
基于高分辨率遥感影像的土壤类型制图研究
2022-03-20 07:47芦倩赵维俊黄鑫
甘肃农业大学学报 2022年6期
芦倩,赵维俊,黄鑫
(1. 甘肃农业大学资源与环境学院,甘肃 兰州 730070;2. 甘肃省祁连山水源涵养林研究院,甘肃 张掖 734000;3. 甘肃农业大学管理学院,甘肃 兰州 730070)
土壤在人类生活及各项农业生产活动中发挥着不可替代的作用,是重要的自然资源。人们通过传统的土壤调查认识土壤,获取土壤信息,并且借助常规绘图工具完成土壤制图。这种方法不仅工作周期长,而且耗费大量人力,无法保证数据时效性,使制图准确性受到影响。近年来,随着信息技术、地理信息系统及遥感技术、卫星导航定位技术的快速发展,数字土壤制图逐渐表现出其优良的制图能力。数字土壤制图是基于土壤⁃景观模型,借助地理信息系统中的空间分析方法和数学规则,模拟出土壤类型和不同属性在空间上的分布情况[1]。根据土壤⁃景观模型相关理论及五大成土因素理论,土壤的性质与气候、地形、母质、时间、生物等因素密不可分,因此数字制图将这些环境因素作为协同变量,辅助制作土壤类型图、土壤性质图等。
数字土壤制图研究发展迅速,基于环境协同变量构建的土壤类型或土壤性质制图模型层出不穷。诸如神经网络模型[2-3]、广义线性模型[4-5]、分类回归树模型[6]等。赵明松[7]基于地理加权回归方法构建土壤有机质空间模型,发现该模型在大尺度区域更具优势,并且相较传统的全局回归模型,建模结果精度更高。任丽[8]等选择随机森林模型对苹果区土壤有机质含量进行预测,发现该方法在研究区适用。杨煜岑[9]等人通过多元线性回归预测方法,将研究区不同的环境影响因子进行筛选建模,最终对土壤养分进行了空间预测,并得到较为理想的结果。过往的研究也表明神经网络模型的构建结果不易解释,不能得到较为理想的结果。广义线性模型的使用主要考虑土壤属性和环境因子在非正态分布状态下。决策树的基本思想是分类与回归。它可以依据样本数据通过建立分类规则来构建决策树模型。韩浩武等[10]通过决策树算法构建了土壤⁃环境关系模型,基于模型实现了研究区的土壤类型预测,结果精度较传统土壤图有明显提升。决策树算法众多,如ID3,C5.0,CART 等,可提供多种选择进行研究,其分类精度高,可读性强,而且速度较快。因此被广泛应用在各个领域,如水质监测[11]、生态环境预测[12-14]、土壤属性制图[14-16]等。此外还有支持向量机、专家知识模型等方法运用在数字土壤制图中。
