
基于系统调用的入侵检测技术研究
2022-03-18 07:45陈仲磊伊鹏陈祥雷靖玮孙重鑫
网络安全技术与应用 2022年3期
◆陈仲磊 伊鹏 陈祥 雷靖玮 孙重鑫
基于系统调用的入侵检测技术研究
◆陈仲磊 伊鹏 陈祥 雷靖玮 孙重鑫
(中国人民解放军战略支援部队信息工程大学 河南 450002)
如今网络攻击的多样性与低成本性以及攻击工具的齐全使得网络攻击日益泛滥。对于防御者来说,遭受一次攻击的损失是巨大的,防御和攻击的不对等使得防御方往往处于被动和弱势的地位。入侵检测技术通过模型学习勾勒网络入侵行为轮廓或正常行为轮廓,从而实现对入侵行为的识别与检测,实现对零日攻击的检测能力。本文是对基于系统调用数据上的入侵检测的综述性文章,重点介绍了系统调用数据的特征提取方法、入侵检测分类模型、应用场景,同时简单概括了系统调用的数据集与模型的评判标准。
系统调用;异常检测;入侵检测
2021年三月,西班牙警方破获一起网络金融诈骗案,由此揭开了一场席卷欧洲的银行木马攻击活动。犯罪团伙利用名为“FluBot”的安卓恶意软件伪造电子银行登录界面收集受害人电子银行凭证和信用卡详细信息。“FluBot”具有短信蠕虫机制,其将包含恶意软件下载链接的短信群发给受害者的联系人列表。2021年5月,美国主要成品油管道运营商之一科洛尼尔管道运输公司遭遇黑客攻击,其导致美国多个州和地区燃油供应面临危机,油价大涨。传统的计算机安全防护措施,如防火墙、身份认证等措施只能被动地进行防御,已经越来越满足不了如今计算机和网络安全发展的需要。因此,致力于提前发现各种攻击意图、攻击行为的入侵检测技术受到个人、公司与国家层面的高度重视。
入侵检测技术是网络安全领域十分具有挑战性的任务,有成长为未来数字时代设备安全防护主流技术的可能。入侵被定义为任何危害计算机资源完整性、机密性或可用性的行为。入侵检测则是通过从网络或系统中若干关键点收集信息,并对这些信息进行分析,以判断网络系统中是否存在攻击的迹象,即入侵行为的发觉。
基于系统调用的主机入侵检测是入侵检测的一个重要分支,其使用进程运行时产生的系统调用追踪序列作为主要的分析数据。系统调用是主机系统的内核函数,是程序和硬件设备之间的桥梁。分析进程系统调用数据能够实现对进程所有重要活动的总体感知,而不是关注于文件读取、性能开销、进程间通信等单一方面。系统调用函数工作在内核空间,其对于进程重要活动的感知相比于其他将更精确和细粒度。基于系统调用的入侵检测技术在数据预处理阶段面临着待分析数据冗余度高、数据量大、特征不明显的问题,其检测模型的误报率一直居高不下[1]。
下文在第一部分简单介绍了系统调用和入侵检测的背景知识,在第二部分详细描述了系统调用追踪数据的特征提取方法、基于系统调用的入侵检测技术常用模型和它的应用场景。第三部分简单介绍了常用的系统调用数据集和基于混淆矩阵的性能评判标准。最后一部分是对未来研究方向的展望。
1 背景知识
1.1 误用检测与异常检测
根据检测分析方法可以将入侵检测分为两类,即异常检测和误用检测[2]。
误用检测是基于知识的检测分析方式,它收集非正常操作的行为特征并建立相关特征库,当检测到的用户或系统行为与记录相匹配时,即认为这是入侵。误用检测具有以下特征:
(1)对已知的入侵行为进行建模;
(2)监督学习模型更适合用于误用检测;
(3)不能够检测未知入侵;
(4)检测误报率低,且对已知入侵具有高检测准确率。
异常检测则是构建用户的正常行为轮廓,当用户行为与正常行为有较大偏差时即被认为是入侵。异常检测具有如下特点:
(1)构造系统用户的正常行为轮廓;
(2)半监督或无监督学习模型更适合用于异常检测;
(3)对未知威胁依然具有检测能力;
(4)有较高的检测误报率,分类模型对检测的准确率影响较大。
1.2 系统调用
入侵检测根据检测所用数据源可以分为基于主机的入侵检测、基于网络的入侵检测和基于混合数据的入侵检测[3-4]。基于主机的入侵检测系统的数据来源主要是操作系统事件日志、应用程序事件日志、系统调用日志、端口调用数据和安全审计日志等。基于网络的入侵检测的数据来源则主要是网络上的原始数据包、数据流等。基于网络的入侵检测不依赖于主机,提供的是网络行为的入侵检测。
系统调用是主机系统用户态到内核态的接口,它并不同于应用程序调用接口(API)。系统调用数据包含系统内核特征,能直接反应进程对系统内核函数的调用过程。其收集于操作系统内核,是操作系统最原始和最细粒度的信息[5],根据进程的系统调用追踪序列可以有效构建进程或程序正常或异常行为轮廓,从而做到入侵的提早发现。Forrest在1996年首次提出通过对系统调用数据的分析发现异常并预警实现Unix系统的自我防御[6]。此后,基于系统调用的主机入侵检测技术逐渐发展起来。
