
基于ERNIE_BiGRU模型的中文医疗文本分类
2022-03-11 12:39:22常俊豪武钰智
电脑知识与技术 2022年1期
常俊豪 武钰智


摘要:【目的】探究ERNIE模型 (Enhanced Language Representation with Informative Entities)和双向门限循环单元(BiGRU)在医疗疾病名称科室分类中的效果及差异。【方法】以医疗疾病名称为训练样本,以BERT(Bidirectional Encoder Representation from Transformers)为对比模型并在模型之后加入不同网络层进行训练探究。【结果】ERNIE模型在分类效果上优于BERT模型,精度约高4%,其中精确度可达79.48%,召回率可达79.73%,F1分数可达79.50%。【局限】仅对其中的八个科室进行分类研究,其他类别由于数据量过少而未纳入分类体系中。【结论】ERNIE-BiGRU分类效果较好,可应用于医疗导诊系统或者卫生统计学中。
关键词:文本分类;医疗导诊系统;利用知识增强语义表示模型;双向门限循环单元;人工神经网络与计算
中图分类号:TP183 文献标识码:A
文章编号:1009-3044(2022)01-0101-04
1引言
Hinton在1986年提出了分布式表示(Distributed Representation)的思想,分布式表示以其拥有非常强大的特征表达能力而受到学术界的广泛关注。Bengio在2003年提出了神经网络语言模型(NNLM)[1],之后在google Mikolov 2013年发表的两篇有关词向量的文章[2]大放异彩,在语义维度上得到了充分验证,使文本分析的进程有了极大的提高;Mikolov在2016年7月提出了fastText[3] 的思想,把句子中所有的詞向量进行平均化处理然后直接向 softmax 层进行输出,fastText 中的网络模型完全没有考虑词的顺序信息对结果所带来的影响,而它使用的语言模型(N-Gram)却充分说明了局部序列信息对实验结果所产生的重要意义。卷积神经网络CNN[4](Convolutional Neural Network)不仅在图像处理领域取得了巨大成功,在语音识别、文本分类等多个领域也发挥着重要的作用,但CNN存在一个问题是特征尺寸的视野为固定的,一方面较长的序列信息无法建模,另一方面特征尺寸的超参调节也很烦琐。近年来在自然语言处理领域中,比较常用的网络模型是递归神经网络RNN[5](Recurrent Neural Network),它的独特性是能够更加充分地表达上下文信息。CNN和RNN用在文本分类任务中虽然都发挥着巨大的功效,但其模型理解不够直观,可解释性不好的缺点也成为学者们研究的热点。近几年将注意力机制[6-7](Attention)应用在自然语言处理领域能够把每个词对结果的贡献很直观地表达出来,其强大的功能在自然语言处理领域也引发了对注意力机制的各种加工和改进。BERT[8-10](Bidirectional Encoder Representation from Transformers)模型是谷歌公司AI团队在2018年 10 月发布的一种基于深度学习的新的语言表示模型,即基于转换器的双向编码表征模型,在当时基本刷新了很多NLP任务的最好性能,其具备广泛的通用性也受到广泛好评,在当时自然语言处理领域引起了极大的轰动,是NLP领域极为重要的一次突破。ERNIE[11-12]模型是继BERT模型提出后做出的进一步提升,预训练过程以大量的中文数据集为样本,同时对BERT预训练模型的逻辑过程进行了改进,ERNIE模型与BERT模型相比,其优势显而易见,通过对训练语料的扩展和对论坛语料的引入来增强模型对语义表示的能力,通过对实体概念知识的学习来进行真实世界完整概念的语义表示,在中文文本任务的使用中最具有广泛性。