研究选择在祁连山排露沟流域开展。长久以来,该流域土壤调查工作大多基于传统的土壤调查方法,对土壤类型的分布研究多利用地形图及航片等资料进行判读,制图方法耗时耗力,制图精度不高。但土壤类型的研究一方面可以让人们直观认识其空间分布状况,另一方面影响着研究区土地利用、植被恢复和水土流失等。因此只有明确表达土壤类型在空间上的分布情况,才能够有效开展土壤资源的科学规划。本研究在研究区进行野外土壤采样,利用数字土壤制图方法绘制高精度土壤分类图,打破传统土壤制图方法的局限性,保证土壤数据的时效性,提高制图精度。基于高分辨率遥感影像数据及研究区数字高程模型,提取遥感光谱指数和地形因子等环境协同变量,采用C5.0决策树算法、CART决策树算法及支持向量机方法对研究区土壤类型分别进行高精度数字土壤制图,并对制图结果进行评价对比,旨在探索适用于研究区的数字土壤制图模型,为研究区土壤调查提供新的技术手段,对流域植被恢复和水源涵养提供空间数据支持和科学依据。
1 材料与方法
1.1 研究区概况和数据来源
排露沟流域(N 38°32′~38°33′,E 100°17′~100°18′,)位于祁连山中段西水林区,海拔在2 600~3 800 m 之间,纵坡比降1∶4.2,流域面积2.71 km2。该区属大陆性高寒山地森林草原气候。根据祁连山西水生态站多年统计资料显示,该流域年均气温-0.6~2.0 ℃;年均降水量291.3~453.8 mm,多集中在5~9 月;年均蒸发量1 081.7 mm;年均日照时数1 895 h;日辐射总量110.28 kW/m2;年均相对湿度60%[17]。研究中用到的DEM 数据来源于国家青藏高原科学数据中心,是从大野口流域1 m 分辨率的DEM裁剪获得。国产“高分二号(GF-2)”遥感影像数据分辨率为1 m,其不仅具有优越的空间分辨率,而且定位精度准确,对于排露沟流域这种小尺度研究区,选择高分辨率影像尤为重要。本次研究中遥感影像成像时间为2015年12月3日。
排露沟流域土壤类型主要有山地栗钙土、山地森林灰褐土和亚高山灌丛草甸土3类。在流域海拔2 700~3 300 m的阴坡和半阴坡区域,分布着建群种青海云杉,其土壤类型为山地森林灰褐土。草地主要分布在2 700~2 900 m的阳坡和半阳坡,土壤类型为山地栗钙土。流域高海拔3 300~3 800 m 的土壤类型多为亚高山灌丛草甸土。本次研究对流域内不同植被类型下的土壤进行采样。为了力求采样点分布均匀,并保证采样的合理性,首先基于研究区GF-2 数据对流域植被采用面向对象的高分辨率遥感影像分类方法进行分类。该方法能够最大程度地基于图像信息和目标划分地理对象,同时借助于光谱统计特征、图像形状、大小、影像纹理、空间关系等众多因素,进行高精度的对象分类。分类操作在eCogni⁃tion 8.7软件中完成,多次试验后,在影像分割时确定波段权重全为1,分割尺度为100,形状指数0.2,紧致度因子0.5。