系统调用函数设计的初衷其一是使内核态与用户态分隔以保证系统内核空间的数据安全,其二是为用户提供系统内相关功能,用户不必去了解某些功能的底层实现逻辑,减轻用户负担[7]。操作系统都是以系统服务的方式向上层提供服务的,即对上层提供本层的功能函数集合并将本层参数和函数进行封装。系统调用是内核态向用户态提供的功能函数,在Windows中主要封装在NTOSKRNL.dll文件中[8]。下面将系统调用在Windows系统下的调用流程作一个示例。如图1所示,应用程序在主机上运行,为某一功能实现调用应用程序接口(API)函数,应用程序接口函数内封装相关的系统调用请求号并发起系统调用请求,发起为系统调用特别开放的一个软中断(int 80h)并执行系统调用返回相关值。在这个过程中,应用程序及API属于用户空间而系统调用属于内核空间。
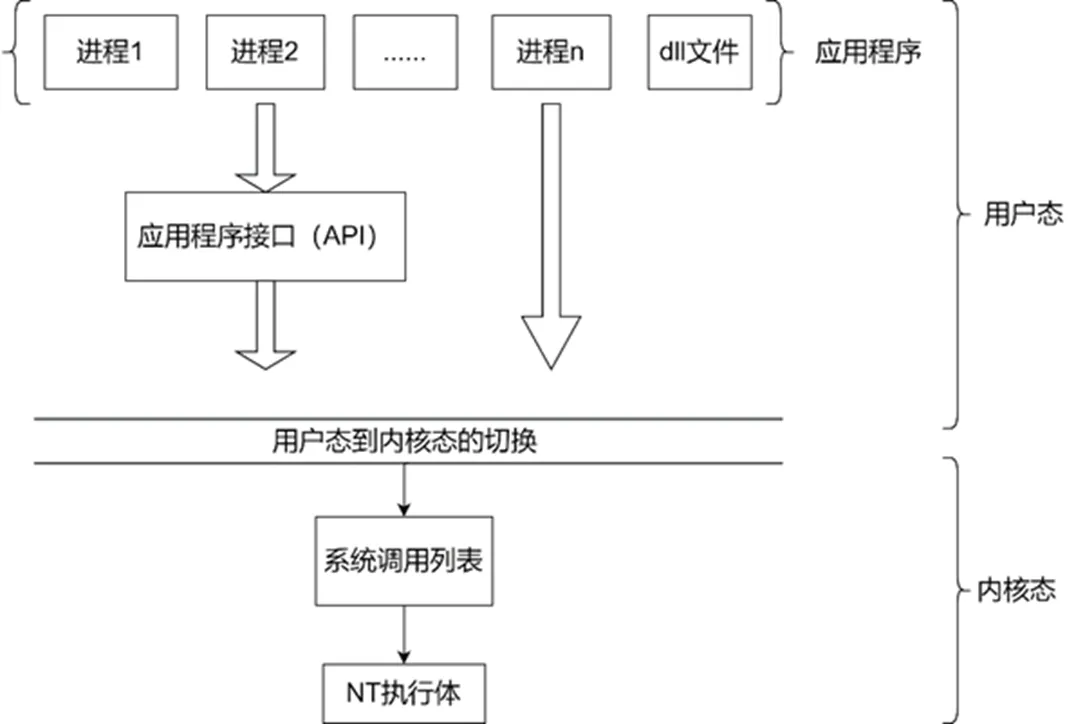
图1 计算机调用系统调用函数示意图
每一个操作系统的系统调用数量都是固定的,因此每一个系统调用函数都有一个惟一的系统调用号。在早期的Linux系统中有两百多项系统调用,随着Linux系统的升级,有些调用被删除,更多的系统调用被添加进来,现今Linux内核大约有340个(版本不同,数量也会不同)系统调用函数供开发者调用。系统调用作为内核函数被保存在Linux系统中unistd.h文件或Windows系统下ntoskrnl.exe和ntkrnlpa.exe执行文件下,每个系统调用函数有其固定的参数和返回值,表1介绍了几个常用的系统调用函数的参数及其返回值。系统调用参数个数各不相同,大多数只有两三个参数,最多的有六个参数,其返回值大多只有一个。
表1 系统调用示例
系统调用名参数返回值 open2个参数:文件描述符,文件模式标志文件描述符 write3个参数:文件描述符,文件模式标志,写入字符数实际写入字符数 mmap6个参数:起始地址、长度、端口、文件模式标志、文件描述符、偏移地址映射区地址指针
2 基于系统调用的入侵检测现状
系统调用的原始追踪序列包含该进程在系统上的绝大部分重要行为,因为恶意行为往往是隐藏在大量的良性行为后,故具有明显特征的恶意系统调用序列也往往淹没在大量的良性系统调用序列中。系统调用数据的预处理对于其模型的训练和检测是十分重要的,应该保证其尽可能地筛除冗余数据而突出其特征数据。现今的主机入侵检测模型检测准确率已经有了很大提升,其误报率却居高不下,这将是研究者们面对的一个不小的挑战。
以下将从系统调用的预处理、基于系统调用的入侵检测模型、模型应用场景三个部分来介绍基于系统调用的入侵检测模型现状。
2.1 系统调用数据的预处理
(1)短序列提取方式
即把较长的系统调用跟踪序列拆分成短序列集合。n-Grams原本是应用于文本分类的一种语言模型,其基本思想是将不定长文本里的内容按照字节进行大小为n的滑动窗口操作,形成具有上下文依赖关系的长度为n的词组[9]。Warrender和Forrest在1996年提出利用系统调用序列定义Unix系统进程的正常行为[6]。1998年,他们利用系统调用序列简单建立了进程的行为轮廓[10]。他们收集sendmail进程的系统调用序列,然后对每一条追踪数据进行滑动窗口分割生成系统调用短序列。这些短序列被加入系统调用数据库里,当执行其他进程时将此进程的n-grams序列集在该数据库里匹配搜索,若无匹配的序列数超过阈值则可认为此进程非sendmail进程。针对在异常检测模型中,使用n-grams算法提取系统调用短序列时n该取何值的问题,文献[11]认为,6-grams是最合适的,因为其能保证模型检测精度同时又不会过多增加模型计算量。事实上,在后续的大量研究中均表明,5-grams与6-grams往往在检测精度和模型计算量的权衡下是最合适的。另外,当提取窗口的滑动不是固定步长而是固定时间间隔时,其为STIDE(Subsequence Time-Delay Embedding)方式。
2013年,胡建坤博士提出了一种基于语义理论的系统调用短序列提取方法[12],其核心思想是入侵行为序列往往不能由阳性样本构建的正常行为短序列所组成,即入侵行为的系统调用序列中应该具有良性行为系统调用序列中所没有的短序列词组。在该文献中,作者将去重后的2-grams序列作为单词,在正常样本中使用2-grams单词组成给定长度的短序列词组,自此构建了正常序列词组的字典并以此为初始特征矩阵。在测试阶段,当系统调用追踪序列进入模型时将被分割成若干个固定长度的词组,然后逐个检索字典中的词组在该追踪数据中的出现次数,形成该系统调用跟踪的特征矩阵。此提取方式获得了很好的检测效果,但是巨大的计算量和烦琐的步骤在工程应用中颇具难度。基于短序列的系统调用提取方式只考虑局部上下文关系或其语义信息,往往数据量大,处理烦琐。
表2 n-grams方法示例
系统调用序列15223344422 系统调用名称sigreturnpipedup2statstatstatpipe 1-grams15,22,33,4,4,4,22 2-grams15 22,22 33,33 4,4 4,4 4,4 22 3-grams15 22 33,22 33 4,33 4 4,4 4 4,4 4 22
