
基于高阶矩冲击机器学习Multi-LSTM模型的中国碳价预测
2022-03-21 03:28:48陈江华唐文之
安徽师范大学学报(自然科学版) 2022年1期
云 坡, 陈江华, 唐文之
(合肥学院 经济与管理学院,安徽 合肥 230601)
在双碳战略目标背景下,有效的碳排放权定价形成机制,对于撬动全国碳排放达峰目标的实现具有重要意义。价格机制是碳交易市场的核心,因此,研究碳排放权市场化交易中价格形成机制,开展价格预测研究是切实增强金融体系管理气候变化相关风险能力的关键举措,相关结论和方法也能为投资者参与碳金融市场交易,规避碳市场风险提供有益参考。
1 文献综述
现有碳价预测方法主要分为两类:基于GARCH簇波动率建模的碳价预测和人工智能集成建模技术。其中,早期碳价预测研究学者主要采用GARCH簇建模技术从价格的内在波动视角探究碳溢价波动机理。研究发现,GARCH簇模型具有拟合和预测欧盟碳期货价格的优势,特别是非对称门槛GARCH模型、多元GARCH模型、自回归AR-GARCH模型以及EGARCH等模型能有效揭示市场结构性定价因子对碳收益的内在冲击,提高收益预测的准确性[1-2]。碳资产收益具有时变跳跃和随机游走特征,使得基于正态分布假设的ARMA-GARCH模型的预测性能下降,而考虑时变跳跃非参数特征的GARCH模型,以及融合时变跳跃Levy过程的GARCH模型能够有效解释碳期货市场收益的变化[3-4]。张晨则指出中国区域碳价具有非线性和异质性波动特征,由于发展时间较短,累计数据量较少,使得传统GARCH簇等统计建模技术对该类数据的市场信息预测性能不足[5]。
基于GARCH簇波动建模技术的碳价预测模型要求收益服从严格的尾部分布假设,容易产生模型适用性的质疑。而人工智能集成建模技术则具有非线性映射、特征提取以及网络结构参数的自学习自适应和自调整优势。融合数据分组技术GMDH和支持向量机SVM的优势,使用PSO算法、SVM模型对BP神经网络和ARIMA碳价预测模型进行优化,发现改进后的模型能够对欧洲碳价取得较好的样本外预测效果[6-7]。基于分解重构集成建模思路,使用EMD模态分解技术将碳价序列分解为若干游程模态IMF,并使用聚类算法、遗传算法GA等对游程集成预测模型进行优化,研究指出人工智能集成技术能对非线性多模态的碳价序列进行有效预测[8-9]。进一步地,Sun等提出一种融合混合优化算法的数据预处理机制、分解技术和距离熵将变分模式VMD融合的集成预测方法,并在中国区域碳价预测中取得很好的预测表现[10]。
2 碳价预测模型设计
首先构建基于高阶矩冲击关系的碳价预测机理,厘清碳价预测的逻辑路径和碳溢价波动的影响关系;其次,基于机器学习方法构建碳定价的实证模型。
2.1 碳价多因素APT预测机理
根据高阶矩CAPM定价模型,金融资产收益不仅受到系统性风险的影响,而且表示市场非对称信息和极端冲击风险因子的协偏度和协峰度冲击等高阶矩项也是资产溢价的解释证据[12]。为揭示高阶矩项对投资组合收益的冲击,Fry等在传统CAPM框架中引入了协偏度和协峰度项,建立一个扩展的高阶矩CAPM模型[13]。协偏度和协峰度冲击下,基于二元正态分布投资组合的预期收益如下所示:
(1)
(2)
其中,fcos kness(r1,t,r2,t)和fcokurtness(r1,t,r2,t)分别表示考虑协偏度和协峰度冲击的资产组合收益;θ12表示协偏度冲击系数;θ13表示协峰度的冲击系数;r1,t,μ1,σ1以及r2,t,μ2,σ2分别表示资产1和资产2的收益率、均值和方差;ρ表示相关系数,η为残差。
然而,上述高阶矩CAPM模型仅适用处理二元资产定价问题,需要收益率遵循标准分布的假设前提,为克服这一局限性,本文将协高阶矩冲击项引入多因素APT定价模型之中,揭示市场非对称信息和极端外部事件等因素对碳价的影响和冲击,公式如下:
(3)
其中,f(r0,t)表示碳资产收益;ηn,t表示残差项;r1,t,r2,t,…rn,t表示碳价影响因子的收益率;α1,α2,…αn表示冲击系数;θi表示资产i二阶中心距(方差)对碳资产收益1一阶中心距(收益率)的冲击系数,即定价因子的市场非对称信息对碳价的冲击,也就是协偏度冲击关系;δi表示资产i的三阶中心距(偏度)对碳资产收益1一阶中心距(收益率)的冲击系数,揭示定价因子极端外部因素或政策性因素对碳价的冲击,即协峰度冲击关系。
2.2 基于LSTM神经网络的预测模型构建
根据构建的碳价多因素APT预测机理,碳资产收益预测实质上多变量时间序列输入的回归问题。在模型选择上,考虑到碳定价因子数据的时间序列数据特征,本文选择在时间序列数据处理具有优势的长短期记忆神经网络模型(Long Short-Term Memory network,LSTM)作为碳价拟合预测的工具,并以此构建多层多变量的深度网络,即构建多层多变量(Multilayer and Multivariable)的LSTM模型(Multi-LSTM)实现多维碳定价因子数据输入的特征捕捉和非线性拟合。LSTM网络实现对较长滞后数据信息的特征学习依赖于模型独特的细胞元组Cell,作为LSTM的关键,细胞元组Cell通过特殊的遗忘门(forget gate)、输入门(input gate)、和输出门(output gate)控制数据信息的筛选、更新和摒弃。各门结构的数据训练如下:
遗忘门的作用是对碳定价因子数据信息特征进行筛选和过滤,得到遗忘过滤输出:
ft=σ(Wf×[ht-1,xt]+bf)
(4)
输入门是对遗忘数据输出进行更新和保存处理,通过激活函数得到输入们输出:
采用免疫组织化学方法检测宫颈鳞癌及子宫内膜腺癌标本及对照组标本,对其MTSS1的表达情况进行判定。应用实时荧光定量PCR(q-PCR)测引物序列及Western 蛋白印迹法对MTSS1的表达情况进行判定。
(5)
(6)
ot=σ(Wo×[ht-1,xt]+bo)
(7)
输出门则决定隐藏层细胞元组Cell中需要被记忆的数据特征,通过激活函数进行映射得到本层输出:
it=σ(Wi×[ht-1,xt]+bi)
(8)
ht=ot×tanh(Ct)
(9)

2.3 模型评价准则
