
基于关键点的点对特征三维目标识别算法
2022-03-21 04:41:48陆军韦攀毅王伟
北京理工大学学报 2022年2期
陆军,韦攀毅,王伟
(1. 哈尔滨工程大学 智能科学与工程学院,黑龙江,哈尔滨 150001;2. 哈尔滨工程大学 船海装备智能化技术与应用教育部重点实验室,黑龙江,哈尔滨 150001)
在计算机视觉中,对由不同传感器获得的3D对象的识别已得到广泛研究[1],基于局部特征的物体识别方法[2],是依据点的局部特征信息进行匹配,进而检测识别出目标物体. 点签名法[3]是通过点所在曲线的法向量与参考矢量定义旋转角度对点深度信息进行描述的方法. 该方法易受噪声的影响. DENG 等[4]使用局部协方差描述符对人脸特征进行描述,然后通过黎曼核稀疏编码方式对人脸进行识别. 该方法目前主要针对特定的流形. ANDREW等[5-6]]提出基于旋转图像法的三维点云场景物体识别方法,该方法主要用于识别场景中比较规则的物体,对于复杂的室外场景物体,则表现不佳. GUO等[7]提出了一种ROPS(rotational projection statistics)描述符,将邻域内的点映射到二维坐标平面上,并通过计算二维平面上点的低阶矩和熵来形成描述符. FROME等[8]提出了三维形状上下文法,该方法在特征匹配时需要将场景特征描述向量绕Z轴旋转并计算与模型描述特征向量的相关度,计算量较大.
基于全局特征方法通过描述和对比三维物体整体形状中的几何特征来完成物体的识别. KHOSHELHAM[9]提出使用广义的霍夫投票用于目标的识别,对三维物体的姿态估计需要6个自由度. 这样增加了时间和空间的复杂度,加大投票过程的成本. CHEN等[10]提出一种基于物体表面积的描述符的识别方法,通过构建有向包围盒中物体表面积的柱状图来匹配物体. DROST等[11]提出一种点对特征全局描述符,该描述符不需要依赖于点周围邻域局部曲面的特征计算,而是利用点与点之间的几何关系来构建特征描述. 后来许多研究学者对该算法进行改进,CHRISTENSEN等[12]对该描述符加入颜色信息,构成颜色点对特征描述符. 最近VOCK 等[13]在后期匹配搜索方式上进行了改进,但是这些算法对点对特征的构建都是在原始三维点云中进行的,将点云中的所有参考点对都考虑在内,计算量大,消耗了大量的时间.
本文设计了一种基于关键点的点对特征三维目标识别算法,使用内在形状签名(intrinsic shape signatures,ISS)算法提取关键点以减少点云数据,对关键点集合构建点对特征描述符,利用快速投票方案对模型点云和场景点云进行匹配识别,迭代最近点(iterative closest point,ICP)算法用于对物体姿态进行优化,完成点云配准,根据配置后点云的重叠情况实现点云目标识别. 本文方法不需要对场景进行分割,对有噪声、杂波和遮挡的情况下具有良好的适应性.
1 基于ISS算法的关键点提取
ISS算法是一种利用局部几何信息来构建协方差矩阵,并根据求取的特征值之间的关系来提取关键点的算法. 关键点提取步骤如下:
①对原始点云建立空间拓扑结构,方便后续遍历搜索.
②选取点云中的任意一点pi作为参考点,并以此为中心构建半径为R的邻域,计算邻域内的点与参考点pi之间的距离,取倒数作为权重并记为wij
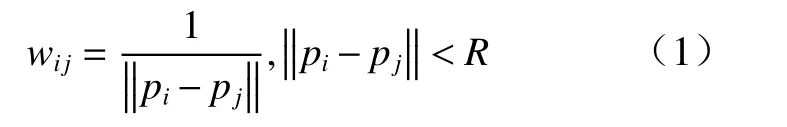
③根据参考点pi的邻域信息构建协方差矩阵
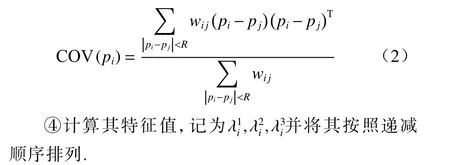
⑤设定参数阈值δ1和δ2,将满足式(3)的点作为关键点,并加入关键点集
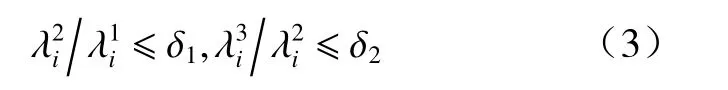
重复上述步骤,直到全部点都检测完为止,至此便构建完成关键点集合. 提取的关键点一方面会提高后续的识别效率,另一方面会增强对噪声的鲁棒性.
