
基于深度学习的Power Shell恶意代码家族分类研究
2022-03-04 06:46高宇航彭国军杨秀璋宋文纳吕杨琦
武汉大学学报(理学版) 2022年1期
高宇航,彭国军,杨秀璋,宋文纳,吕杨琦
空天信息安全与可信计算教育部重点实验室,武汉大学国家网络安全学院,湖北 武汉 430072
0 引言
网络空间正在成为现代战争中的第五战场,作为国家之间博弈重要方式的高级持续性威胁(ad⁃vanced persistent threat,APT)攻击出现得越发频繁。360互联网安全中心在2021年发布的APT研究报告[1]中指出:2020年全球APT攻击活动异常活跃,全年公开报告数量687篇,其中被披露的组织为132个,越来越多的未知APT组织开始涌现。APT组织从开发成本角度考虑,往往会采取代码复用技术,即同一团队的攻击者在已有的恶意代码基础上进行修改生成新的恶意代码而不是重新开发。这就导致相同家族的恶意代码往往存在许多相似性和共同点,比如代码执行流程、代码风格或者相同的代码片段。对恶意代码进行家族分类,将有助于研究人员发现同类型的变异代码,进而对未知恶意代码进行有针对性地防御。
PowerShell是Windows平台特有的可执行脚本语言,在Windows7及以后的版本中默认安装。由于PowerShell[2]简单易用且与Windows平台交互方便,被广泛应用于Windows平台的自动化运维,但同样因为它的便捷性,使其成为APT攻击链中不可缺少的角色,PowerShell恶意代码的身影频繁出现。据安全公司McAfee在2020年7月发布的网络安全威胁报告[3]数据显示:与上一季度相比,2020年第一季度新型PowerShell恶意软件数量增长了689%。利用PowerShell可以轻易完成:下载攻击载荷至内存运行、修改注册表、操作文件、执行定时任务以及与命令和控制(command and control)服务器通信等常见的恶意行为,并且运行环境的差异性不会对其产生影响。
传统的可执行文件(portable execute,PE)恶意代码检测技术采用的指纹库、特征库、黑名单等方式难以实现高准确率、高召回率和低误报率的效果。因此出现了大量利用机器学习与深度学习对PE恶意代码进行检测与家族分类的方法。但是,在PowerShell检测领域,大部分已有工作和主流的杀毒软件都只对PowerShell代码进行恶意性判定,缺乏对PowerShell恶意代码的家族分类。近年来爆炸式增长的恶意PowerShell代码同样具备传统PE恶意软件的代码复用问题,并且携带PowerShell恶意代码的APT攻击已对全球众多的国家和企业造成巨大影响,对PowerShell恶意代码进行家族分类具有重要意义。
1 相关研究
目前,在PowerShell恶意代码家族分类领域的相关研究较少,而结合机器学习与深度学习的PowerShell恶意代码判定方法以及针对PE恶意代码的家族分类方法对PowerShell恶意代码家族分类具有一定的参考性。
在PowerShell恶意代码判定方面,目前较多的工作都结合了自然语言处理与深度学习。2018年,Hendler等[4]提出了一种基于深度神经网络的PowerShell恶意代码检测方法,通过动态分析提取PowerShell命令后,利用n-gram分词工具进行特征提取,使用4层卷积神经网络(convolutional neural network,CNN)实现恶意性判定。2020年,Hendler等[5]又提出了一种基于上下文词嵌入的PowerShell恶 意 代 码 检 测 方 法,利 用Word2Vec[6]、FastText[7]等词嵌入工具获取代码上下文词嵌入信息作为恶意特征,输入卷积神经网络、循环神经网络等模型实现恶意代码判定。Tajiri等[8]提出了利用Doc2Vec[9]提取上下文词嵌入信息,并利用卷积神经网络进行分类的方法,其中Doc2Vec无需将完整的代码进行分割,能够保留更加完整的上下文信息。
