
锚和通道注意力相结合的车道检测算法
2022-03-07 04:34韩尚君余艳梅陶青川
现代计算机 2022年24期
韩尚君,余艳梅,陶青川
(四川大学电子信息学院,成都 610065)
0 引言
随着传统汽车行业与人工智能技术的结合,各种计算机视觉技术已被证明是保证自动驾驶安全可靠的[1]不可或缺的一部分。为保证自动驾驶的实用性和有效性,车道检测是至关重要的。随着卷积神经网络(convolutional neural networks,CNN)[2]的发展,深度学习的快速发展和设备能力的改善(如计算力、内存容量、能耗、图像传感器分辨率和光学器件等)提升了视觉应用的性能和成本效益,并进一步加快了此类应用的扩展。与传统CV 技术相比,深度学习可以帮助CV 工程师在图像分类、语义分割、目标检测和同步定位与地图构建等任务上获得更高的准确率,故目前自动驾驶的研究热点已转移到深度学习方法上来[3-6]。
车道检测对于自动驾驶而言是极为重要的一步,首先它可以使车辆行驶在正确的道路上,对于后续的导航和路径规划也是至关重要的,同时它也具有挑战性,因为交通、驾驶环境、障碍物、天气条件等各种内外部复杂条件都会产生巨大影响。对于车道检测的研究主要有两种方法进行解决——传统方法和深度学习方法。
传统方法主要是通过手工提取特征,然后将其与滤波器进行结合,得到分割的车道线,最后过滤部分错误车道得到最终的检测结果。目前已经有研究使用深度网络来取代手工提取特征来进行车道检测:Huval 等[7]首次将深度学习方法应用于CNN 的车道检测;Pan等[8]通过提出一种相邻像素之间的消息传递机制SCNN显著提高了深度分割方法对车道检测的性能;Li等[9]提出了一种端到端的高效深度学习系统Line-CNN(L-CNN),在实时环境中试验显示,优于当时最先进的方法,显示出更高的效率和效率;Tabelini 等[10]提出了一种基于锚的单阶段车道检测模型LaneATT,其架构允许使用轻量级主干CNN,同时保持高精度。
本文提出的模型LaneEcaATT 是在基于锚的单级车道检测模型LaneATT 的基础上进行改进,添加了通道注意力机制ECAnet[11],将ECAnet和轻量级主干网Resnet[12]相结合,在保持FPS 和MACs 指标基本不变的情况下,提高了车道检测的准确率。本文在两个公开数据集Tusimple[13]和CULane[8]上评估了本文的方法,同时与LaneATT的结果进行了比较。
1 相关技术
1.1 LaneATT算法[10]
LaneATT 是一种基于锚的单阶段模型,用于车道检测。LaneATT 算法主要由主干网Resnet、基于锚的特征池化层、注意力机制和结果预测层组成。
