
基于情感词典的视频评论情感倾向分析研究
2022-03-18 08:08杨廉正翟天智
网络安全技术与应用 2022年3期
◆杨廉正 翟天智
基于情感词典的视频评论情感倾向分析研究
◆杨廉正1翟天智2
(1.中国人民警察大学研究生院 河北 065000;2.哈尔滨工程大学经济与管理学院 黑龙江 150000)
B站的诞生打造了一个由用户自发组建和养生的生态系统,丰富了人们的生活,其中强大的弹幕互动信息以及视频评论透漏出用户自己的价值观和文化多样性。本文针对其中的视频评论进行情感分析,主要是判断其中的情感倾向,即正面情感、负面情感和中性情感的判断。本文在原有的基础情感词典的基础上,对B站领域的情感词进行汇总和整理,构建出领域情感词典,并运用SO-PMI算法进行其中的情感倾向计算,实现了一个面向B站领域情感倾向分类系统。实验数据来源于数据堂,针对抗击肺炎专栏中的要点聚焦视频评论进行分析,由志愿者进行人工标注后进行实验验证,并能够取得较高的准确率,对B站视频中的情感分析进行了初步探索。
B站;情感词典;情感倾向;SO-PMI算法
1 视频评论情感倾向及研究现状
由于2020年初爆发的新型冠状病毒肺炎成为全国人民关注的焦点,众多社交媒体平台专门设立了肺炎项目的专栏,能够及时报道前线最新消息并为全国人民科普自我安全的防护知识。B站设立了抗击肺炎的专栏,不仅有疫情速报、现场探访等视频,还有小区追踪,能够根据用户的具体位置查看其城市小区的疫情分布。B站中的各种新闻报道,尤其是武汉部分社区UP主拍摄的Vlog,也引起了众多用户的不同声音,同时也存在虚假信息和造谣的传播可能会对社会层面产生重大影响。因此,从视频评论文本中获取用户的情感倾向,并将此应用于生活与工作有利于形成一种更大范围的共识。本文将对抗击肺炎的视频评论文本中的情感倾向进行分析,实现一个面向视频评论的情感倾向分析系统。
文本情感分析实际就是对文本信息中主观性内容的挖掘、处理并归纳,其中包含对物品或事件的评价,这其中掺杂了各种情感色彩,需要自然语言处理、计算机学习等多个领域的涉及,故近几年才推出了一些对于文本中信息研究的检索来推动文本倾向分析语料库的建设。
20世纪90年代末,国外的文本情感分析才开始研究,Riloff和Shepherd构建了基于语料库的语义词典[1],Hatzivassiloglou和McKeown尝试对英文词语做出情感倾向判断时考虑情感词的处理[2],Turney等运用点互信息法拓展基准词的情感词汇,然后用ISA算法分析情感倾向[3]。在近几年中,Miao研究了基于产品评论的文本情感分析,并做了特征级别的分析[4],Narayanan等对条件语句的分析做了研究,结合了各种特征以及对相关句子类别标注,收获了不错的效果[5]。
在国内,情感研究分析起步相对较晚,韩忠明等提出构建一个自动机来对短文本进行情感分析,周咏梅等采用了N-Gram方法进行分词,运用了SO-PMI的方法计算了微博文本情感倾向值[6]。在近几年中,闻彬、何婷婷等提出了基于语义理解的文本情感分类方法,赵妍妍等提出了基于语法路径的情感评价单元自动识别方法。总体来看,已经有许多优秀研究者对情感分析做了深入研究,但由于中文分词的特殊性使得中文研究相对于英文而言较复杂,目前还有很大的研究进步空间。
目前的文本情感倾向研究取得了较大的进展,多个情感倾向分析测评在国际上被推出。但随着互联网中越来越多用户的参与,其主观性的涉及面越来越广,研究人员依旧需要对此进行更深一步的探索。
2 相关专有名词介绍概述
2.1 哔哩哔哩弹幕视频网站(www.bilibili.com)
哔哩哔哩(简称B站)诞生于2009年,是一个用户粘连性很强的平台[7],凭借其强大的自身壁垒已成为国内最大的实时弹幕网站,并于2018年3月在美国纳斯达克成功上市。B站在年轻人眼中极受喜爱和欢迎,它独特的二次元文化社区吸引了海量用户,UP主进行二次创作使得B站在发展初期和中期占有了一定优势。与爱奇艺、优酷、腾讯视频等相比,B站是一个庞大的ACG文化集中平台[7],许多优秀的UP主持续输出优秀的作品,打造了一个由用户自发组建和养成的生态社区。在B站中用户可以自发创新出一些新的视频并保持在该平台的活跃度,这使得B站拥有了其他平台没有的强大用户流量。