本文使用一步向前预测方法对碳价收益率进行预测实验分析,由于真实值能在未来的预测中不断修正预测信息,使得一步向前预测方法具有良好的模型适应性和鲁棒性。使用以下方法对Multi-LSTM模型的参数估计和碳价预测性能进行效果评价。
(10)
(11)
(12)

(13)

3 基于高阶矩冲击的中国区域碳价预测实证分析
3.1 样本数据和基本统计
碳资产具有特殊的金融属性和商品属性,其市场收益受到能源市场、资本市场以及环境市场产品的综合影响。基于此,本研究选择湖北碳交易市场的碳排放权成交均价作为碳资产的收益序列(HBEA),数据源自中国碳排放交易网;并选取焦炭期货(JTF)、焦煤期货(JMF)、布伦特原油期货、沪深300指数以及欧洲碳配额期货产品EUAF作为影响碳资产收益波动的定价因素,数据来自大连商品交易所、万德金融终端等数据库。之所以选择湖北碳交易中心的碳配额资产的原因在于,湖北碳市场的市场成交规模、社会资金引进以及减排企业参与等已经领先全国,并且承担即将于2021年6月启动的全国性碳排放权注册登记系统的运行和建设任务,市场制度建设和运行规制相对成熟。上述碳资产及其定价因子数据窗口为2014年4月28日—2021年2月26日,剔除节假日、疫情因素以及数据不一致共得到1626个样本点。在机器学习数据建模上,以时间序列前75%数据作为训练集,后25%数据作为测试集。使用Rt表示碳资产收益率:Rt=100×(lnPt-lnPt-1),其中Pt表示碳资产及其定价因子日价格序列或指数序列。
样本数据的描述性统计结果(表1)显示:第一,根据ADF和JB统计量表明碳价及其定价因子序列具有一阶平稳性,并不服从标准正态分布;第二,碳资产及其定价因子序列的收益均值差别较小,而标准差差异较大。其中,碳资产HBEA的市场偏差最大为3.9474,衡量股市走势的HS300市场偏差最小为1.5003,这也反映碳资产的市场风险较大,在碳价预测中考虑市场冲击尤为重要。第三,所有收益序列的市场偏度均为负,偏度值较大,表明碳资产及其定价因子序列具有明显的市场非对称性和尖峰厚尾特征。负偏度表明市场下行对收益序列的冲击较强,而较高的峰度意味着资产收益方差的增加是由低频度的极端值引发的,收益序列容易遭受到外部极端事件或政策性因素的冲击。
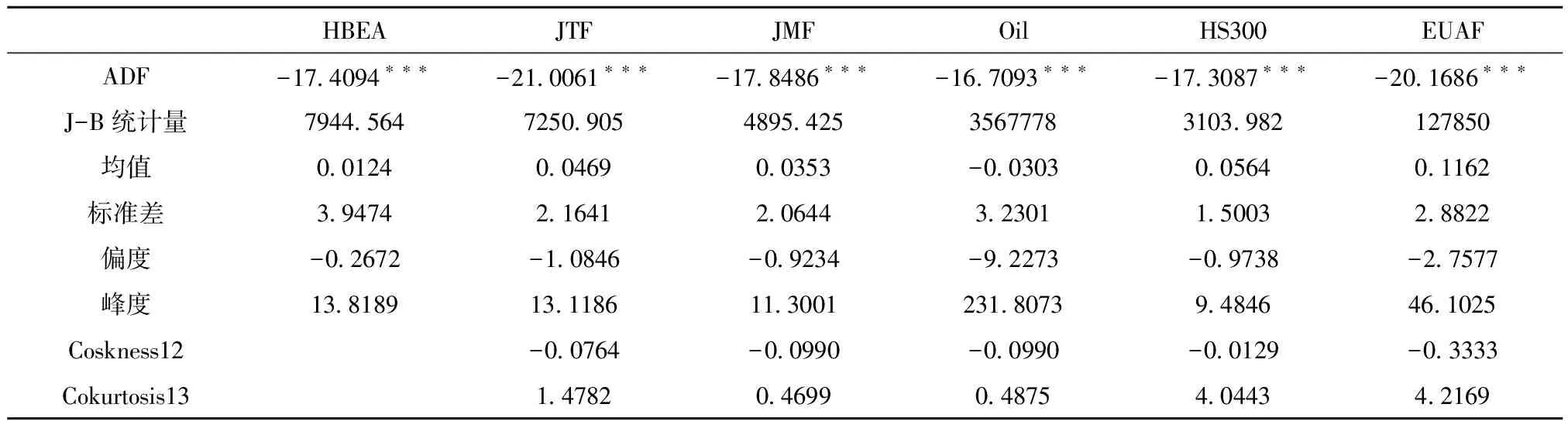
表1 描述性统计分析
所有的协偏度均为负,表明来自定价因子市场的信息不对称极易对碳资产形成风险冲击,引发碳收益下降;而较高的协峰度系数表明源于定价因子市场的极端冲击极易蔓延到碳市场,并形成严重的收益冲击现象。如图1所示,在碳资产与HS300的联合概率密度分布中,较高的分布峰度表示该组合资产容易遭受市场上极端风险的冲击,定价因子市场的风险极易传递到碳市场引发收益波动。以上证据表明碳资产收益预测不仅要从收益和方差视角着手,而且反映市场非对称信息和极端冲击因素的市场偏度和峰度等高阶矩信息也是揭示碳溢价形成的不可或缺因素。
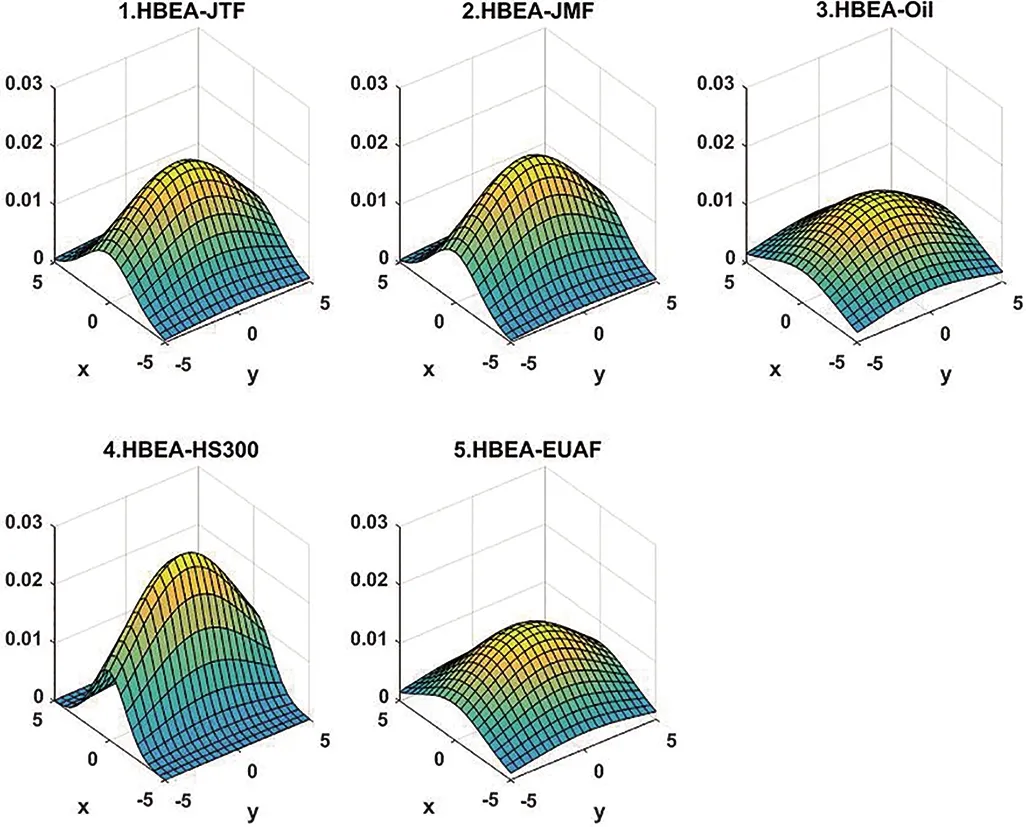
图1 中国区域碳价及其定价因子间的协高阶矩联合概率密度分布图
3.2 碳价预测模型Multi-LSTM网络结构设计
