
儿科疾病及保健知识问答系统的构建
2022-03-09 11:53李俊卓昝红英闫英杰张坤丽
中文信息学报 2022年1期
李俊卓,昝红英,闫英杰,张坤丽
(1.郑州大学 计算机与人工智能学院,河南 郑州 450001;2.鹏城实验室,广东 深圳 518055)
0 前言
近年来,随着互联网技术的发展,网络上的信息也呈爆炸式增长。纷繁复杂的信息增加了用户在网络上获得自己需要知识的可能性,但也有一定的弊端——降低了用户获取信息的准确性与及时性。传统的搜索引擎允许用户以关键词的形式进行检索,但仅仅是关键词的逻辑组合,不涉及语义层面,搜索结果多以网页链接的形式返回,用户还需要进一步进行筛选鉴别[1]。在网络信息量如此庞大的今天,搜索引擎往往不能有效提高用户获取信息的效率,有时甚至可能产生偏向性误导。因此,构建能够准确理解用户问题、迅速给出精确答案的问答系统就显得十分必要。
20世纪六七十年代,早期的NLIDB(Natural Language Interface to Data Base)开始发展[2],其中的代表是1961年的BASEBALL系统[3]和1972年的LUNAR系统[4]。这类问答系统一般限定在特定领域,允许用户使用自然语言查询结构化的知识库。这类问答系统一般面向特定领域,制定其特殊的语法解析规则,很难转移到其他领域的应用。
基于信息检索的问答系统(Information Retrieval based Question-Answering System, IRQA)[5]根据问题中的关键词和语义关系,在大量文本或是相关互联网网页中抽取问题答案。这种方式在一定程度上解决了覆盖领域狭窄的问题,但是由于文本质量、网页信息良莠不齐,抽取出的答案质量也很难令人满意。
2012年,谷歌提出了知识图谱(Knowledge Graph, KG)的概念,为知识库的构建提供了可借鉴的模式[6]。图结构的数据库为问答系统发展提供了新的方向,即基于知识图谱的问答系统(Knowledge Graph Question Answering, KGQA)。KGQA能够充分利用知识图谱中的结构化数据,为用户提供简洁、精准的答案,因而也成为自动问答领域重要的研究方向。