B站的弹幕有着强大的互动性,不同的视频内容其弹幕数量不相同,实时发展的剧情推动弹幕的发展,用户在弹幕发表自己的看法和观点,时而表现出热情或吐槽,他们有着自己的文化和价值观,这是一种影响力,向外界发散着。他们利用自己的形式文化,以弹幕的形式来加固社群的归属感。
2.2 文本情感分析
文本情感分析技术[8](也称为意见挖掘)是指用自然语言处理、文本挖掘以及计算机语言学等方法来识别和提取原素材中的主观信息。文本分析按照其处理文本粒度[9]不同,可大致分为词语级、句子级和篇章级[10]。
在本文中我们主要采用词语级的情感分析方法,主要有:
(1)基于词典的分析方法,即建立情感词典,将要处理对象的情感词与情感词典中的情感词对比,并进行情感倾向的加权计算去判断该词语的情感倾向;
(2)基于网络的分析方法,即利用万维网查询信息,通过计算正负极性种子词汇之间的语义关联度判断出词语的情感分类;
(3)基于语料库的分析方法,即利用自然语言学习中的计算机技术判断情感倾向。
2.3 文本预处理技术
文本预处理技术是判断情感倾向的前提条件,不管在中文文本还是英文文本的情感倾向判断中这都极为重要,在自然语言处理中属于相对成熟的技术,对文本预处理的结果会影响我们去选择相应的文本特征,最终建立正确的文本模型。
对文本进行分词的过程是文本预处理的第一步,即删除那些没有明显情感倾向的词,然后对该文本标注出正面情感、负面情感或中性情感,利用计算机自动处理文本。总而言之,文本预处理就是分词、词性标注、去除停用词的过程,是判断文本情感倾向的前提。
(1)中文分词
在中文中以字为基本书写单位,但在一个句子中,若通常把一个字拿出来往往不能表达出完整的意义,通常我们认为能够表达语义的最小单位是词。中文分词指的是将一个或几个词语或是句子切分成一个个单独的词。一般在汉语写作中,词语之间没有明显的区分标记,分词不同会影响语句所表达的含义,如“不要用坏了”,和“不要用坏了”,因此文本分词对文本情感倾向性的研究影响很大。
(2)去除停用词
停用词[11]是指在信息检索中,为节省存储空间和提高搜索效率,在处理自然语言数据(或文本)之前或之后会自动过滤掉的字或词。停用词对文本情感倾向的判断没有影响,如“这”、“唉”、“啊”、“也”等。目前去除停用词的方法主要有两种,一是建立停用词表,将停用词在停用词表中进行比对和扫描,另一种是计算某一词语的文档频率,超过了一定阈值将其去除。
2.4 特征选择
特征选择是指从原句中选择带有明显的情感倾向的特征词,将选出的特征词构成特征子集并进行分类或者建立相应模型,特征子集中会扩展与其相似度比较近的特征词,这样能够使模型覆盖词语面积更广,提高计算效率,避免降维中歧义的出现。情感分类的特征选择实际上就是去除与停用词或是对情感分析意义不大的词语,找出与情感分类有关联的特征信息,通过筛选提高情感分析的准确性。在特征选择中,词频法、文档频次法、互信息法、信息增益法等都是比较常用的方法。
3 情感词典相关理论介绍
3.1 情感相关术语说明以及视频情感词典的构成
情感在心理学中的定义为“情感是人对客观事物是否满足自己的需要而产生的态度体验”,是我们主观的感觉和想法的表达[12],它与情绪不同,情绪是人对于自己的某种需求上的体验,而情感则指人对于社会需求上的态度体验。在B站上,用户看到某个视频发表自己的评论,可能表达赞赏或者吐槽,这就有了明显的情感倾向。
情感词是指带有情感色彩的词,分为正面情感词和负面情感词,词性不定,我们一般要判断一个句子的情感倾向时都会去找其中的情感词,如“开心”、“生气”、“羡慕”等等。
情感倾向是指情感词所表达的情感的方向和大小,它实际上是一种度量。我们在判断情感倾向时要考虑两方面,一个是情感倾向方向,即情感词所要表达的情感是正面还是负面;另一方面是情感倾向度,即情感词所表达情感的程度大小。所有情感词集合起来就构成了情感词典,情感词典又有褒义词典和贬义词典之分。
本文以B站为例,要构建一个面向B站的视频情感词典,不仅要对已有的情感词进行搜集和整理,还要建立一个视频领域中的情感词典。常见的英文情感词典有哈佛大学整理的GI评价词词典、基于认知语言学的WordNet。国内的情感分析研究处于萌芽阶段,故仅有部分实用的情感词典,目前有董振东先生开发的知网(HowNet);台湾大学整理的NTUSD;张伟、刘缙等编著的《学生褒贬义词典》;杨玲、朱英贵编著的《贬义词词典》以及史继林、朱英贵编著的《褒义词词典》。
