
机器学习的著作权困境及制度方案
2022-03-21 01:57:04徐龙
东南学术 2022年2期
徐 龙
随着人工智能时代的到来,机器学习技术不断发展,越来越多的“作品”(1)人工智能生成内容是否构成作品是另一个问题,国内外已有相当多学者对此进行了讨论。因本文不涉及该问题的讨论,不宜作出判定,故下文称其为“内容”“成果”“结果”。参见徐龙:《论人工智能创作之法律属性与保护》,《东吴法律学报》2021年第1期。通过机器学习诞生。从《贝拉米画像》《阳光失了玻璃窗》到《I AM AI》等智能“作品”的问世,机器学习已广泛运用于绘画、文学、音乐等诸多创作领域,在交易市场中获得认可。同时,人工智能创作已不再专属于大型企业,个人也可以借助开放性或授权性人工智能平台,通过机器学习进行创作。机器学习技术的发展颠覆了人类对创作规律的认知,也对现有的法律制度造成冲击。机器学习可以快速、大量地生成包含输入作品特征的新内容,且在市场上获得良好反馈。这让人不得不思考,现行著作权制度框架下,机器学习是否构成著作权侵权,其造成的不利影响能否得到规制?若现行法无法有效规制,应当如何对著作权人予以保护,兼顾著作权人利益和科技发展应用,实现社会效益最大化?目前,学界关于机器学习的研究主要集中在其生成内容的可著作权性,以及小部分学者的研究涉及输入阶段的大批量复制行为,却不曾关注到批量复制的后续使用行为是否应当受到著作权法规制。为此,笔者将从机器学习对创作者的影响,机器学习的著作权侵权分析、制度困境及其出路等方面进行分析,并提出解决方案。
一、机器学习及其对创作者的影响
(一)机器学习
通常来说,机器学习就是由人类设计初步算法模型,通过输入数据信息,并使得算法模型在数据训练中不断优化,并生成反映输入数据特征值的输出内容的过程。其技术过程大致可分为三个阶段(如图1所示):输入阶段,将选定数据样本导入(input)初始模型,供算法学习与训练;训练阶段,通过算法模型学习样本数据的内在逻辑关系,提取特征值,逐步优化和改进算法并完成指令;输出阶段,在前两个阶段的基础上,通过算法程序对数据的学习评估模型并预测结果,最终输出(output)相应内容。

图1 机器学习阶段构成图
依照是否有表达性内容的输出,可将机器学习分为“表达性机器学习”(expressive machine learning)和“非表达性机器学习”(non-expressive machine learning)。(2)Sobel, Benjamin L .W., “Artificial Intelligence’s Fair Use Crisis”, Columbia Journal of Law & the Arts,2017,41(1),pp.45- 49.“非表达性机器学习”指没有表达性内容输出的机器学习。如人脸识别系统,虽然开发过程中涉及对大量人脸图像的复制,但其目的不是为了生成表达性内容,而是为了完善人脸识别算法。这种没有表达性内容输出的机器学习,并非本文的研究对象。“表达性机器学习”指有表达性内容输出的机器学习,即通过输入作品数据供算法学习,并生成具备作品集特征的表达性内容。其作品数据可以来源于不特定的多位作者,如2019年微软小冰举办的“或然世界”画展,其训练数据来源于过往400年艺术史上236位著名画家的画作;也可以来源于某一特定作者,如2014年微软公司与荷兰国际银行合作开发的“下一个伦勃朗”,其训练数据来自于画家伦勃朗的346幅画作,机器通过分析学习其绘画风格如颜色、服装、主题、人物、构图等特征,最终生成类似伦勃朗的画作,(3)Shlomit Yanisky-Ravid, “Generating Rembrandt: Artificial Intelligence, Copyright, and Accountability in the 3A Era”, Michigan State Law Review,2017(4),pp.659-663.再如巴黎索尼计算机科学实验室开发的“深度巴赫”,其训练数据来自于音乐家巴赫的352首乐曲,最终输出了巴赫风格的音乐共2503首,测评中超过一半的听众误认为机器输出的音乐是巴赫本人创作的作品。(4)Ga⊇tan Hadjeres, François Pachet & Frank Nielsen, “Deepbach: A Steerable Model for Bach Chorales Generation”, Proceedings of the 34th International Conference on Machine Learning,2017,pp.1362-1371.这种有表达性内容输出的机器学习即是本文所要研究的对象。