本文构建了一个基于多数据源的面向儿科疾病和保健知识的专科医学问答系统——MDPeQA(Multiple Data Sources based Pediatric Question-Answering System),充分发挥IRQA和KBQA的优势。用户在输入问题后,系统首先使用AC自动机(Aho-Corasick Automaton)[7]和正则表达式对问题与系统内的问题模板进行匹配。随后,根据匹配到的模板分别对中文医学知识图谱[8]和多种医学文档进行检索。随后,根据数据来源权威性结合答案匹配度给出每一个备选答案的评分,优先将评分最高的答案返回给用户。本系统以微信小程序的方式进行推广,具有免下载、打开即用的特点,使用起来较Web程序更加方便。目前系统已在河南省某三甲医院投入试用。
1 研究现状
国外对于医学领域自动问答的研究起步较早,但大部分都是面向医学专业人员的问答系统,对于公众不够友好。张芳芳等人[9]分析了国外自动问答系统的相关研究成果及应用,指出当前医学自动问答领域研究中存在的不足。
Minsuk Lee等人[10]完成了 MedQA 系统,这是一个真正上线的医疗问答系统,该系统面向医生,回答医学领域的定义类问题。返回的结果是与问题相关的段落,依赖于信息检索技术。AskHERMES[11]也是面向医生的问答系统,能够回答较为复杂的临床实际问题。MEANS[12]的答案提取基于语义查询,存在的缺点是该系统把问题分为十类,却只能解决其中的四类问题。enquireMe[13]是面向非医学专业人员的问答系统,其数据来源于在线社区中的问答对。
国内对于自动问答系统,尤其是医学领域自动问答系统的研究尚在起步阶段。刘一诚[14]在专业医疗知识库的基础上搭建了一个医疗领域的问答系统,可以回答针对症状、疾病和药品提出的问题。梁耀波[15]实现了一个智能理疗诊断系统,以自然语言对话的形式与患者进行多轮问答,最后给出患者可能患有的疾病及其概率,以及疾病的相关信息。李超[16]基于命名实体识别、多标签分类、TextRank排序算法实现了智能疾病导诊及医疗问答系统。王蕾[17]以高血压慢性病医疗知识为基础,设计并实现了一个面向高血压医疗健康领域的智能问答系统。
国内当前有较多的医学类网站,如39健康网、春雨医生等,这些网站的功能多是宣传日常健康百科、患者留言相关医生进行回答讲解等。但是仅局限于人工回答,由于受到医生数量、工作时间的限制,往往难以给予用户及时的回答。
综上,目前已有的针对医学领域的自动问答大都存在以下局限: 一是答案来源往往局限于知识图谱或是医学文档数据,而并未充分发挥两者之间的优势;二是大多问答系统面向的是全科疾病的轻量级内容问答,很少根据儿科疾病和儿科保健的特殊性提供专业的深度知识问答服务。
