
软件静态分析融合技术研究*
2022-03-08 06:48:02吴亚锋
火力与指挥控制 2022年1期
王 鑫,赵 伟,吴亚锋
(1.解放军32381 部队,北京 100000;2.江苏自动化研究所,江苏 连云港 222061)
0 引言
军品软件可靠性直接决定武器装备产品的质量,必经多轮测试后方可交付列装。代码规则检查在软件产品研制与测试过程中均至关重要。针对C/C++语言的自动化代码检测工具在大规模代码的多轮迭代及回归中凸显其高效性,但单一工具检测结果存在误检或漏检,且需人工复核以确保准确性,本文提出一种多测试工具代码规则检查报告自动融合的方法,极大缩短了软件迭代测试周期,提升了复查结果准确率,降低迭代测试的时间、经济成本。
1 面向C/C++ 语言静态测试工具及结果比较
LDRATestbedForC/C++、Klocwork、可集成在Visual C++工具中的C++test 以及HelixQAC 工具是4款面向C/C++语言的静态分析工具。除了检查代码的标准符合性,更以图和报告形式实现代码可视化测试,提高了代码测试的可视性和清晰度,其中C++test 更支持代码复审及在线回归。4 款测试工具均支持代码规则定制以及检测结果文本形式浏览。基于工具起动方式、结果输出形式、支持编码语言以及规则可查看角度对工具进行分析,如表1 所示。

表1 工具特性表
上述工具均无法检测出全部违规代码,测试结果之间互有补充又诸多重合,各工具分析代码所依据的规则也并非完全一致。
比对测试结果与原始代码可以发现工具自动生成的测试报告具有以下特征:
1)针对存在问题的同一行源码,不同工具测试结果描述语言不同,具有独特语言风格;
2)不同测试工具检测的同一问题代码,其问题定位信息在不同结果中显示不同。测试报告中的问题代码行数与源码存在差异(工程实践经验该误差通常不大于5);
3)选定参考标准为GB、GJB 后,测试报告中的问题描述与GB、GJB 建立对应关系。测试工具生成的测试报告为英文描述,而GJB 与GB 均为汉字描述,在人工复核检测结果工作中带来不便。
综合上述比对可知,多工具自动化生成的英文检测报告与汉语描述的GB、GJB 之间仍未完全对应,面对规模庞大的代码,人工分析其测试报告在GB、GJB 标中的映射,其时间和人力成本都随代码规模的扩张,呈现几何级数的增长。因此,将工具生成的报告与标准之间建立准确的映射关系,成为提升“最后一步”工作效率的可行手段。
2 基于语义的跨语言文本聚类方法
检测结果与GB 之间的映射关系可以理解为对不同语言之间语义相近的语句分类,描述同一个问题的英文检测结果与其在GB 中的汉字规则描述理论上存在相关性。在自然语言研究中,通常把一个词汇描述为向量,一条语句描述为一个矩阵,语义相近的两句话之间在语义空间上必然存在向量一致性。为解决上文提出的多工具检测报告与规则集映射问题,基于语义的跨语言文本聚类方法体现了其优势。
国内外诸多学者对自然语言文本聚类方法进行了深入探讨,本文采用基于VTM(Vector Term-frequency Model,向量词频模型)完成文本分类。该方法具有以下特点:
1)基于语料库实现跨语言的文本聚类。多测试工具生成的检测报告中全部问题描述语句和规则集构成平行语料库,从各自有限大的语料库中提取文本分类所需要的信息。通过平行语料库完成语句分类可以避免传统模式的先翻译,再将翻译结果进行分类带来的大量计算,全部聚类过程处于语义和概念层面,更多结合自然语言的涵义。
2)借鉴Word2Vec模型完成“语句- 向量”转换。Word2vec 模型最早由Mikolov 提出,由图1 可知,由CBOW 模型和Skip-gram 模型构成。

图1 Word2Vec 模型数学表达示意图
CBOW 模型由词的前后m 个词汇出现的概率决定词A 出现的概率,其数学表达式如下:

类似地,Skip-gram 模型则是由上下文n 个词汇预测词A 出现的概率,其数学表达式如下:

Word2Vec 是自然语言研究中将词语划分为实数值向量表达的深度机器学习工具,在词向量训练中涵盖语料的上下文,从语义的层面解决了跨语言文本分类主题漂变和语言隔离问题。同时
Word2Vec 工具训练高效,300 M 语料词向量的训练时间仅40 min 左右。
2.1 文本的向量表达
采用Word2Vec 模型,将一段文本S 描述为一组向量V(T),向量存在一个几何中心,如同该文本存在一个核心词。核心词定义为Core(S),其归一化向量表达形式如下:

如式(2)所示,归一化向量表达式描述了文本S的几何中心,也是该文本向量表示。
2.2 基于加权词频的文本向量表示
本文用TF-IDF(Term Frequency-Inverse Document frequency)方法确定式(2)中的词向量权重。TF-IDF 是一种常用数据挖掘的加权技术,TF(Term Frequency,词频)表示目标词在文本中出现的频率,体现该词在文本中的重要程度,IDF(Inverse Document Frequency,逆向文本频率)用度量目标词的普遍性,反映了该词在文本集中的识别度。TF-IDF 是TF 与IDF 的乘积。
假设一个预料库D 中存在一段文本包含N 个的词(其中k 个词不重复),对于一个词T而言,其重要性可表示如下:

文本中每个词的权重向量可表示如下:

通过式(9)可以得知,在有限语料库场景下,基于词频的文本权重向量表达式与TF 无关,仅需要计算IDF 即可得出一段文本的权重向量表达式。
2.3 相似性测度计算


图2 基于语义的检测结果规则聚类流程图
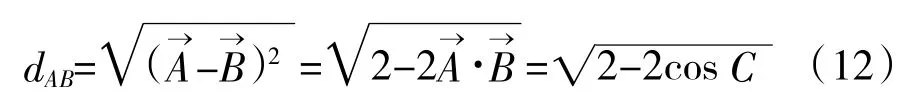
此时两文本之间欧氏距离等价于余弦距离,在文本分类中以此为相似性测度。当两个文本相似性测度(欧氏距离)大于设定阈值时,判定为语义相近。至此完成跨语言的文本聚类。
3 基于语义的检测结果与规则集聚类流程
首先,建立包含检测结果与规则集的平行语料库,语料库内容如图3 所示,运行图4 代码,完成文本向量表达和文本向量距离计算。

图3 平行语料库截图

图4 文本向量相似性计算实现
表2 中第1 列选取了5 条检测结果,每一行对应计算该检测结果与规则集之间的相似性测度计算值,对于成功匹配的两条文本相似性计算结果加粗标明。可见,两条文本语义上接近的相似性测度值更大,与无关文本相似性测度存在明显的分离性,可以通过合理的相似性测度阈值加以区分。

表2 检测结果与规则集相似性计算
上述方法仅实现检测报告与规则集之间映射关系,检测结果之间仍存在重合与互补。检测结果自身携带问题代码路径Path 以及所在函数中行数Line 可区分问题代码。类似的,规则集的常见形式是:“编号ID+规则描述”,编号即一个规则在其集合中的唯一识别。规则描述与检测结果完成映射,意味着“Path+Line”与“规则ID”之间建立映射。根据测试工作实践,问题与规则之间的关系如下页图5所示。
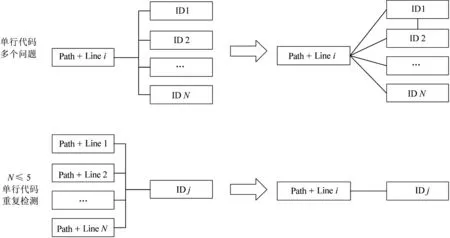
图5 问题代码路径与规则标识关系图
对于近似行代码对应单规则ID 情况判定为重复检测,任选其一作为最终结果;单行代码对应多个规则ID 情况判定为结果互补,保留不重复ID规则。至此完成多工具检测结果与规则集合的融合匹配。
4 结论
本文结合静态测试实践,整理代码规则检查工具,针对C/C++语言检查结果。以检测结果及规则集作为有限集语料库,以文本加权词频向量之间的相似程度为判别条件进行相似性判断,并对聚类文本进行去重及融合,达到检测结果互相补充、彼此完善的目的。实现了多工具检测结果与规则集智能匹配,提高了代码级规则检测效率。本文介绍了文本词频向量表达聚类算法在多工具检测结果与规则集之间的匹配方法,仍存在优化空间。文中相似性测度算法值得在未来研究中完善优化,同时面向更多种类语言的代码规则检测结果融合也具有较高的研究价值。
猜你喜欢
数学物理学报(2022年5期)2022-10-09 08:56:44
河北画报(2020年8期)2020-10-27 02:54:20
天津外国语大学学报(2020年1期)2020-03-25 13:29:26
动漫星空(2018年11期)2018-10-26 02:24:02
动漫星空(2018年2期)2018-10-26 02:11:00
动漫星空(2018年9期)2018-10-26 01:16:48
动漫星空(2018年5期)2018-10-26 01:15:02
作文评点报·低幼版(2017年13期)2017-04-18 18:15:11
浙江大学学报(工学版)(2016年2期)2016-06-05 09:20:51
语言与翻译(2015年4期)2015-07-18 11:07:45