(二)机器学习对创作者的影响
随着人工智能时代的来临,模仿他人创作手法、风格已经不需要经过人类辛苦且漫长的学习和思考,也不需要亲自动手创作,而只需将作品数据输入人工智能算法进行机器学习即可高效实现。相较于人类作者学习和模仿创作时的费时费力,人工智能生成表达性内容的高效,会对被学习作品的相关市场产生竞争甚至替代效果,产生侵占甚至取代原作市场的风险。创作风格、手法等特征是作者鲜明个性的体现,往往经过不断摸索、淬炼而成,作品的潜在市场和价值与之息息相关。精心创作而成的作品刚刚发表,他人便可肆无忌惮地利用机器学习快速、大量地生成特征相似的内容,对原作品的潜在市场和价值以及作者的创作热情所造成的影响是难以估量的。
有学者认为,若机器学习的作品来源于某一特定作者,则机器的输出内容会对原作品的潜在市场产生替代效果;若其学习的作品来源于多位作者,则机器学习的是不同作者间通用的大众化表达,其输出内容不会对原作品的潜在市场造成影响。(5)李安:《机器学习作品的著作权法分析》,《电子知识产权》2020年第6期。其实,不论其学习的作品来自一人还是多人,其输出内容都可能对原作品的潜在市场和价值造成影响。因为机器学习所利用的内容是每一个作品的全部表达,包括其特有的独创性表达,而并非只针对其中通用的大众化表达。通过对不同作者作品的学习,机器学习的生成内容有可能同时呈现多个作者的表达风格。相比于再现某一特定作者风格的作品,含有多个作者风格的作品可能会对相关市场造成更大的影响。试想一下,原本身处同一领域的知名作者之间并不常出现合作,多位知名作者强强联手的情形往往只存在于粉丝们幻想的情节中;现在,通过机器学习便可让现实生活中粉丝们不敢想象的事情变成可能,这必然会对原作品市场产生影响,甚至其影响更甚于对特定作者风格的模仿。
与此同时,若允许通过机器学习肆意生成具备他人作品特征值的新内容,久而久之将可能导致人类作品市场被大型人工智能公司所垄断,因为任何一个先前作品都可以通过人工智能算法快速学习,大量生成类似的成果,甚至包含多个作者风格特点的超越性成果。掌握资本、数据和算法的大型公司通过垄断优质算法和数据,将可能侵占和挤压人类创作的市场空间,以至于人类创作萎靡,影响文化艺术和人类精神文明的繁荣。
二、机器学习的著作权侵权分析
鉴于机器学习所导致的不利影响,有必要从著作权法上对其展开讨论,研析现行著作权法框架下机器学习是否构成侵权,能否对其作出有效规制。
(一)可能涉及的著作权行为
1.输入阶段
在输入阶段,算法程序无法像人类一样通过阅读来获取信息,而必须仰赖数据的输入,且需要将作品信息转化为算法可读的数据格式,包括对非数字化作品的数字化和对数字化作品的拷贝。我国《著作权法》第9条明确数字化属于复制行为,认为复制权是指“以……数字化等方式将作品制作一份或者多份的权利”。输入作品数据的行为客观上制作了一份或者多份复制品,属于“复制行为”。同时,在监督学习(6)监督学习(supervised learning)是机器学习的一种。在监督学习中,需要对数据进行分类、标注,再用标注的数据进行模型的训练。中,工作人员需要在输入前对数据进行标注(labels),如在猫脸图面识别算法中对数据进行“是猫”或“非猫”的标注,使得算法根据标注的数据进行训练。监督学习中对作品数据的标注行为,其实是一种对作品数据的“改编行为”。此外,监督学习还需要工作人员对作品数据进行整理和汇总,且所有机器学习都涉及对作品数据的选择。监督学习对作品数据集合中的数据选择、整理和汇总,可以视为一种“汇编行为”。
2.训练阶段
在训练阶段,机器学习也可能伴随临时副本的生成,涉及临时复制。临时复制件是客观技术现象的产物,没有被利用与传播的独立经济价值,不属于著作权法意义上的复制行为,对此不作赘述。
3.输出阶段
一般情况下,机器学习的输出内容不涉及改编。即便是同人作品也必须以原作内容为基础,是基于原作的人物关系和人物设定上所做的改编。相反,所谓的“人工智能作品”实际上是通过对输入的作品数据进行解码、学习,在算法模型下生成的反映数据特征值的内容。创作风格、手法等特征属于思想范畴,不受著作权法保护。对创作风格、手法等特征的模仿和融合等实质性利用,都不构成对原作品的改编。当然,在算法存在严重缺陷且训练数据极少的极端情况下,有可能出现输入作品和输出内容构成实质性相似的情形,但这种极端情形不是机器学习所要追求的目标,不作赘述。