(2)频率特征提取方式
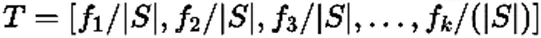
(3)混合提取方式
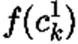
文献[16]提出了一种基于概率有向图的提取方式。在该文献中,作者将每一个系统调用看作一个状态,而下一个系统调用则是状态的改变。作者构建了k×k的特征矩阵T,其中T(i,j)表示系统调用状态i向系统调用状态j转变的概率值,概率值由追踪数据中该状态转换的频率得到,k表示此系统的系统调用函数数量。文献[17]在n-grams短序列的基础上重点考虑了系统调用追踪序列中最多重复与最少重复的调用函数。文献[18]则致力于创建一种脱离平台的频率短序列提取方式。其将n-grams短序列的出现频率作为值构建特征向量,忽略掉原本的n-grams短序列,通过此种方式增强特征矩阵的可迁移性以解决训练样本不足的问题。
文献[19]提出了两种判别式特征选择算法。ADWSC(Absolute difference of weighted system calls)算法针对每个系统调用在样本里的发生频率为它们赋值,频率越高则代表其越冗余,赋予较低的权重。RSLPT(Ranked System Calls Using Large Population Test)算法则根据一个系统调用在良性样本和恶性样本中出现次数的不同定义其权值,次数差异越大说明其对于区分良性与恶行越重要,则赋予更高权值。通过实验分析,RSLPT算法更具有可扩展性,而ADWSC在检测效果上往往会好一些。
混合提取方式是目前基于系统调用数据做入侵检测的主流特征提取方式。其往往可以在保证特征提取有效性的同时,付出较小的计算和时间成本。合适的系统调用提取方式对模型训练具有重要意义,提取频率特征的预处理方式往往更适合于聚类模型,提取短序列特征的预处理方式则在分类模型中具有较好的表现。
(4)参数特征
系统调用函数的参数同样是系统调用序列的重要特征,对系统调用的参数特征的抓取和学习能够有效降低入侵检测模型的误报率。但是每个系统调用函数的参数个数、参数意义都与该函数密切相关,故很难对其量化地进行分析和处理。Krueger第一次将系统调用的参数特征用于入侵检测[20]。他们的模型学习正常系统调用参数的长度、字节和结构性特征并期望于模型在检测阶段能够发现系统调用参数的异常。事实上他们为每一个系统调用构建了配置文件,即针对特定系统调用设置参数字符串长度、常用单词和结构性特征,并在训练阶段找到违反该设置次数的最大阈值。在文献[21]中,系统调用序列参数被作为单个系统调用的属性并以元组形式保存,将原本的系统调用序列转换为以参数元组为元素的集合并进行聚类分析,通过算法将聚类后的类别信息抓取并以此为样本进行分类模型的训练和检测。
文献[22]提出了一种新的特征提取方式来获得系统调用的参数特征以改善深度学习模型的入侵检测效果。在该文献中,作者将系统调用分成了三类,分别是系统调用相关参数、与进程相关的参数和与时间相关的参数。不同类别的参数将使用不同的处理方式,系统调用相关参数使用嵌入的方法即将参数进行独热编码后与嵌入矩阵相乘,而与进程相关的参数将使用pid与tid号,与时间相关的参数将进行编码。在对参数分别处理后,三种类别的参数将成为同一纬度的向量,系统调用事件的表达由处理后的参数进行向量的加法得到。结合参数特征可以获得进程间的通信关系,有助于构建进程间有向图和去除数据冗余信息。
2.2 基于系统调用入侵检测模型
(1)聚类模型
聚类即将样本划分为两类或多个类别,其寻找到相对距离最小的样本形成一个集群。2002年,文献[23]提出使用无监督学习框架训练异常检测模型,在该文献中介绍了集群算法、KNN(K最近邻)算法、单分类SVM算法在异常检测的应用。文献[13]在对ADFA-LD数据集的评测过程中通过K均值聚类和KNN聚类对该数据集进行分类,其实验结果显示K均值聚类算法在ADFA-LD数据集里表现优于KNN算法。文献[24]对比了K均值算法、AP(Affinity Progation)算法、层次聚类算法和最大期望值聚类算法用于系统调用序列的表现。他们在Windows系统下运行病毒样本收集系统调用追踪序列得到系统调用原始数据,在预处理阶段原始数据去重后使用主成分分析法降维。最大期望值聚类算法在他们的实验中表现最好,K均值算法和层次聚类算法表现接近。因为系统调用数据的冗余特性,聚类模型在入侵检测模型的表现往往不如预期,其往往作为数据集的评估模型。
(2)贝叶斯分类器
是有监督机器学习模型,其基本思想在相关概率已知的情况下利用误判损失来选择最优的类别分类。常见的有朴素贝叶斯分类器、最小代价贝叶斯分类器、最小风险贝叶斯分类等。文献[21]抓取系统调用追踪数据的上下文信息和参数特征,分两个阶段完成入侵数据的检测。在第一阶段,使用参数特征对系统调用进行聚类,获得进程和系统调用的集群。第二阶段则是计算先验概率矩阵,构建朴素贝叶斯分类器得到系统调用序列的概率分布。得到概率分布后,很容易就可以得到生成某个序列的概率值,以此设定阈值进行异常分类。此模型在训练阶段步骤烦琐,对检测精度的提升也不大,但是可以获得进程间的联系,而不仅仅局限于单个进程。