光谱差异分割进一步对相邻分割对象进行光谱特征分析,最终设定光谱差异最大值为70,有效避免了“过分割”现象。特征参数选择归一化植被指数NDVI和改进后的归一化水体MNDWI进行特征计算,最终借助面向对象最邻近法将植被类型分为青海云杉、灌丛、草地及裸岩四种类型,如图1所示。因高海拔地区地形复杂,常用的规则网格采样法实施起来难度较大,根据植被空间分布图和DEM数据,借助研究区《土壤志》等数据材料,采用非等间距不规则网格布点法,在不同高程、坡向上均进行了样点采集,并通过手持GPS记录了样点经纬度。其中,青海云杉林下共采集45个山地灰褐土类型样点;草地35个,为山地栗钙土类型样点;灌丛33个,为亚高山灌丛草甸土类型样点,共计113个采样点,其中80 个用于土壤类型制图,33 个用于制图结果验证。图1为样点分布图。

图1 采样点的空间分布Figure 1 Spatial distribution of sampling points
1.2 传统土壤类型图
排露沟流域面积较小,过去的研究中形成了大量的野外土壤调查文档数据,有关土壤类型空间制图的研究较少,因此研究区没有形成传统的土壤类型分布图。为了便于和后续研究中基于机器学习产生的土壤类型预测图进行对比,所以对研究区野外土壤类型采样点进行空间插值,基于克里金插值方法得到的图2作为传统土壤类型图,将在下文中和其他预测方法结果进行对比。
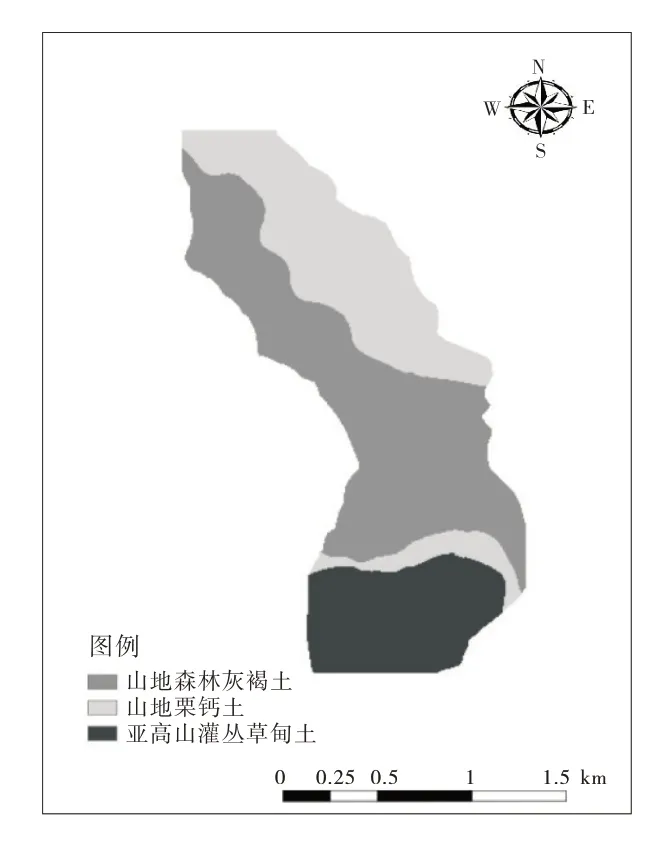
图2 传统土壤分类Figure 2 Conventional soil map
1.3 环境协同变量信息生成
不同的环境条件造就了各异的土壤属性。数字土壤制图中,影响土壤环境差异的地理变量可以辅助预测土壤性质的空间变化,这些变量即为环境协同变量[1]。母质、气候、生物和地形等因素都能够作为环境协同变量。土壤母质信息一般较难获得,因此研究中用地貌信息代替[1]。由于排露沟流域尺度较小,因此没有考虑气候因素,认为其影响是均质的,研究中主要借助地形因素来体现局域气候对土壤发育的影响。生物因素在文中主要通过流域内的植被来综合反映。综上,本次研究中环境协同变量的选择主要从影响土壤空间变化的强度及信息获取的难易程度这两方面考虑。首先,基于排露沟流域DEM 数据提取相关地形要素。包括高程、坡度、坡向、平面曲率、剖面曲率和地形湿度指数(TWI)。其次,根据GF-2 裁剪出的研究区遥感影像,计算遥感光谱指数。其中遥感光谱指数中的纹理特征能够表现研究对象自身的属性,所以在影像分类中起到关键的作用。环境协同变量的具体选取情况见表1。

表1 环境协同变量的选取Table 1 Selection of environmental covariates