MDPeQA是一个基于多数据源的面向儿科的专科问答系统,能够为常见儿科疾病和儿科保健相关的十余种问题提供较为全面、准确的答案,涵盖症状、检查、治疗、预后等相关知识。考虑到不同数据来源的答案权威性不同,系统设置了数据来源权威性及匹配度的评分机制,以将权威、准确的答案返回给用户。
2 系统架构
MDPeQA系统分为三个模块: 用户交互模块、问题匹配模块以及答案检索模块。系统结构如图1所示。
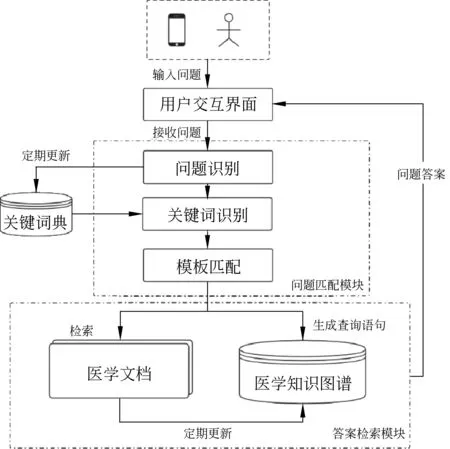
图1 系统结构图
用户交互模块主要完成的功能有: 用户输入问题、系统接收问题、将答案反馈给用户。在测试阶段,用户对答案的评分以及统计也在该模块完成。
问题匹配模块主要实现对用户问题的识别、匹配模板、计算问题与模板的相似度。用户输入问题后,系统首先对问题进行预处理,如修正错别字、去除特殊符号等,接着将处理后的问句进行关键词识别并匹配相应的模板,随后将模板信息送至答案检索模块。
答案检索模块实现对问题的答案检索、整合功能。在用户输入某一问题时,同时对医学文档和医学知识图谱两个来源的答案进行检索,其中医学文档按优先级进行依次检索。得到所有备选答案后,系统会依据评分规则对所有答案进行评分计算,给出评分最高的1~2个答案;如果没有答案高于阈值,则认为所找到的答案为不可靠的,此时应当将答案反馈给用户,注明数据来源,并提醒用户加以注意。系统维护人员定期对知识图谱进行更新,确保用户所查找答案的时效性。
3 关键技术
3.1 融合句法结构及关键词的问题匹配
为了刻画出问题所包含的语义信息,本文引入“问题的关键词”的概念。问题的关键词可以划分为两类,一类表明问题聚焦的中心,记为“中心词”;另一类表征问题的意图,记为“疑问词”。
如图2所示,对于问题“如何治疗过敏性紫癜?”而言,“过敏性紫癜”表明了用户问题的聚焦之处,该问题都应和疾病“过敏性紫癜”有关;“如何治疗”则将问题的意图呈现给系统,告诉系统用户想知道的是“治疗”,而不是“并发症”。中心词面向知识库中的任何一类实体,而疑问词则面向知识库中的关系。

图2 问题关键词划分示例
根据医学知识图谱的内在关系,结合正则表达式构建问题模板以及每个问题模板的中心词和疑问词的字典。中心词的词典通常由知识图谱中节点的内容信息决定,为了提高检索召回率,也将节点内容的同义词引入词典。疑问词的词典由同一语义的疑问词的不同表达构成,以扩大问题覆盖面。疑问词词典在初期通过枚举常见疑问代词(共16个)及其近义词、同义词构成,后期通过问题记录,不断对其进行更新。
在用户输入问题后,利用AC自动机和正则表达式对问题进行匹配,返回中心词和疑问词的具体类别以确定问题模板,交由答案检索模块进行下一步检索工作。