(3)HMM模型
是经典统计模型,它用来描述一个含有隐含状态的马尔可夫过程。早在2003年便有人将马尔可夫模型应用于系统调用序列的分析[25]。文献[26]通过系统调用评估进程间的行为距离,对镜像攻击具有较高的检测性能。两个进程的系统调用序列为可观察对象,通过HMM模型获得该序列在隐含状态下的概率值,将其映射为两进程的行为距离。HMM模型相比于其他模型尤其是深度学习模型具有更完善的认证理论。
(4)支持向量机模型
早在2002年,文献[23]提出三种无监督机器学习模型作为基于系统调用的分类模型,分别是层次聚类、K近邻和单分类SVM模型。当时的模型注重于对特定进程的入侵识别,并不具有普遍的识别能力。在2013年,谢苗、胡建坤等人使用SVM模型评估其新建的ADFA-LD数据集[27]。他们使用添加频率特征的n-grams方法构建特征矩阵T来表示一个进程的追踪数据。在特征矩阵T中,T(i,j)表示一个系统调用序列号和该调用出现频率的乘积,每一行表示一个经过乘法处理的n-grams短序列,因为重复的数据没有意义,故该n-grams短序列集合经过去重处理。在他们的模型中,使用的是单分类的SVM算法。经过实验,核函数对实验结果的影响很小且5-grams短序列的检测效果是最好的,在20%的误报率时候精确率是70%。单分类SVM算法与多分类SVM算法所不同的是单分类SVM算法是在数据和原点间构建超平面,且要求超平面与原点呈最大距离。文献[15]同样使用单分类SVM模型和ADFA-LD数据集,可变长度的n-grams特征提取方式使得该模型在误报率10%的情况下检测精度达到了90%,其检测性能大大提升。
(5)极限学习机(ELM)
极限学习机可以看作是一种单隐层前馈神经,它使用随机的输入层权值和偏差,通过误差函数训练得到输出层权重,其相比于其他的神经网络具有训练参数少、学习速度快、泛化能力强的优点。文献[12]中,胡建坤博士使用极限学习机作为入侵检测分类模型取得了不错的效果。该模型在KDD98数据集、UNM数据集以及ADFA-LD数据集上均能达到在误报率不超过15%的情况下准确率超过85%。ELM模型用时间和计算成本换取入侵检测准确率,其不适合实时检测和大量数据同步处理的应用场景。
(6)CNN模型
深度卷积网络在图像处理中应用广泛,文献[28]将系统调用序列转换为二维图像,分别训练CNN模型、随机森林模型、支持向量机模型、多层感知机作为分类器。作者通过在安卓仿真器里运行恶意软件得到样本数据,在该实验场景中,CNN模型的表现是最佳的。CNN模型处理一维数据的效果显然不如循环网络,将一维系统调用序列升为二维必然改变其原始特征,对特征的选择是此类模型所需解决的问题。
(7)LSTM、GRU、RNN
循环神经网络及其变种具有对时间信息的记忆能力,能以很高的效率对序列的非线性特征进行学习。文献[29]对比了CNN模型、GRU模型、LSTM模型与RNN模型在基于系统调用入侵检测上的表现。在他们的模型中,神经网络被训练来预测序列中当前系统调用的下一个系统调用序号的概率分布,并利用该概率分布估计一个序列的发生概率。如公式1所示,P(x)表示长度为l的系统调用序列发生概率,该模型将此概率作负对数似然并设置阈值来检测系统调用序列的入侵。他们使用ADFA数据集并通过处理保证系统调用序列具有相同的长度,在GRU、LSTM模型和CNN+RNN模型中,LSTM模型是表现最好的。LSTM模型能够学习长期依赖关系,极适合应用于一维序列。事实证明,LSTM模型应用于基于系统调用序列的入侵检测技术表现优于其他的深度学习模型。
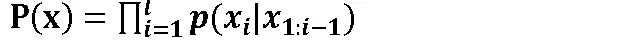
(8)集成学习
集成学习的特点是结合多个基学习器来完成学习任务,按照基学习器之间有无强烈依赖关系其可以被分为两类。在系统调用序列的集成学习模型中,基学习器往往是并行无强烈依赖关系的,以Bagging和随机森林为代表。文献[30]中,作者使用两个单层LSTM和一个双层LSTM作为基学习器构成了Bagging集成学习模型。系统调用序列独热编码后使用嵌入矩阵进行数据的降维处理。该模型在ADFA、UNM、KDD数据集上达到了0.928的AUC值。随机森林是以决策树为基学习器的集成学习模型,其在入侵检测方面应用广泛。
(9)注意力机制
为了克服LSTM模型很难从超过200的序列中学习语义和上下文信息[31],而系统调用序列长度往往超过200的问题,文献[32]在LSTM模型中添加注意力机制来改善LSTM模型对系统调用时间信息学习不完全的情况。在他们的模型中,首先对系统调用进行去冗余和切割处理,即去除周期性重复的短序列并将长度超过200的系统调用序列切割到200以下以达到LSTM模型的最优长度。在此模型中,出现频率更高的单词将被赋予更高的敏感度。
