
基于自注意力特征融合的半监督生成对抗网络用于SAR目标识别
2022-03-07 07:53应自炉王发官翟懿奎王文琪
信号处理 2022年2期
应自炉 王发官 翟懿奎 王文琪
(五邑大学智能制造学部,广东江门 529020)
1 引言
合成孔径雷达(Synthetic Aperture Radar,SAR)采用相干成像原理,通过接收不同位置的回波信号进行相干处理,以此来获取高分辨率的图像。SAR具有很强的穿透能力,不受光线强度和天气的影响,可以实时地对地监测,因此被广泛应用到民用和军事领域[1]。然而,SAR图像缺乏足够量的标签,对其进行标注需昂贵开销。除此之外,SAR 图像充斥着散斑噪声和特有的几何畸变特征,不能像光学图像一样准确地用肉眼判别出来。因此,SAR 目标识别技术成为近年来的研究热点和难点。
针对以上挑战,一些传统的SAR 目标识别模型通过结合机器学习和图像特征提取方法来解决问题。文献[2]通过目标类型以及传感器,目标和地面的相对方向参数化了条件高斯模型,提出了用于SAR 图像的条件高斯信号方法。文献[3]提出了一种新的聚类模板自动生成算法,该算法解决了模板生成姿态角依赖性问题,提高了识别性能。Zhao 等人[4]将支持向量机应用到了SAR 目标识别任务,并与常规分类器进行了比较。Sun 等人[5]通过原始特征补偿目标估计误差,使用Adaboost 算法对SAR 图像进行分类。然而,上述算法严重依赖于经验选择,过程繁琐复杂,而且设计的模型泛化性能差,无法得到高效的识别效果。
近年来,随着大数据时代的来临和计算设备的不断更新完善,深度学习得到了快速发展。卷积神经网络(Convolution Neural Network,CNN)是现有深度学习算法中最具代表性的模型,CNN 本身具有空间不变性和通道特异性,利用权值共享和局部感受野很容易从图像中提取结构特征,从而可以有效地解决视觉分类和识别等任务,如ResNet[6]、Shuffle-NetV2[7]和MobileNetV2[8]等是近年来出现的经典的CNN 架构。成功的训练出高效的CNN 网络有两个必要条件:适当的网络结构和含有丰富信息的充足的带标签数据集。虽然CNN 网络结构的设计在不断的改进,但现有的带标签的SAR 图像极其有限并且难以获得。为了缓解监督学习方法对大量标注数据的迫切需求,提出了同时使用有限的标签数据和未标签数据的半监督学习方法。文献[9]设计了一个由分类网络和重构网络组成的半监督SAR 目标识别框架,解决直接将CNN应用于SAR目标识别时,可能会产生过拟合的情况。文献[10]设计的半监督学习框架通过自一致增强规则迫使扩增前后样本共享相同标签,然后混合标签和无标签样本,在识别SAR 图像上得到了不错的效果。文献[11]将深度学习技术与与基于传统散射特征分类器结合,提出了用于极化SAR 图像半监督分类方法。这些半监督学习的方法在有限标注样本的数据集上,一定程度提升了深度学习系统的训练和识别能力。