问题与模板是否匹配、匹配的程度如何均取决于中心词和疑问词的匹配程度,由此可以给出如下问题匹配程度的计算方法,如式(1)所示。
(1)
其中,Skey即为关键词的匹配程度。
问题中的关键词与关键词词典中的匹配结果通常有三类: 完全匹配、部分匹配、无法匹配。考虑患者在咨询某种疾病时往往会省略“症”“征”“病”等后缀词,同时也有一些疾病的同义词是其精确表达的子串,如“支气管肺癌”的同义表达有“支气管癌”。为了精准刻画出部分匹配的情况,本文采用最长公共子序列长度作为衡量标准。为了消除关键词本身长度的影响,取词长作为分母,做归一化处理。Skey的计算如式(2)所示。
(2)
其中,LLCS为问题中关键词与匹配所得关键词的最长公共子序列的长度,LS为匹配所得关键词的长度。Skey最大值为1,即完全匹配;最小值为0,即无法匹配,此时需要将该问题进行记录,后期由维护人员根据问题质量决定是否对词典、模板进行更新。
经过测试与试用,对于已收录的关键词,算法匹配成功率较高,达到97.2%;但是对于未收录的疑问词和关键词,系统难以分辨出其问题意图。
3.2 答案检索
答案检索分为两个部分——知识图谱的检索和非结构化医学文档的检索。
3.2.1 知识图谱的检索
本系统的知识图谱采用图数据库Neo4j进行存储,对结果进行查询时使用标准的Cypher语句进行查询。
针对每一种问题模板,设置标准的查询语句。部分模板对应的查询语句如表1所示。表中的Dis、Age等是问题的中心词,分别代表要查询的疾病(Disease)、年龄(Age)实体。

表1 问题模板与查询语句对应关系示例
3.2.2 非结构化医学文档检索
医学文档并非纯粹的非结构文本,大多数有一定的半结构化信息。以《儿科学》[18]教材为例,其小节标题为具体的疾病,正文通常以“病因”“病理”“临床表现”“实验室检查”“诊断”“治疗”“预后和预防”进行划分。经过实践发现,基于标题、小标题、段落层次结构的半结构检索体系不仅能有效找到用户所需的信息,也能节约在海量数据中盲目检索所浪费的时间,降低系统复杂度,能显著提高系统性能。
3.3 融合数据来源权威性与匹配度的答案评分 机制
系统在进行检索时,会同时对知识图谱以及医学文档进行检索,得出答案后对每一个备选答案进行评分,并对所有备选答案按照评分进行排序。对于评分高于阈值的答案,将评分最高的一个或两个答案反馈给用户。若不存在高于阈值的答案,则返回评分最高的答案,并标明来源,提醒用户加以注意。评分的计算方法如式(3)所示。