(10)其他深度学习模型
深度学习模型近来被广泛应用于图像识别、自然语言处理、数据生成等领域,在入侵检测领域很多模型同样表现优秀。文献[33]介绍了典型的深度学习算法及其在入侵检测领域的应用,其中大多数算法同样适用于基于系统调用的入侵检测模型。自适应编码器、迁移学习、元学习、生成对抗网络等也可以用来提高异常检测模型效能。
2.3 应用场景
(1)移动端
移动端应用的开放性为系统的普及提供了很大的便利,同时也为移动端应用网络安全埋下了重大的安全隐患。每年大量的恶意软件对我们的隐私安全、数据安全产生了重大威胁。与常规入侵检测所不同的是,移动端应用的更新操作和进程间通信更为频繁,且其进程的系统调用序列往往有多个开始点和结点。文献[34]提出一种动态分析与静态分析相结合的方法,即针对软件样本静态分析该软件的功能、安装代码、调试环境,动态分析其系统调用序列,结合两者获得其风险分数。文献[16]提出了一种安卓恶意软件检测器并将它命名为Sword。在Sword里,样本应用在安卓仿生器中执行,Mokey工具自动生成系统事件和用户事件,随即系统调用序列被提取出来并生成有向图在决策算法里进行判别。文献[35]提出SysDroid检测器,该检测器同样在安卓虚拟机上安装应用并使用Monkey生成事件。Sysdid的安卓虚拟机除了安装样本应用外,还会再安装常用的安卓应用以检测某些恶意软件针对其他软件行为的特定攻击。在Sysdid中,系统调用序列使用n-grams方法提取特征,使用逻辑回归算法、随机森林、深度神经网络等多种学习方法作为分类模型。
(2)容器、虚拟机、云环境
容器机制在计算机各个领域均有应用,它具有轻量且方便部署的特性。但容器之间共享主机内核,容器之间的隔离是很弱的,因此容器被认为应该有额外的防护机制。且容器的防护机制不宜太复杂,应在保证防护能力的情况下尽可能少地占用系统资源。文献[36]提出一种针对容器的加密货币挖掘劫持攻击检测系统,该系统抓取容器内系统调用数据生成特征向量,可实现对加密货币劫持攻击的实时检测。在该文章中,作者评估了随机森林算法、前馈神经网络、RNN网络和XGBoost(eXtreme Gradient Boosting)四种模型在加密货币劫持攻击检测上的表现。其结果是XGBoost模型与随机森林表现较其余两种网络表现更好,其检测准确率分别为97%和90%。针对容器内系统调用序列的追踪和获取,文献[36]使用了sysdig工具。文献[37]构建模型为容器构建系统调用白名单,该容器将被禁止调用名单以外的系统调用。虚拟机管理程序所提供的虚拟机之间的隔离并不完整,因此虚拟机应防御同一主机上其他虚拟机攻击的能力。文献[38]提出了一种适用于同一主机上多个虚拟机入侵检测的运行状态追踪架构,其依赖于PT(Intel Process Trace)技术。该架构接受来自PT的数据流并将其解码和净化,提取到的系统调用序列被应用于基于机器学习的主机入侵检测模型中。云环境是如今网络服务的基础环境,云上虚拟机可以实现云上办公,即有网络即可办公。文献[39]提出了一种基于云环境的虚拟机入侵检测模型,其部署在虚拟机管理软件上,通过系统调用序列检测入侵。在该模型里,使用自回归模型将系统调用序列分为三类,每一类分别使用不同的分类模型进行检测。文献[40]提出了一种在云环境下的实时入侵检测模型。
其他场景人们的工作和生活逐渐地依靠于各种各样的电子产品和网络。这使得某些非法团体的网络攻击具有明显的目的性和强大破坏力,利用系统调用序列训练对某一类攻击具有极强检测能力的模型是业界一直在努力的方向。文献[41]专注于APT攻击的检测和预防,文献[42]专注于注入攻击,而文献[43]则专注于僵尸网络的发现和阻止。值得注意的是,文献[44]提出了一种系统调用注入攻击方式,此方式能对大部分的基于系统调用的入侵检测模型造成干扰甚至让其失效。文献[45]提出适用于大型公司内网的基于系统调用的进程监视管理系统,其在服务器上部署LSTM异常检测模型,收集内网主机系统调用数据进行实时的异常检测和预警。文献[46]提出一种构建系统调用白名单的算法,即针对特定进程构建系统调用白名单以减少其攻击的可能性和危害。
3 数据集与入侵检测模型性能指标
系统调用追踪序列可以使用strace、sysdig等工具收集,有相当一部分的基于系统调用的入侵检测研究使用的是研究者个人收集数据。包含系统调用数据的数据集简单介绍如下,同时本部分也将对入侵检测模型的性能指标做一个简要概括。
3.1 数据集
(1)DARPA数据集[52]
由麻省理工林肯实验室收集并公开,是第一个用于计算机网络入侵检测的数据集。DARPA1998、DARPA1999与DARPA2000分别收集于1998、1999、2020年,其中DARPA200新增了DDoS攻击样本数据。DAPRA数据集包含网络流量和审计数据,其收集于Solaris系统。