机器学习过程中具有著作权法意义的实际上只有输入阶段的“数据处理”行为(data processing),包括对作品数据的复制行为、监督学习中对作品数据的改编以及汇编行为。对于输入阶段的后续作品使用行为(训练、输出阶段行为),并不在现行著作权法的制度目标内,无法直接对其调整。
(二)著作权例外的分析
我国的著作权例外规定为法定许可与合理使用。虽然现行法律并未设置相关的法定许可,但合理使用制度仍可使机器学习输入阶段的数据处理行为免于侵权风险。
从学理上看,输入阶段的数据处理行为属于转换性使用,满足合理使用“四要素”和“三步检验法”的判断。实务中“三步检验法”往往结合“四要素”作判断,而“四要素”中最重要的当数“行为性质和目的”以及“对原作品潜在市场和价值的影响”。一是输入阶段的数据处理行为目的具有转换性,符合转换性使用。美国法院在“谷歌图书馆案”中认为,为图书检索而大规模数字化扫描的行为,具有不同于让公众阅读内容的原始创作目的,属转换性使用。(7)Authors Guild v.Google Inc., 954 F.Supp.2d.282(2013), affirmed by 804 F.3d 202(2nd Cir.2015), cert.denied, 136 S.Ct.1658(2016).论文查重、法律数据库涉及的数据复制行为也有类似判决。(8)A.V.v.Iparadigms.LLC., 562 F.36 630, 633 - 644 (2009); Edward White v.West and Lexis, No.12 Civ.1340 (JSR) (S.D.N.Y.Jul.3, 2014).机器学习输入阶段的数据处理行为也不同于原始创作目的,其对作品数据的复制、标注、整理汇总不是为了让公众获取并阅读复制品、改编或汇编作品,而是为了让人工智能算法对作品数据进行机器学习并生成内容,属于转换性使用。二是输入阶段的数据处理行为不会对原作品潜在市场和价值造成影响。输入阶段的数据处理行为仅是机器学习的内部行为,并未就该处理结果(复制品、改编作品、汇编作品)对外使用。复制、改编或汇编行为所控制的结果也未直接表现在最终输出内容上。输入阶段行为不等同于机器学习本身。后续的算法训练和内容生成并不是输入阶段的数据处理行为所控制的内容。机器学习所复制的作品数据仅是针对输入作品样本的一次复制甚至临时复制,且并未就该复制品进行对外商业性使用,不会对原作品造成影响。改编与汇编的情形亦同。因此,输入阶段数据处理行为的结果并未对外界使用,该特定情形不会影响原作品的正常使用,也不会损害著作权人的合法权益。
从制度上看,新修订的《著作权法》为输入阶段的数据处理行为提供了合理使用的制度空间,国外对此专设的著作权例外则进一步佐证其合理使用的正当性。一是《著作权法》第24条增设兜底规定并引入“三步检验法”,为其构成合理使用提供制度空间。此前,最高人民法院的指导性意见就主张在“四要素”基础上结合“三步检验法”进行判断。(9)最高人民法院《关于充分发挥知识产权审判职能作用推动社会主义文化大发展大繁荣和促进经济自主协调发展若干问题的意见》(法发〔2011〕18号)第8条指出:“在促进技术创新和商业发展确有必要的特殊情形下,考虑作品使用行为的性质和目的、被使用作品的性质、被使用部分的数量和质量、使用对作品潜在市场或价值的影响等因素,如果该使用行为既不与作品的正常使用相冲突,也不至于不合理地损害作者的正当利益,可以认定为合理使用。”我国司法实践中也有不少判决突破了穷尽式列举的限制,将法定情形之外的行为认定为合理使用。(10)北京市高级人民法院(2013)高民终字第1221号民事判决书;上海知识产权法院(2015)沪知民终字第730号民事判决书;广州知识产权法院(2017)粤73民终85号民事判决书。因此,只要输入阶段的数据处理行为满足“四要素”及“三步检验法”,即可认定构成合理使用。二是相比于“四要素”和“三步检验法”判断的不确定性,域外国家制定了更加明确具体的规定。