1.4 基于C5.0算法构建决策树模型
1.4.1 环境协同变量筛选 根据采样点的空间分布情况,提取各个采样点上的环境协同变量信息,制作样本集。根据图3环境协同变量信息发现,流域内高差较大,且坡度坡向变化明显。平面曲率和剖面曲率也呈现出较大的地表变率,因此流域内地表物质运动过程明显,从而使土壤性质的空间异质性显著[18]。地形湿度指数反映了土壤水分的空间分布状态,距离研究区水系越近,其值越大。NDVI则表明流域内植被覆盖度较高。在众多环境协同变量中如何筛选出作用显著的变量还需要继续探讨。研究中通过逐步回归方法分析环境协同变量的重要性,其分析思路是判定全部变量对土壤类型的贡献大小,并按贡献大小顺序逐个代入回归方程,其中作用不显著的变量有可能被淘汰。为了保证新引入的变量参与判定,每一次进入方程计算后都要进行F检验,这样不断判定直到确定出各个变量的重要性。该过程借助Clementine 软件完成环境因子筛选,如表2,最终选出高程、均值、地形湿度指数、二阶矩和NDVI5种环境协同变量深入挖掘探索。

表2 环境协同变量重要性值Table 2 The important value of environmental covariates

图3 环境协同变量筛选Figure 3 Environmental covariates selection
1.4.2 数据挖掘 研究选用C5.0算法进行决策树模型构建,其构建方法可以从单一模型或者Boost模型入手。Boost 模型[19]的最大优势在于建模时能够对样本进行正确和错误的划分,并且予以赋值,在完成多个模型建立后,根据加权投票的结果,判定出精度最高的模型,而且可以对模型结果进行测试验证。但是在模型构建时,并不能完全使用其形成的规则,还要对其改进,这就需要对决策树进行剪枝修正,再次建模,直到模型可信度达到70%以上,即可停止建模。本次研究根据排露沟流域的相关土壤资料,结合基于C5.0算法构建的决策树模型,修剪建模规则,得到如表3的土壤分类推理规则。根据该规则进行土壤类型数字制图,如图4-A所示。

表3 推理规则Table 3 Inferenced rules
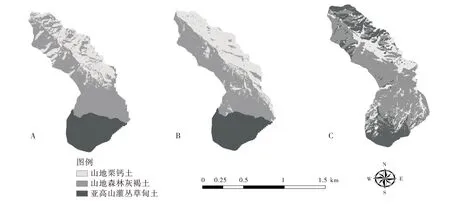
图4 不同制图方法下排露沟流域的土壤分类Figure 4 Soil classification map of Pailugou watershed with different mapping methods
1.5 基于CART算法构建分类决策树模型