在恶意代码家族分类方面,大部分都是针对PE文件的恶意代码进行分类的工作。基于灰度图像的家族分类方法是目前国内外研究PE恶意代码家族同源判定的主要方法,Nataraj等[10]于2011年发现将恶意代码的二进制文件(PE文件)按字节读取为8位无符号整数向量后,恰好满足256级灰度,因此可将PE恶意文件转化为灰度图表示并进行恶意代码家族同源分析。此后,越来越多的深度学习方法被使用。Kim[11]于2017年提出在灰度图的基础上将卷积神经网络算法应用于恶意数据集的分类。陈小寒等[12]提出一种基于卷积神经网络的PE恶意代码家族分类模型,将PE恶意代码转化为灰度图像后,结合CNN自主学习灰度图像相关特征实现家族分类。尽管基于CNN的静态检测方法解决了动态检测的资源耗费以及耗时问题,但是CNN忽略了特征序列的先后顺序,无法解决长距离依赖以及梯度爆炸等问题。因此,王国栋等[13]提出了一种基于CNN-BiLSTM(convolutional neural networkbidirectional long short-term memory)网络的静态恶意代码检测方法,旨在解决长距离依赖以及上下文特征捕获的问题。该方法通过将PE恶意代码转换为灰度图像,然后通过CNN-BiLSTM网络模型对恶意代码进行家族分类。但是相对于同样作为循环神经网络(recurrent neural network,RNN)的变体门 控 循 环 网 络(gate recurrent unit,GRU)来 说,BiLSTM模型参数过多,收敛速度慢。此外,结合灰度图的检测方法局限于PE等格式较为固定的恶意代码,PowerShell恶意代码格式灵活,转化为灰度图像后并不存在明显的区段划分。在PowerShell恶意代码家族分类方面,Rusak等[14]使用机器学习对PowerShell恶意代码进行家族分类,该方法通过抽取样本抽象语法树(abstract syntax tree,AST)的高度与节点数量作为家族分类的特征,在4 079个Power⁃Shell恶意代码数据集上获得85%的分类精确度。
为了解决已有恶意代码分类工作主要集中于PE文件分析,针对PowerShell恶意代码家族分类存在精度较低、耗时较长,缺乏对PowerShell恶意代码功能层面的深入挖掘等问题,本文从PowerShell代码的功能角度出发,提出一种基于注意力机制、代码语义特征和双向门控循环网络(bidirectional gated recurrent unit,BiGRU)的PowerShell恶意代码家族分类方法AA-PSFC(abstract syntax tree and attention based BiGRU for PowerShell malware family classification)。该方法通过捕捉抽象语法树的上下文语义及局部特征,忽略无关信息,实现对PowerShell恶意代码家族的高效分类。
2 模型设计
AA-PSFC整体框架如图1所示,AA-PSFC由预处理、词嵌入、BiGRU网络、注意力机制、分类器组成。AA-PSFC model工作流程如算法1所示。

