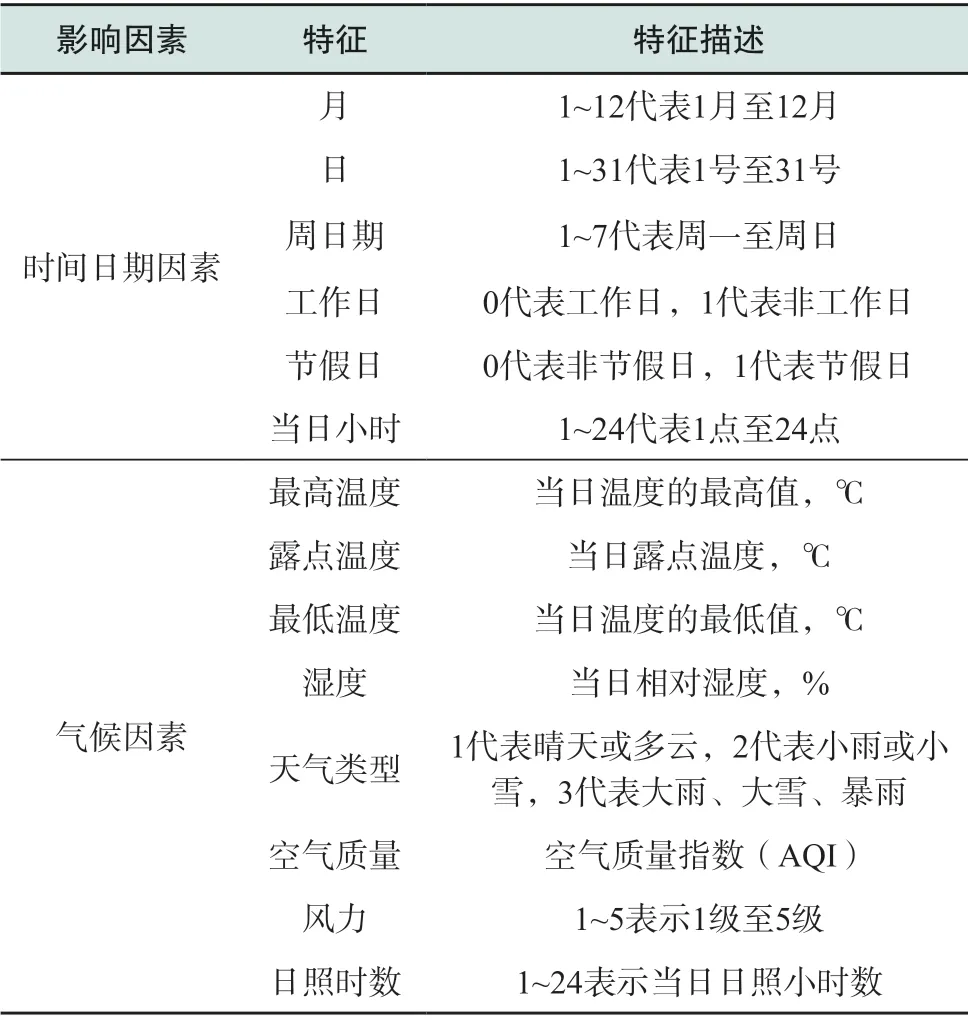
表1 预测特征集Table 1 Feature set of prediction data
2 RF-LSTM混合模型
2.1 随机森林分类原理
随机森林算法是对传统决策树的继承和改进,能够分析复杂且相互作用的特征,在处理存在缺失值的数据时学习速度较快并具有较高的鲁棒性。此外,随机森林算法中的变量重要性度量作为其重要特点可以用于高维度数据特征的选择,近年来在分类、特征选择等问题中得到了广泛的应用。本文采用的随机森林算法本质上是包含多个分类回归树的组合分类器,利用随机重采样(bootstrap)技术和节点随机分裂技术构建了若干决策树,在随机重采样的过程中,部分未被选中的样本被称为袋外(out of bag, OOB)数据。使用OOB数据对随机森林模型进行评估可得到OOB误差,本研究通过分析OOB误差从而得到各特征变量的重要性,其原理可理解为:当OOB数据自变量发生轻微扰动时,OOB误差增加幅度越大则该变量越重要。因此,OOB误差可以用于定量评价特征变量的重要性,进而对高维特征数据进行选择[18-20]。
随机森林算法选择变量的流程(伪代码)如下。
1)假设随机森林算法中共有k棵树,各特征变量分别为x1,x2,…,xn, fori =1:k
①针对其中的每棵树都通过随机重采样从数据集N中有放回地随机抽取一定规模的数据作为样本,构成样本训练子集Ni,未被抽取的数据则构成b个OOB数据。
②在Ni中重复步骤a—c,每次循环中使决策树按最大限度生长,不对其剪枝,得到决策树Ti。
a)假设共输入M个特征属性,随机抽取其中的m个属性作为当前决策树分裂的属性集。
b)从m个特征变量中选择最佳的变量j和切分点s得到θi(j,s)。
c)将该节点按照θi(j,s)切分成2个子节点。
end for
2)生成k棵决策树构成随机森林时,对每棵决策树Ti对应的b个OOB数据进行投票,从而获得OOB数据中每个样本的投票分数为

3)随机改变OOB数据样本中各特征变量xi的数值从而生成新的OOB数据测试样本,并通过随机森林对新OOB数据投票,得到