分类决策树,是以树形结构对研究对象进行分类。在构建树的过程中,需要选择不同的变量作为构建节点,其中叶节点用来表示划分完成的一个类。通过分类决策树进行分类时,首先完成训练集的组成,这其中包括不同变量的属性和即将分类的类别,然后基于CART 算法建立各个变量之间的规则,最后确定出变量属性和类别的关系,即可完成分类。
CART算法构建决策树模型的核心是进行特征选择和剪枝。基于上述研究中的15 个环境协同变量,通过CART算法选择最优变量组合,并形成决策规则。通过自变量标准化重要性分析,最终筛选出高程、坡向、信息熵(entroy)3个自变量。CART规则树如图5所示,可以看出,该规则树将土壤类型作为根节点,高程变量将其分为2个子节点,分别为高程小于等于3 271.05 m和大于3 271.05 m,且在后者划分出部分亚高山灌丛草甸土。然后又基于坡向对前者进一步划分,在坡向值小于等于121.338°处划分出部分山地森林灰褐土,并对坡向大于121.338°处再次以坡向值划分,此时,当坡向值小于等于315.443 5°时,得到部分山地栗钙土。坡向值大于315.443 5°时,根据影像的信息熵(entroy)进行划分,在该值小于等于1.783时,划分出部分灰褐土,大于1.783时得到部分栗钙土。同时在构建过程中,为了防止过度拟合,研究中选择分割样本验证方法,随机选择70%作为训练样本用来构建模型,剩余30%则用来检验。最终分类结果如图4-B所示。
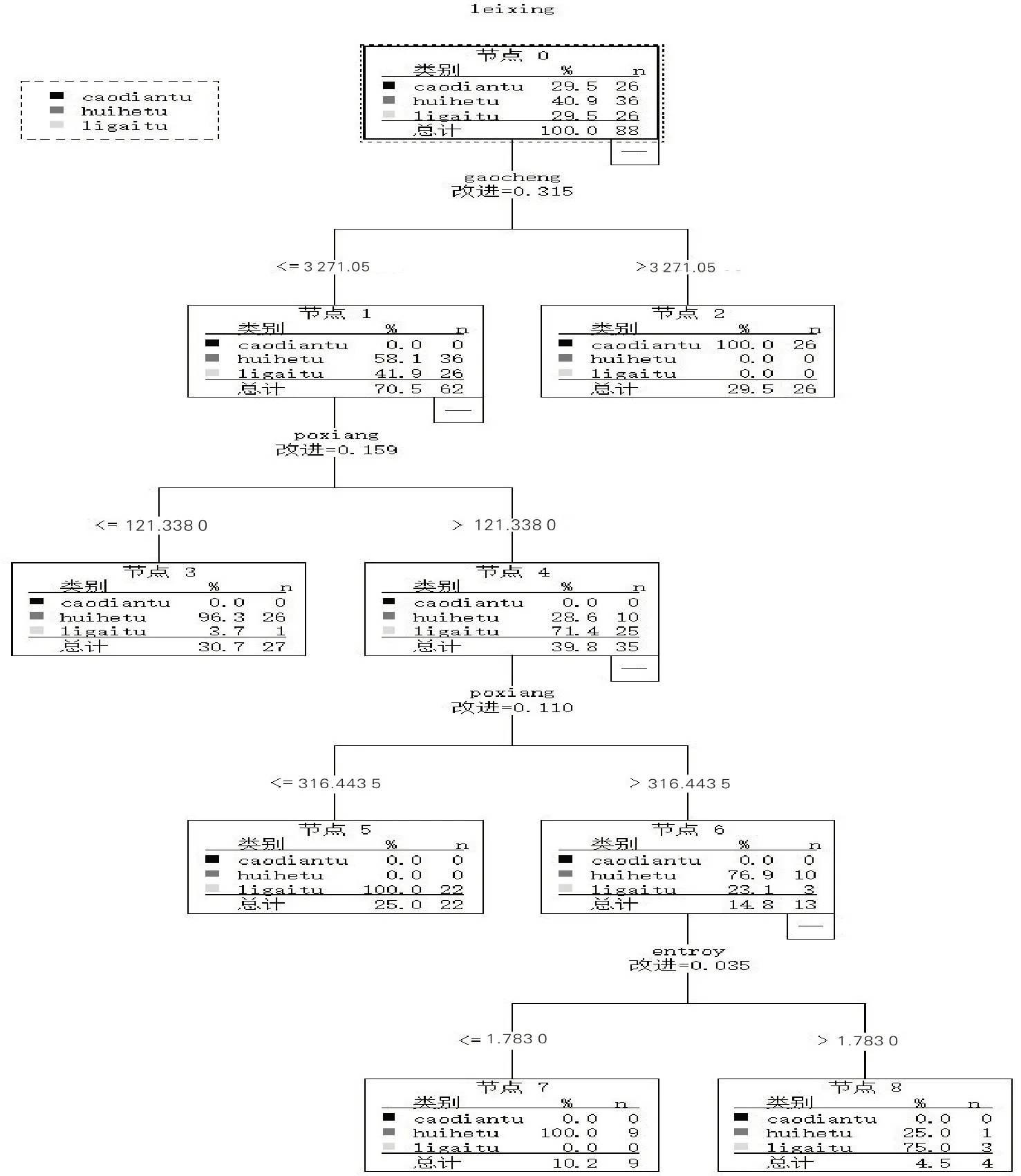
图5 CART规则树Figure 5 CART decision tree
1.6 基于支持向量机算法构建分类模型
支持向量机(Support Vector Machine,SVM)是一种机器学习算法。SVM支持线性可分,即在二维空间上,2类点可以被一条直线完全分开,从二维扩展到多维空间,SVM 力求寻找能够把2类样本分开的最大间隔,即最优超平面,这时两类样本被划分至该超平面两侧,即便距离超平面最近的两侧样本点也被距离最大化。SVM可以通过核函数进行分类,本次研究选择了核函数中的径向基方法,该方法中参数众多,其中惩罚因子C,在理论上表现出模型的精度随着C 值的增大而提高,但是也不能使该值过大,否则易造成模型的过度拟合,导致模型性能降低。支持向量机算法中参数的确定需要经过多次遍历优化后方可获得,研究中经过多次试验,最终获取的最优参数组合中,C值取值15。建模结果如图4-C所示。
2 结果与分析
2.1 制图结果与分析