日本2018年修订的《著作权法》第30条之四第2项将“信息分析”规定为著作权例外,(11)日本『著作権法(昭和四十五年法律第四十八号)』第三十条の四第二項。并于第47条之五规定了三类“轻微使用”,为产生新知识新信息而利用计算机进行信息检索、信息分析并提供结果,或其他利用计算机处理信息产生新知识新信息并改善公民生活便利的行为,信息处理者可对他人作品进行必要限度的复制或向公众公开。(12)日本『著作権法(昭和四十五年法律第四十八号)』第四十七条の五。欧盟议会2019年通过的《数字单一市场版权指令》第4条规定,以文本和数据挖掘(text and data mining)为目的,对合法获取的作品或其他内容进行复制与提取的行为属于著作权例外。(13)DIRECTIVE (EU) 2019/790 OF THE EUROPEAN PARLIAMENT AND OF THE COUNCIL of 17 April 2019 on copyright and related rights in the Digital Single Market and amending Directives 96/9/EC and 2001/29/EC, https://eur-lex.europa.eu/legal-content/EN/TXT/PDF/?uri=CELEX:32019L0790&from=EN (last visited 2021/8/10).德国、(14)Gesetz über Urheberrecht und verwandte Schutzrechte, https://www.gesetze-im-internet.de/urhg/UrhG.pdf (last visited 2021/8/10).英国、(15)The Copyright and Rights in Performances (Research, Education, Libraries and Archives) Regulations 2014, https://www.legislation.gov.uk/ukdsi/2014/9780111112755 (last visited 2021/8/10).法国(16)LOI n° 2016-1321 du 7 octobre 2016 pour une République numérique (1), https://www.legifrance.gouv.fr/loda/id/JORFTEXT000033202746/ (last visited 2021/8/10).等也对非商业性的数据处理行为做出了著作权例外规定。这些专门的著作权例外规定,进一步佐证了输入阶段数据处理行为构成合理使用的正当性。
综上,现行著作权法无法对机器学习所造成的不利影响作出有效规制,仅输入阶段的数据处理行为有著作权法意义,且满足合理使用,不构成著作权侵权;输入后续阶段的行为,则不在著作权法规制目的范围之内。
三、著作权制度困境及机器学习权之创设
(一)机器学习的著作权制度困境
随着机器学习技术的不断发展,人机合作的创作模式已逐渐成为常态,从腾讯Dreamwriter大量生成新闻报道到个人利用GPT-3生成各类作品,(17)Tom B.Brown et al., “Language Models are Few-Shot Learners”, arXiv:2005.14165 [cs.CL22 Jul 2020], https://arxiv.org/pdf/2005.14165.pdf (last visited 2021/8/6).作品创作已经从过去的人类自然创作模式逐渐转变为人机合作模式。然而,依据现行著作权法,输入阶段的作品数据处理行为应属合理使用,机器学习并不构成著作权侵权,无法得到有效规制。究其原因,是在机器学习的过程中,只有输入阶段的作品数据处理行为(包括复制、改编、汇编)才具有著作权法上的意义,受到著作权法的规制,之后的数据训练以及内容生成并不在著作权法调整范围内。机器学习的不利后果正是由于输入数据后的行为所致。输入作品数据之后,人工智能通过学习数据集的内在逻辑关系,输出了包含作品数据特征的新内容,对原作品的潜在市场和价值产生不利影响。这种对作品特征(主要指创作风格)的高效模仿或多种风格的融合性模仿,并不在现行著作权法立法和规制目的范围之内。不论是欧盟《数字单一市场版权指令》中的“文本和数据挖掘”行为,还是日本著作权法中的利用计算机处理信息产生新知识新信息的行为,都只是将其作为一种现行著作权的例外情形来加以规定,并未注意到机器学习本身对人类自然创作规律的颠覆。造成机器学习制度困境的原因就是著作权法关于机器学习这种新事物的空白和缺失。