(2)UNM数据集[53]
是新墨西哥大学于1998年收集,其攻击样本包括缓冲区溢出、符号链接攻击、木马程序、特权程序等。DPRPA数据集与UNM数据集均存在年代较为久远可能导致其训练模型并不适用于现代网络的问题。
(3)ADFA数据集[54]
由澳大利亚国防大学于2013年收集[47],其包含了Linux版本和Windows版本,分别命名为ADFA-LD和ADFA-WD。其样本中包括密码爆破攻击、添加超级用户提权、Java-Meterpreter、Webshell攻击等。ADFA数据集取代DARPA数据集成为目前的主流数据集。
(4)NGIDS-DS
2016年胡建坤、Haider等人提出了一个高质量数据集[48],并将其命名为NGIDS-DS(the next-generation IDS dataset)。他们在Ubuntu14.4系统主机上收集了包含漏洞、蠕虫、扫描攻击等7类攻击样本的系统日志数据和流量数据。
(5)AWSCTD[55]
文献[49-50]在2018年提出了AWSCTD数据集,该数据集收集在Windows系统上执行12110个恶意样本时产生的系统调用信息。此数据集在GitHub上开源并在文献[51]构建多种深度学习模型的评估中表现良好。
3.2 入侵检测模型性能指标
混淆矩阵用来描述分类模型在已知真实值的测试数据上的性能,其同样适用于入检测模型的性能评估。下面将简单介绍混淆矩阵的一些术语:
TP(True Positives):真阳性,即预测为阳性实际也为阳性,是正确的预测。
TN(True Negatives):真阴性,即预测为阴性,实际也为阴性,是正确的预测。
FP(False Positivee):假阳性,即预测为阳性,实际为阴性,是错误的预测。
FN(False Negatives):假阴性,即预测为阴性,实际为阳性,是错误的预测。
ACC(Accuracy):准确率,总的来说分类器的准确率。
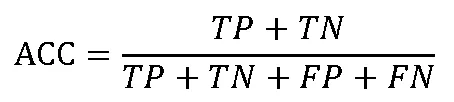
Recall:召回率,实际为阳性的样本中被正确识别所占比例。
Precision:精确率,在被识别为阳性的样本中,正确识别所占的比例。

FPR:误报率,在所有阴性样本中,被错误识别为阳性所占的比例。
ROC曲线:一个常用图表,总结了分类器在所有可能阈值上的性能。通过阈值改变时绘制其真阳率(召回率)和假阳性率(误报率)来生成。
AUC值:即ROC曲线下的面积,其值越大分类器性能越好,取值范围为0-1之间。
F1score:精确率和召回率的调和平均值。其值同样是越大分类器性能越好,取值范围为0-1之间。
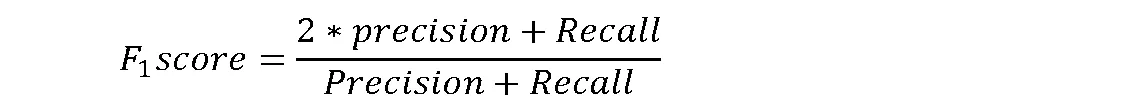
4 研究趋势与挑战
4.1 可多平台混用的特征提取方式
即系统调用序列预处理的流水化和规模化。现今的特征提取方式往往是模型针对该数据集所做的特殊处理和操作,数据集收集时所使用的系统不同、版本不同以及恶意样本攻击的复杂程度都造成了数据集之间的不通用。然而,大多数攻击的攻击思路是相同的,并不会因为其攻击系统的不同产生较大的改变,也因此其行为模式的改变也是很小的,只不过因为同一个操作在不同系统里,系统调用函数的名称、号码略微不同而已。可多平台混用的特征提取方式将把在不同系统、不同版本所收集的数据集进行整合,这将大大增加模型训练的样本。将新收集的不同系统的系统调用序列使用此特征提取方式进行预处理,能够在同一个模型下进行检测,实现了模型在训练和使用上的跨平台化。
4.2 检测能力更好的模型
基于系统调用序列的异常检测模型发展已久,其检测准确率可以达到90%以上,但是其误报率同时也居高不下。与深度学习技术的结合是如今各个领域研究的热门。实践证明,利用好深度学习技术能有效提升异常检测的准确率并降低其误报率,且同样具有检测0day漏洞的能力。异常检测与入侵检测的结合也是提升其入侵检测效果的有效途径。
分布式的部署方式某些场景下的入侵检测模型应具有实时检测的能力,例如在大型公司内网、大型数据中心的管理机组、虚拟主机网络等。分布式的部署方式希望实现的是整个网络入侵检测模型的共同进化、共同防御和实时报警。
4.3 针对特定类攻击的长时监控
系统调用序列是计算机底层函数的集合,对程序行为的刻画是最为细粒度的。某一类特定的攻击方式,在其行为上将会出现类似的行为特征。针对某些具有很大危害的攻击,例如DDoS攻击、勒索病毒攻击、挖矿攻击等训练特殊模型,长期部署该模型以完成对此类攻击的提前发现与报警甚至将攻击驱除。
[1]Liu M,Xue Z,Xu X,et al. Host-Based Intrusion Detection System with System Calls:Review and Future Trends[J]. ACM computing surveys,2019,51(5):1-36.