2 基于点对特征的全局描述符
全局模型描述由所有模型点对特征组成,描述了模型曲面上所有点对特征的全局分布. 与需要密集局部信息的局部方法相比,在本文方法中,模型和场景数据由一组稀疏的有向点表示,这些点(关键点)可以很容易地从输入数据中提取出来. 使用稀疏数据可以显著提高识别速度,并且不会降低识别率.
2.1 点对特征
点对特征描述了点云中2个定向点的相对位置和方向的关系. 在关键点集合任意选取2个点m1, m2且已知这2个点的三维空间坐标以及法向量n1, n2,如图1所示.
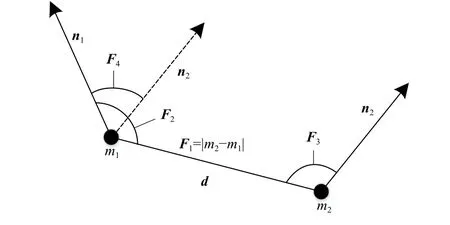
图1 点对特征示意图Fig. 1 Point-to-feature schematic
设d=m2-m1,并定义点对特征F为

该点对特征F是一个4维向量,其中第1个分量代表2个关键点之间的欧式距离,第2个和第3个分量分别为向量d与法向量n1,n2,之间的角度,最后一个分量是2个关键点的法向量n1,n2,之间的角度. 夹角规定在(0,π)之间.
2.2 全局模型描述符的构建
全局模型描述可以看作是从点对特征空间到模型的一种映射关系,对模型关键点集合中的任意点对 (mi,mj)∈M2计算其特征向量Fm(mi,mj). 对特征向量Fm(mi,mj)进行量化处理,建立哈希表. 设定距离采样步长ddist和角度采样步长θ=2π/n,其中n为角度量化的区间数. 如图2所示,将特征相同的点对存储在哈希表的同一个槽中,以特征向量Fm(mi,mj)为哈希表的索引键,而哈希表的值为特征相似的点对的集合,并记为A.

图2 全局模型描述Fig. 2 Global model description
哈希表也称为散列表,是根据索引键直接访问内存数据的一种数据存储结构,可以实现数据的快速搜索、插入和删除等操作. 将模型点云中量化的点对特征向量存储在哈希表中,以加快识别阶段的特征匹配搜索.
3 三维目标识别
三维目标识别过程见图3. 在离线阶段,创建全局模型描述. 在线阶段,只需要选择场景中的一组参考点. 将场景中的所有其他点与参考点配对以创建点对特征. 这些特征与全局模型描述中包含的模型特征匹配,并检索出一组潜在的匹配项. 通过使用有效的投票方案,对每个潜在对象姿态进行投票. 通过位姿聚类与优化,得到最佳对象位姿. 最后,通过配准将模型点云旋转平移到场景中,与待识别目标重合,判断点与点的欧式距离是否小于阈值,将目标点云中的点从多目标场景中分割出来.