Goodfellow 等人[12]在2014年提出了生成对抗网络(Generative Adversarial Network,GAN),旨在学习原始图像的特征分布,自动生成可以以假乱真的伪样本。Radford等人[13]将CNN与传统的GAN结合到一起做无监督训练的深度卷积生成对抗网络(Deep Convolutional Generative Adversarial Netwotrks,DCGAN),利用CNN 强大的特征提取能力来提高生成对抗网络的生成结果。目前,GAN 及其变体已经应用在图像翻译、图像超分辨和图像识别等方面。Cai 等人[14]提出了深度生成对抗网络,通过多任务学习来执行联合人脸完成和人脸超分辨率。Cao等人[15]提出通过标签定向生成网络为模型训练提供标记样本,提升模型的识别精度。Emami[16]将注意力机制引入到GAN 架构中,帮助生成器将注意力集中在源域和目标域之间最有区别的区域上,从而获得更逼真的输出图像。GAN 除了在无监督领域备受关注外,许多研究学者将GAN 与半监督方法进行了结合,研究了GAN 在半监督学习中的适用性。Salimans等人[17]首次提出了利用DCGAN 为基础架构进行了半监督分类训练并取得了优异的结果。Cui 等人[18]通过利用生成对抗网络生成样本,并为生成样本设计一个选择滤波器提高新生成训练样本的质量。Odena[19]等人利用判别网络输出类标签,将该网络转化为半监督网络,从而产生高质量的图像。Mirza 等人[20]通过添加类约束作为监督信息,允许网络在生成类标签的同时生成图像。Zheng 等人[21]使用GAN 生成的样本作为CNN 的训练样本,该方法通过GAN 生成的未标记图像扩展到真实有标记的训练集中,并将半监督学习方式整合到网络训练中,有效的提高了分类精度。
然而,与上述大多数研究使用的光学图像不同,SAR 图像的基本特征难以捕捉,难以建立跨图像区域的长距离、多层次依赖关系,从而导致GAN网络敏感性和不稳定性加深。针对以上难点问题,本文提出了基于自注意力特征融合的半监督生成对抗网络(Semi-supervised Generative Adversarial Network Based on Self-attention Feature Fusion,SAFSGAN)用于SAR 图像目标识别。首先,为解决长距离、多层次依赖问题,本文在网络中引入了自注意力[22]模块,有效地对SAR 图像的全局特征进行利用。其次,将经过不同层级的特征进行融合,捕获SAR 图像的关键信息。然后,为保证网络生成图像的细节信息分布与原始图像保持一致,在生成器的损失中引入了特征匹配损失。最后,为使网络的训练过程更加稳定,利用谱归一化代替批归一化层[23]。实验结果表明,在训练样本有限的情况下,该方法的识别精度具有一定竞争力。
2 本文方法
2.1 整体网络结构