[2]Mishra P,Varadharajan V,Tupakula U,et al. A Detailed Investigation and Analysis of Using Machine Learning Techniques for Intrusion Detection[J]. IEEE Communications surveys and tutorials,2019,21(1):686-728.
[3]Glass-Vanderlan T R,Iannacone M D,Vincent M S,et al. A Survey of Intrusion Detection Systems Leveraging Host Data[J]. 2018.
[4]蹇诗婕,卢志刚,牡丹,等. 网络入侵检测技术综述[J]. 信息安全学报,2020.
[5]Ye Y,Li T,Adjeroh D,et al. A Survey on Malware Detection Using Data Mining Techniques[J]. ACM computing surveys,2017,50(3):1-40.
[6]Forrest S,Hofmeyr S A,Somayaji A,et al. A sense of self for UNIX processes[J]. Computer Science,1996.
[7]葛仁北. 系统调用与操作系统安全[J]. 计算机工程与应用,2002(19):97-99.
[8]高岩,蒋若江. 主机防护系统中系统调用截获机制的实现[J]. 计算机工程与设计,2003(11):76-80.
[9]Damashek M. Gauging Similarity with n-Grams:Language-Independent Categorization of Text[J]. Science (American Association for the Advancement of Science),1995,267(5199):843-848.
[10]Hofmeyr S A,Forrest S,Somayaji A. Intrusion detection using sequences of system calls[J]. Journal of computer security, 1998,6(3):151-180.
[11]Tan K M C,Maxion R A. "Why 6?" Defining the operational limits of stide,an anomaly-based intrusion detector, Los Alamitos CA,2002[C]. IEEE,2002.
[12]Creech G,Hu J. A Semantic Approach to Host-Based Intrusion Detection Systems Using Contiguousand Discontiguous System Call Patterns[J]. transactions on computers,2012.
[13]Xie M,Hu J,Yu X,et al. Evaluating Host-Based Anomaly Detection Systems:Application of the Frequency-Based Algorithms to ADFA-LD[M]//Cham:Springer International Publishing,2014:542-549.
[14]Jiang G,Chen H,Ungureanu C,et al. Multiresolution Abnormal Trace Detection Using Varied-Length n-Grams and Automata[J]. IEEE transactions on systems, man and cybernetics. Part C,Applications and reviews,2007,37(1):86-97.
[15]Khreich W,Khosravifar B,Hamou-Lhadj A,et al. An anomaly detection system based on variable N-gram features and one-class SVM[J]. Information and software technology,2017,91:186-197.
[16]Bhandari S,Panihar R,Naval S,et al. SWORD: Semantic aWare andrOid malwaRe Detector[J]. Journal of information security and applications,2018,42:46-56.
[17]Haider W,Hu J,Xie M. Towards reliable data feature retrieval and decision engine in host-based anomaly detection systems,2015[C]. IEEE,2015.
[18]Liu Z,Japkowicz N,Wang R, et al. A statistical pattern based feature extraction method on system call traces for anomaly detection[J]. Information and software technology,2020,126:106348.
[19]P V,Zemmari A,Conti M. A machine learning based approach to detect malicious android apps using discriminant system calls[J]. Future generation computer systems,2019,94:333-350.
[20]Kruegel C,Mutz D,Valeur F,et al. On the Detection of Anomalous System Call Arguments[M]//Berlin,Heidelberg: Springer Berlin Heidelberg,2003:326-343.
[21]Koucham O,Rachidi T,Assem N. Host Intrusion Detection using System Call argumented-based clustering combined with bayesian classification:SAI Intelligent Systems Conference 2015,London,UK,2015[C].
[22]Fournier Q,Aloise D,Azhari S V, et al. On Improving Deep Learning Trace Analysis with System Call Arguments[J]. 2021.
[23]Eskin E,Arnold A,Prerau M,et al. A geometric framework for unsupervised anomaly detection[J]. Applaications of Data Mining in Computer Security,2002:77-101.
[24]Ognev R A,Zhukovskii E V,Zegzhda D P. Clustering of Malicious Executable Files Based on the Sequence Analysis of System Calls[J]. Automatic control and computer sciences,2019,53(8):1045-1055.
[25]Cho S,Han S. Two Sophisticated Techniques to Improve HMM-Based Intrusion Detection Systems[M]//Berlin,Heidelberg: Springer Berlin Heidelberg,2003:207-219.
[26]Gao D,Reiter M K,Song D. Behavioral distance measurement using hidden markov models[M]//RAID. 2006.
[27]Xie M,Hu J,Slay J. Evaluating host-based anomaly detection systems:Application of the one-class SVM algorithm to ADFA-LD,2014[C]. IEEE,2014.