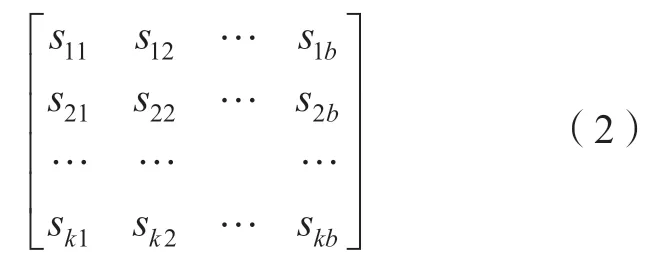
4)求特征变量xi的重要性评分
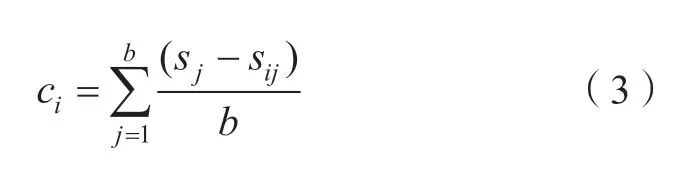
式中:sj和sij分别表示变量改变前后第i棵树的OOB误差率;ci代表各特征向量对于分类过程的贡献大小,可以衡量各特征的独立分类能力,因此有助于在分类过程中确定各特征的重要性,为选择特征提供依据。随机森林算法模型流程如图1所示。
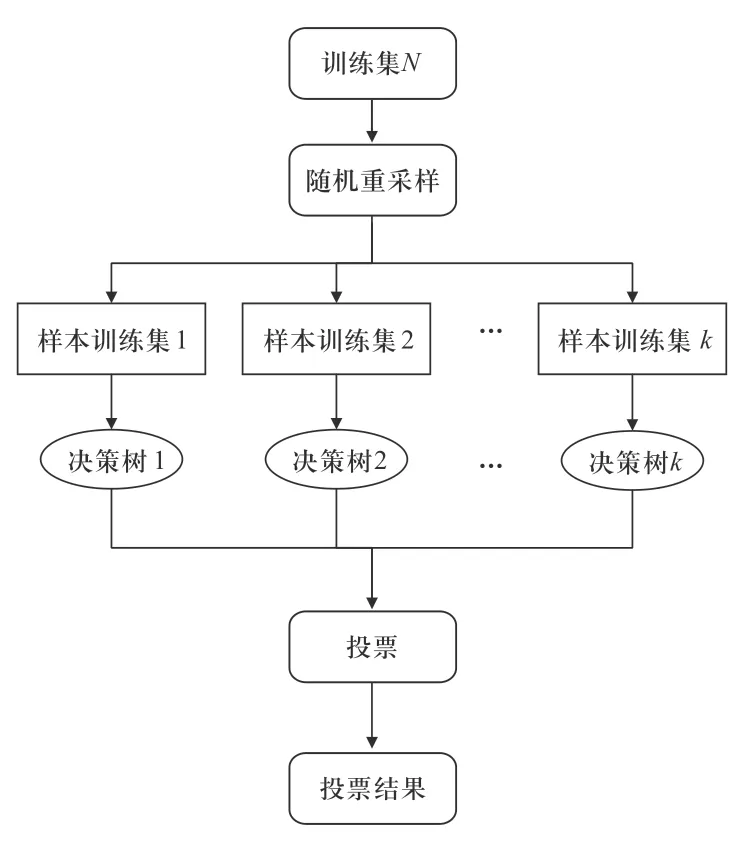
图1 随机森林算法流程图Fig.1 Flow chart of random forest algorithm
2.2 LSTM预测模型
LSTM作为循环神经网络(recurrent neural network, RNN)的继承和发展,经Graves[21]改进后,解决了RNN模型在训练过程中经常出现的问题——梯度消亡。此外,面对时序性及非线性较强的电力负荷数据时,LSTM能够很好地掌握时间序列所依赖的信息,因此在负荷预测领域得到了很好的应用和发展[22-23]。LSTM基本单元模型如图2所示。
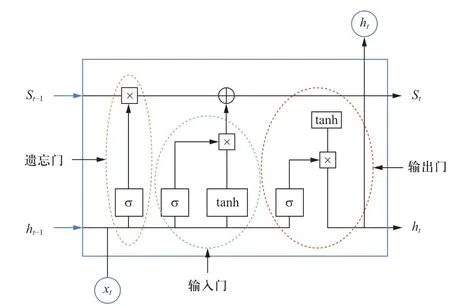
图2 LSTM模型图Fig.2 Diagram of LSTM model
一个LSTM单元由输入门、遗忘门、输出门和记忆单元构成,其核心记忆单元用于描述该单元当前的状态[24]。模型中的3个控制门分别与乘法单元连接,实现对该单元的输入、记忆单元和输出的控制。记忆单元的遗忘部分由记忆单元St、遗忘门的输入xt以及中间输出ht-1共同决定,记忆单元的保留向量则由输入门中的xt分别经过tanh函数和sigmoid函数变换后的结果共同决定,更新过后的St和输出ot共同决定中间输出ht,其计算公式如式(5)—式(10)所示[25]。
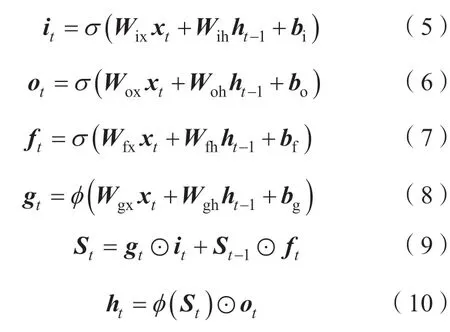