本文采用半监督学习对GAN 进行训练。与经典GAN 不同,判别器不再是仅用于鉴别图像真伪的二分类器,而是将半监督GAN 中的判别器看作一个多分类器。具体来说,判别器就是预测样本x是否属于真实数据分布,它从n类中赋予每个输入图像一个标签y。本文提出的SAF-SGAN 算法的总体框架如图1所示,其中,生成器和判别器都使用了谱归一化。谱归一化技术在判别器中可以通过谱范数达到约束利普希茨常数的目的,在生成器中使用谱归一化可以防止参数放大和避免不寻常的梯度,从而使整个网络的参数更加平滑,训练过程更加稳定[24-25]。同时,在生成器和判别器中集成了自注意力模块,使两者能够捕获到长范围的依赖关系。
2.2 生成器模型
生成器模型如图2 所示,将100 维的随机噪声作为生成器的输入,经过线性映射和重塑,转换为4 维张量,再经过反卷积和自注意力模块,输出为64×64 图像。在反卷积过程中,通过将卷积核尺寸设置为4×4,有效避免了反卷积过程中容易产生的棋格子状伪影现象。在生成器网络中除了输出层使用Tanh激活函数,其他层均采用ReLU激活函数。训练生成器时通过引入特征匹配损失,使得生成图像更加逼真。生成器的作用就是生成无标注的图像来辅助提高判别器的性能,生成器网络的详细参数见表1。

表1 生成器网络结构表Tab.1 Generator network structure table
2.3 判别器模型
判别器含有8 个卷积层和3 个自注意力模块,且使用LeakyReLU 激活函数和谱归一化构建网络。具体操作如图3 所示,将生成图像或原始图像喂入到判别器中,经过8 个卷积层,在第4、第6 和第8 层卷积层后面分别跟上自注意力模块。在经过前两个自注意力模块得到的特征图分别经过最大池化层与最后一个自注意力模块得到的特征图进行融合,随后输入到下一个全连接层中。最后,接入Softmax层。需要说明的是,判别器网络中自注意力模块的引入是为了有效提取图像全局的纹理特征和几何特征。除此之外,判别器同时采用了最大池化层,用以提取不同阶段特征的显著信息,同时也降低了卷积层对位置信息的敏感性。然后,特征显著信息可以通过特征融合更加突出地显现出来,判别器网络详细参数如表2所示。
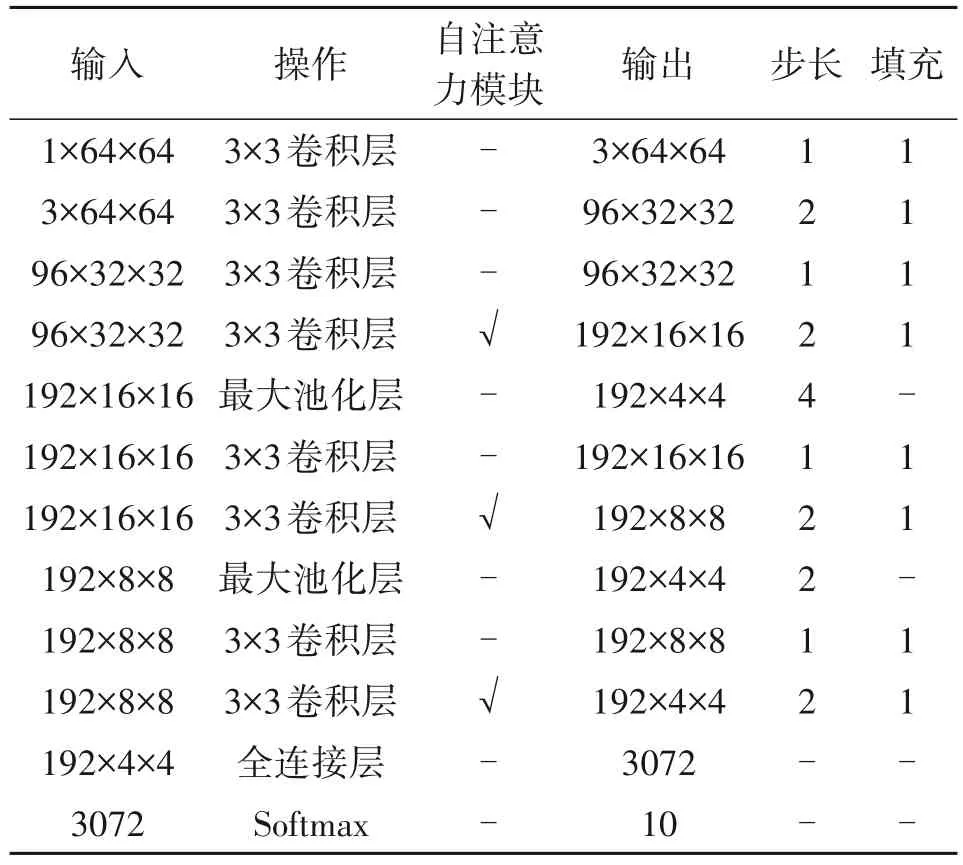
表2 判别器网络结构表Tab.2 Discriminator network structure table
2.4 自注意力模块
受非局部均值算法的启发,文献[22]提出了非局部模块,又称为自注意力模块,此模块能够使神经网络获得图像上的任意两个位置之间的互信息。自注意力模块用于捕获长范围依赖,成为计算机视觉领域的通用模块。具体操作如下:
首先,自注意力模块将在前层网络提取到的,含有C个通道的特征图x经过三个1×1卷积层分支,每个分支输出通道数分别为C/8,C/8和C,得到特征空间f(x),g(x)和h(x),其中:
然后,f(xi)的转置与g(xj)相乘,再经过Softmax函数归一化得到注意力权重βj,i。
其中,βj,i表示在合成第j个区域时对第i个区域的相似度。N表示特征图中特征位置的数量。其次将注意力权重加权到特征空间h(x)上,将加权过后的特征图经过1×1 卷积层,所以注意力层的输出oj可以表示为:
在上述公式中,Wf、Wh、Wg和Wv均是1×1 卷积层的权重矩阵。进一步,注意力层与一个尺度参数相乘,再与输入特征图相加,得到最终的输出yi,如公式(7):
