
联邦个性化学习推荐系统研究*
2022-03-04 12:57李康康
现代教育技术 2022年2期
李康康 袁 萌 林 凡
(1.江苏师范大学 江苏省教育信息化工程技术研究中心,江苏徐州 221116;2.江苏师范大学 智慧教育学院,江苏徐州 221116;3.厦门大学 信息学院,福建厦门 361000)
个性化学习推荐既是实现自适应学习的核心引擎,也是“人工智能+教育”的核心研究领域之一。随着人工智能技术的不断发展和教育数据的大量积累,个性化学习推荐在准确性和多样性等方面的性能得到较大提升。但当前个性化学习推荐仍面临诸多问题,如数据隐私保护问题[1]、“冷启动”问题[2]、法律约束问题等。为解决这些问题,本研究引入了“联邦学习”的概念。联邦学习是指各参与方在保证数据隐私安全的基础上,共同训练机器学习模型,以实现模型效果提升的目的[3]。作为近年来优秀的数据隐私保护机器学习技术解决方案,联邦学习通过同态加密、协同训练的方式,可实现数据隐私安全的有效保护和数据价值的共享。基于此,本研究尝试将联邦学习和个性化学习推荐相结合,通过构建联邦个性化学习系统,探讨此系统的应用场景、解决方案和未来挑战,以实现更安全、更高质量的个性化学习推荐服务。
一 问题分析
个性化学习推荐在一定程度上缓解了海量网络学习资源的信息过载问题,但随着现代社会对数据所有权和隐私权的重视程度不断提升,个性化学习推荐面临一些亟待解决的问题,主要如下:
1 数据隐私保护问题
近年来,学习者隐私数据泄露和不法交易现象时有发生。例如,“央视网”曾报道有140 万名考研学生的姓名、手机号、身份证号等敏感信息遭遇泄露[4];美国非营利性教育科技公司inBloom 为实现个性化学习服务,通过与各州教育机构及教育技术公司合作,收集了学习者的家庭情况、经济情况、身体情况等敏感信息,并在学校、学区和在线教育平台中传播[5],这种侵权行为遭到了家长和相关隐私权维护组织的强烈抵制,最终导致该公司走向破产;此外,还有Piazza涉嫌滥用学生数据风波[6]、Edmodo 因广告漏洞使学生信息大量泄露等[7]——这些事件的发生,都揭示了学习者的数据隐私保护尤为迫切。其中,inBloom 公司的案例说明个性化学习推荐服务强烈依赖丰富且优质数据的支撑,而学习者隐私保护成为了其发展的瓶颈。
2 “冷启动”问题
“冷启动”问题是指推荐系统在面对新用户或新物品时,由于缺乏相应的行为数据,导致推荐系统不知给新用户推荐哪些合适的物品,或者无法将新物品推荐给有需求的用户[8]。在教育推荐领域,因学龄具有阶段性、学科专业具有多分类性、知识结构具有复杂多样性等特点,各在线教育平台之间的教育数据都是割裂的,这使得个性化学习推荐系统在面对新用户或新学习资源时缺乏足够的参考信息,导致推荐服务质量不高且推荐多样性不足。特别是当面对跨学龄或跨学科推荐时,个性化学习推荐面临的挑战较大。
3 法律约束问题
为应对人工智能应用可能带来的学习者隐私数据泄露甚至被滥用的问题,各国都积极出台了相应的法律法规。例如,欧盟的《通用数据保护条例》《电子通信领域个人数据处理和隐私保护的指令》、美国的《学生数字隐私和家长权利法》、英国的《数据保护法》以及我国的《中华人民共和国网络安全法》《个人信息保护法》等,都对数据的采集、存储和使用等环节进行了严格的规范[9]。受法律的约束,不同组织、不同机构之间分享数据正变得愈发困难,这将极大地限制个性化学习推荐技术的发展。在进行个性化学习推荐的同时确保学习者隐私数据安全,为学习者提供更加安全、高效、精准的个性化服务,是当前个性化学习推荐面临的重要挑战。