1.1.1 LaneATT的主干网
卷积神经网络(CNN[2])是一种模拟生物的神经结构的数学模型,通常用于目标检测、图像分割、车道检测等方法的特征提取。理论上CNN 网络随着深度越深,就能获得更加丰富的特征信息,但是在实际实验中,网络的深度并不能无限制地增加,网络深度达到瓶颈之后,效果反而更差,准确率也随之降低。
通过添加如图1所示的残差块,将多个相似的Residual Block 进行串联构成Resnet[12]。根据不同的需求,残差块有两种形式,一种是图1左边的形式basic block,它由两层3 × 3 的卷积组成,输入输出的维度相同;另一种是图1右边的形式bottleneck block,通过使用1 × 1 卷积层实现了先降维再升维的过程,此方法可以降低计算复杂度。Resnet通过引入残差块在一定程度上解决了梯度消失和梯度爆炸的问题,从而能够训练更深的网络。相比于VGG[14]网络,Resnet网络不仅更深而且模型的尺寸和参数量更小,LaneEcaATT 使用Resnet18、Resnet34、Resnet101 作为主干网来提取图片特征。
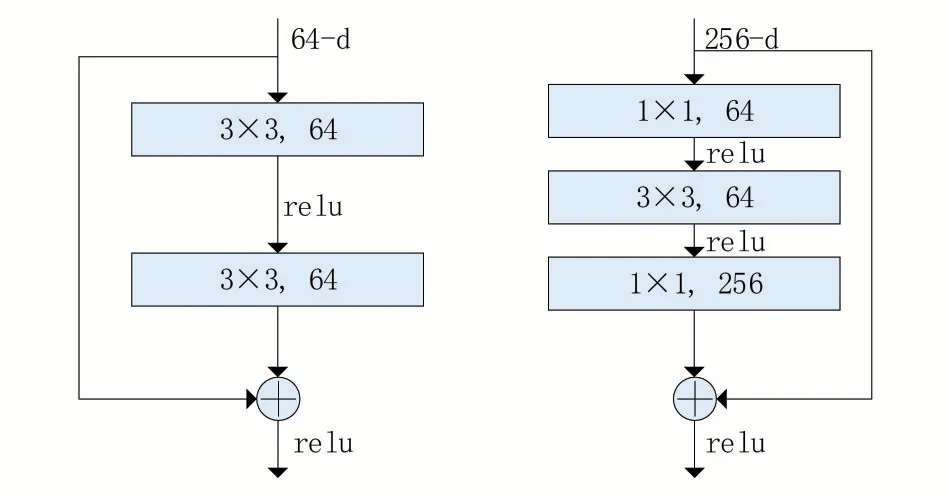
图1 bottleneck block[12]
1.1.2 基于锚的特征池化层
LaneATT 的池化操作借鉴了Fast R-CNN[15]的感兴趣区域投影(ROI 投影),区别在于检测的时候使用的是线。相比于Line-CNN[9]只利用了特征图的边界,LaneATT 在一定程度上可以使用所有的特征图,故LaneATT 可以使用更小的主干网和更小的接受域。一个锚就定义了一个候选点集F,将锚所构成虚线上的特征进行串联,对于超出图片边界的点做补零操作以保证串联后的维度恒定,。对于每一个yj=0,1,2…HF-1,的计算公式如式(1)所示:
其中(xo,yo)是锚线的原点,θ是锚线的斜率,δback是主干网的全局步长。
1.1.3 LaneATT的注意力机制
对于大多数轻量级模型来说,获取的是局部特征向量。但是在某些复杂的场景下,例如有其他物体遮挡视野或目标部分消失的情况下,局部特征可能无法预测车道是否存在以及其位置。为解决这一问题LaneATT 提出了一种新的注意力机制Latt[10],它利用局部特征来生成附加特征,将其和局部特征结合得到全局特征。对于每一个局部特征向量,当i≠j的时候,输出一个权重ωi,j[10],如公式(2)所示:
1.2 ECAnet模型[11]
通道注意力机制可以提升CNN网络的性能,但现有的算法为获得更加优秀的效果,大都选择复杂的注意力模块而忽略了算法应用于轻量级模块和实时运算的情况[11]。