通过图4可以看出,不同制图方法下,在流域海拔3 300~3 700 m的亚高山地带,土壤类型主要是亚高山灌丛草甸土。在流域海拔2 600~3 300 m 的阴坡区域,土壤类型多为山地森林灰褐土。在流域海拔2 700~3 000 m 的阳坡区域,分类结果存在差异:图4-A 中该区域土壤类型主要以山地栗钙土居多,伴随少量山地森林灰褐土;图4-B 中该区域则主要是山地栗钙土;图4-C 中该区域分布有山地栗钙土和亚高山灌丛草甸土。
2.2 精度评价
本次研究通过均匀采样选择的33 个野外采样点对不同制图方法下的土壤图进行精度评价,结果(表4)表明基于C5.0决策树制图结果精度明显高于采样点插值的结果。为进一步验证3种机器算法的制图结果,通过混淆矩阵计算得到的Kappa系数、生成精度和用户精度实现,结果如表5所示。由精度评价结果可以看出,C5.0 决策树分类方法总体精度为89%,Kappa 系数为0.83;CART 决策树分类方法总体精度为83%,Kappa系数为0.78;支持向量机分类方法总体精度为57%,Kappa 系数为0.52。由此可见,C5.0和CART 决策树分类方法得到的土壤分类结果较为满意,而支持向量机方法分类结果较差。

表4 不同制图方法下验证点精度比较Table 4 Comparison of the validation point accuracy among different mapping methods
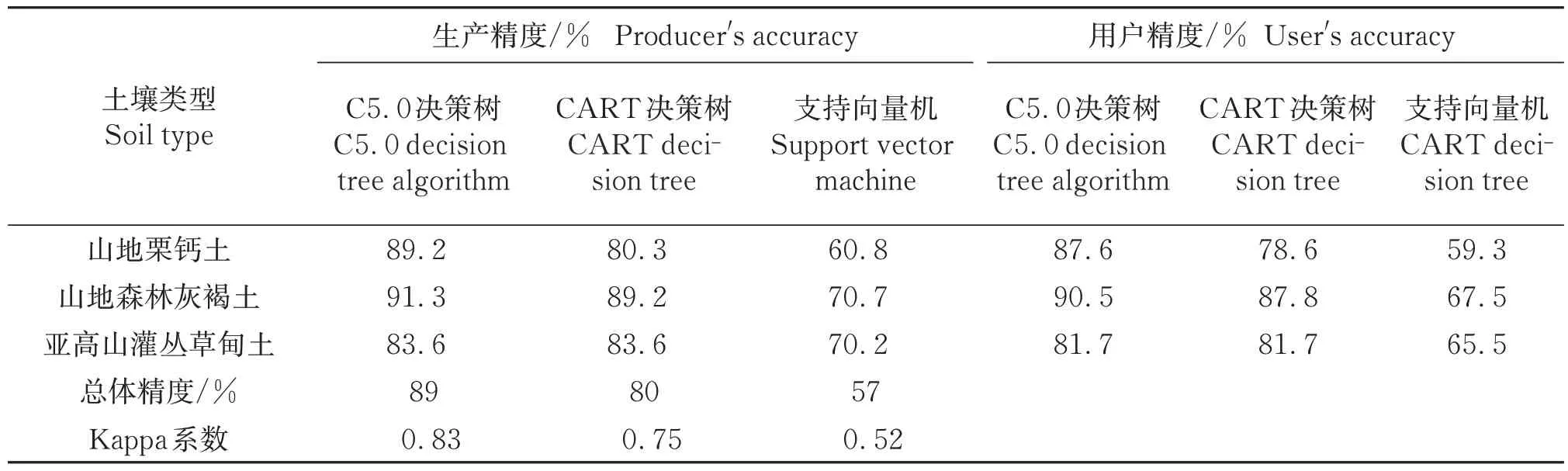
表5 精度评价Table 5 Accuracy evaluation
对比3种不同方法的精度评价结果,从整体上来看,3种方法下各土壤类型的空间分布具有明确的相似性,C5.0决策树的分类结果较CART 决策树结果的图斑数量更多,图上细节也更为清晰。尽管支持向量机分类结果图斑数增多,但是分类结果较差,在流域阳坡地带出现了较多的亚高山灌丛草甸土,和传统土地调查的结果有一定出入。生产精度方面,C5.0 算法和CART 算法分类结果中,3 种土壤类型的精度均比较高,支持向量机分类精度较低。用户精度方面,支持向量机分类精度较差。综上,3种方法都基于高清遥感影像获取的环境协同变量进行土壤⁃景观模型构建,并借助构建的模型对推理预测土壤类型的空间分布状态,但由于选取的数据挖掘算法不同,提取的环境协同变量也存在一定的差异,因此得到了不同的制图输出。通过精度评价,基于C5.0算法构建的决策树模型应用在排露沟流域的土壤分类图结果最佳。
3 讨论
数字土壤制图通常要经过选择环境变量、采集样点、构建模型及验证评价4个步骤。环境变量的选择要能够充分表达土壤的空间变化并且易于获取。Scull、Razakamanarivo、Sarkar[20-22]等人均采用了地形因子或土地利用信息作为环境变量来对土壤相关性质做空间预测。本次研究从地形因子和遥感光谱指数两方面入手,共选取高程、坡度、坡向及影像纹理特征等15个变量作为环境协同因子分析建模。建模过程中对变量重要性进行了分析,尽管引入了遥感光谱指数,但在最终选取的变量中遥感光谱指数参与度不如地形因子,在未来的研究中可以考虑将土壤理化性质作为环境协同变量参与制图。