其中μ是一个可学习参数并且初始值为0。这使得生成器在生成样本时不再局限于相邻点,而是全局的任意两个位置之间的信息计算,其相当于设计了一个和输入特征图一样大小的卷积核,可以学习到丰富的全局信息,因此生成器会使生成的样本与真实样本更加接近,收敛速度也相应加快。
在自注意力模块的作用下,生成对抗网络克服了传统神经网络只能在图像像素领域操作的问题,从而学习到更多图像的细节信息。在本文中,生成器和判别器中均引入了自注意力模块,判别器可以判断出图像的远端细节信息分布是否与其他细节保持一致。
2.5 损失函数
损失函数是用来评估生成图像和原始图像之间差异的,同时也是生成对抗网络的优化目标。损失函数的值越小代表生成图像与原始图像之间的差异越小。恰当的损失函数可以提供准确梯度信息,从而提高整个模型的性能。遵循上述原则,在设计生成器的损失函数时,只需最小化它的输出虚假图像概率Lfake,即:
其中D(G(z))表示输入为生成图像时,判别器输出的第n+1维。通过在生成器损失函数中引入特征匹配损失,期望生成图像能够匹配真实图像,以达到对生成模型的约束,获得高质量的生成图像。特征匹配损失Lfeat定义为:
其中,θ(·)表示判别器中间层特征的激活函数的输出。因此生成器的总损失函数LG公式(8)和公式(9)之和,如公式(10):
在本文中判别器的损失函数由无监督学习损失Luns和监督学习损失Ls两个部分组成。对于无监督学习来说,通过利用无标签数据计算无监督损失,不需要计算标签损失,只依赖于对真假的判断来构建损失:
而监督学习部分的损失函数LS使用交叉熵:
Di(x)表示当输入为真实图像x时,判别器第i维的输出。yi表示第i维标签。在训练判别器时引入参数α来控制无监督损失。因此,判别器的总损失函数为:
3 实验结果与分析
3.1 数据集设置
本文在美国国防高等研究计划署推出的运动与静止目标获取和识别(Moving and Stationary Target Acquisition and Recognition,MSTAR)公开数据集上验证了该方法的性能,该数据集含有在各个方位角下获取的多种车辆目标的SAR 图像。在实际的实验中,采用标准工作条件下(Standard Operating Conditions,SOC)采集到的十类MSTAR 数据集,以俯仰角为17°和15°的图像分别作为训练数据和测试数据,数据集使用的具体配置见表3。

表3 SOC下十类MSTAR数据集Tab.3 Ten types of MSTAR datasets under SOC
所有样本通过中心裁剪将图像大小设定为64×64 像素。在训练SAF-SGAN 过程中,SOC 下的十类MSTAR 的训练集首先被分为两部分:按1∶2,1∶3,1∶4,1∶8,1∶16 和1∶32 的比例随机抽取每类数据作为有标签样本,剩下的训练数据作为无标签样本。在测试过程中,测试集采用标准工作条件下十类MSTAR数据集的测试集的所有样本。
3.2 实验环境及参数配置