图1 AA-PSFC模型Fig.1 AA-PSFC model

?
AA-PSFC的执行步骤如下:首先,将各家族的PowerShell恶意代码与对应标签输入模型,通过预处理提取各样本的抽象语法树序列,同时利用Word2Vec进行词向量训练,随后将词向量与样本输入词嵌入层,获得每个样本的向量表示;其次,将样本的向量组合与标签作为feedDict同时输入前向GRU网络与后向GRU网络获取上下文特征,并将它们的输出进行拼接以获得BiGRU网络层的完整输出h,再融合注意力机制捕获样本各节点的局部特征,赋予BiGRU网络输出h对应的权重后传入全连接层;最后,利用Softmax分类器计算当前样本对应的家族标签,从而实现PowerShell恶意代码的家族分类任务。
2.1 数据预处理
2.1.1 生成抽象语法树
PowerShell的抽象语法树作为代码的语义表达,以多叉树的形式表示脚本功能的逻辑结构,保留了代码上下文的特征并剔除无关的参数干扰,是分析功能类似的PowerShell代码的有效方法。Windows为PowerShell提供了访问脚本AST的接口[15],使用内置接口获取的AST结构如图2所示。
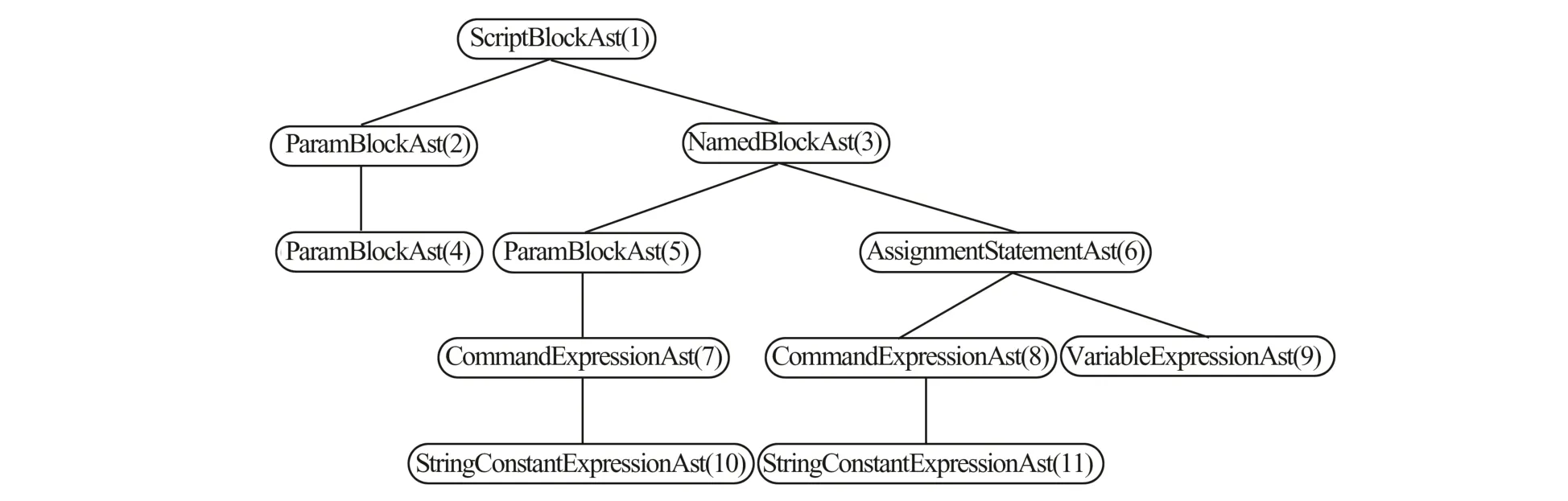
图2 AST的结构Fig.2 The structure of AST
本文采用后序遍历的方式序列化AST,以便进行下一步的词向量训练。
图2序列化的结果如下所示:

由于复用的代码结构类似,会根据攻击目标设置不同的参数,例如硬编码路径、加密密钥、定时任务时间、远程服务器地址等参数,通过该方式能有效去除相似代码的参数差异,仅保留代码的结构特征,从而提升家族分类的效果。
2.1.2 词向量训练
深度学习无法直接对AST节点序列进行训练,本文采用Google于2013年提出的一款词向量工具Word2Vec进行特征映射。Word2Vec作为一种神经网络模型,通过将输入的语料转化为K维空间向量,再利用向量来计算文本之间的相似性。该模型具备两种训练模式,分别是连续词袋(continuous bag of words,CBOW)模型和Skip-gram模型。CBOW模型根据中心词“w(t)”周围的词生成中心词的词向量,而Skip-gram模型则是根据中心词“w(t)”的词向量预测邻近词的词向量。虽然前者的效率更高,但是当其遇到低频词的时候,准确率大大下降。Skip-gram模型弥补了上述缺点,在本文处理的AST节点序列中,提取的节点类型出现频率从几十次到几千次不等。图3显示了本文用于训练的数据中低频语法树节点类型的出现情况。从图3中可知,不同家族类型的低频节点交错出现,各家族类型的低频节点主要集中在10~30频次区域。为了能够更好地处理低频的语法节点,本文采用Skip-gram模型作为Word2Vec的训练模型。