当今社会,物质需求已经基本被满足,身心健康的精神需求也在融入生活中,巨大的生活压力使很多人的身体状况处于亚健康甚至不健康状态,当人们感觉到身体不适需要采用医疗手段来进行干预的时候,便是其就医活动的开始,但在就医流程中,存在着诸多影响就医效率的问题:1)在医院专家诊治之前,需要先向相关的导诊医师咨询,这样无形间增加了就诊时间;除此之外,绝大多数人诊断前在互联网上的“自诊”,从浩瀚如烟的互联网数据中寻找导致自己不适的病因如同大海捞针一般,一方面检索的效率较低,另一方面检索结果的准确率也被人们所担忧,容易出现选错科室等一系列问题,导致不必要的花费等;2)挂号资源紧缺。在大中型城市中,“无论大病小病都要排队挂号”的问题使本身挂号资源紧缺的情况雪上加霜,同时还浪费了患者宝贵的就诊时间;3)对于现在网上许多在线问诊的情况,不仅非常耗时耗力,还需要投入一小批专业性医师来回答来自患者各种各样的问题,比较占用医生资源。
具体而言,本文通过医疗疾病名称数据集,采用ERNIE_BiGRU模型与其他对比模型设计相应的分类实验,探究各种模型的分类效果,并分析分类效果的影响因素。
2数据及模型介绍
2.1数据集介绍
本文的数据主要来源于中国科学院软件研究所刘焕勇老师在2018年搭建的有关医药领域的知识图谱[13],该项目以疾病为中心,立足于医药领域,以垂直型医药网站为数据来源,包含7类规模为4.4万的知识实体,11类规模约30万实体关系的知识图谱,该项目的数据来自垂直类医疗网站,主要包括诊断项目检查、医疗科目、疾病、药品、食物、症状等多个部分,除此之外,本文还选取了有关医疗疾病及健康知识相关的专业互联网网站获取相关的医疗知识信息,如寻医问药网( http://jib.xywy.com/)以及39健康网(http://www.39.net/),从中获取如疾病名称、所属科室、常用药品、推荐食物等相关信息,将两部分数据经过数据清洗、数据去重、数据打散打乱[14]等一系列处理从中抽取需要的数据,数据的部分结构如图1所示。
其中,0~7分别代表肿瘤科、皮肤病科、妇产科、五官科、儿科、内科、外科和其他科室,每类数据的样本在1000条左右,总共包含了一万余种常见疾病名称和疑难杂症名称;除以上科室外,还有急诊科、中医科、精神科、男科、传染科、肝病等科室,由于其数据量较少,容易造成样本间数据不平衡从而影响实验结果,故将其放入其他科室中。本文采用随机抽取的形式,从该医疗疾病名称数据集中按2:2:6的比例划分为训练集train_data、开发集dev_data和测试集test_data。
2.2模型介绍
ERNIE模型基于字特征输入建模,不需要依赖其他信息,具备较强的通用性和可扩展性,此外,ERNIE的训练语料引入了多源数据知识,除了对百科类文章进行建模,还对新闻资讯类、论坛对话类等数据进行学习,通过对实体概念知识的学习以及训练语料的扩展,增强了模型的语义表示的能力,ERNIE的模型结构图如图2所示。为了能够更加充分地提取上下文信息的特征,在ERNIE模型的基础之上加入BiGRU[15](双向门限循环单元),ERNIE模型将医疗疾病名称数据训练为词向量的形式输入到BiGRU中来进行更深层次的特征提取。
ERNIE模型的结构主要由抽取知识信息和训练语言模型两个部分构成,在抽取知识信息中,为了得到结构化的知识编码使用Transformer[16]作为模型的基本编码器,保留了词在文本中的上下文信息,生成对应的词向量表示,transformer编码器使用的是全attention机制,注意力机制可以提高训练模型的速度,通过对句子中关键节点来把控句子的整体意思,其原理为:
[attention(Q,K,V)=softmaxQKTdkV] (1)