本文实验的编译环境统一在Ubuntu 18.04 系统,采用CUDA 10.1和开源的Pytorch深度学习框架进行训练。实验采用参数为β1=0.9,β2=0.99 的Adam 优化器,学习率设为0.0003,LeakyReLU 层的斜率设为0.1,共训练500轮。
3.3 不同标签样本下的实验
为验证本文提出的方法在含有不同数量标签样本下的性能,对每类MSTAR数据集分别按1∶2,1∶3,1∶4,1∶8,1∶16和1∶32的比例抽取标签样本。如上所述,这些标签样本都是随机选取的,并且六个独立实验所选取的样本也不尽相同。实验过程中将判别器单独作为分类器,同时利用标签样本对分类器上进行有监督训练并获得监督识别精度(Supervised Recognition Accuracy,SRA)。表4 分别记录了在不同标签样本下SAF-SGAN 和SRA 两种方法的实验结果,从结果中可以看出与仅使用带标签样本的监督学习模型相比,使用半监督生成对抗网络的方法可以显著提高识别精度。当标签样本数量最少时,与监督学习模型相比,半监督生成对抗网络模型在识别准确率方面有较大改善,识别精度相对提高了9.84%,当标签样本数量最多时,识别精度提高了4.91%,平均相对识别精度提高了8.62%。这进而说明半监督生成对抗网络方法可以结合生成图像、无标签图像和带标签图像共同训练使模型学习更多的数据特征,从而提高模型识别精度。从表4的实验数据可以发现,本文所提出的SAF-SGAN 随着标签样本数量的增加,识别准确率也逐渐提高。在每个类别仅含有原始数据的四分之一带标签样本时,本文提出的SAF-SGAN 方法训练出来的模型识别准确率超过了监督学习方法下使用整个数据集的识别率。

表4 不同数量样本下的识别精度Tab.4 Recognition accuracy under different number of samples
为了展示本文方法在不同类型目标识别准确率上的改进,表5和表6分别描述了本文方法和监督学习方法在SOC 下含有1∶32 标签的MASTAR 数据集上的混淆矩阵。当每个类别仅有原始数据1∶32标签样本时,本文方法与监督学习方法的每类识别准确率的比较如图4所示,详细说明了本文方法相对监督学习方法在每个类别中的准确率的改进情况。
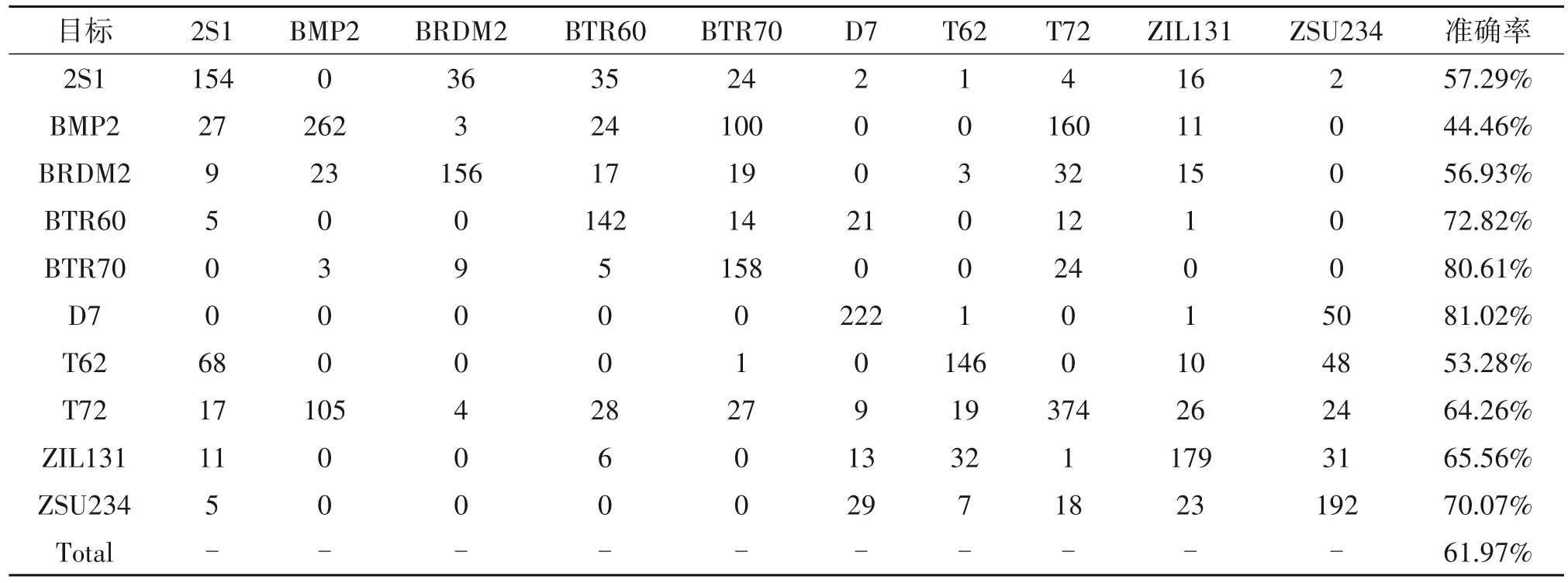
表5 SAF-SGAN在SOC下含有1∶32标签的MASTAR数据集上的混淆矩阵Tab.5 Confusion matrix of SAF-SGAN on the MASTAR dataset with 1∶32 label under SOC
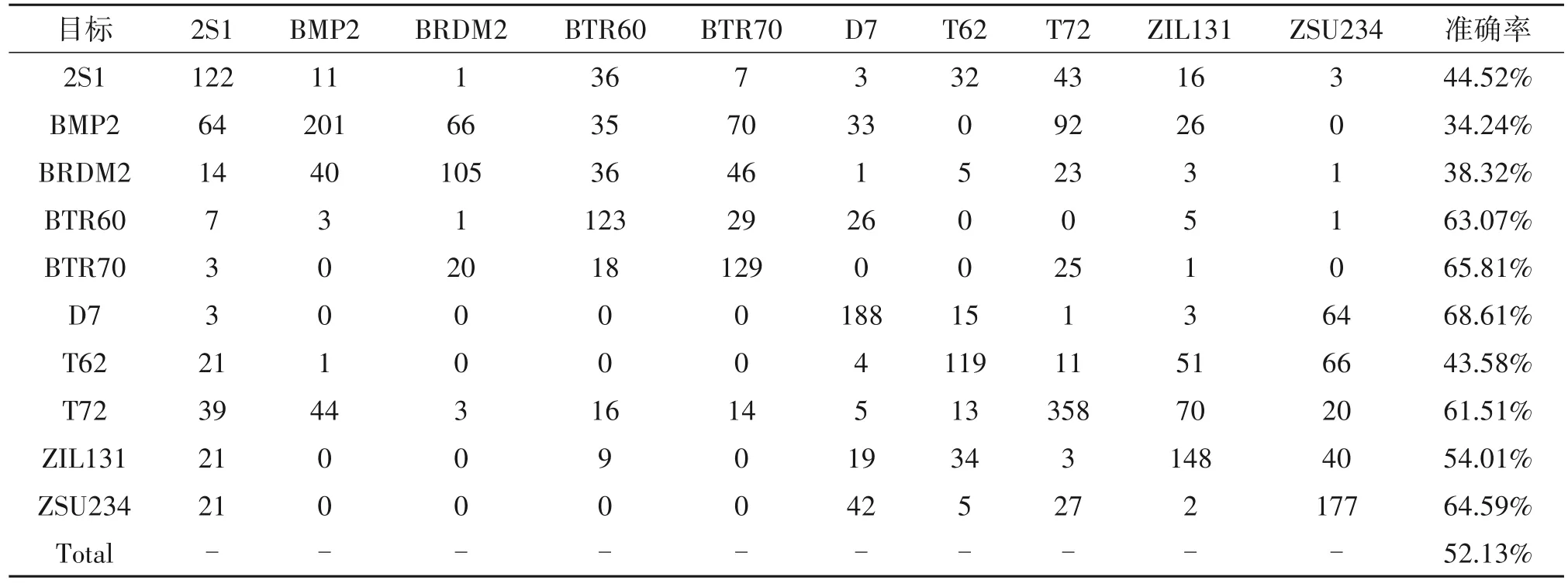
表6 SRA下含有1∶32标签的MASTAR数据集上的混淆矩阵Tab.6 Confusion matrix of SRA on the MASTAR dataset with 1∶32 label under SOC