式中:σ和φ分别表示sigmoid函数和tanh函数;it,ot,ft,ht,gt和St分别表示输入门、输出门、遗忘门、中间输出节点、中间输入节点以及状态单元;Wix,Wih,Wox,Woh,Wfx,Wfh,Wgx以及Wgh分别表示输入xt和中间输出ht-1在与对应门相乘时的矩阵权重;⊙表示两向量中的元素按位相乘;bi,bo,bf及bg分别表示各对应门的修正向量。
根据对LSTM模型原理的分析,本实验以负荷预测值Ypred为目标建模变量,确定负荷预测的步骤如下:
1)将随机森林算法筛选后的重要时间日期因素及气候因素特征向量与历史负荷数据结合作为特征建立预测特征集XL={x1,x2,…,x7,y},其中x1~x7为随机森林算法所筛选的7个重要特征量,y为历史负荷数据。
2)根据图3构造LSTM网络模型,将特征集XL作为输入层,中间为隐藏层,最后输出负荷预测值Ypred。
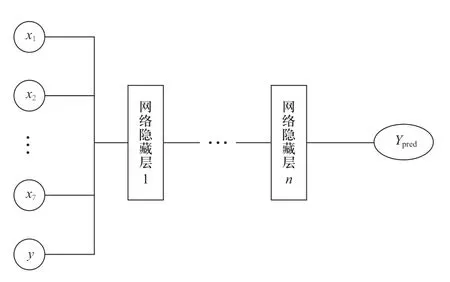
图3 LSTM网络模型Fig.3 LSTM network model
根据数据集的特征确定LSTM网络模型的网络隐藏层层数及每层包含的记忆单元数,并通过粒子群(particle swarm optimization, PSO)算法对训练次数等参数进行寻优。其中模型的激活函数及训练时的损失函数分别为式(11)和式(12)。
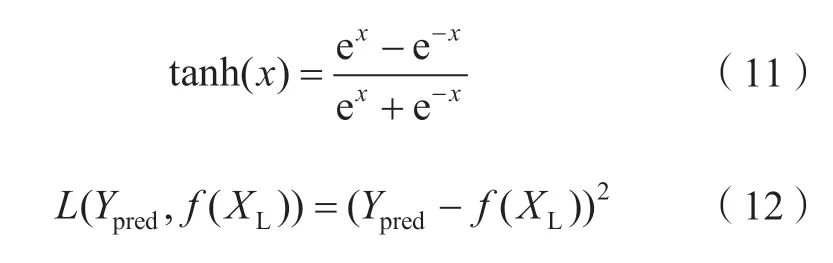
2.3 RF-LSTM混合预测模型
本文提出的RF-LSTM网络混合预测模型的流程如图4所示,其中包括对负荷及相关数据的采集和预处理、随机森林模型及LSTM模型的构建以及电力负荷的预测。
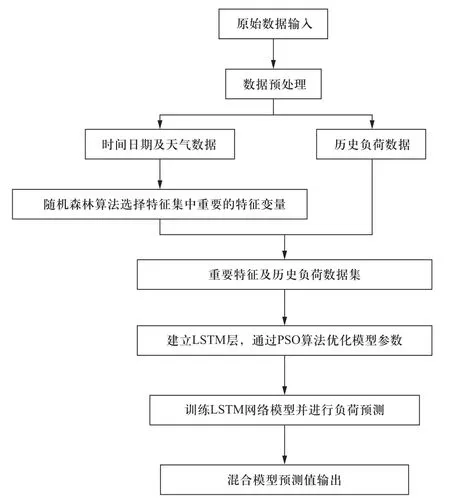
图4 RF-LSTM混合模型预测流程图Fig.4 Process of prediction of RF-LSTM hybrid model
1)相关数据的采集和预处理。以河北电网某台区电力负荷数据,以及表1所示的可能对负荷造成影响的环境因素和时间日期因素等共15个特征因素构成数据集。对于部分缺失或异常的负荷数据采用线性插值法进行填补,并对所有特征数据进行归一化处理。