针对上述问题,研究者纷纷展开了相关研究,如刘梦君等[10]提出基于差分隐私保护的学习资源学习热度推荐,以解决数据隐私保护问题;刘宝忠等[11]基于热传导和物质扩散理论,提出基于二部图的学习资源混合推荐,以解决“冷启动”问题;侯浩翔[12]分析了人工智能时代学生数据隐私保护的动因并给出具有实操性的学生隐私保护策略,以解决法律约束问题。但是,目前研究大多侧重于解决某一问题,而很难同时兼顾解决三个问题。对此,本研究设计了三种不同应用场景的联邦个性化学习推荐系统。这三种系统均采用加密协同训练个性化学习推荐模型的方式,帮助各参与方在遵守法律规定的前提下,同时解决数据隐私保护、“冷启动”和法律约束等问题。
二 联邦推荐系统综述
本研究首先对商品推荐场景中的联邦推荐系统进行综述,以了解联邦推荐系统的运作流程和应用现状,为后续针对教育应用场景设计联邦个性化学习推荐系统提供参考。
1 联邦推荐系统的流程与分类
在联邦推荐系统中,多个参与方服务器在不直接访问彼此隐私数据的条件下,协同训练各自的推荐模型,最终达到推荐效果优于本地单独训练模型的目的[13]。联邦推荐系统的运作流程如下[14]:①各参与方服务器从中央服务器下载全局物品特征矩阵;②各参与方服务器在本地进行信息聚合和对齐操作,以剔除不符合规则的信息;③各参与方服务器在本地计算用户特征矩阵与全局物品特征矩阵,以更新本地用户特征和物品特征;④各参与方服务器将更新后的物品特征按照安全协议传输到中央服务器;⑤中央服务器通过联邦平均求解的方式对聚合的全局物品特征进行更新,并传输给各参与方用于新一轮计算。
根据商品推荐应用场景的不同,可将联邦推荐系统划分为:横向联邦推荐系统、纵向联邦推荐系统、联邦迁移推荐系统和联邦强化推荐系统[15]。其中,横向联邦推荐系统主要用于物品相同但用户不同的场景,以在保护用户数据隐私的同时,实现用户行为数据信息的深度共享;纵向联邦推荐系统主要用于用户相同但物品不同的场景,可提升推荐的多样性;联邦迁移推荐系统主要用于物品相同且用户重叠数量较少的场景,以解决数据样本较少或模型难以训练的问题;而联邦强化推荐系统主要用于捕捉个体用户即时反馈信息的场景,以提升推荐的及时性。
2 联邦推荐系统的应用现状
目前,联邦推荐系统的应用尚处于探索阶段,但已经引起了广泛的关注。例如,字节跳动结合联邦学习和个性化推荐算法,帮助教育客户广告跑量显著提升124.73%,正价课续报人数大幅提升211.54%,续报率提升32.69%,正价课续费用户获客成本降低11.73%[16];微众银行也已经发布多种联邦推荐系统模型,如联邦协同过滤推荐模型、联邦因子分解机模型、联邦矩阵分解模型等[17],以加速联邦推荐系统的落地应用和相关算法的研发。
此外,科研人员在联邦推荐系统研究方面也取得了一些突破性的进展。例如,Wu 等[18]提出联邦学习与知识点追踪相结合的联邦知识点追踪算法,实验结果证实该算法能提高知识点追踪的预测效能,预测的知识掌握情况可用于个性化知识点推荐;Kulkarni 等[19]提出了一种具有泛化性能的联邦元学习框架,其通过参数化算法训练推荐模型,针对特定的个体用户,可以在较小规模内减少资源消耗,实验结果显示该框架具有较高的精准度,且对于解决“冷启动”问题有较好的适应性;杨强等[20]将传统的推荐算法(如矩阵分解、因子分解机、奇异值分解等)改造为联邦推荐算法,为联邦推荐算法的普及和应用提供了便捷的云服务。
三 应用场景