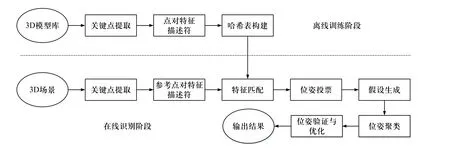
图3 目标识别过程Fig. 3 The process of target recognition
3.1 匹配策略
对于场景中的任意参考点sr∈S,假设该点是识别目标对象上的点,如果假设是正确的,则模型上一定会存在一个点mr∈M与之相对应. 通过平移和旋转使2个对应点及法线在空间中对齐后,目标对象可以围绕场景参考点sr的法线旋转一定的角度使模型和场景对齐,如图4所示. 因此从模型到场景的刚性变换就可以通过模型上的一个点mr和绕法线的旋转角α来描述. 称(mr,α)为模型相对于场景参考点sr的局部坐标. 模型到场景的转换公式如下
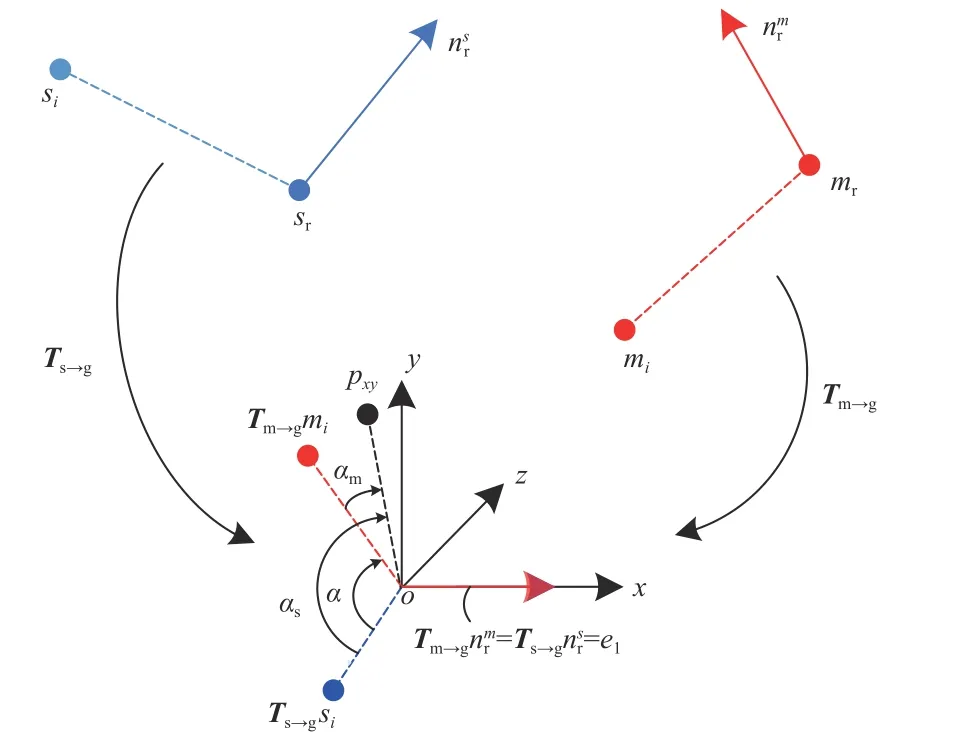
图4 模型和场景中的坐标变换Fig. 4 Coordinate transformations in models and scenes

式中:Ts→g和Tm→g分别为场景坐标系和模型坐标系到中间局部坐标系下的变换矩阵;Rx(α)为场景参考点si在中间坐标系下绕法线(即x轴)的旋转矩阵.
为了提高算法效率,加速对式(5)方程的求解,利用中间坐标系的x-o-y平面将旋转角度α 分成αs和αm两 部 分,其 中αs和 αm分 别 为 中 间 坐 标 系 下sisr和mimr绕法线(即x轴)旋转至x-o-y平面的角度,得到α=αs-αm, 由于匹配的特征点对具有相似的特征向量,所以当在同一坐标系下旋转至x-o-y坐标平面时,匹配点对应该是对齐的,因此式(5)中的Rx(α)可以根据式(6)分解为
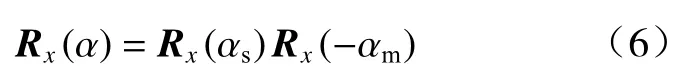
可以得到

式中pxy位于中间局部参考系下的x-o-y平面上. 无论是场景还是模型中的点对,pxy都是唯一的. 同时为了加快算法速度,可以在离线阶段对模型上的点对事先计算出αm,并且一起存储在哈希表中. 在识别阶段只需要对场景中的参考点对(sr,si)计算αs,结合已知的αm便可计算出旋转角度α.
根据角度α,可以确定出模型点云到场景点云的变换矩阵,重复上述过程,可以得到多个变换矩阵,其中有一些是错误的,本文设计了基于快速投票的最优α的选择方法,继而计算出模型点云到场景点云的变换矩阵,获得目标的位姿.