目前学界关于机器学习的讨论基本都集中在“复制”上,(18)吴汉东:《人工智能生成作品的著作权法之问》,《中外法学》2020年第3期;张金平:《人工智能作品合理使用困境及其解决》,《环球法律评论》2019年第3期。而忽略了机器学习的核心并非“复制”,而是“学习”和“生成”,即能够快速、大量地生成具备输入作品特征值的新内容。法律制度和理论研究的双重空白,使得解决机器学习的著作权困境愈发紧迫,理论和实务都应当对此作出应对。
(二)新型著作权的提出——创设机器学习权
机器学习不同于复制、改编或汇编。企图通过复制权或其他著作权来调整机器学习对著作权人的不利影响是不现实的。诚然,机器学习输入数据时必然涉及复制,但该复制行为仅仅只是输入阶段的内部行为,不会对外界产生影响。要想使得输入数据的后续行为受复制权规制,就必须进行扩张解释,将复制后使用复制品的行为视为复制行为的延续。但这种做法并不可行,因为它会不正当地扩张复制权的含义,使复制权和其他著作权的边界变得模糊。复制行为和复制后利用复制品的行为,不论在客观事实还是著作权法含义上都是不同的。复制是对作品内容的原样再现。复制作品数据后,再利用算法训练和输出内容的行为,已经超出了复制权的含义。换言之,改编者在复制某一作品后,学习该复制品并进行改编,我们不能将后续的改编行为视为前期复制行为的内容。机器学习中的复制行为自然也不包含后续的行为。同理,通过改编权或汇编权来规制机器学习也是不可取的,因为它们同样不延及后续的行为,并且改编或汇编行为仅仅发生在采用监督学习算法的少数情况下,并不必然发生在所有机器学习中。
机器学习不同于以往任何一种著作权法意义上的作品使用方式。虽然其初始阶段可能涉及复制,少数情形涉及改编或汇编,但机器学习有着不同于复制、改编或汇编的内涵,即机器对过去作品创作风格的高效自动化模仿或融合性模仿的速度远超人类极限,会影响原作品市场和潜在价值,减损著作权人利益。在过去,受制于“思想—表达”二分法的桎梏,对他人创作风格的模仿并不在著作权法规制目的范围之内,不构成著作权侵权。传统著作权法框架下,不论是复制权、汇编权、改编权或是其他著作权,都无法对其作出有效规制。因此,为避免机器学习对原作品潜在市场和价值的不利影响,保障著作权人的利益,有必要针对机器学习这种新型作品使用方式设置一项新的著作权进行规制,未经许可不得对新发表的作品进行表达性机器学习。
四、机器学习权的制度设计
(一)权利主体
机器学习权的权利主体应当是被学习作品的著作权人,一般情况下是被学习作品的创作者。机器学习权设置的首要目的就是保障被学习作品著作权人的利益,避免其作品的潜在市场和价值受影响。被学习作品的著作权人权益因机器学习受到侵害时,有权请求加害人承担侵权责任。
(二)权利内容
机器学习权所要保护的是著作权人在一定期限内对其发表的作品进行表达性机器学习的排他性垄断权利。因此,机器学习权的内容应当是未经著作权人许可,不得随意对其作品进行表达性机器学习。
(三)权利限制
1.权利限制的理由
若机器学习作品都需要事前授权,则会产生较高的交易成本,抑制人工智能产业发展。机器学习需要输入大量作品数据,包含在保护期内和已过保护期的作品。若需要一一识别数据的版权状况,并向权利人请求授权,无疑会大大增加交易成本。就法律经济学而言,交易成本是对著作权进行限制的重要理由。过高的交易成本会阻碍人工智能在创作领域的应用和技术发展;过于严苛的著作权保护则会减少可供机器自由学习的作品,有可能引发算法偏见。著作权保护会增加高质量作品数据的获取难度,使人工智能训练者倾向于选择“获取限制较低但带有偏见的数据集”(biased, low-friction data)来训练算法,譬如已过保护期处于公共领域的作品。训练算法的数据不充足、不完整,将可能导致算法偏见甚至出现歧视。(19)Amanda Levendowski, “How Copyright Law Can Fix Artificial Intelligence’s Implicit Bias Problem”, Washington Law Review,2018,93(2),pp.582-584.