SENet[16]的降维会给通道注意力机制带来副作用,并且没有必要获取通道之间的依赖关系。ECAnet 将原始的SENet 与它的三个都没有降维的变体(SE-Var1,SE-Var2 和SE-Var3)进行了对比实验:SE-Var1 虽然没有参数但是性能仍然优于SENet,说明在提高深度CNN 的性能上面通道注意力是有用的;SE-Var2 在每个通道独立地学习权重且参数较少,结果也是优于SENet,说明通道及其权重需要直接对应,而且避免降维比非线性通道依赖更加重要;SE-Var3 比在SE块中少使用一个FC 层进行降维,结果显示性能更好[11]。综合ECAnet 的实验可以表明,避免降维对于通道注意力机制的性能有很大的提升,故ECAnet 在SENet 的基础上进行改进,ECAnet通过一维卷积来实现了一种不需要降维的局部交叉通道交互策略。ECAnet 的模型结构如图2所示。

图2 ECAnet结构[11]
1.3 锚和通道注意力相结合的车道检测算法LaneEcaATT
本文提出的算法模型LaneEcaATT(如图3 所示)在LaneATT 的基础上添加了ECAnet(如图3圆角矩形所示),以提取局部特征。模型的输入图像经过主干网Resnet 和ECAnet 提取特征,利用基于锚的特征池化层提取感兴趣的锚线,进而生成局部特征,局部特征通过注意力机制生成全局特征,将局部特征和全局特征进行结合,最后将组合特征传递给全连接层得到最终预测的车道。

图3 LaneEcaATT的模型图
2 实验
2.1 实验参数设置
本文的方法在两个最常使用的车道检测数据集(Tusimple[13]和CULane[8])上进行测试,两个数据集的具体信息如表1所示,所有的实验都使用了数据集的创建者默认的参数。
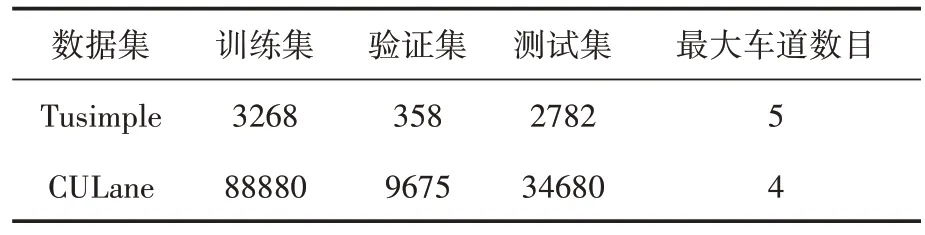
表1 数据集信息
实验中的所有输入图像都被调整为HI×WI=360 × 640 像素,对于两个数据集都使用Adam优化器,Tusimple训练100个epochs,CULane训练15 个epochs,通过随机的平移、旋转、缩放和水平翻转来进行数据增强。本文实验部分的效率指标分为每秒帧数(FPS)和乘积累加运算(MACs)。
2.2 Tusimple数据集上的实验
2.2.1 Tusimple数据集
Tusimple[13]是一个只包含高速公路场景的车道检测数据集,通常相对于街景来说,这个场景作为车道检测会更容易。但是它仍然是在车道检测工作中使用最广泛的数据集之一。所有的图像都有1280 × 720像素,最多有5个车道。
2.2.2 Tusimple数据集上的评价指标