2)重要特征变量选择。利用随机森林算法对14个时间日期及天气因素特征变量进行重要性排序,选择最重要的7个特征作为进一步负荷预测的特征变量输入。
3)LSTM网络模型构建及负荷预测。将步骤2)中由随机森林算法筛选得到的7个重要特征变量及历史负荷结合构成8维LSTM网络模型的训练集XL={x1,x2,…,x7,y}。构建LSTM网络模型,将模型参数初始化并通过粒子群算法优化,训练得到负荷预测结果Ypred。
2.4 模型评价指标
根据国家电网负荷预测结果评价指标,本实验设置平均绝对百分比误差EMAPE、均方根误差ERMSE以及预测精度AF三项评价指标,具体表达式如式(13)—式(15)所示。
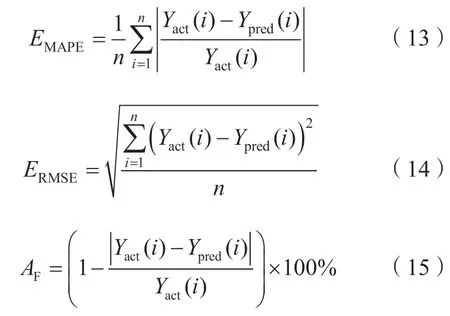
式中:n为总预测次数;Yact(i)和Ypred(i)分别为负荷真实值和负荷预测值。
3 算例分析
本文使用河北电网某台区2020年3月至5月的电力负荷数据对所提出的RF-LSTM混合预测模型进行验证。根据如表1所示构建的预测特征,通过随机森林算法进行重要性筛选,与历史负荷数据结合作为特征向量,并按照0.9:0.1的比例将数据集划分为训练集和测试集。在相同条件下分别使用LSTM模型、随机森林模型、BP神经网络模型以及RF-LSTM混合预测模型进行训练及负荷预测。
3.1 模型数据归一化
为消除各特征之间不同量纲的影响并使预测模型尽快收敛,在确定特征集后需要对原始数据进行归一化处理,使各特征数据经线性变换后都在[0,1]内:

式中:x和x*分别为归一化前后的值;xmax为各特征样本数据的最大值;xmin为各特征样本数据的最小值。
3.2 模型构建及参数确定
电力负荷易受时间、日期及天气环境等因素影响,且具有非平稳、非线性等特点,在预测电力负荷的过程中并非参与预测的特征变量越多,预测越准确。本文通过随机森林算法对影响电力负荷的多个特征变量的重要性进行评估并排序,选择对负荷影响较大的变量参与后续预测。将表1所示14维特征向量经数据预处理后,作为重要特征备选,经过随机森林算法重要性评估后的结果如图5所示。