Sanswer=Spriority+Smatching×λ
(3)
其中,Sanswer表示答案整体评分,Spriority表示数据来源优先级评分,Smatching表示答案匹配程度评分,λ为比例系数,用以平衡两部分赋分单位的差异。
3.3.1 数据来源权威性评分
考虑到不同来源数据的权威性、可靠性不同,因此有必要将数据来源按权威性进行优先级赋分,以排除不可靠的答案,避免对用户造成误导。优先级越高,数据越权威。
医学知识图谱往往需要专业人士参与构建,本文选择儿科医学知识图谱[8]作为知识库,权威性较高,可认为其优先级最高。医学教材选择《儿科学》[18]和《临床儿科学》[19],二者均为业界认可的教材,优先级也设置为最高。临床路径和临床实践文献通常由国际、国家级机构统一制定发布,其特点是权威性高、数据公开可靠,但更新不及时,优先级应次之。真实的儿科病历由于存在病例个体的差异,因此优先级不应过高。医学百科(如百度百科),由于编辑词条者职业、受教育经历的未知性,答案的正确性难以保证,应当将其优先级设置为最低。各类数据来源权威性-优先级赋分如表2所示。
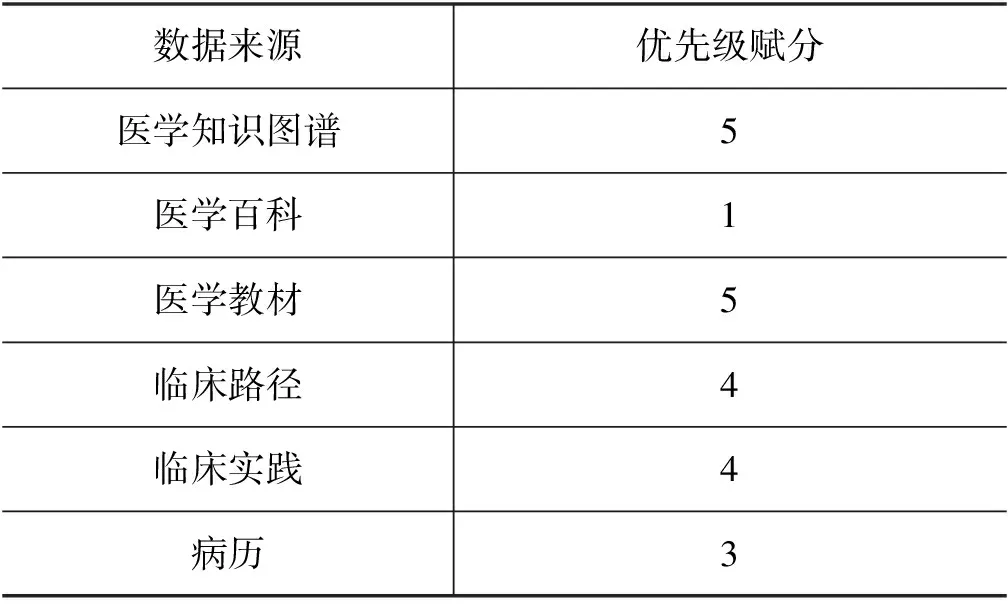
表2 数据来源权威性-优先级赋分表
3.3.2 答案匹配程度评分
答案匹配程度取决于两方面: 问题与模板的匹配程度、答案和中心词的关系与问题疑问词表征关系的一致程度。答案匹配程度评分的计算方法如式(4)所示。
Smatching=Squestion×Srelationship
(4)
其中,Srelationship表示答案和中心词的关系与问题疑问词表征关系的一致程度。
问题与模板的匹配程度决定了查询方案与问题原本意图的匹配程度,如果用户提出的问题与问题模板完全一致,则能匹配到标准的查询方案,此时问题匹配程度应当最高。
答案和中心词的关系与问题疑问词表征关系的一致程度Srelationship主要用于衡量来源于医学文档的答案。来源于知识图谱的数据由模板和查询语句的匹配关系确定,因此应设置Srelationship=1.0,以避免重复影响。
4 数据来源及处理
混合问答系统的答案来源结合结构化的数据(如知识图谱)和非结构化的文本数据。由于医疗领域问答系统对于回答的精确性要求较高,因此需要选择权威性较高的数据。MDPeQA的知识图谱使用来自于北京大学、郑州大学、鹏城实验室共同构建的中文医学知识图谱(Chinese Medical Knowledge Graph, CMeKG)儿科部分[8];非结构化数据来源于医学百科、医学教材、临床路径、临床实践文献及某三甲医院所提供的儿科病历。