在建立情感词典时我们需要大量阅读文献并进行人工标注,然后对情感词进行收集、分类和整理,非常耗时且费力。目前的通用方法是对大型语料库集进行统计分析,并通过人工标注选择具有明显情感倾向的代表性的基准词,然后对候选词和基准词进行一定的计算,归类并得到新的情感词,最终可以获得新的情感词典。在本文中,我们将构建一个面向视频评论的情感词典,主要组成结构如图1所示。

图1 视频情感词典组成图
3.2 基础情感词典
基础情感词典包括知网、NTUSD和其他情感词典。
3.3 视频领域情感词典的生成
建立视频领域情感词典要先选取基准词,首先选用B站中抗击肺炎栏目下的评论语料,将这些数据做文本预处理,并对词频统计排序,然后人工挑选褒义词和贬义词各20个,通过对这20对同义词扩展再得到20对,文献中提到,进行基于HowNet情感倾向实验时,准确率会随着基准词对数的增加而提高,若选用40对基准词时,准确率在81.37%,故我们选用了40对基准词。选用基准词的要求一定要保证情感词有强烈的情感倾向,并且出现的频率要足够高,为了避免个人的思维差异,我们选用了四名志愿者参与该工作,对于有异议的词语投票选择票数最高的作为基准词。
在视频领域情感词典的构建中,我们要用到SO-PMI算法来识别情感词:在文字预处理后选择情感比较强烈的词作为候选词,将它们与基础情感词典中的词扫描对比,若情感词典中已有该候选词,则结束实验。若情感词典中不存在该候选词,将候选词和早先选取的基准词进行SO-PMI计算,根据4.3节的计算结果判断候选词的情感倾向,然后将其归类,要注意舍去中性词语。
我们通过SO-PMI算法对B站中视频评论进行实验,将其中和基础情感词典重复的词语以及没有情感倾向的中性词语去除后,最终得到正面词语729个,负面词语806个,组成B站领域情感词典。
4 情感倾向分析研究
4.1 有情感词的情感倾向分析
根据第3章中情感倾向的概念,我们知道要衡量一个情感词的情感倾向,要从两方面分析,一是情感倾向的方向,另一个是情感倾向度。为了方便,我们将B站情感词典中的褒义词赋值为1,贬义词赋值为-1,首先来分析有情感词的情感倾向。
(1)否定词的分析
当一个正面情感词语前面出现了否定词,其情感倾向往往是负面的,比如“我一点都不开心”,“开心”是正面情感词语,而前面的“不”使其情感变成了负面的。但有时候有否定词也并不一定是负面情感,如看到了健身视频时会有评论说“我一点都不羡慕这样的身材”,虽然“羡慕”前面有了“不”这个否定词,但这条评论实则夸赞博主,针对这些情况要根据视频内容做相应的处理。
(2)程度副词的分析
程度副词的使用会改变其情感倾向程度,如“完全赞同楼主”,其中“完全”加强了正面情感。不同的程度副词修饰情感的强烈程度也不相同,中文程度副词中有最高级、更高级、比较级和较低级这四个级别,我们对不同级别的程度副词赋予不同大小的权值,如表1所示。
表1 程度副词表
量级权重举例个数 最高级2最、极其、绝对99 更高级1.75格外、出奇、太42 比较级1.5还、较、更加37 较低级0.5稍微、略显、不怎么41
(3)感叹词的分析
感叹句一般以句末感叹号为标志,它改变情感的倾向程度,一般表示用户表达情感的增强,本文将有感叹词的情感词设置为增强两倍的关系。在文本预处理后首先判断该句中是否有感叹号,如果有感叹号,在感叹号前找出距离它最近的情感词并将其权值乘2。
4.2 无情感词的情感倾向分析
在很多评论中,有时会有表情符号的评论,如用户通过[拇指]的表情来表达赞美,或者[发怒]的表情表达不满,还有些无情感词的疑问句也会带有一些感情色彩。我们将分为表情符号的分析和疑问句的分析。
(1)表情符号的情感倾向分析
B站平台提供了很多的表情符号,大多普通用户可选择,还有部分会员专用表情,虽然很多评论中很少只以表情符号来单独作为评论,但表情的加入使用户的评论充满了感情色彩,我们可以构建基于B站表情符号的情感倾向判别表并赋予不同表情符号权值。构建的情感表情符号如表2所示。
表2 B站表情符号情感表
名称权值个数表情符号内容 正面情感222[加油武汉][鸡腿][微笑][呲牙][星星眼][喜欢][大笑][惊喜][打call][点赞][鼓掌][奋斗][爱心][锦鲤][胜利][加油][保佑][支持][拥抱][老鼠][2020][福到了] 114[口罩][笑][OK][害羞][调皮][喜极而泣][偷笑][秒啊][滑稽][思考][墨镜][干杯][抱拳][响指] 负面情感-213[嫌弃][大哭][奸笑][阴险][灵魂出窍][疼][生病][吐][翻白眼][难过][抓狂][生气][跪了] -124[哦呼][酸了][无语][疑惑][捂脸][囧][呆][抠鼻][惊讶][哭笑][doge][吃瓜][尴尬][冷][委屈][傲娇][吓][嘘声][捂眼][再见][哈欠][撇嘴][怪我咯][黑洞]