著作权法一直都是一部利益平衡的法律,在保障著作权人权益的同时兼顾科学技术的发展。所以,在赋予著作权人对其作品进行表达性机器学习权利的同时,为避免高昂交易成本及可能出现的算法偏见风险,有必要对机器学习权作出适当限制。
2.权利限制的内容
在时间上,对机器学习权设置为期6个月的权利衰减期,对于发表或连载完结已满6个月的作品进行权利限制。机器学习权设置的目的是为了保护被学习作品的潜在市场和价值不受影响,保障创作者权益,因此在制度设计上应充分考量作品的市场和价值因素。自进入互联网时代以来,作品传播迅捷、高效,市场上充斥着各种各样的作品。在这个资讯爆炸的时代,热度是影响作品市场的重要因素,受众要从成千上万的作品资讯中作出选择,其考量因素除了自身需求等主观因素外,客观世界对作品的关注和热度是一个重要的评判标准。作品的热度代表着其受众的数量和市场,代表着流量和经济利益。各大文化艺术领域的创作者或公司为了获得更大的市场,更是绞尽脑汁地希望其作品及相关周边产品尽可能地挤上所谓的“热搜”“热榜”等热门榜单,成为大众关注的对象。一个新发布的作品之所以会因机器学习而影响其潜在市场,是因为机器学习的生成内容会分散读者市场对原作品的关注和热度。纵观当下各大作品流量榜单,各类作品发布后在榜单上的持续时间都相对较短。以音乐作品为例,一般情况下,很少有音乐作品能在榜单上维持超过十几周的时间,特别优秀的也不过半年左右。就算是连载作品,如连载漫画、小说,当作品完结后,其市场关注热度也逐渐下降,很难维持超过6个月。因此,鉴于机器学习和互联网作品传播的特性,相较于其他著作权,机器学习权获得完全保护的时间应当相对较短,新发表不久的作品不被机器学习的保护需求较强,著作权人应当获得完全的保护;作品发表或连载完结一段时间后热度下降使其保护需求相对减弱,此时科技应用和发展的利益更值得被保护,权利应当受到弱化衰减。具体来说,以新作品发表的热度持续时间为参考因素,初步建议可对机器学习权设定为期6个月的权利衰减期,即对于发表或连载完成时间未满6个月的作品,未经权利人许可,他人不得随意对其进行机器学习;对于发表或连载完成后6个月的作品,表达性机器学习的排他性垄断权利受到限制,权利衰减。
在方式上,对于发表或连载完成后6个月的作品,法定许可他人可以对其进行机器学习。相比于合理使用,法定许可更能实现机器学习中各方的利益平衡。法定许可制度既保证了人工智能研发者可以大规模使用作品,又对著作权人的利益给予了充分尊重,弥补了权利限制对其利益的损害,能够最大程度地平衡各方利益,在激励文化艺术创新的同时保证科学技术的发展,实现交易成本最小化与资源配置的效益最大化。为此,建议对机器学习权采用法定许可进行限制,对于发表或连载完成后6个月的作品,法定许可他人可以对其进行机器学习。在法定许可的具体费用计算和收取上,可通过完善著作权集体管理制度和引入区块链技术来实现。