图3 低频语法树节点的出现频率Fig.3 Frequency of occurrence of low-frequency syntax tree nodes
2.2 BiGRU模型
RNN能够挖掘数据中的时序信息与语义信息,但是传统的RNN在计算当前输出时,依赖于过去每一个时刻的隐藏状态,所以当其处理超长序列时,简单的RNN几乎丧失了学习长期依赖关系的能力,同时衍生出梯度消失与梯度爆炸的问题。为了解决上述问题,Chung等[16]提出了RNN的变体循环单元门GRU,旨在解决传统RNN的梯度消失问题与长期依赖问题,本文使用的GRU基本单元[17]如图4(a)所示。
GRU通过引入重置门rt(reset gate)和更新门zt(update gate)改进了传统RNN计算前向隐藏状态的方式,它们的输入均为当前时间步t的输入xt与前一时间步t-1的隐藏层状态ht-1。rt与zt的输出计算方法如下

其中,α为激活函数sigmoid,wxr、whr、wxz、whz为对应激活函数的权重矩阵,br与bz为偏差值。通过(1)式获得重置的输出后,GRU通过(3)式中的激活函数tanh计算当前准隐藏层状态
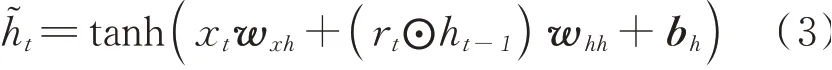
其中,wxh与whh为激活函数对应的权重矩阵,bh为偏差参数。最后结合更新门输出zt通过(4)式计算当前隐藏层状态,其中⦿为Hadamard乘积运算符。

通过(1)~(4)式,GRU单元能够在每个时间步保存上文的信息,但是它忽略了下文的信息。所以本文采用BiGRU同时保存每个节点的上下文信息。BiGRU由前向层(forward layer)与后向层(back⁃ward layer)两组GRU单元组成,如图4(b)所示。其中,前向隐藏层与后向隐藏层第i个单词在时间步t的状态分别通过下式计算

图4 GRU单元与BiGRU模型Fig.4 GRU unit and BiGRU model
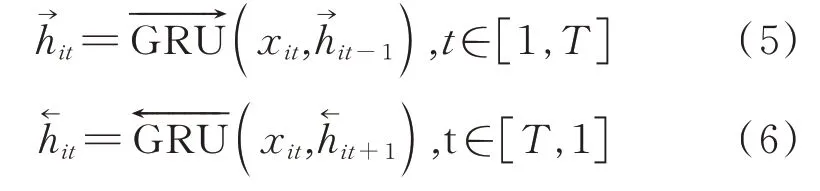
最后通过(7)式整合加权状态

2.3 注意力机制
注意力(Attention)机制[18]是模仿人类注意力提出的一种用于从大量信息中快速提取高价值信息的方法,通过对输入的每个元素计算不同的权重,将局部重点信息放大,并且忽略干扰信息。AST序列的节点中,并不是每一个节点都对当前脚本的家族类型产生相同的影响,例如每个脚本都存在用来标识脚本开始与结束位置的节点“Script⁃Block Ast”,所以本文使用注意力机制来提取对脚本家族类型产生较大影响的节点,并赋予它们更高的权重,突出它们的重要性。本文模型使用的注意力机制通过以下步骤完成计算。
首先使用tanh函数对当前单词的hit与权重矩阵ww的乘积结果进行非线程变换,得到hit对应的隐藏层表示uit,如(8)式所示