式中:[Q,K,V]代表輸入字向量矩阵;[dk]代表输入向量维度。
在常见的神经网络结构中,按传播方向可以分为单向传播和双向传播,在单向的神经网络结构中,状态一般是从前往后输出的,虽然可以得到前向的上下文信息,但是忽略了后文的上下文信息所产生的影响。在自然语言处理任务中,如果当前时刻的输出不仅能够与后一时刻的状态产生联系,还能与前一时刻的状态建立联系,即从两个方向同时获取上下文信息对文本分析的特征提取将会带来很有力的影响。双向门限循环单元就可以建立这种联系,且具有对词向量的依赖性小、复杂系数低、响应时间快的优点。BiGRU模型的输入是由两个单向的、方向相反的GRU组成,输出由这两个GRU[17]的状态共同决定,BiGRU的模型结构如图3所示。
由图3可以看出,BiGRU当前的隐藏层状态由当前的输入[xt]、[t-1]时刻前向的隐藏层状态的输出[ht-1]和反向的隐藏层状态的输出[ht-1]三个部分共同决定。BiGRU由两个单向的、方向相反的GRU组成,输出由这两个GRU的状态共同决定,所以BiGRU在t时刻的隐藏层状态通过前向隐藏层状态[ht-1]和反向隐藏层状态[ht-1]加权求和得到:
[ht=GRUxt,ht-1] (2)
[ht=GRUxt,ht-1] (3)
[ht=wtht+vtht+bt] (4)
其中,[GRU()]函数表示对输入的词向量的非线性变换,把词向量编码成对应的GRU隐藏层状态。[wt]、[vt]分别表示t时刻双向GRU所对应的前向隐藏层状态[ht]和反向隐藏层状态[ht]所对应的权重,[bt]表示t时刻隐藏层状态所对应的偏置。
模型通过对数据的处理最终将会以词向量表示进行输出,此时的每个词向量表示[T1,T2,T3,…,Tn]都包含了文本的上下文信息。在进行多层双向训练的同时,它既与后一时刻的状态产生联系又与前一时刻的状态产生联系,就会使得需要预测的词在上下文之间被“提前观测”,造成信息的泄露,BERT模型为了解决这一问题将模型输入序列进行随机遮掩,将对应位置的输入变成[mask]标记,通过序列中其他未被标记的词来预测这些被屏蔽的词,ERNIE模型在此基础上进行了进一步的优化,将字的遮蔽上升为短语和实体层面的遮蔽,对海量数据中的实体概念等先验语义知识进行建模,使得模型学习完整概念的语义表示。模型的整体结构图如图4所示。
3实验及结果分析
3.1实验环境
为了验证该医疗疾病名称在BERT模型和ERNIE模型中的普适性和可行性及分析各模型的效果,本实验在运行速度较快的v100上进行训练,具体的实验环境及配置如表1所示。
3.2实验过程
该分类任务主要分为两种训练模式:一种是通过调整数据集构成,分别是从八种分类中按比例随机抽取和从总样本中按比例抽取,然后再将打散后的数据放入模型中进行试验;另一种是不断调整模型的参数来获得模型的最佳效果参数值。为了验证模型的可靠性,本文在以下模型上进行对比实验探究。
1)BERT;2)BERT_CNN;3)BERT_RCNN;4)ERNIE;5)ERNIE_BiGRU。
3.3评价指标
在文本分类任务中,最普遍最常见的评估指标[18]是包括精准率P(Precision)、召回率R(Recall)以及F1值(F1-Score)。精准率又称查准率,是针对预测结果而言的一个评价指标,在模型判定为正样本的结果中,真正是正样本所占的百分比。召回率又称为查全率,是针对原始样本而言的一个评价指标,在实际为正样本中,被预测为正样本所占的百分比,具体计算公式如下:
[P=TPTP+FP] (5)
[R=TPTP+FN] (6)
[F1=2PRP+R] (7)
式中 TP:預测为正,实际为正;
FP:预测为正,实际为负;
TN :预测为负,实际为负;
FN :预测为负,实际为正。
3.4实验参数