4.1 儿科医学知识图谱
儿科医学知识图谱分为疾病体系和保健体系。疾病体系涉及儿科常见疾病500余种,涉及实体11类、关系54种;保健体系涉及儿童成长的6个阶段,涉及实体5类,关系24种。
儿科医学知识图谱的覆盖面较广,实体之间关系划分得较为细致,但考虑到本问答系统的受众是患者或者是大众,而非医学专家,对于某些关系,无须特别细致地划分。原因主要有: ①用户没有受过专业的医学教育,大部分人并不清楚医学名词的含义以及类别划分依据; ②划分过于细致会导致反馈给患者的答案不够全面。
因此,本文对疾病体系中的部分关系进行合并处理,原关系作为合并后关系的属性存在,使回答能够更大程度地满足用户的需求,同时也能降低系统的复杂度,既能确保回答的全面性,又不会因为合并关系失去知识图谱的专业性——在回答大类问题时按合并后的关系检索即可,询问更加专业的类别时,则将关系的属性也作为检索条件。部分合并CMeKG关系表如表3所示。
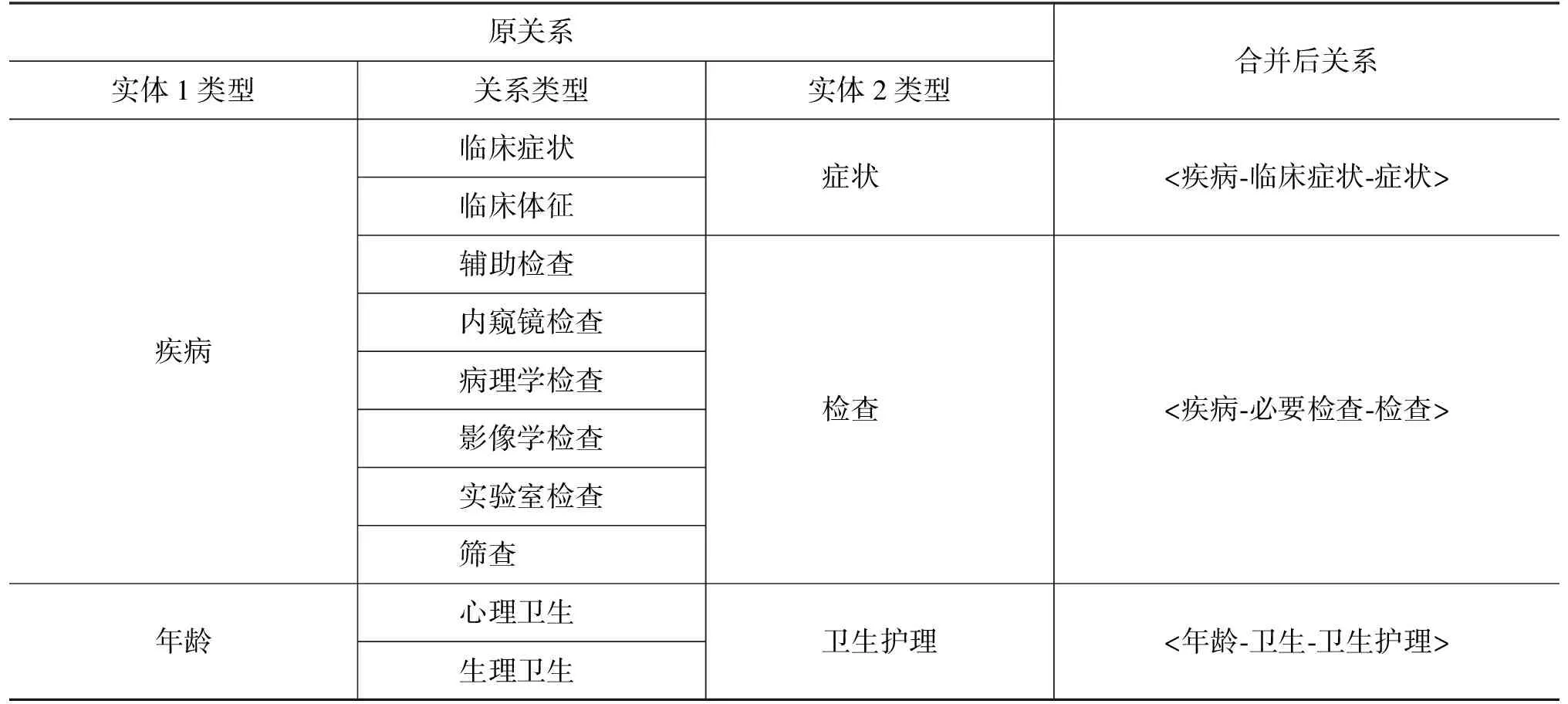
表3 部分合并CMeKG关系表
4.2 文本层级结构的非结构医学文档
系统检索的医学文档分为五大类: 医学百科、医学教材、临床路径、临床实践和儿科病历。
医学百科类以百度百科为主,以国际/国家标准术语集为标准爬取词条信息。考虑到百科类文档的权威性、严谨性、准确性无法保证,仅在人工校对后才开放答案检索,以保证系统的可靠性。
医学教材选取《儿科学》[18]和《临床儿科学》[19]。二者均是国内儿科临床医学专业经典的教材和参考书。《儿科学》主要内容包括儿科学的发展与展望、儿童保健原则、儿科疾病诊治原则、青春期健康与疾病、新生儿与新生儿疾病、感染性疾病、呼吸系统疾病、心血管系统疾病、造血系统疾病、儿童急救等。《临床儿科学》贴近临床,运用国内外流行病学资料,着重反映诊断、治疗、预防及预后动态。全书共分十七篇,内容覆盖儿科各系统疾病,着力于反映儿科特色的生长发育(特别是神经心理发育)、营养、急救和监护、肿瘤。
临床路径是针对某一疾病建立一套标准化治疗模式与治疗程序,是一个有关临床治疗的综合模式,以循证医学证据和指南为指导来促进治疗组织和疾病管理的方法。通常由国家权威机构发布,可靠性很高。
临床实践将最新的研究成果、诊断步骤、治疗步骤、证据等整合在一起,为临床医生和患者提供特定临床情况的处理和指导临床决策支持工具。