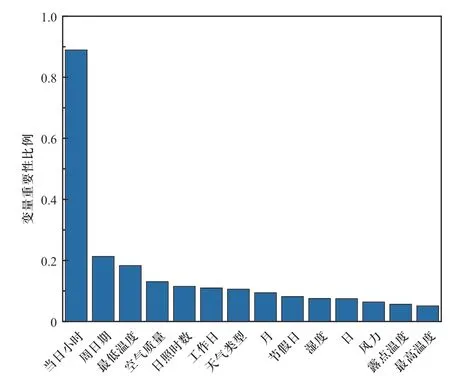
图5 随机森林特征变量重要性分析结果Fig.5 Results of the importance of characteristic variables based on random forest
由图5可知,将对于电力负荷存在影响的14个特征变量按重要性排序,剔除重要性比例小于0.1的特征变量,选择当日小时、周日期、最低温度、空气质量、日照时数、工作日、天气类型等变量作为后续负荷预测模型的输入,使得负荷预测中参与的特征向量由14维降至7维。
将由随机森林算法筛选得到的7维重要特征向量与历史负荷数据结合,该8维特征向量作为LSTM网络模型的输入,以1维电力负荷预测结果作为LSTM网络模型的输出,构建LSTM网络模型。如图3所示,首先确定LSTM网络模型的结构,即确定网络隐藏层数和每个隐藏层的记忆单元数,本文使用穷举搜索法研究二者对LSTM网络模型预测精度的影响。分别设置LSTM网络模型具有1、2、3个网络隐藏层,并设置每层记忆单元数在[40,80]范围内递增,计算不同模型结构下负荷预测的平均绝对百分比误差EMAPE,得到单网络隐藏层实验结果(表2)和多网络隐藏层实验结果(图6)。
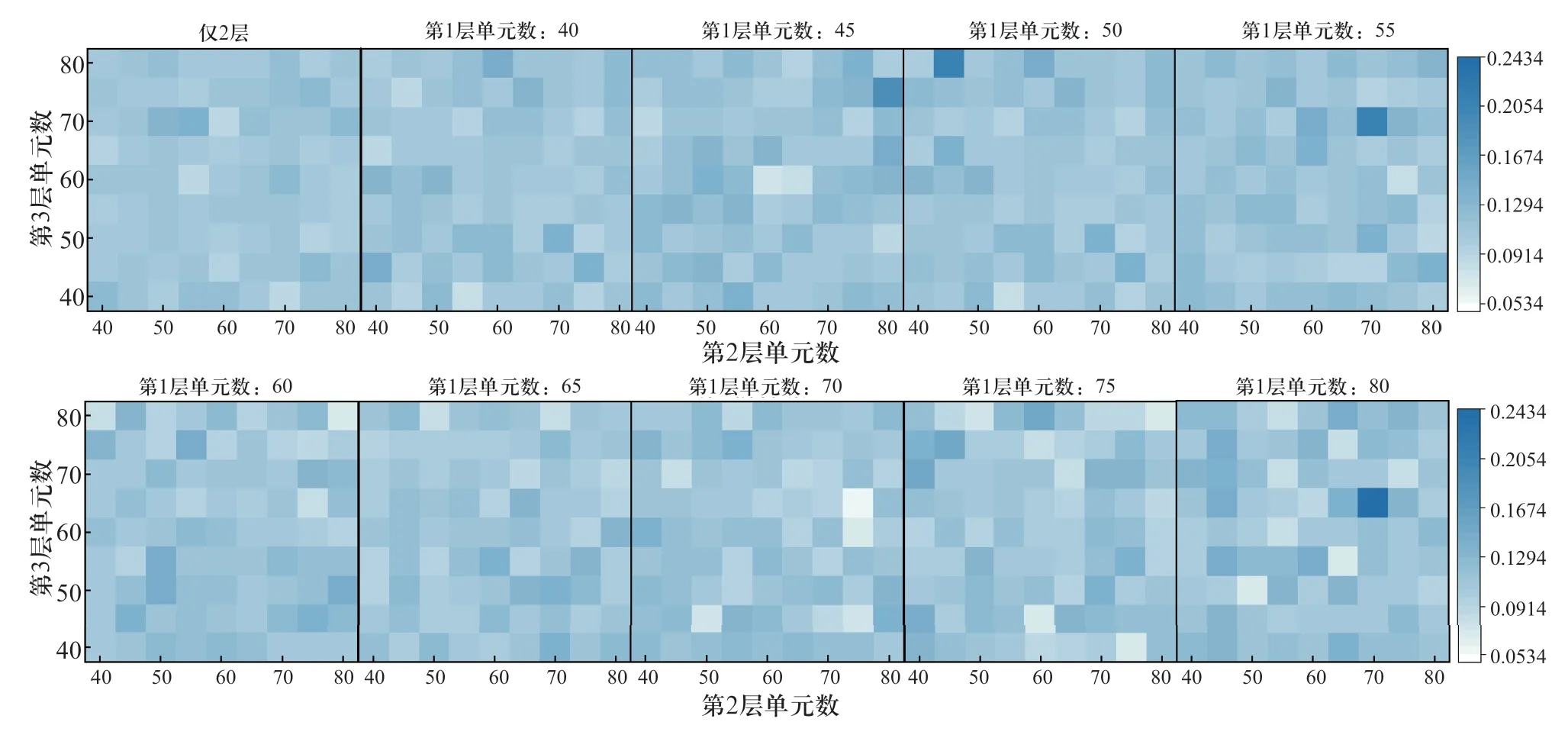
图6 多网络隐藏层不同LSTM网络结构的EMAPE比较Fig.6 Comparison of EMAPE of different LSTM network structures of multi-hidden layers
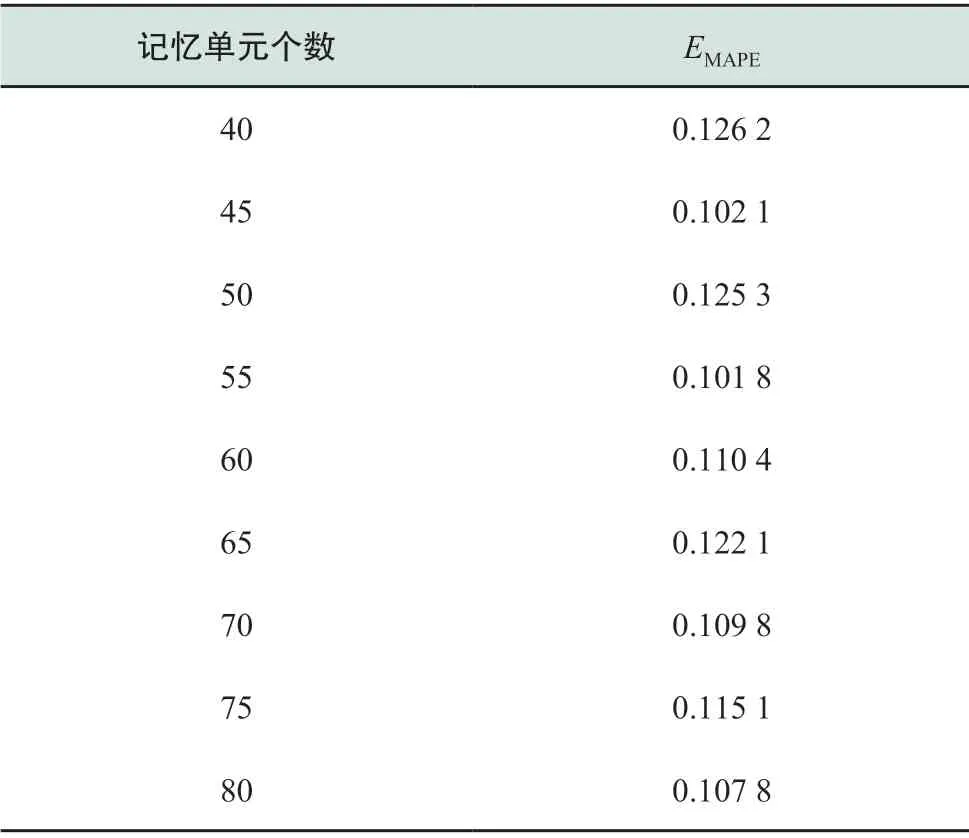
表2 单网络隐藏层不同记忆单元数EMAPE 比较Table 2 Comparison of EMAPE for different number of memory unites of single hidden layer
综合表2、图6的结果可知,当LSTM具有3个网络隐藏层且各层记忆单元数分别为70、75、65时,LSTM模型的预测精度可以达到最高。