然后利用softmax函数计算当前序列每个节点的权重

其中,uw为当前序列的上下文词向量,代表整个序列的语义。依(10)式可获得第i个样本的向量表示

将yi输入全连接层后获得每个家族类型的概率,并利用softmax分类器获得最终的分类结果。
3 实验设计与评估
3.1 数据来源
本文采用的数据集由3部分组成:①White[19]在Github上的开源数据集,该数据集中的样本已被分类为不同的家族;②利用HyBrid开放API下载的恶意PowerShell脚本;③从AnyRun下载与PowerShell相关的恶意脚本。对于从Hy Brid与AnyRun中收集的样本,它们的标签采用与Jeff White样本集相同的分类规则标注。基于不同家族的样本数量考虑,经过数据清洗及人工标注,样本总计4 658个,分为6个家族类型,包括AMSIBypass、BITS Jobs、Down⁃loader、RemoveAV、Scheduled Task、Shellcode Inject,各家族的数量分布如图5所示。由图5可知,Shellcode Inject与Downloader家族的样本数量较多,分别为1 932和1 430个;Scheduled Task家族的数 量 居 中,为756个;AMSI Bypass、BITS Jobs、RemoveAV 3个家族的样本数量较少,分别为135、189、216个。由于各家族样本数量分布不均,所以后文在计算模型的性能指标时需要根据各个家族的数量占比赋予不同的权重。

图5 恶意PowerShell脚本的家族分布情况Fig.5 Family distribution of malicious PowerShell scripts
3.2 实验设置
实验环境的CPU为Intel(R)Xeon CPU@E5-2678v3@2.50 GHz,GPU为NVDIA Tesla K80,内存8 GB。编程语言为Python3.7,采用Py Torch、Sklearn等工具对本文提出的方法进行实现与测试。
3.3 评估指标
为评估本文分类方法的效果,采用分类算法中4个常用的指标评判模型的有效性。对于一个标签,分别定义:
a)真阳性(true positive,TP),真实标签为A,预测标签为A;
b)假阳性(false positive,FP),真实标签为其他,预测标签为A;
c)真阴性(true negative,TN),真实标签为其他,预测标签为其他;
d)假阴性(false negative,FN),真实标签为A,预测标签为其他。
标签i的准确率、精确率、召回率、F1值4个指标的定义如下:
a)准确率(accuracy,ACC):分类结果中,被正确分类的样本数占总样本数的百分比,用于评估检测模型整体性能的评价指标,计算式如下
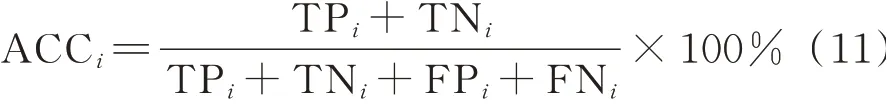
b)精确率(precision,PRE):分类结果中,被正确分类为恶意样本的恶意样本数量占被分类为恶意样本总数的占比,计算式如下

c)召回率(Recall):分类结果中,属于A标签的样本中,被正确分类的样本占比,计算式如下

d)F1值(F1-score):精确率和召回率的调和平均数,计算式如下

由于本文研究的是多分类任务,且样本类别数量分布不均衡,因此对于上述的准确率、精确率、召回率、F1值采用(15)~(18)式进行加权计算。

其中,权重wi为标签i的样本数量在总体样本数量中的占比。
3.4 结果与分析
3.4.1 分类效果评估
为验证本文方法的有效性,本文选取了CNN[12]、CNN-BiLSTM[13],以及RNN、LSTM、FastText等常见的深度神经网络学习模型与本文提出的AA-PSFC模型在同一数据集上进行家族分类效果对比。图6显示了各个模型在同一环境下测试得到的指标。AA-PSFC模型的准确率、精确率、召回率、F1值 分 别 为96.47%、96.25%、96.74%、96.11%,均高于其他模型。