儿科病历使用某三甲医院提供的真实儿科病历数据。真实病历的优点在于真实可靠,但是缺点在于病例个性化较强,只可用于部分参考。
5 系统评价及结果展示
5.1 系统评价
问答系统的评价指标通常有正确性、精确度、可解释性和用户友好性[20]。
由于系统数据来源于固定的参考路径,因此系统给出的答案可参考性是较强的,即可解释性较强。因此,对于除去可解释性的其他三个指标,分别对MDPeQA系统、知识图谱检索部分(KB)、非结构化文档检索部分(IR)进行考察,并对文档检索部分和系统整体进行了针对评分机制的对比实验,实验结果如表4所示。

表4 系统各部分实验结果对比
正确性是指系统是否正确地回答了问题。与开放领域的问答系统不同,对于医学领域的问答系统而言,用户常常难以辨别答案的正误,因此答案的正确性就显得更加重要。我们在实验时测试,将问题以及答案反馈给医学专家,进行正误判断,统计得出系统整体的正确性。从实验结果可以看出,知识图谱检索部分的正确性是较高的,错误答案往往是由于知识图谱中没有相关的知识。非结构化文档部分虽然正确性没有知识图谱部分高,但是能够回答知识图谱部分无法检索到的答案,二者互为补充,有机地结合起来使得整个系统地正确性提高了一个档次。
精确度是指答案是否缺失信息、是否包含多余的信息。来自于知识图谱的答案由于知识图谱构建过程的严谨、知识来源的准确、检索过程的规范,往往能达到较高的精确度。由于临床路径、临床实践以及医学教材等是半规范化的数据,通常会有少部分答案精确度较低,占测试用例的6.3%。医学百科中检索出的答案,由于词条质量参差不齐,因此往往精确度难以保证,缺失信息和多余信息的现象时常发生。儿科病历由于病例间的差异较大,也存在检索精确度不高的现象。
用户满意度是用户在使用过程中对答案质量和使用体验进行的评分。考虑到系统面向的是没有医学专业背景的普通用户,用户满意度不可忽略。在系统回答用户输入的问题之后,会邀请用户对答案进行评价。
评分机制是MDPeQA的特色机制。由于知识图谱检索部分不涉及评分机制,因此只对文档检索部分和系统整体针对评分机制进行了对比实验。在没有有效的答案筛选机制时,系统将会返回检索到的所有答案。从表4可以看出,设置了评分机制的系统,在正确性、精确度和用户满意度等方面效果都比没有评分机制的系统好。
从各部分实验结果可以看出,评分机制、知识图谱检索部分和非结构化文档检索部分相辅相成,使得MDPeQA能够取得较好的效果。
5.2 结果展示
用户在咨询“脑积水需要做哪些检查”时,系统查询得到得分最高的答案来源于CMeKG中的儿科部分,便将其注明出处后返回给用户,如图3所示。