3.2 基于快速投票的目标姿态估计
对于投票过程,建立一个二维累加器数组用于统计每个参考点的得票数量,该数组的行数和列数分别记为Nm和Nangel,分别对应于模型点云中关键点的数量和旋转角度α量化的份数. 投票过程见图5.
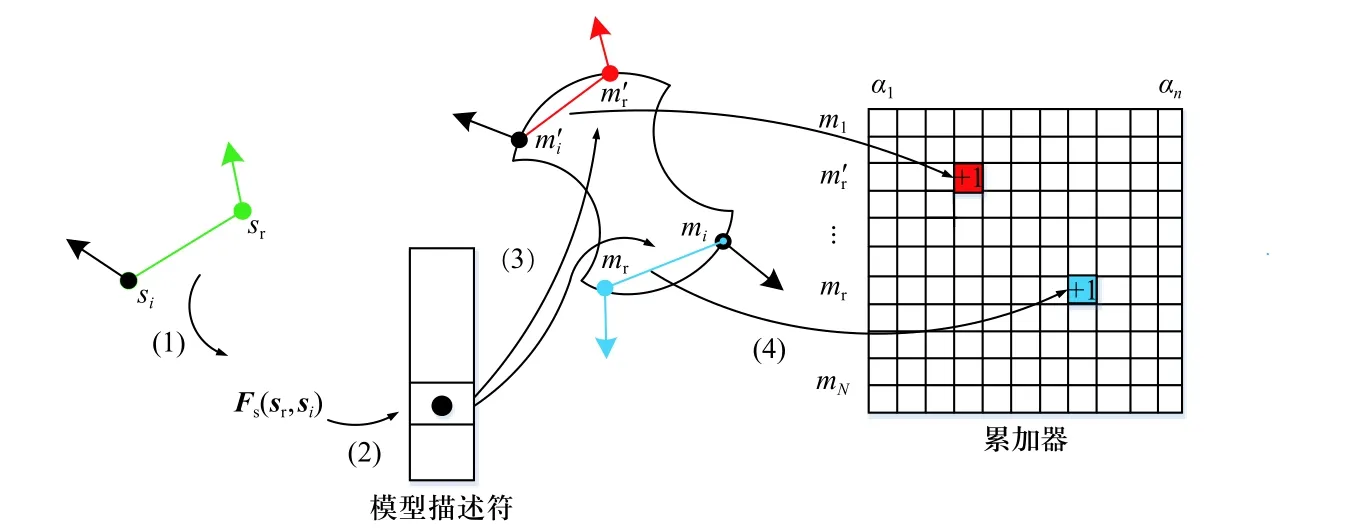
图5 快速投票示意图Fig. 5 Quick voting scheme
快速投票的具体过程如下:
① 首先选取场景中的某一关键点sr作为参考点,与其他所有关键点si∈S组成点对(sr, si),然后计算点对特征向量Fs(sr, si),并进行离散化处理.
②用离散化的特征向量Fs(sr, si)作为哈希表的索引键对离线阶段构建好的全局描述符进行搜索,返回与特征向量Fs(sr, si)相似的模型点对(mr, mi).
③根据对应点对的坐标转换关系计算出旋转角度α,并在预先初始化的二维累加器数组上对局部坐标(mr, αr)投票加1.
④遍历场景关键点集合中的所有点,对每一个关键点执行上述步骤.
每个参考点sr∈S都对应一个累加器,其中行对应于模型中的每个关键点,列对应一个将 [0 , 2π]等间距分成若干份后的角度值. 对与参考点sr组成的所有特征点对投票完成后,统计投票结果,峰值就对应于参考点sr的最优局部坐标. 根据最优局部坐标(mr,αr)及式(5)可以得到一个候选位姿变换[Rs, ts],Rs,ts分别表示模型点云到场景点云的旋转矩阵和平移向量. 遍历完所有场景参考点以后,会得到N个候选位姿变换,记位姿变换集合为C={(R1, t1), (R2,t2),….,(RN, tN)},式中N为候选位姿的个数. 获得候选位姿集合C后,需要通过后续的姿态优化才能确认目标的最终姿态.