在Tusimple 数据集上三个评价指标分别是错误发现率(FDR)、假阴性率(FNR)和准确性(Accuracy)。
准确性Accuracy如公式(4)所示:
其中,Cclip是切片中正确预测车道的点数,Sclip是图片中总的点数,预测点必须是在真实图像点的20个像素内才能被认为是正确的点。
2.2.3 Tusimple数据集上的实验结果
表2是本文模型在Tusimple数据集上得到的检测结果。可以看出,本文的方法LaneEcaATT在MACs 和Params 上基本上没有任何增加,FPS也基本持平。在准确率上本文均优于LaneATT,甚至在使用Resnet18 作为主干网的情况下,比LaneATT 使用Resnet34 的准确率还要高,但MACs 减少了50%,Params 减少了45%,FPS 提升了44%。虽然在Resnet18 和Resnet34 上FDR比较高,但是在FNR 方面则是都优于LaneATT。图4 是LaneEcaATT 和LaneATT 在Tusimple 上 的检测效果对比,LaneEcaATT 的检测效果要略优于LaneATT的检测效果。
结合表2 和图4,在Tusimple 数据集上,本文算法的准确率都得到了提升,尤其是在Resnet18 上达到了LaneATT 在Resnet34 上的准确率。(左中右依次是原图、LaneATT、LaneEcaATT;上中下分别是Resnet18、Resnet34、Resnet101;黑色线条是真实车道,灰色线条是检测结果)
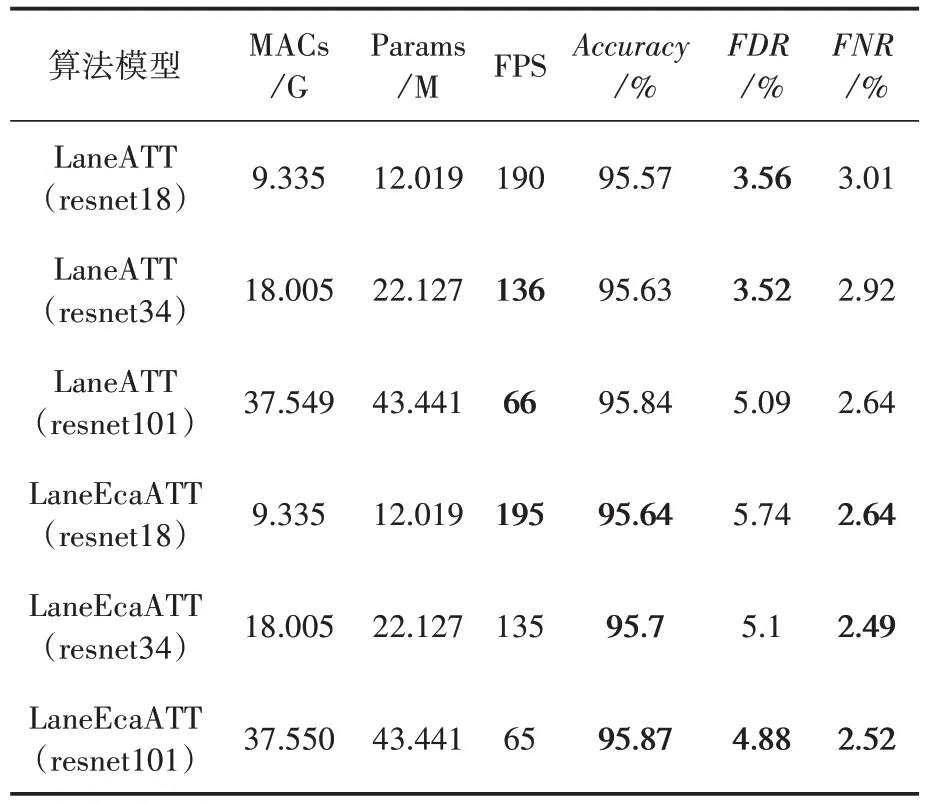
表2 Tusimple数据集结果

图4 Tusimple数据集实验结果
2.3 CULane数据集上的实验
2.3.1 CULane数据集
CULane[8]是最大的公开车道检测数据集之一,也是最复杂的数据集之一。所有图像大小均为1640 × 590 像素,测试图像分为九类,包含正常、拥挤、夜间、无可见线等。
2.3.2 CULane数据集上的评价指标
在CULane 上有三个评价指标Precision、Recall、F1。
Precision是计算正确预测占整个正确预测与错误预测之后的百分比,如公式(5)所示:
Recall是计算正确预测占正确预测与假阳性之和的比例,如公式(6)所示:
在式(5)、式(6)中,TP是正确预测车道的数目,FP是错误预测车道的数目,FN是假阴性的数目。
F1 是基于IOU(intersection over union)来进行判断的。IOU 的评价标准是根据两个区域的交集占比,官方将车道线视为30像素值宽的线,如果预测出来的车道和真实车道的IOU大于0.5,那么就会被认为预测正确,F1 如公式(7)所示:
2.3.3 CULane数据集上的实验结果
考虑到CULane 数据集图片大小和Resnet 深度,在CULane 数据集上本文在Resnet18 上将ECAnet 的一维卷积核大小k保持为3,在Resnet34 和Resnet101 将k修改为5,整个CULane 数据集的测试结果见表3,表4 展示了从normal到night的九类场景的F1参数数据。
通过表3、表4 可以得到,Resnet18 运用本文方法后在Recall上提升0.4个百分点,hlight上提升1.66 个百分点,arrow 上提升1.24 个百分点,在curve上提升1.15个百分点,在night上提升0.99 个百分点。Resnet34 上运用本文方法后在Precision 上提升0.04 个百分点,cross 错误量降低了28 个百分点,但是F1 值有所下降。Resnet101 上运用本文方法后在Recall 上提升了1.04 个百分点,在noline 上提升了0.88 个百分点,在curve 上提升了1.26 个百分点。图5 是Lane-EcaATT和LaneATT在CULane上的检测效果对比。
结合表3、表4 和图5 的结果,可以看出在CULane 数据集上,本文算法在Resnet18 网络结构上改进效果较好。

图5 CULane数据集实验结果
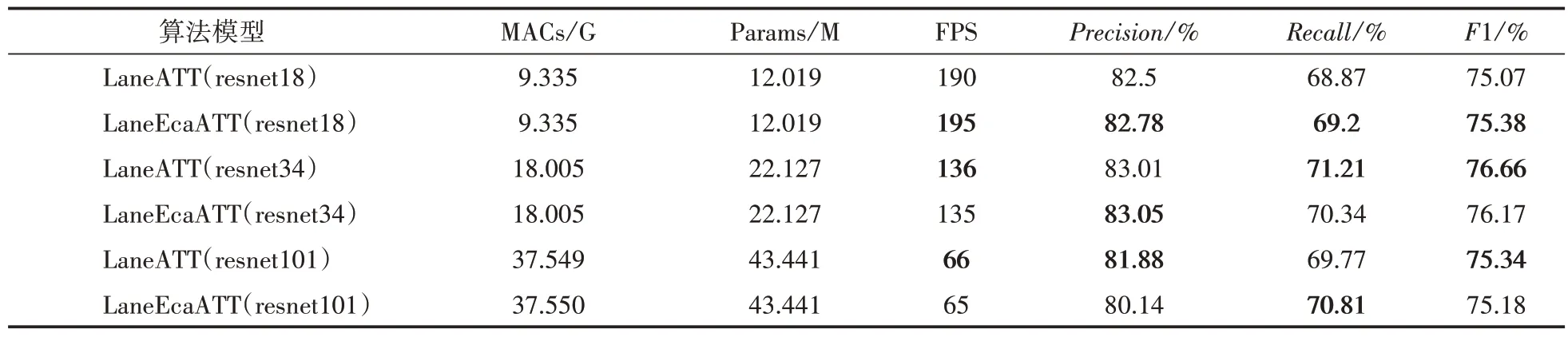
表3 整个CULane数据集的结果

表4 CULane数据集九类场景的F1结果
3 结语
本文改进的车道检测算法LaneEcaATT 不仅有着高准确率,同时还保持快速的检测速度。在Tusimple 数据集上,本文方法比原始模型检测准确率更高,甚至可以用更浅的主干网实现不错的检测效果。在CULane 数据集上,本文方法在Resnet18 网络结构下表现优于原方法,但是在另外两种网络结构下的表现有待提升,将在后期研究中进一步改进。
猜你喜欢
中国教育网络(2022年1期)2022-04-12
卫星应用(2021年11期)2022-01-19
科学大众(2021年9期)2021-07-16
中国交通信息化(2020年11期)2021-01-14
海洋信息技术与应用(2020年2期)2020-07-27
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
中国教育网络(2019年10期)2019-12-13
井冈山大学学报(自然科学版)(2019年4期)2019-09-09
中国交通信息化(2016年10期)2016-06-08