根据前文分析,碳资产价格预测模型的输入为各个定价因子序列以及定价因子对碳资产的协偏度动态冲击和协峰度的动态冲击,即网络输入神经元为15;模型输出就是碳资产收益序列,即定价因子网络训练的标签目标,输出神经元为1。然而,大多数研究对隐藏层个数以及隐藏层神经元的确定多依据经验而定,存在较为主观的人为设定误差。增加较多的隐藏层和神经元数量固然可以实现大规模复杂数据的模型训练,降低训练和拟合误差,但是也容易产生过拟合或是梯度消失问题,增加训练成本;而较小的隐藏层和神经元又会引发训练不足,限制网络的学习能力并难以接近最优解。研究显示,两层隐藏层的神经网络已经能够满足多数问题的解决[14]。
为了避免人为主观经验设置而带来的训练损失,本研究将根据网络模型输入和输出的数据信号特征,借助机器学习的网络结构训练自学习、自适应和自调整优势,通过逐步实验方法进行动态参数调优,找到最优的模型结构。通过表2中显示的模型参数逐步实验结果显示,当碳价预测模型Multi-LSTM设置为3个隐藏层,并且每层神经元个数为64时的模型训练误差最低,性能最优,此时误差标准RMSE、MAE为0.1204627和1.5402976,为所有试验结果的最小值。因此,本文将碳价预测模型Multi-LSTM的网络结构设计为:15-64-64-64-1。

表2 基于逐步实验法的Multi-LSTM模型网络结构参数
3.3 基于Multi-LSTM模型的碳价预测分析
为对比分析本文构建的考虑高阶矩冲击碳价模型的预测效果,选择门限神经网络模型(Gated Recurrent Unit,GRU)、梯度提升回归模型(Gradient boosting regression,GBR)、多层感知机模型(Multilayer Perceptron,MLP)、极端随机森林回归(Extremely Randomized Forest regression,ETR)以及经典反向传播BP模型(Back Propagation Network,BP)等回归器作为模型评价的比较基准,并采用相同的神经网络结构参数。
实证结果显示:①对于考虑高阶矩冲击关系的碳价预测效果,Multi-LSTM模型相比基准模型具有显著的预测精度和稳定性,模型的收益预测能力和预测效果比较符合投资者的心理预期,表明该模型能够为投资者研判市场行情、制定投资策略等给提供技术支撑。表3可知,Multi-LSTM模型的误差指标RMSE、MAE、MAPE分别为2.6506440、1.7367371和2.4321860,在所有基准模型中最小,预测精度最优;DA指标数据为0.8819048也明显高于其他模型,表示具有较强的市场前景预测能力。图2显示基于Multi-LSTM模型的预测序列和真实序列拟合程度较强,误差值较小并且波动幅度较低。相比而言,基于BP模型对考虑高阶矩冲击的碳价预测效果较差,误差指标值较大,市场预期DA指标相对较低,表示该模型对碳价序列的拟合能力有限,模型的稳定性和鲁棒性不足。

图2 考虑高阶矩冲击的碳价预测效果

表3 基于多层多变量Multi-LSTM模型的中国区域碳价预测绩效