除了模型的结构以外,训练次数的选择也会影响预测精度,过多或过少的训练次数对于LSTM模型的性能都是不利的。训练次数不足会导致模型无法达到最佳收敛,训练次数过多则会导致训练所耗费的时间过长而预测精度并未得到明显的提升。此外,影响LSTM网络预测精度的主要参数还有初始学习速率(initial learn rate)、学习速率下降时的迭代数(learn rate drop period)及学习速率下降因子(learn rate drop factor),因此还需要确定这3个参数的最佳选择。需要确定的参数较多,不适宜再使用穷举搜索法,因此采用粒子群算法进行参数寻优[26]。设粒子群算法中最大迭代次数为100,种群规模为20,适应度函数为不同参数下负荷预测的平均绝对百分比误差EMAPE,寻优结果如图7所示。最终确定LSTM网络模型的关键参数如表3所示。
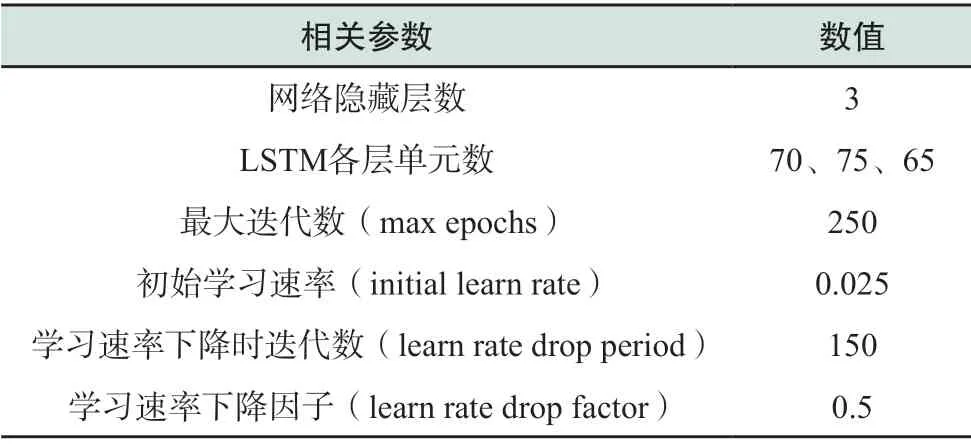
表3 LSTM网络关键参数Table 3 Key parameters of LSTM network
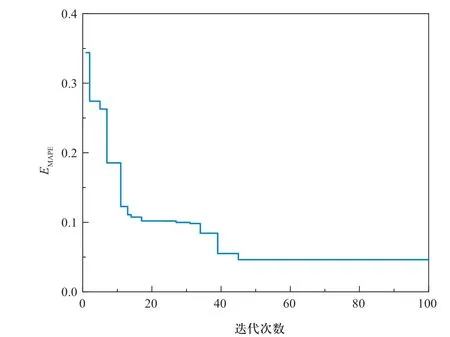
图7 基于粒子群算法的LSTM模型参数寻优Fig.7 Parameter optimization of LSTM network based on PSO
3.3 实验结果分析
LSTM网络和随机森林模型构建完毕后,对本文提出的RF-LSTM模型进行训练及负荷的预测工作,计算模型的均方根误差ERMSE、平均绝对百分比误差EMAPE以及预测精度AF三项评价指标,并将预测结果分别与未经特征量筛选的单一LSTM模型、随机森林算法、BP神经网络模型进行对比。其中,单一LSTM模型、随机森林算法及BP神经网络模型均使用PSO算法进行参数优化,各模型参数优化结果分别如表4—表6所示,表7为各模型预测结果的对比情况,可看出RFLSTM混合模型的预测结果明显更优。