(2)疑问句的情感倾向分析
疑问句分为一般疑问句和反义疑问句。一般视频评论中只有极少数一般疑问句,它所表达的仅是用户的疑惑,不带有情感倾向,就像陈述句多加了一个问号,故本文将这类句子判为中性句子,不存在情感倾向。而反义疑问句多用于强调,表达用户强烈的情感。如“怎么会不感动呢”能把用户的感动的思想表达得更鲜明。我们将“为什么”、“凭什么”、“怎能”、“何必”等等这类词称为反问标志词,将问号的权值设置为-2。不管是哪类疑问句它们的句末都会有问号标志,本文在处理疑问句的情感倾向问题时同处理感叹句相同,首先找到是否有问号标志,若有问号,向前查找是否有反问标志词,若有则将其权值乘-2,若无则寻找其他特征词。
4.3 情感倾向的加权计算
由于B站视频评论中不一定所有评论都是文字形式,可能会有带表情符号的评论或者不同词语修饰情感词的情况,为了方便计算情感倾向,我们将表情符号的情感倾向程度加入所建立的B站情感词典中。
经过文本预处理后的视频评论,先识别不同情感极性的特征词,根据4.2中是否有情感词的情况进行相应的处理,获取每条评论中特征词的权重,最后进行求和求出该句的情感倾向。
我们将视频评论以每句作为一个单位,若句子中有情感词被程度副词修饰时,可能会加大其情感倾向,同理,若句子后面出现感叹号也会加大其情感倾向。这时我们要计算它们的情感倾向权值,用到以下公式:
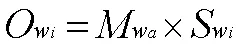
若有句子中的情感词被否定词修饰时,该情感词的情感倾向权值公式为:
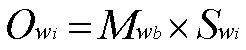
而每句中可能有k个情感词,故该句子的情感倾向度的计算公式为:
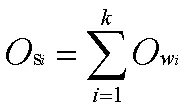
含有n个句子的评论的最终情感倾向公式为:

根据上述公式,我们得到的最终结果可能有三种情况:
5 情感词典分析的实验数据及结论
5.1 实验数据介绍
本文的数据是由数据堂提供,数据堂专注于数据采集,能够减少人工采集数据所需时间,提高实验效率。本文选用的测试数据来源于B站中的抗击肺炎的专栏中的最新要点聚焦视频共计6个,其中评论共计2389条。
首先选用6位志愿者,每人分别对2389条评论进行主观的情感倾向判断,让每人明确正面情感、中性情感和负面情感的句子,然后根据分类结果进行统计,为了避免个人的思维差异,每条评论以情感倾向支持票数最多的为准,最终结果为:正面情感数目1271条,中性情感数目532条,负面情感数目586条。
根据最终结果,我们发现各个评论在情感倾向上分布不算均衡,对于本文选取的视频,大多用户发表的正面情感倾向的评论居多。
5.2 实验性能评估指标
本文采用准确率和召回率这两个指标来分析。准确率p是正确的数目占其所属该类的比值,它反映了情感分类的准确性,计算公式为:

召回率是r判断正确的类别数目占应该判断为该类别的数目的百分比,它的计算公式为:

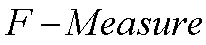


5.3 实验结果及分析
本文主要构建了B站领域的情感词典,介绍了有无情感词的处理方法以及SO-PMI算法,为了验证这些处理方法的效果,我们做了两组实验:第一组实验,我们要用到在第3.3节中构建的视频领域情感词典,在此基础上我们仅采用有情感词时的处理方法,得到表3所示结果。
表3 只对有情感词的情况进行处理的结果
评估指标正面情感中性情感负面情感 准确率p召回率rF1值0.6900.6820.6860.6310.8350.6930.7230.6660.686
第二组实验中,我们在第一组实验基础上,加入无情感词情况下的处理方法,得到如表4所示结果。
表4 加入无情感词的情况下处理的结果
评估指标正面情感中性情感负面情感 准确率p召回率rF1值0.7230.7180.7200.6750.8500.7520.7360.6880.711
通过实验得到结论:
(1)通过构建新的B站领域的情感词典,我们更容易判断每条评论的情感倾向,所建立的视频情感词典覆盖面越广泛,我们所得出的结论越精确。