在网络模型改进的基础上,还需要对参数进行调整来提升模型的效果,在本实验中使用的主要模型参数如表2所示。
3.5实验结果
为了能够更加直观地反映数据集在每个模型的好坏程度,每5个epoch后使用验证集进行一次测试来得到训练的效果,通过验证集的准确率[vacc]和损失值[vlocc]的变化来分析每个模型经过一次训练后性能的变化,其中,准确率[vacc]变化曲线如图5所示,损失值[vlocc]变化曲线如图6所示。
由图5可以发现,这五个模型的准确率从第一次训练后,整体呈上升然后趋于平缓。其中ERNIE_BiGRU模型的准确率从第一次开始训练就明显高于其他四个模型且呈继续上升的趋势,说明ERNIE_BiGRU模型在特征提取方面效果较好,可以充分提取一个词前后文的信息,提高分类的准确率。继续提高epoch,ERNIE模型的准确率还会继续上涨,还有继续学习的空间,但是继续调大epoch,最终的分类准确率仍然没有ERNIE_BiGRU的高。模型的收敛情况具体可以通过损失值的大小来加以说明。当损失值比较大时,模型出现过拟合的可能性比较高,当损失值比较小时,模型出现欠拟合的可能性比较高,在图6中,五个模型的损失值呈下降的趋势然后趋于平缓,ERNIE_BiGRU在10个epoch之后的损失值一直处于较低的平稳状态,说明该模型具有良好的收敛效果。如果继续将epoch调大,训练集的损失值还会继续减小,但是验证集的损失几乎不变,说明数据的特征不是特别明显,模型无法充分提取到它的特征。上述结果表明,在该医疗数据集中,ERNIE_BiGRU模型的分类效果最好。
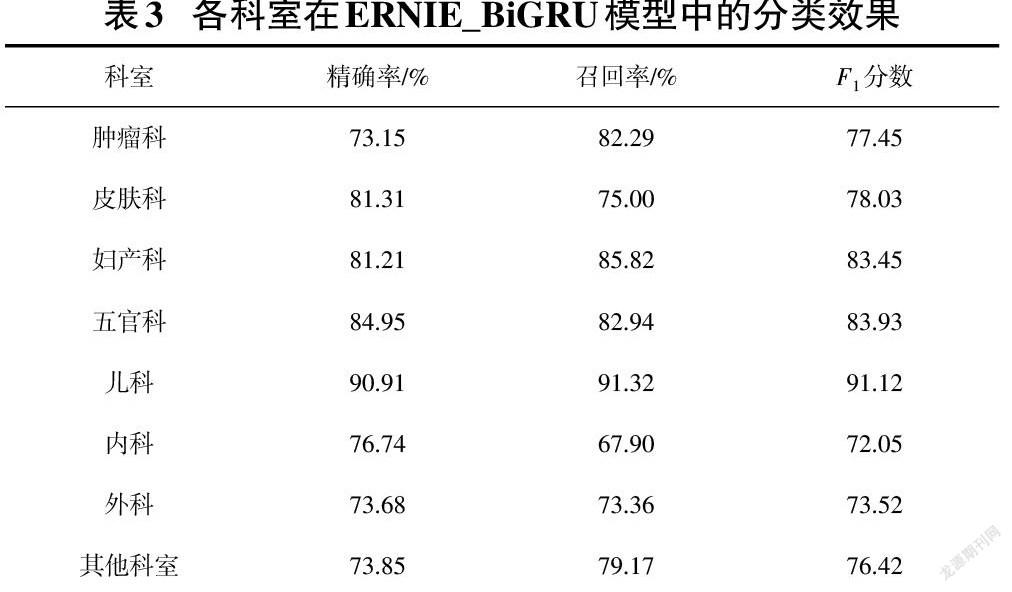
使用测试集对经过25个epoch后的训练模型进行测试,得到8个类别的精确率、召回率和[F1]分数如表3所示。其中儿科、妇产科、五官科的评估指标略高于其他科室,原因是儿科中“小儿”“婴儿”、妇产科中“子宫”“卵巢”、五官科中“眼”“鼻”等特征比较明显,所以模型可以更加充分地提取到它的特征,提高该类别的分类效果。
4结束语
本文通过对比分析了ERNIE_BiGRU和BERT的几种分类模型对医疗科室分类效果的影响及产生效果差异的原因,根据以上的实验结果可以得到以下结论,并分析可以进一步提升分类效果的方法。
1)本文的数据为医疗疾病名称,字符量偏短,样本量较少,导致特征提取不够明显。可选用长文本模型对其特征描述进行特征提取可能会有更好的分类效果。
2)有些科室的样本数量较少,可采用过采样欠采样(Undersampling)、对原数据的权值进行改变、组合集或者特征选择的方式解决。
3)有些科室由于样本量过少未纳入分类体系中,可以以本文分类模型为例重新构建一个分类器对其进行分类。
在后续的研究工作中,将进一步完成更大样本量的分类模型实验,考虑在句子级、段落级、文档级等不同粒度[19-20]中使用不同的分类模型所产生的效果和差异,来解决实际问题,促进模型的应用。
参考文献:
[1] Bengio Y,Schwenk H,Senécal J S,et al.Neural probabilistic language models[M]//Innovations in Machine Learning.Berlin/Heidelberg:Springer-Verlag,2006:137-186.
[2] Mikolov T, Chen K, Corrado G, et al. Efficient Estimation of Word Representations in Vector Space[C]//Proceedings of the International Conference on Learning Representations (ICLR 2013), Scottsdale, 2013: 1-12.