相比较于传统高维特征量输入的LSTM算法,RF-LSTM混合模型预测结果的均方根误差减少了12.89%,预测精度提高了0.83个百分点,这表明通过随机森林算法对高维时间日期及天气等变量进行重要性筛选后模型预测效果更优,验证了RF-LSTM混合预测模型的可行性。此外,RF-LSTM混合模型预测结果与输入为高维特征量的随机森林算法以及BP神经网络相比,RF-LSTM混合模型预测结果的均方根误差分别减少了19.44%和27.27%,预测精度分别提高了1.10和2.22个百分点,验证了本文混合预测模型的有效性。4种模型预测曲线对比如图8所示,抽取其中连续24 h的预测结果数据汇总表见表8。分析对比结果可知,本文提出的RFLSTM混合负荷预测模型对输入变量的重要性进行选择,大大减少了模型的输入变量个数,预测误差小,预测精度高,能够实现对负荷预测输入参数的优化,较好地完成电力负荷预测任务。

表4 单一LSTM模型关键参数Table 4 Key parameters of single LSTM network
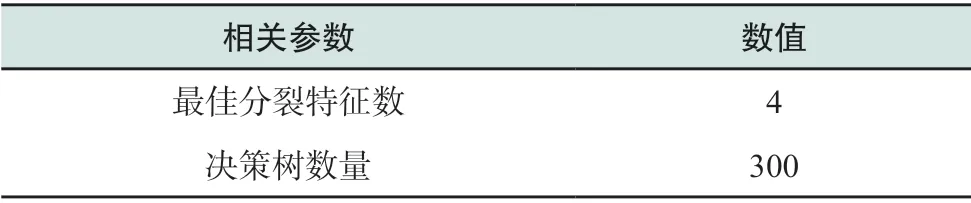
表5 单一随机森林模型关键参数Table 5 Key parameters of single random forest

续表
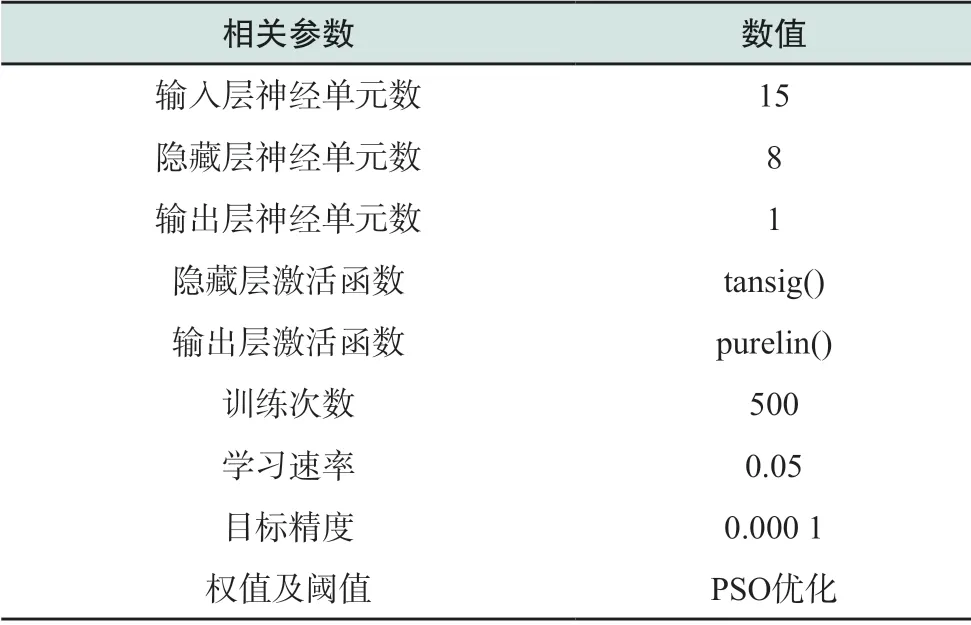
表6 单一BP神经网络关键参数Table 6 Key parameters of single BP neural network
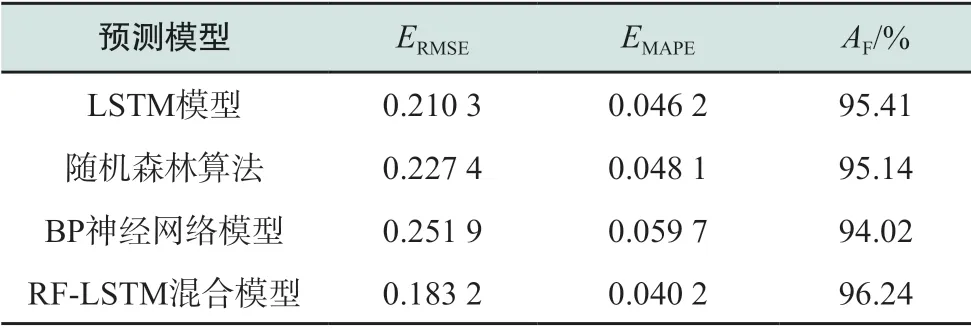
表7 不同模型预测结果比较Table 7 Comparison of prediction results of different models
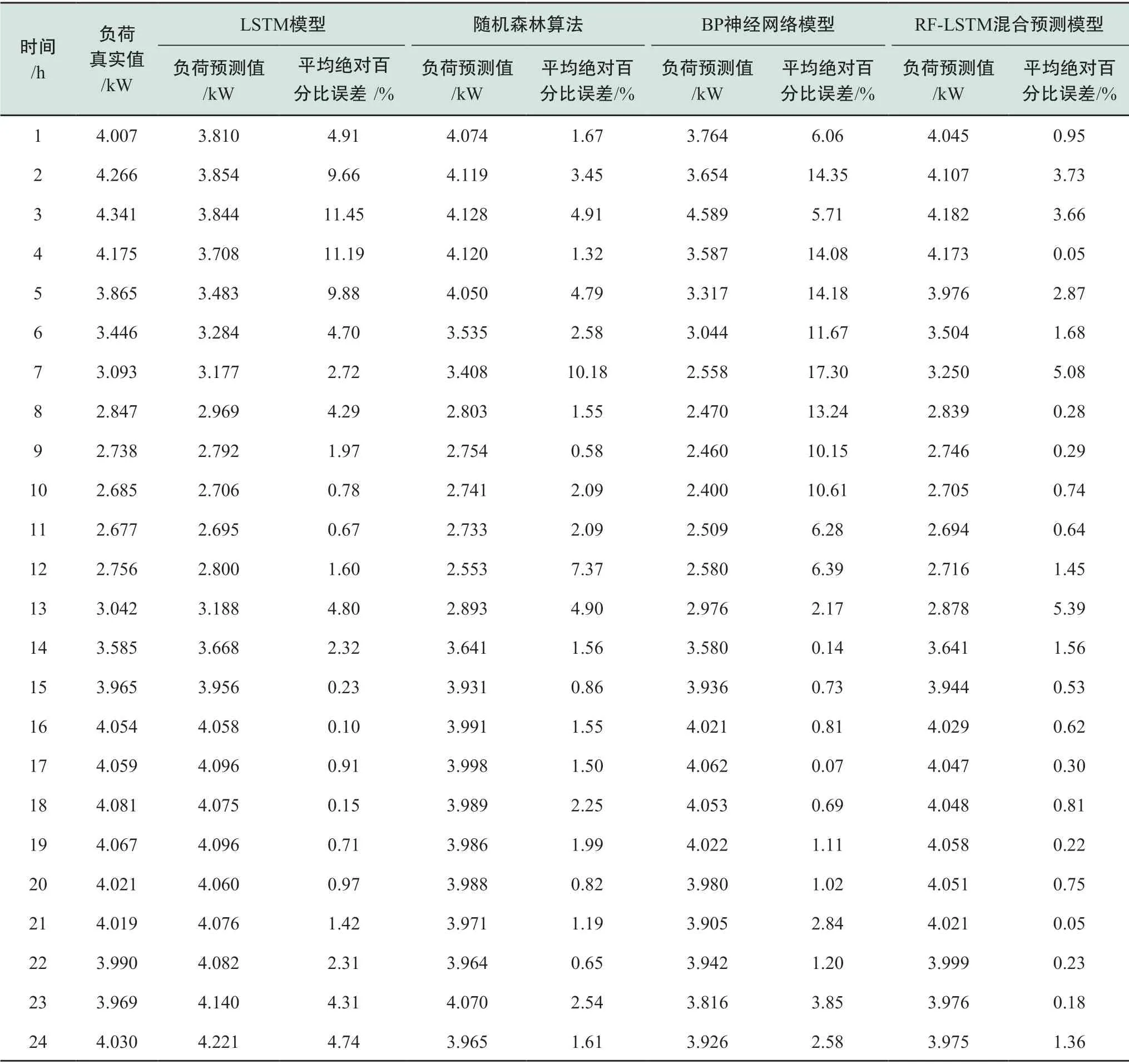
表8 不同模型预测数据汇总Table 8 Summary of forecast data for different models
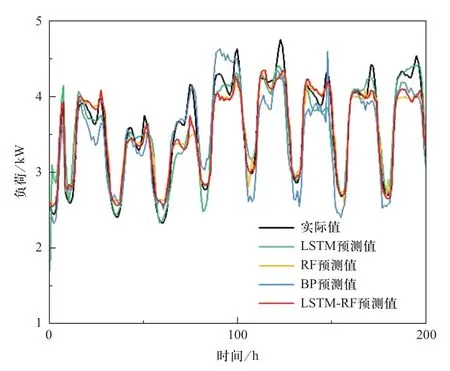