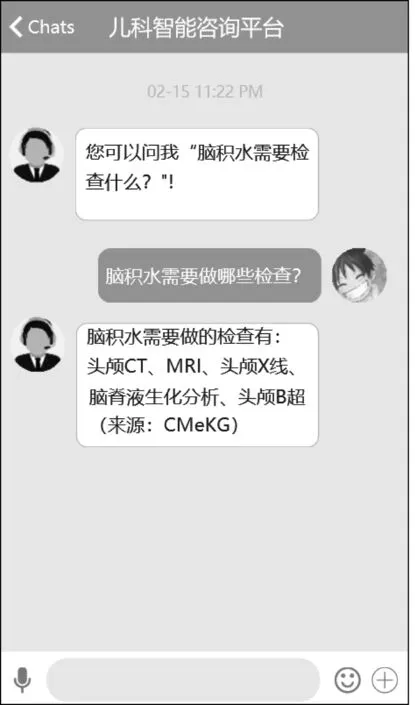
图3 常见疾病相关问答展示
用户在咨询“新型冠状病毒肺炎的症状”时,由于当前知识图谱和可信度较高的医学文档暂时都未对该病做详细记录,因此系统返回来源为百度百科的答案,如图4所示。同时将会对问题进行记录,以便后期及时更新。
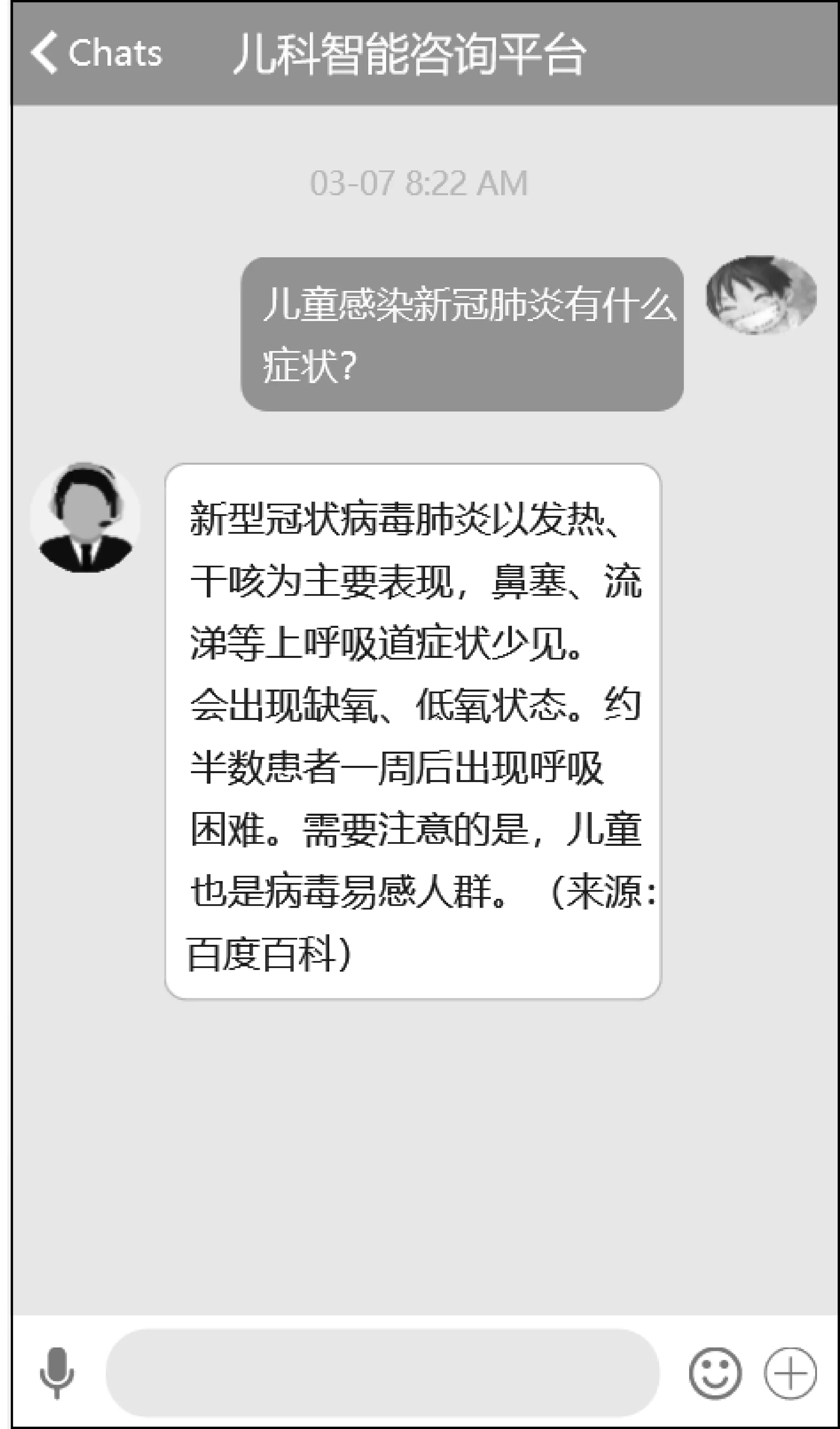
图4 新发疾病相关问答展示
6 总结及展望
MDPeQA是一个面向儿科的、基于知识图谱和信息检索的自动问答系统,能够充分发挥KBQA与IRQA的优势。使用AC自动机和正则表达式,结合句法结构和关键词特征匹配问题和模板。为保证答案的准确性、权威性,本文对于五个不同来源的医学文档按照权威性分别赋予优先级分数。系统引入了评分机制,能够将知识图谱准确且结构化的数据与医学文档全面但准确度无法保证的数据进行量化评价,择优返回给用户。
该系统在河南省某医院投入使用一个月,用户平均满意度为85.43%。分析测试及使用阶段用户所提出的问题及系统给出的答案,可以看出系统能满足大多数用户对于常见病的常见咨询问题,但仍有一部分问题的识别及回答效果较差。问题识别效果的局限在于关键词典过小;回答效果较差的问题多为罕见病或没有意义的问题。
由于采用规则匹配的方式进行问题匹配时关键词词典的大小会限制系统识别问题的能力。在前期,由于缺乏语料,因此依据常识和知识图谱构建了关键词典。对于过于口语化、方言化的问题,系统识别效果较差。在用户使用过程中,系统会对识别效果较差的问句进行记录并人工标注关键词,为后期使用深度学习等方法进行问题识别及分类提供必要的语料。
下一步的工作会从儿科保健、育儿常识两个方面进一步丰富MDPeQA的数据来源,充分利用自然语言处理技术,为用户提供更全面的儿科知识,进一步提高用户体验。
猜你喜欢
军事文摘(2022年24期)2022-12-30
中国毕业后医学教育(2022年2期)2022-10-12
北京航空航天大学学报(2022年8期)2022-08-31
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
少先队活动(2020年12期)2021-01-14
医学新知(2019年4期)2020-01-02
中国循证儿科杂志(2019年1期)2019-03-29
中国循证儿科杂志(2019年6期)2019-03-19
电脑爱好者(2017年7期)2017-05-06