4 位姿优化
如果选择的参考点正好位于目标物体的表面上,那么通过上述投票方案可以识别出目标物体并确定其姿态. 所以在进行投票时要多选择一些参考点,以保证目标物体上有参考点存在. 由于复杂场景中会有其他干扰物体存在,使得参考点只有一部分位于目标物体表面,为了获得正确的位姿,本文采用贪婪算法对候选位姿进行聚类,首先对位姿集合C中的所有位姿按照获得的投票数从高到低排列,选取集合中的第1个候选位姿作为第1个聚类中心,并记录其投票数量. 然后判断第2个候选位姿是否与聚类中心相似,若相似将其加入到对应的类别中,并更新投票数量;否则单独建立一个聚类中心,以此类推,对所有候选位姿进行相同处理. 判断位姿是否相似的计算方法如下

式中:p*为聚类中心的位姿;p为判断的候选位姿;trace表示迹运算;t和t*分别为p和p*中的平移向量;ε和δ分别为旋转矩阵的角度阈值和平移向量的距离阈值.
如果2个位姿满足式(8)即可判定为相似,属于同一类别. 候选位姿聚类处理完毕后,选取投票数量最多的类别,对该类别中包含的位姿求平均值作为最终的位姿. 尽管聚类得到的位姿与真实位姿非常相近,但仍然还有一些误差,本文使用ICP算法对结果进一步优化. 最后,根据优化后的位姿,将模型点云旋转平移到场景中,与待识别目标重合,判断点与点的欧式距离是否小于阈值,将目标点云中的点从多目标场景中分割出来.
5 实验结果及分析
进行相关实验,对本文方法进行评估,测试了算法的可行性、准确度以及鲁棒性. 实验中使用图6所示点云,以及一些人工合成的点云数据. 实验中设置点对特征向量量化参数ddist=0.05DM,其中DM为模型的直径,θ=2π/n,其中n= 30;姿态聚类参数ε=π/6、δ=0.2DM. 本文实验是使用Microsoft Visual Studio 2017编译环境在Win10操作系统上实现的.
图6 模型数据Fig. 6 Model data
5.1 实验结果
图7为半身像模型点云关键点提取结果,从图7中可以看出,模型点云经过关键点提取后,数据量明显较少、密度明显降低. 为了便于观察,将关键点标记为蓝色并且放大4倍显示.
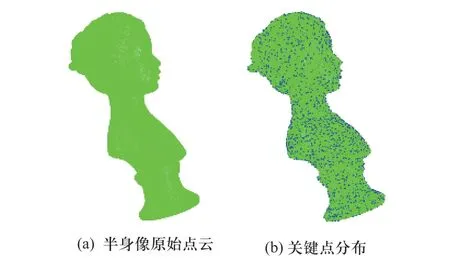
图7 关键点提取结果Fig. 7 Down-sampling results and key point extraction results for the point cloud bust
图8给出了半身像模型在不同场景下的识别结果.为了便于显示观察,将上述场景标记为浅绿色,场景中识别出的目标物体标记为深红色,并用实心蓝色框标记出来. 从图中可以看出,简单场景中的遮挡和重叠为5%~10%,而中等场景和复杂场景中的遮挡和重叠为10%~20%,尽管这样,利用本文算法依然能够将目标准确识别出来,并且具有较好的识别效果. 对于同一目标分别在不同复杂程度场景下进行多次实验,定义识别率等于正确的识别次数除以总的识别次数,统计实验数据得出不同模型在不同场景下的识别率如图9所示,4种模型在简单场景下的平均识别率可以达到95%以上,中等场景下的平均识别率也能达到90%左右,但在复杂场景下椅子模型的识别率要明显低于显微镜、鞋和半身像模型,这是因为椅子的模型表面比较平滑,点对特征相似的比较多,容易出现错误匹配. 表1给出此次实验结果参数.