图8 不同模型预测结果对比图Fig.8 Comparison of prediction results of different models
4 结语
为了更加精确地预测电力负荷,本文提出一种基于RF-LSTM的混合预测模型,利用随机森林算法对高维特征变量进行重要性排序和选择,将筛选出的重要特征量与历史负荷数据作为LSTM预测模型的输入,构建RF-LSTM混合预测模型。通过对比实验可知RFLSTM混合模型的主要优势如下。
1)使用随机森林算法对众多可能影响电力负荷的时间日期及天气因素进行重要性评估,筛选重要变量,从而减少后续预测模型输入变量个数,降低预测模型的复杂性,有利于提高预测精度。
2)LSTM模型对于具有明显非线性、时序性的电力负荷数据学习能力较强。面对较多超参数寻优问题时使用粒子群算法进行参数优化可以较为快速地获得优化结果,并使预测结果更为准确,避免人为选参对预测结果带来的不利影响。根据实验结果可知,本文提出的方法可有效提高电力负荷的预测精度,RFLSTM混合预测模型具有充分的可行性和有效性。
本文中所构建的特征数据集未考虑不同时段电价不同这一影响因素,因此后续研究中考虑加入电价等特征,构建更为丰富的特征集并深入探究各因素间的关系。同时将对模型作进一步改进,提高预测速度和精度。此外,还将考虑将电力负荷预测应用于电网数字孪生的建设中。基于负荷预测数据和实时工作环境数据,研究数据驱动的智能配电网容量挖掘技术,构建配变及线路重过载多维度评估体系。
猜你喜欢
纺织标准与质量(2022年2期)2022-07-12
煤气与热力(2022年4期)2022-05-23
中学生数理化·中考版(2021年8期)2021-07-31
小学生学习指导(高年级)(2021年4期)2021-04-29
长江大学学报(自科版)(2021年6期)2021-02-16
作文大王·笑话大王(2017年1期)2017-02-21
作文大王·笑话大王(2016年10期)2016-10-18
作文大王·笑话大王(2016年7期)2016-08-08
作文大王·笑话大王(2016年2期)2016-02-24
新高考·高二数学(2014年7期)2014-09-18