图6 不同深度学习模型的效果对比Fig.6 Comparison of the effects of different deep learning models
为进一步验证双向网络机制与注意力机制对模型性能提升的作用,将AA-PSFC与单向GRU、BiGRU在同一环境下进行对比实验,结果如表1所示。由表1可知,BiGRU的各项指标相对于单向GRU,至少提高了0.76%,因为前者在捕获上文语义的基础上,同时捕获了下文语义,能够更好地提取出一个语法节点的特征。而同时融合了双向网络机制与注意力机制的AA-PSFC模型各项指标均达到最优,相对于BiGRU模型,准确率、精确率、召回率、F1值分别提高了1.18%、1.24%、1.45%、1.28%。因为注意力机制能够对部分有效节点赋予更大权重,因此提升了有效节点对分类结果的影响。
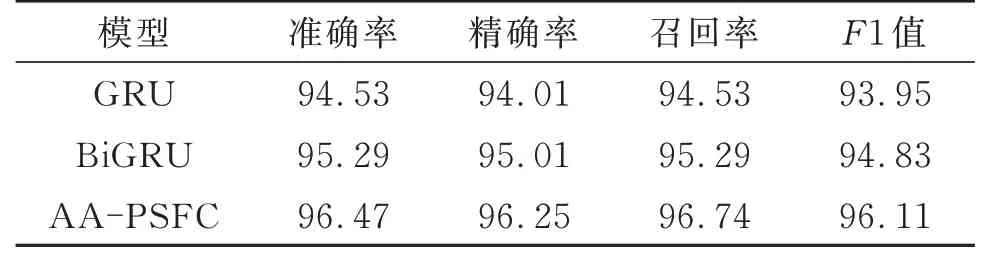
表1 双向机制与注意力机制效果对比Table1 Comparison of the effects of the two-way mechanism and the Attention mechanism%
由于F1值能够较好地体现模型的综合性能,本文给出了3种模型的F1值变化趋势。如图7所示,在0~100轮的训练过程中,AA-PSFC的F1值提升迅速,达到91.2%,相对于BiGRU与GRU,分别提高3.05%、7.45%。在300轮后,AA-PSFC逐渐趋于稳定,达到95%及以上,收敛快于GRU与BiGRU。结果表明BiGRU能够更好地处理具备时序性的语法节点序列,有效捕获前后时序特征以及长距离依赖,后序的注意力机制能够进一步提升分类效果。