[3] Joulin A, Grave E, Bojanowski P, et al. Bag of tricks for efficient text classification[C]//Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics,,2017:427-431.
[4] Kalchbrenner N,Grefenstette E,Blunsom P.A convolutional neural network for modelling sentences[C]//Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1:Long Papers).Baltimore,Maryland.Stroudsburg,PA,USA:Association for Computational Linguistics,2014.
[5] Liu P F, Qiu X P, Huang X J. Recurrent Neural Network for Text Classification with Multi-Task Learning [C]//International Joint Conference on Artificial Intelligence.AAAI Press,2016:2873-2879.
[6] Du J C,Gui L,Xu R F,et al.A convolutional attention model for text classification[M]//Natural Language Processing and Chinese Computing.Cham:Springer International Publishing,2018:183-195.
[7] Pappas N, Popescu-Belis A. Multilingual Hierarchical Attention Networks for Document Classification[C]//Proceedings of the The 8th International Joint Conference on Natural Language Processing, 2017:1015-1025.
[8] Devlin J, Chang M W, Lee K, et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[C]//Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies,2019:4171-4186.
[9] Sun C,Qiu X P,Xu Y G,et al.How to fine-tune BERT for text classification?[M]//Lecture Notes in Computer Science.Cham:Springer International Publishing,2019:194-206.
[10] Wang Z N,Huang Z L,Gao J L.Chinese text classification method based on BERT word embedding[C]//Proceedings of the 2020 5th International Conference on Mathematics and Artificial Intelligence.Chengdu China.New York,NY,USA:ACM,2020.
[11] Sun Y,Wang S H,Li Y K,et al.ERNIE 2.0:acontinual pre-training framework for language understanding[J].Proceedings of the AAAI Conference on Artificial Intelligence,2020,34(5):8968-8975.
[12] Wang Y S,Zhang H H,Shi G,et al.A model of text-enhanced knowledge graph representation learning with mutual attention[J].IEEE Access,2020,8:52895-52905.
[13] Farrugia D.Exploring stigma:medical knowledge and the stigmatisation of parents of children diagnosed with autism spectrum disorder[J].Sociology of Health & Illness,2009,31(7):1011-1027.
[14] Erhan D, Bengio Y, Courville A, et al. Why Does Unsupervised Pre-training Help Deep Learning[J]. Journal of Machine Learning Research, 2010, 11(3):625-660.
[15] Ning W, Shi-Lin L I, Tang-Liang L, et al. Attention-Based BiGRU on Tendency Analysis of Judgment Results[J]. Computer Systems & Applications, 2019.
[16] Zhang Y,Ding X,Liu Y,et al.An artificial neural network approach to transformer fault diagnosis[J].IEEE Transactions on Power Delivery,1996,11(4):1836-1841.
[17] Dey R,Salem F M.Gate-variants of Gated Recurrent Unit (GRU) neural networks[C]//2017 IEEE 60th International Midwest Symposium on Circuits and Systems (MWSCAS).August 6-9,2017,Boston,MA,USA.IEEE,2017:1597-1600.
[18] Aggarwal C C,Zhai C X.A Survey of Text Classification AlgorithmsMining Text Data,2012.
[19] Nigam K,McCallum A K,Thrun S,et al.Text classification from labeled and unlabeled documents using EM[J].Machine Learning,2000,39(2/3):103-134.
[20] Qian C, Wen L, Long M S, et al. Extracting Process Graphs from Texts via Multi-Granularity Text Classification[EB/OL].[2020-12-20].https://arxiv.org/abs/1906.02127v2.
【通聯编辑:唐一东】
收稿日期:2021-10-15
作者简介:常俊豪(1997—),男,山西临汾人,硕士,研究方向为自然语言处理;武钰智(1997—),男,山西临汾人,硕士,研究方向为自然语言处理。
3806500338212
猜你喜欢
中国典型病例大全(2022年13期)2022-05-10 05:54:37
新高考·高一数学(2022年3期)2022-04-28 07:02:46
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
孩子(2019年5期)2019-05-20 02:52:44
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
基层中医药(2018年2期)2018-05-31 08:45:04
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
中国卫生(2016年6期)2016-11-23 01:09:14