如前文所述,个性化学习推荐的发展受限于数据隐私保护、“冷启动”和法律约束问题,使推荐系统难以获得学习者学习数据的全貌,不利于提升个性化学习推荐服务的质量。因此,可以尝试设计联邦个性化学习推荐系统,以满足高质量学习推荐服务的需求。但在设计该系统之前,首先需要明晰系统适用的场景。在商业领域的四类联邦推荐系统中,联邦迁移推荐系统大多被应用于不同企业之间的推荐模型协同训练,主要解决跨领域商品推荐问题。而结合教育场景的特殊性,本研究认为联邦迁移推荐系统不适用于个性化学习推荐,故将联邦个性化学习推荐系统的应用场景分为横向联邦、纵向联邦、联邦强化三种。
1 横向联邦个性化学习推荐的应用场景
在个性化学习推荐应用的过程中存在以下场景:具有相同学科教学背景的不同在线教育平台(或不同学校、不同教育部门)各自收集了不同学习者的学习数据,为了更好地满足学习者的自适应学习需求,需要建立精准的个性化学习推荐模型——但是,这些平台各自拥有的优质数据量过少,距离建立精准的个性化学习推荐模型的目标相差甚远;若不同平台之间私自共享数据,又容易触犯数据安全和隐私保护条例。针对上述场景,不同平台可以联合建立横向联邦个性化学习推荐模型,通过在不同平台协同训练推荐模型,来提升模型的预测能力和推荐能力。当面对新学习用户或新学习资源时,横向联邦个性化学习推荐模型可以搜索不同平台相似用户的学习偏好或使用相似资源的用户特征,从而有效解决传统推荐算法的“冷启动”问题。此外,不同平台之间的学习资源也存在一定的差异性,可以利用不同平台之间协同训练的横向联邦个性化学习推荐模型,探索用户新的知识薄弱点或学习兴趣,将不同平台的相关学习资源推荐给用户,这样既可提高不同平台资源的利用率,又可促进不同平台的资源共享。
2 纵向联邦个性化学习推荐的应用场景
在个性化学习推荐应用的过程中存在以下场景:具有不同学龄段背景的不同在线教育平台各自收集了不同学习者的学习数据,其中有部分学习者的学习数据是重叠的,为了更好地适应跨学龄学习者的个性化学习需求,需要建立跨学龄的个性化学习推荐模型——但是,各平台只拥有一个学龄段的数据,尚不足以支撑建立跨学龄的个性化学习推荐模型;而出于行业竞争、数据安全及隐私保护等方面的考虑,平台之间也难以形成有效的数据共享机制。针对上述场景,不同平台可以联合建立纵向联邦个性化学习推荐模型,以提高跨学龄推荐能力。例如,在不同学龄阶段的数学教学中,纵向联邦个性化学习推荐模型可以根据不同学龄阶段的数学知识图谱,追踪学习者的薄弱知识点,为学习者提供层层递进的个性化学习路径[21]。
3 联邦强化个性化学习推荐的应用场景
在个性化学习推荐应用的过程中存在以下场景:拥有海量学习者的不同在线教育平台将学习者的行为数据保留在学习者的智能终端,不再将数据上传到平台服务器,以实现更安全的隐私保护。但是在这样的隐私保护安全级别,各智能终端之间如何并行训练个性化学习推荐模型成为难题。要解决上述难题,不同平台可以在海量智能终端之间联合建立联邦强化个性化学习推荐模型。之后,联邦强化个性化学习推荐模型将各终端计算所得中间信息加密传输到平台服务器,平台服务器再将更新后的推荐模型参数通过加密方式传输到各终端,以保障各终端智能推荐模型的及时更新,如此既可达到将数据安全地保存到用户终端的目的,还可减轻平台服务器的计算压力。
四 解决方案
1 横向联邦个性化学习推荐应用解决方案