具体而言,第一,应当完善著作权集体管理,建立市场化分类收费机制。针对声音、图像、文字等不同艺术表现方式分类设定标准,由著作权集体管理组织代为收取报酬。在费率的设置上,应考虑被学习作品的市场价值、生成内容的市场价值以及被学习作品占作品数据集合的比重等因素。第二,引入区块链技术,完善机器学习作品数据使用的透明度,建立机器学习数据使用公开和审核制度。机器学习的隐蔽性较强,常常在脱机状态下完成,现有制度框架下著作人很难发现其作品被用于机器学习,并进行相应的维权。为此,可以考虑引入区块链技术,以区块的方式将作品数据进行固定,并以密码学方式保证其不可篡改和不可伪造。(20)中国电子技术标准化研究院等:《中国区块链技术和应用发展白皮书(2016)》,http://www.199it.com/archives/526865.html。一旦作品在区块链平台上发表,与之相关的使用情况都会被完整、详细地记载在分布式账本中,以便追踪作品使用情况及确定许可费用。对此,最高人民法院《关于加强著作权和与著作权有关的权利保护的意见》第2条指出:“允许当事人通过区块链等方式保存、固定和提交证据,有效解决知识产权权利人举证难问题。”与此同时,要求人工智能作品发布前需将机器学习的作品数据集公开并提交著作权集体管理组织审核,由专门机构对机器学习的作品数据中是否有发表或连载完成未满6个月的情形予以审核确认(详见图2)。
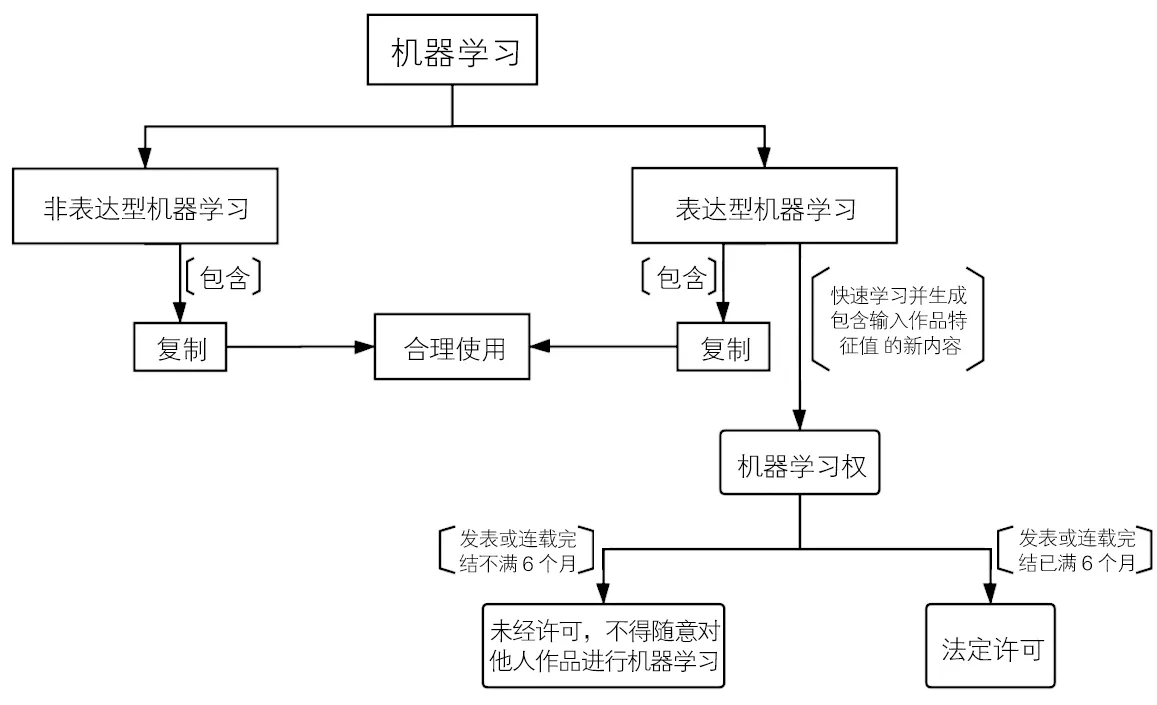
图2 机器学习权制度设计图
五、结 论
机器学习的发展,令包含被学习作品特征值的新内容可在短时间内被快速、大量地生成,减损著作权人利益,甚至可能导致少数大型企业通过对优质算法和数据的垄断,挤压普通创作者的创作空间。对此,现行著作权法无法有效规制,仅输入阶段的数据处理行为有著作权法意义,涉及复制(主要情形)、改编或汇编,且满足合理使用,不构成著作权侵权;后续阶段的批量化学习以及风格模仿或多种风格融合性模仿行为,却并不在传统著作权法规制范围之内。
面对机器学习引发的制度困境,有必要针对机器学习这种新型作品利用方式创设新型著作权予以规制。权利内容为未经著作权人许可,不得任意对他人作品进行表达性机器学习。同时,为避免过于严苛的著作权保护阻碍科技的创新和进步,对于发表或连载完成已满6个月、保护需求较弱的作品,法定许可他人可以进行机器学习,并完善著作权集体管理制度,建立市场化分类收费机制,引入区块链技术,建立机器学习数据公开和审核制度,以确保权利人能够顺利获得报酬,在激励创作热情、保护著作权人利益的同时,兼顾科学技术的发展和应用,实现利益平衡和社会效益的最大化。
猜你喜欢
中国食用菌(2022年5期)2022-11-21 16:10:34
中国食用菌(2022年1期)2022-11-21 14:23:58
社会科学战线(2022年5期)2022-07-23 07:04:28
环球时报(2022-07-13)2022-07-13 17:18:39
环球时报(2022-03-14)2022-03-14 18:19:44
电影(2018年8期)2018-09-21 08:00:06
知识产权(2016年4期)2016-12-01 06:57:54
知识产权(2016年10期)2016-08-21 12:41:06
小猕猴智力画刊(2015年4期)2015-04-28 23:55:53
天津造纸(2014年3期)2014-08-15 00:42:04