从图4可以清楚的看到该方法将所有类别的识别准确率提高了两个百分点以上。T72类别的识别准确率提升的精度低于5%,其他类别精度的提升均高于5%。BRDM2 识别精度提高了18%以上。T72的准确率改善不是很大的原因是因为在测试集中T72类型含有132、812和S7三种变体,而训练集中仅有132系列一种,从而说明T72的变体之间存在很大差异难以学习。而BMP2在测试集中也含有三种变体,但利用本文方法识别精度提高了10.22%,这说明本文的模型在识别BMP2 的能力优于识别T72 的能力。综上所述,本文提出的模型在识别变体能力上得到了改善,提升了模型的鲁棒性。
3.4 网络结构分析
为探究最佳的半监督生成对抗网络结构设置以及自注意力模块对网络性能的影响,我们对不同结构和在网络中使用不同数量的自注意力模块在SOC 数据集上进行实验验证,并对生成器生成的图像进行了可视化。
3.4.1 卷积层数和自注意力模块的分析
为探究半监督生成对抗网络的理想状态,本小节对判别器网络的构成进行了定量分析。首先,我们设计含有不同卷积层数的判别器,并在含有不同数量的标签数据下识别MSTAR数据集,实验结果如表7所示。实验结果表明,适当的增加卷积层数可以有效的提高判别器网络的特征提取能力,从而使得整体的分类性能得到提升。由表7可以发现,当网络中的卷积层数为8时,判别器网络的分类性能最佳。

表7 不同卷积层数的性能比较Tab.7 Performance comparison of different convolution layers
为进一步提升半监督生成对抗网络的识别性能,我们分析了自注意力模块在网络中的作用。通过判别器网络中配置不同数量的注意力模块,在含有不同数量的标签数据下识别MSTAR 数据集并对识别结果进行了比较,如表8 所示。自注意力模块通过点积运算需耗费大量计算资源,减少主干网络的优化力度,经实验采用三组自注意力模块可最大限度提升效果。从而表明自注意力模块可以通过建立长距离、多层次依赖关系,有效地对SAR 图像的全局特征进行利用,进而提高半监督生成对抗网络的判别性能。为获取最佳性能的网络,本文所构造的判别网络采用三组自注意力模块。

表8 配置不同数量注意力模块的性能比较Tab.8 Compares the performance of different number of attention modules configured
3.4.2 生成图像可视化
本文在少量标注样本的条件下,利用SAFSGAN 生成未标记图像进行网络训练,从而提高模型的性能。这样不仅可以将已有的标注样本得到充分利用,而且得到的结果比仅仅使用标注样本进行训练的效果要好。图5绘制了实验过程中的生成器损失和判别器损失,从图中曲线的走势可以看出,在训练过程中生成器损失和判别器损失开始时出现较强的波动后逐渐减小。结果表明,在经过一定的训练阶段后本文采用的方法能够稳定收敛。
图6 从左到右展示了一些输入噪声信号和第50、第100、第200、第300、第400 以及第500 次遍历生成的图像。从图中可以看出,随着训练的进行SAR目标的轮廓和纹理可以更加直观地观察。