针对横向联邦个性化学习推荐的应用场景,本研究以两个参与方服务器协同训练个性化习题推荐模型为例,设计了横向联邦个性化学习推荐应用解决方案,如图1 所示。参与方F1、F2服务器协作训练横向联邦个性化学习推荐模型的步骤具体如下:①中央服务器对全局习题信息和知识基本信息进行特征表示,并将得到的全局习题特征信息和知识特征信息传送到两个参与方服务器。②两个参与方服务器在本地建构个性化学习推荐模型,得到的F1、F2 本地模型均采用循环神经网络方式对学习者的历史答题记录行为进行建模。③两个参与方服务器将各自计算所得的梯度信息采用同态加密的方式传输给中央服务器,并在中央服务器完成梯度聚合。④中央服务器将梯度聚合结果更新,并加密传输给两个参与方。两个参与方服务器接收加密梯度文件后进行解密运算,以更新各自的本地模型参数。之后,重复步骤①~④,直至模型收敛或迭代次数达到上限。⑤两个参与方服务器根据本地模型对学习者的答题正确概率进行预测,并依据知识点之间的关系网络进行习题推荐。
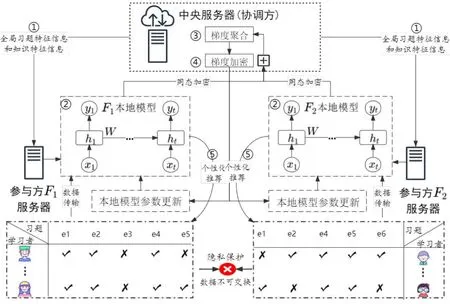
图1 横向联邦个性化学习推荐应用解决方案
2 纵向联邦个性化学习推荐应用解决方案
针对纵向联邦个性化学习推荐的应用场景,本研究设计了相应的应用解决方案,如图2 所示。各参与方服务器协同训练纵向联邦个性化学习推荐模型的步骤具体如下:①各参与方服务器对实体信息进行加密实体对齐。加密实体对齐是指各参与方服务器在互相不知道学习者信息的前提下,找到重叠的学习者实体。②中央服务器创建加密密钥对,并将公共密钥对传送给各参与方服务器,使各参与方的服务器能够单独解密信息。③各参与方服务器交换加密梯度信息,并用于各自推荐模型的训练。④各参与方服务器交换加密中间计算信息,完成本地推荐模型的训练;之后各自将加密梯度和加密损失传输给中央服务器,在中央服务器完成梯度聚合。⑤中央服务器将聚合梯度加密传输给各参与方,各参与方对梯度进行解密完成各自模型参数的更新。之后,重复步骤③~⑤直至模型收敛或迭代的次数达到上限。⑥不同参与方服务器根据各自的需求,通过本地模型推断出习题回答正确的概率,结合知识点之间的关系网络,向学习者推荐符合其自身认知的习题。在纵向联邦个性化学习推荐应用解决方案中,本地模型首先将学习者特征向量和习题特征向量输入长短期记忆模型,以提取学习者的知识点掌握向量;随后,通过知识点掌握向量与知识点难度向量、习题难度因子进行全连接层计算,获得学习者的知识点掌握概率和习题作答正确概率;最后,通过知识点和习题的关联网络,对学习者进行个性化学习推荐。
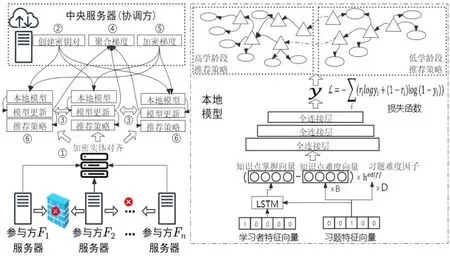
图2 纵向联邦个性化学习推荐应用解决方案
3 联邦强化个性化学习推荐应用解决方案
针对联邦强化个性化学习推荐的应用场景,本研究设计了相应的应用解决方案,具体如图3所示。各参与方的智能终端协同训练联邦强化个性化学习推荐模型的步骤如下:①中央服务器将全局知识信息下发到各参与方的智能终端。②各参与方智能终端在本地单独训练本地模型,以确保数据能够被存储在各自终端。③各参与方智能终端将加密以后的计算信息发送给中央服务器,进行梯度聚合,以从全局信息中习得更多的参考信息。④中央服务器中聚合后的梯度信息被加密传输到各参与方的智能终端,以更新各智能终端的本地模型参数。⑤更新后的模型预测学习者的学习薄弱知识点和习题掌握概率,结合全局知识关系网络和习题关系网络,按照一定的认知层次关系进行排序推荐。在联邦强化个性化学习推荐应用解决方案中,本地模型主要采用联邦强化学习框架,对学习者的答题行为进行建模:首先,将学习者的特征向量和习题特征向量输入答题行为计算模块中,以生成学习者的答题交互行作为特征向量;随后,将该特征输入演员—评价者(Actor-Critic)模块中,计算在目标(Target)条件下,采取不同的选择策略所获得的学习回报奖励(Reward);最后,根据联邦强化学习目标函数计算损失来更新本地模型参数。