②对于不考虑高阶矩冲击关系的碳价预测效果,Multi-LSTM模型在低阶矩属性渠道上的碳价预测精度、模型的稳定性以及对市场前景的投资预测等依然具有显著优势。模型的误差指标RMSE、MAE、MAPE分别为3.2885668、1.9659774、2.7146707,均小于其他基准模型的预测效果;市场预期指标DA值为0.8714286也高于其余模型。这表明,即使不考虑定价因子高阶矩属性对碳价的收益冲击关系,仅考虑定价因子对碳价低阶矩收益冲击,Multi-LSTM模型仍具有显著的预测精度和模型稳健性,能够揭示碳定价因子对碳溢价的影响路径和冲击关系。
③综合比较表3中各模型的预测结果发现,Multi-LSTM模型对考虑高阶矩冲击关系的碳价预测误差类评价指标均小于,且市场预期指标DA又高于不考虑高阶矩冲击关系的预测效果,具体效果呈现如图3。
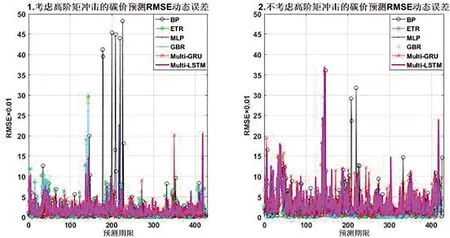
图3 Multi-LSTM模型及其基准模型的碳价预测动态误差
该结果一方面表明,考虑高阶矩冲击关系的碳价预测模型能够对碳资产收益序列进行有效的拟合和映射;另一方面,也证明将定价因子对碳收益序列的高阶矩冲击关系纳入到定价模型中的合理性,揭示市场间的非对称信息和极端冲击等高阶矩信息也是不可或缺的碳溢价解释因素。
4 结论
开展碳排放权市场化交易中的价格预测研究是推动碳金融市场减排作用发挥并实现碳达峰和碳中和的关键。现有碳价预测研究仅考虑低阶矩属性(收益-方差)下的碳定价路径,缺乏从高阶矩(偏度-峰度)视角研究市场非对称信息和极端冲击等因素对碳收益的动态冲击路径。本文基于碳价专属波动特征,从高阶矩属性维度构建多因子碳价预测机理,研究定价因子市场非对称信息和极端事件等对碳价的非线性动态冲击,并使用机器学习模型检验碳价预测的准确度和稳定性。
研究发现,本文构建的Multi-LSTM碳价预测模型具有较强的预测精度和稳定性,模型的收益预测能力和预测效果比较符合投资者的心理预期,该能够为投资者研判市场行情提供技术支撑。这说明,本文构建的考虑高阶矩属性冲击关系的碳价预测机理的有效性和合理性得到有力证明,定价因子市场非对称信息和极端事件等因素也会对碳价收益形成冲击,是重要的碳溢价波动证据,同时也为投资者构建碳资产投资组合、厘清碳溢价形成路径、揭示碳价决定因素等提供参考。
猜你喜欢
财会月刊·上半月(2022年6期)2022-06-15 01:20:17
昆明医科大学学报(2021年4期)2021-07-23 01:21:38
数学物理学报(2021年1期)2021-03-29 03:13:48
数学物理学报(2020年6期)2021-01-14 01:00:36
哈尔滨轴承(2020年1期)2020-11-03 09:16:02
国际放射医学核医学杂志(2020年4期)2020-07-27 01:53:26
中国管理科学(2020年11期)2020-03-09 09:52:00
雷达学报(2018年3期)2018-07-18 02:41:16
中国人口·资源与环境(2017年6期)2017-06-14 16:59:07
罕少疾病杂志(2016年5期)2016-03-11 16:34:41