图7 左边的是SAF-SGAN 生成的图像,右边的图像是MSTAR 数据中真实的SAR 图像。通过图7的对比图中可以发现,生成的SAR 目标图像散斑噪声减少,与原始SAR 目标图像的相似度极高,但也有细微的差异。在生成图像中,人类可以清楚地识别出与真实图像相似的SAR 目标特征,很难判断其真实性,因此可以将其作为真实样本辅助训练。
3.5 与其他实验方法在SOC小样本数据上的性能比较
本小节将所提出的SAF-SGAN的识别结果与一些具有代表性的机器学习方法以及最近发表的几种方法在表9 中进行了比较,包括SVM[4],Adaboost[5],ResNet50[6],MobileNet[8],Shufflenet-v2[7],TAI-SARNet[26],Improved-GAN[17],文献[27]以及带有正则化的半监督GAN[28]。为了证明所提方法在有限数据集上的优越性,仍采用3.3 节的数据划分方式进行训练。针对每个模型重复进行10次实验,最终的识别精度为10 次结果的平均值。由表9 可知,随着训练样本图像数量的增加,所有的识别准确率均有提高。从另一方面还可以观察到,在训练数据有限的情况下,经典的深度学习方法的性能劣于传统机器学习的方法。利用GAN 生成的图像来辅助训练,基于GAN 的方法逐渐表现出优越的性能。与以往基于GAN 的方法相比,SAF-SGAN 的识别准确度大约提高了2%~5%,证明了生成图像对网络训练起到了类似正则化的效果,进而对分类性能起到了很好的辅助作用,弥补了数据不足对网络训练产生的影响。

表9 各方法在SOC有限数据集上的性能比较Tab.9 Performance comparison of the methods on the SOC finite dataset
4 结论
针对SAR 目标识别中的难点问题,本文提出基于自注意力特征融合的半监督生成对抗网络用于SAR 目标识别。本文方法通过引入自注意力模块构建长范围全局依赖关系,丰富了生成图像细节,提高网络学习SAR 图像上下文信息的能力。在生成器损失中引入了特征匹配损失,此外,判别器将多个自注意力模块的输出进行特征融合,提高判别器鉴别能力,对生成器起到更好的约束作用。本文提出的SAR 目标识别算法生成的图像在视觉效果上比原始SAR 图像相比含有较少的散斑噪声。实验结果表明,本文方法在标注数据集有限的条件下,SAF-SGAN 超越了主流SAR 目标识别算法的准确率,证明了本文方法的有效性。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
甘肃教育(2020年22期)2020-04-13
电子制作(2019年11期)2019-07-04
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
北京航空航天大学学报(2018年1期)2018-04-20
第二课堂(课外活动版)(2016年2期)2016-10-21
Coco薇(2015年11期)2015-11-09