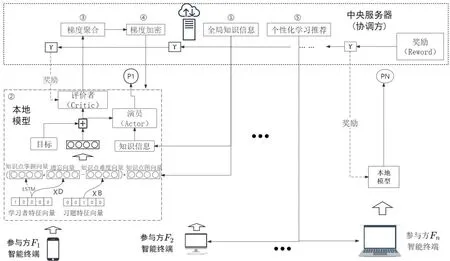
图3 联邦强化个性化学习推荐应用解决方案
五 未来挑战
联邦个性化学习推荐系统不仅可以确保学习者的数据隐私安全,达到法律要求的隐私保护标准,还可以互相参考信息以解决“冷启动”问题。但面向未来,联邦个性化学习推荐系统在其理论研究和实践应用方面还面临以下严峻挑战:
1 基础模型比较缺乏
当前,大多数联邦推荐算法用于在线购物、音乐推荐或短视频推荐等场景,而针对教育场景的联邦个性化学习推荐算法模型比较缺乏。教育场景不同于以上生活应用场景,教育直接面向人才的培养,故后续研究需要结合学习者特有的认知特点,研发与联邦个性化学习推荐有关的基础模型。
2 教育场景较为复杂
教育场景属于知识密集型应用场景,知识结构呈异质网络关系,学习行为数据具有强时序性特征、强关联性等特征,这些都加剧了联邦个性化学习推荐研究的难度。此外,在线教育平台拥有数据的数量级不同、推荐需求不同,这也使得各参与方之间难以形成有效的合作关系。对此,后续研究需结合教育数据特征,研发特定的联邦个性化学习推荐模型,以促进不同参与方之间开展合作。
3 参与机制不够完善
在联邦个性化学习推荐系统中,大型教育平台因海量优质的教育资源,而在协同训练模型中拥有较大话语权。激励大型平台参与联邦个性化学习推荐颇有难度,需设计合理的利益分配机制来保障不同平台的利益,才能使联邦个性化学习推荐系统发挥更大的价值。另外,还需设计诚实参与机制,防止参与方为了利益最大化而做出技术欺骗行为,并在合作前期就筛选掉不诚信的参与方,充分保障用户的隐私数据安全。综上,在线教育平台参与方的激励机制和诚实参与机制有待完善。
4 安全性能有待加强
联邦个性化学习推荐系统采用同态加密、差分隐私、安全多方计算等相关技术,来实现对隐私数据的安全保护。但前沿的后门攻击技术会威胁联邦个性化学习推荐系统的安全,如通过反演攻击和特征推理攻击等方式可以推算出被加密的信息。因此,后续研究还需要加强安全对抗攻击研究,制定攻击防御标准、建立参与方筛选机制,以保障联邦个性化学习推荐系统的安全性。
六 结语
本研究针对三种不同的教育应用场景,提出了横向联邦、纵向联邦、联邦强化等三种联邦个性化学习推荐应用解决方案,并分析了未来联邦个性化学习推荐系统面临的严峻挑战,为后续联邦个性化学习推荐研究厘清了思路。未来研究将在实践中对三种解决方案深入开展模拟实验,并根据这三种解决方案的实际性能表现,不断优化联邦个性化学习推荐系统,以实现为学习者提供更安全、更高质量的个性化学习推荐服务。
猜你喜欢
计算机研究与发展(2022年10期)2022-10-14
家庭影院技术(2020年10期)2020-12-14
铁道通信信号(2019年9期)2019-11-25
网络安全和信息化(2019年8期)2019-08-28
家庭影院技术(2019年7期)2019-08-27
知识产权(2016年8期)2016-12-01
中国房地产·学术版(2016年7期)2016-10-21
网络空间安全(2016年3期)2016-06-15
专利代理(2016年1期)2016-05-17
项目管理技术(2016年10期)2016-05-17