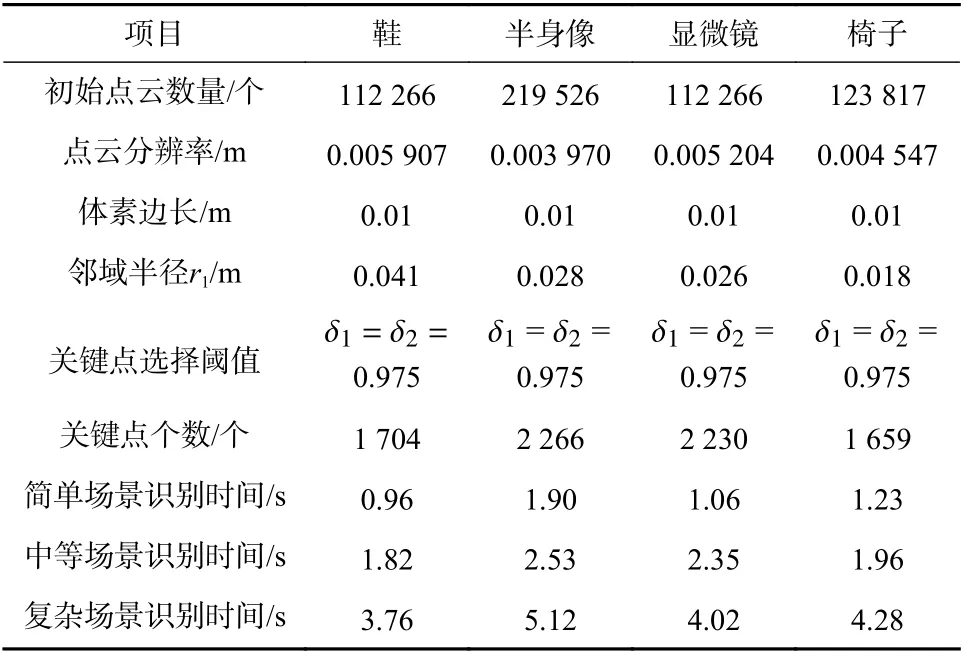
表1 基于关键点的点对特征三维目标识别算法实验参数Tab. 1 Experimental parameters of point-to-feature 3D target recognition algorithm based on key points

图8 不同场景下的目标识别结果Fig. 8 Target recognition results of bust in different scenarios
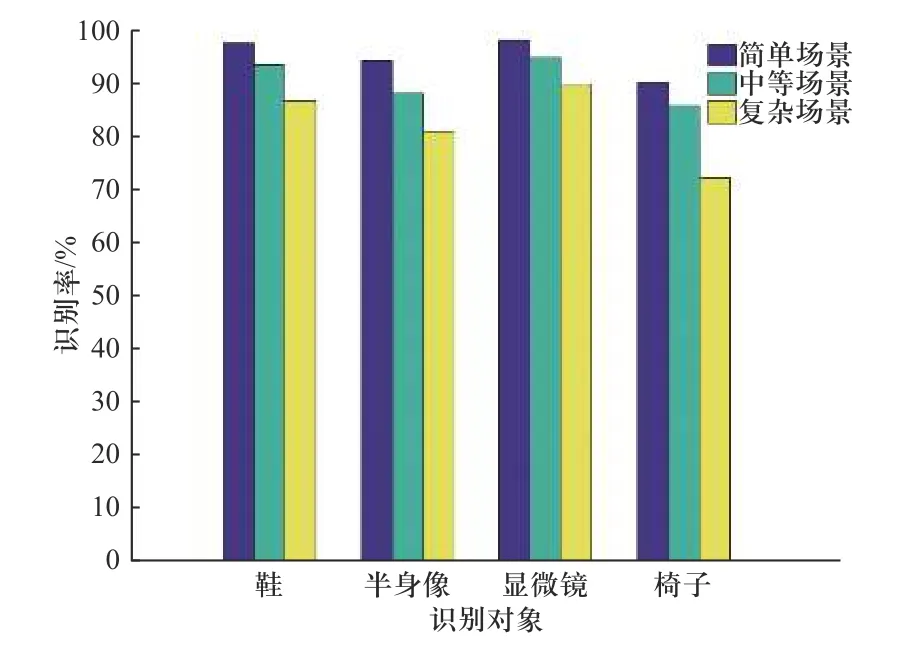
图9 不同模型在不同场景下的识别率对比Fig. 9 Comparison of recognition rates of different models in different scenarios
5.2 实验分析
①关键点选取实验分析.