[28]Casolare R,De Dominicis C,Iadarola G,et al. Dynamic Mobile Malware Detection through system call-based image representation[J]. Journal of Wireless Mobile Networks, Ubiquitous Computing,and Dependable Applications,2021.
[29]Chawla A,Lee B,Fallon S,et al. Host Based Intrusion Detection System with Combined CNN/RNN Model[M]//Cham: Springer International Publishing,2019:149-158.
[30]Kim G,Yi H,Lee J,et al. LSTM-Based System-Call Language Modeling and Robust Ensemble Method for Designing Host-Based Intrusion Detection Systems[J]. 2016.
[31]Khandelwal U,He H,Qi P,et al. Sharp Nearby,Fuzzy Far Away:How Neural Language Models Use Context[J]. 2018.
[32]Xie W,Xu S,Zou S,et al. A System-call Behavior Language System for Malware Detection Using A Sensitivity-based LSTM Model,2020[C]. ACM,2020.
[33]R V,KP S,Alazab M,et al. a comprehensive tutorial and survey of applications of deep learning for cyber security[J]. computer science,2020.
[34]Saleh M F. malware detection model based on classifying system calls and code attributes:a proof of concept[J]. Electronic Security and Digital Forensics,2019.
[35]Ananya A,Aswathy A,Amal T R,et al. SysDroid:a dynamic ML-based android malware analyzer using system call traces[J]. Cluster computing,2020,23(4):2789-2808.
[36]Karn R R,Kudva P,Huang H. Cryptomining Detection in Container Clouds Using System Calls and Explainable Machine Learning[J]. transactions on parallel and distribution systems,2021.
[37]Wang X,Shen Q,Luo W,et al. RSDS:Getting System Call Whitelist for Container Through Dynamic and Static Analysis: 13th Intermational Conference on Cloud Computing,2020[C]. IEEE,2020.
[38]Seo J,Bang I,You J,et al. SBGen:A Framework to Efficiently Supply Runtime Information for a Learning-Based HIDS for Multiple Virtual Machines[J]. IEEE access,2020,8:225356-225369.
[39]Besharati E,Naderan M,Namjoo E. LR-HIDS:logistic regression host-based intrusion detection system for cloud envirmonents[J]. Journal of Ambient Intelligence and Humanized Computing,2018.
[40]Gupta S,Gupta S,Kumar P,et al. An Immediate System Call Sequence Based Approach for Detecting Malicious Program Executions in Cloud Environment[J]. Wireless personal communications,2015,81(1):405-425.
[41]Han W,Xue J,Wang Y,et al. APTMalInsight:Identify and cognize APT malware based on system call information and ontology knowledge framework[J]. Information sciences,2021,546:633-664.
[42]Zhang L,Morin B,Baudry B,et al. Maximizing Error Injection Realism for Chaos Engineering with System Calls[J]. IEEE transactions on dependable and secure computing,2021:1.
[43]Costa V G T D,Junior S B,Miani R S,et al. mobile botnets detection based on maching learning over system calls[J]. Security and Networks,2019,14(2).
[44]Zhang L,Morin B,Baudry B,et al. Maximizing Error Injection Realism for Chaos Engineering with System Calls[J]. IEEE transactions on dependable and secure computing,2021:1.
[45]Dymshits M,Myara B,Tolpin D. Process Monitoring on Sequences of System Call Count Vectors[J]. 2017.
[46]Pailoor S,Wang X,Shacham H,et al. Automated policy synthesis for system call sandboxing[J]. Proceedings of ACM on programming languages,2020,4(OOPSLA):1-26.
[47]Creech G,Member S,Hu J. generation of a new IDS Test dateset time:to retire the KDD collection:Wireless Communications and Networking Conference(WCNC), 2013[C].
[48]Haider W,Hu J,Slay J,et al. Generating realistic intrusion detection system dataset based on fuzzy qualitative modeling[J]. Journal of network and computer applications,2017,87:185-192.
[49]Čeponis D,Goranin N. Towards a Robust Method of Dataset Generation of Malicious Activity for Anomaly-Based HIDS Training and Presentation of AWSCTD Dataset[J]. Baltic Journal of Modern Computing,2018,6(3).
[50]Haider W,Creech G,Xie Y,et al. Windows Based Data Sets for Evaluation of Robustness of Host Based Intrusion Detection Systems(IDS)to Zero-Day and Stealth Attacks[J]. Future internet,2016,8(4):29.
[51]Ceponis D,Goranin N. Evaluation of Deep Learning Methds Efficiency for Malicious and Benign System Calls Classification on the AWSCTD[J]. Security and Communication Networks,2019.
[52]https://archive.ll.mit.edu/ideval/docs/index.html.
[53]https://www.cs.unm.edu/~immsec/systemcalls.htm.
[54]https://research.unsw.edu.au/projects/adfa-ids-datasets.
[55]https://github.com/DjPasco/AWSCTD_Data.
广东省重点领域研发计划(2018B010113001);国家自然科学基金项目(62176264)
猜你喜欢
小学生学习指导(低年级)(2021年12期)2021-12-31
速读·下旬(2021年11期)2021-10-12
商品与质量(2019年34期)2019-11-29
大东方(2019年12期)2019-10-20
阅读与作文(英语初中版)(2019年8期)2019-08-27
计算机系统应用(2019年3期)2019-03-11
小学生学习指导(低年级)(2018年11期)2018-12-03
科学与财富(2017年22期)2017-09-10
商情(2017年1期)2017-03-22
现代防御技术(2016年1期)2016-06-01