本次研究中,土壤采样点的选择尽可能保证均匀分布在流域各个位置,但是受到流域地形的客观条件限制,采样点的典型性和一般性还有待继续探索。
研究中模型的选择主要考虑的是基于机器学习与数据挖掘的方法。这种方法主要探讨土壤类型和环境因子的关系,并建立相应的规则预测空间分布状况[23-27]。由于研究区面积较小,学者对土壤类型的分类研究大多基于传统野外调查数据[28-30],较少分析流域土壤类型的空间分布。本文比较了3种不同的基于机器学习的土壤类型空间制图方法,发现C5.0 算法对土壤类型的预测精度更高,更准确地表现了土壤类型与各环境协同变量间的关系,清晰直观地反映了流域土壤的空间分布状况,后续研究还可以探索其他数字制图方法,讨论流域土壤类型的多样性,为流域在植被恢复、水源涵养等方面的研究提供空间数据支持。
4 结论
本文基于决策树C5.0算法、CART 决策树算法及支持向量机方法分别构建土壤分类模型,并将其应用在祁连山排露沟流域。得到结论是,对比3种土壤类型分类方法,C5.0 决策树模型表现出较好的分类精度,总体精度和Kappa 系数均高于其他两种方法。本文在提取地形因子作为地理协同变量的同时,加入了遥感光谱指数共同参与模型构建,其中C5.0 决策树运用了比CART 决策树更多的遥感光谱指数,在一定程度上提升了制图精度。研究中基于C5.0算法构建的决策树模型,获取了明确的土壤—环境关系规则,该规则能够清晰表达排露沟流域各土壤类型的发育环境,增强了C5.0算法在研究区的可用性,提升了数字土壤制图的精度。在小尺度研究区,高空间分辨率的遥感数据更有利于获取与土壤空间变化相关的环境协同变量,对未来土壤普查工作的精细化提供一定的科学参考。
猜你喜欢
中国水土保持(2022年6期)2022-06-08
中国水土保持(2021年7期)2021-07-08
中国水土保持(2021年12期)2021-04-11
农村青少年科学探究(2021年11期)2021-02-24
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
水利规划与设计(2018年1期)2018-01-31
河南电力(2017年4期)2017-11-30
华东师范大学学报(自然科学版)(2017年1期)2017-02-27
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