根据第1节介绍的ISS关键点提取算法,本文选取阈值δ1和δ2为0.975. 以显微镜模型点云为例进行分析,图10为显微镜模型点云在不同邻域半径下的关键点分布情况,图11为关键点邻域半径与关键点数量以及关键点提取时间的分析情况,从图中很容易看出,当阈值一定的情况下,随着邻域半径逐渐增大,关键点数量逐渐减少,但是关键点的提取时间却变长,由于本文的描述符是一种基于点对特征的全局描述符,必须依靠足够多的关键点来形成点对特征为后期进行投票使用,如果关键点数量太少,后期形成的点对特征就少,投票结果误差会比较大,从而影响识别率,但是如果关键点数量太多,会导致后期匹配搜索时间过长,从而影响识别速度. 综合考虑显微镜模型点云选取适当的邻域半径为0.026 m. 其余模型点云分析方法类似.
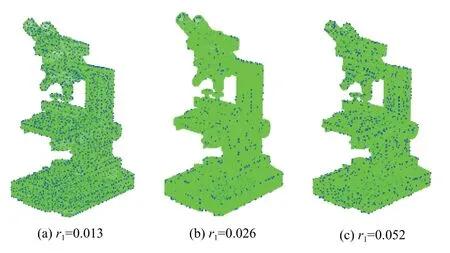
图10 不同邻域半径下关键点分布图Fig. 10 Distribution of key points at different point neighborhood radius
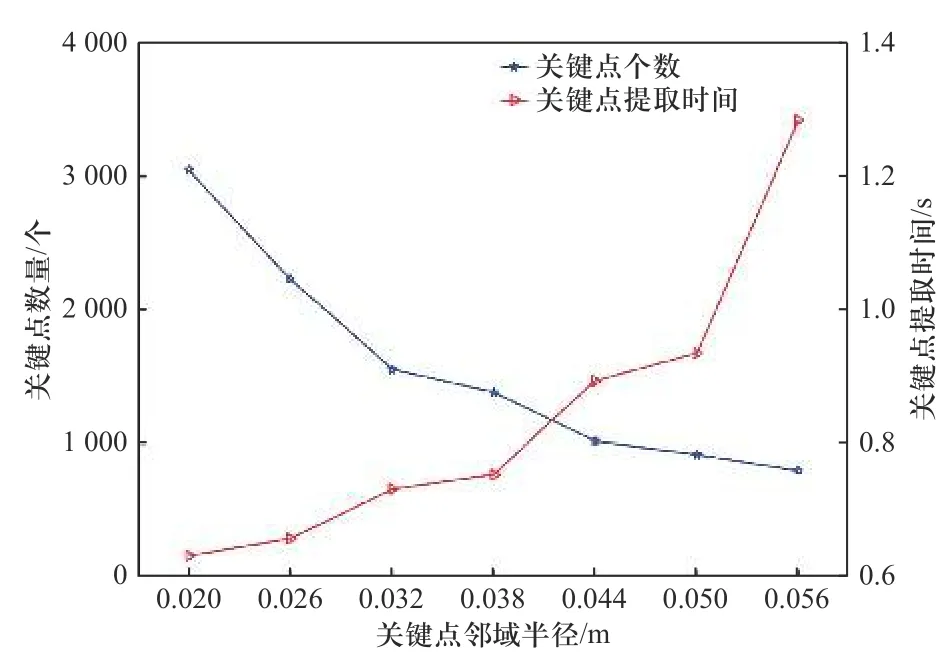
图11 关键点邻域半径与关键点数量和提取时间的关系Fig. 11 Relationship between the radius of the key neighborhood, the number of key points, and the extraction time
②对比实验分析.
为了证明本文设计的算法更具优越性,与原始点对特征算法进行了对比实验,图12给出不同目标模型使用两种算法分别在简单场景、中等场景和复杂场景下的识别时间对比结果(由于算法的识别过程分为离线训练和在线识别两个阶段,所以不包括离线建立模型特征库的时间). 表2给出两种算法在不同场景下的识别率对比结果,可以看出,本文算法与原始点对特征算法相比,识别率略有提高,但在时间方面,本文算法明显加快,主要原因是提取的关键点,使得在匹配阶段以及候选位姿生成阶段中与场景点对匹配的模型点对更可靠而且数量更少,加速了投票过程,提升了算法的整体效率.

图12 不同场景下两种算法的识别时间对比Fig. 12 Comparison of recognition time of two algorithms in different scenarios

表2 两种算法在不同场景下的识别率比较Tab. 2 Comparison of the recognition rates of the two algorithms in different scenarios
③噪声实验与分析.