(2)与原本的只考虑有情感词的情况下情感倾向判别相比,加入了无情感词情况的判别,准确率会有提升。
(3)通过赋予表情符号的权值,以及对有无情感词的一些特征词做相应的处理,能够避免一些有争议的判断,而在抗击肺炎的专栏视频中,大多评论的表情符号表现出正面情感。
(4)一些中性情感的判别准确率相对于其他两类而言不算太高,主要是由于不同的情感词在不同语境中表达的情感不同,一些情感词的出现可能导致普通的陈述句被判断为有情感倾向。
6 结语
本文主要针对B站抗击肺炎专栏的视频评论进行情感分析,并对情感领域的一些相关概念作了介绍,构建了B站领域情感词典,实现了面向B站情感倾向分析的系统,数据选用数据堂语料,并对人工标注的视频评论进行验证,取得了一定的效果。
[1]RiloffE,Shepherd J. A corpus-based approach for building semantic lexicons. in:Proceedings of the secong conference one mpirical methods innatural language processing[J]. 1997:117-124.
[2]Hatzivassiglouv,McKeownK R. Predicting the semantic orientation of adjectives. in:Proceeding the 35th annual meeting of the European Chapter of the ACL[D]. Morristown,NJ,USA: ACL,1997:174-181.
[3]Turney PD,Littman M 1. Measuring Praise and Critism Inference of Semantic Orientation from As sociation[J]. ACM Trans on Information Systems,2003,21(4):315-346.
[4]Qingliang Miao,Qiudan Li,Ruwei Dai. AMAZING:A sentiment mining and retreval system[J]. Expert Systems with Applications:An International Journal,2009,36(3):7192-7198.
[5]Ramanthan Narayanan,Bing Liu,Alok Choudhard. Sentiment Analysis of Conditional Sentences[D]. in:Proceedings of the 2009 Conference on EMNLP.Morristown,USA:ACL,2009:180-189.
[6]韩忠明,张玉沙,张慧,等. 有效的中文微博短文本倾向性分类算法[J]. 计算机应用与软件,2012,29(10):89-93.
[7]文蕾. 哔哩哔哩弹幕视频网站的使用与满足理论研究[D]. 西南交通大学,2016.
[8]魏慧玲. 文本情感分析在产品评论中的应用研究[D]. 北京交通大学,2014.
[9]李岩. 文本情感分析中关键问题的研究[D]. 北京邮电大学,2014.
[10]全湘溶. 中文评论多级情感分析系统的研究与实现[D]. 北京邮电大学,2015.
[11]马治涛. 文本分类停用词处理和特征选择技术研究[D]. 西安电子科技大学,2014.
[12]崔连超. 互联网评论文本情感分析研究[D]. 山东大学,2015.
2020-2021河北省社会科学基金项目(HB20MK027)
猜你喜欢
国际医药卫生导报(2022年18期)2022-09-29
消费电子(2022年6期)2022-08-25
疯狂英语·新阅版(2020年11期)2020-12-21
小天使·一年级语数英综合(2020年4期)2020-12-16
文苑(2019年24期)2020-01-06
文苑(2019年24期)2020-01-06
英语文摘(2019年5期)2019-07-13
大作文(2016年7期)2016-05-14
Coco薇(2015年10期)2015-10-19
传奇故事(破茧成蝶)(2015年7期)2015-02-28