为了分析本文算法对噪声的鲁棒性,对构建的数据集分别加入10%、20%、50%随机噪声进行实验,以鞋模型点云为例,图13展示了鞋模型在不同程度噪声的复杂场景下的识别结果,可以看出随着噪声的增加,识别效果会受到一定影响,但是即使高达50%的随机噪声情况下,依然能够将目标物体准确识别并框选出来.

图13 添加不同程度随机噪声识别结果Fig. 13 Adding different levels of random noise recognition results
图14给出不同算法的对比结果,从图中可以看 出,本文算法对噪声的鲁棒性最好,即使在50%的噪声情况下,识别率依然可以达到70%以上,综合实验结果说明本文算法对噪声具有较强的鲁棒性.
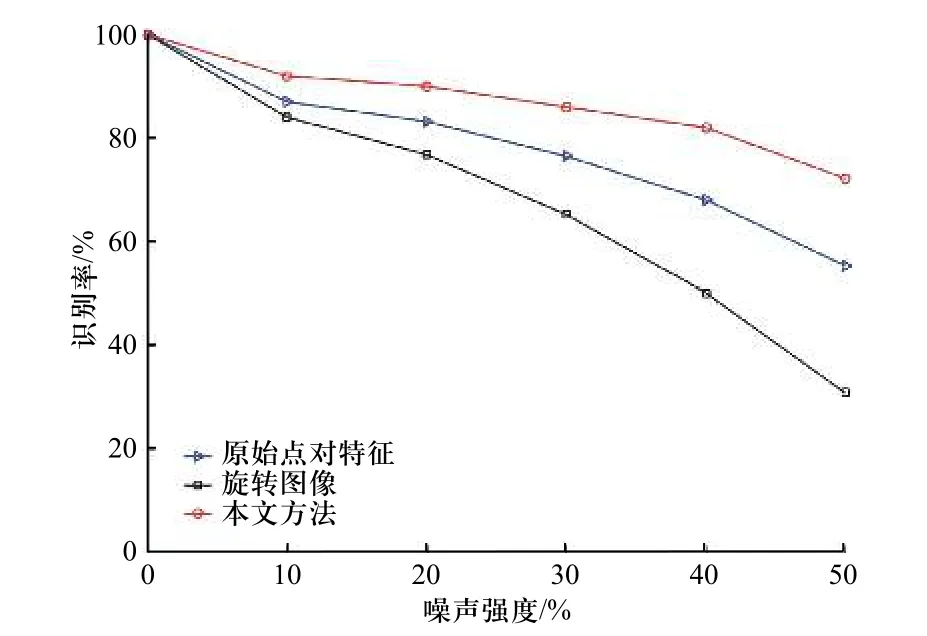
图14 不同程度噪声下目标识别率对比Fig. 14 Comparison of target recognition rates under different degrees of noise
6 结 论
本文设计了一种基于点对特征的识别算法. 首先使用分布较为均匀的ISS算法提取关键点并构建关键点集合,在关键点集合中对任意2个关键点构建点对特征向量,在不影响识别率的情况下减小了搜索范围,提高效率以减少识别时间. 将特征向量按固定步长量化存储在哈希表中以构建全局描述符,利用快速投票方案对模型点云和场景点云进行匹配识别,并生成候选姿态,利用贪婪算法对候选位姿进行聚类与筛选,利用ICP对物体姿态进行优化,根据配置结果,实现目标识别. 实验证明本文设计的识别算法计算复杂度低,识别速度快,同时保持了良好稳定的识别精度.
猜你喜欢
中学生数理化·中考版(2022年12期)2022-02-16 07:36:56
今日农业(2021年8期)2021-11-28 05:07:50
金属加工(冷加工)(2020年11期)2020-11-24 08:58:20
测控技术(2018年5期)2018-12-09 09:04:24
精密制造与自动化(2018年1期)2018-04-12 07:42:50
光学精密工程(2016年5期)2016-11-07 09:05:55
光学精密工程(2016年4期)2016-11-07 09:05:11
设备管理与维修(2016年5期)2016-03-16 02:20:46
湖北工业大学学报(2016年5期)2016-02-27 13:14:48
中国卫生(2014年2期)2014-11-12 13:00:16