图7 3种模型F1值对比Fig.7 Comparison of F1 values of three models
为进一步衡量本文模型的分类效果,选取检测效果与本文模型较接近的文献[12]中的CNN、文献[13]中的CNN-BiLSTM以及RNN作为对照,评估它们对各个家族的分类结果,计算的混淆矩阵如图8所示。由图8可知,在所有家族的分类结果中,AA-PSFC模型准确分类的样本数量均为最多。为了更直观地辨别模型分类结果,基于混淆矩阵计算出的分类误报率如表2所示。由表2知,虽然CNN总体分类效果很接近于本文提出的AA-PSFC,但在面对AMSIBypass、BITS Jobs、RemoveAV等数量较少的家族时,AA-PSFC误报率比CNN至少下降20%。
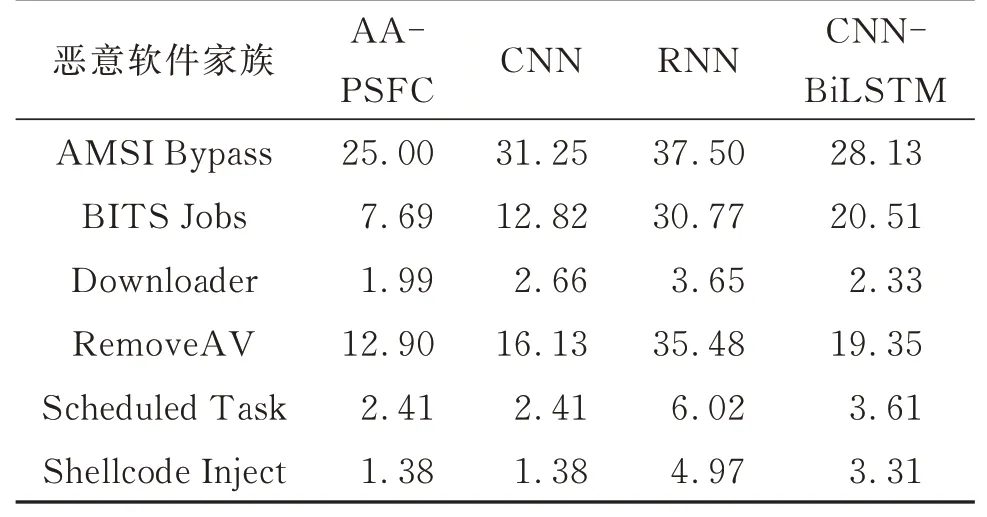
表2 家族分类误报率Table 2 False alarm rate of family classification%
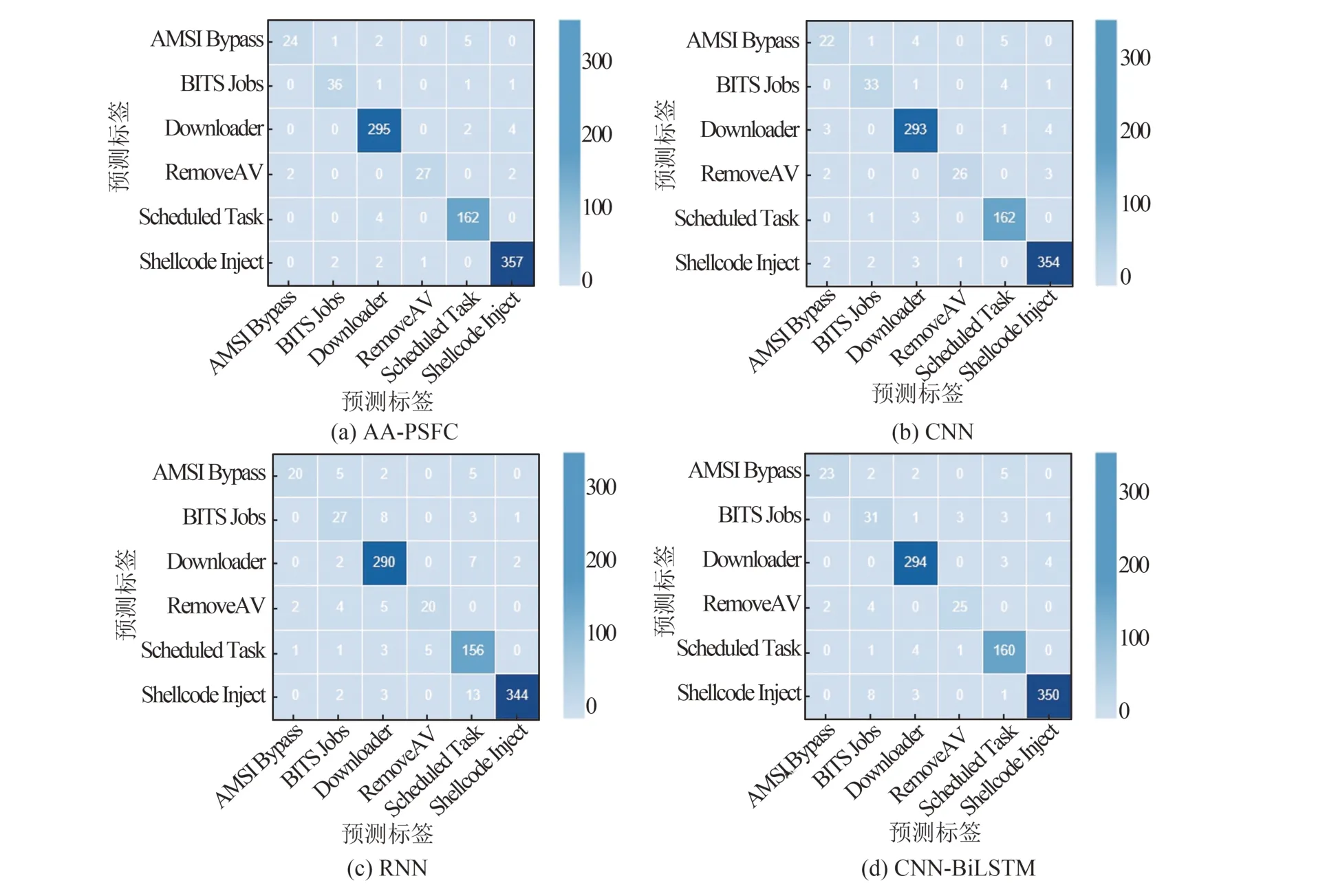
图8 不同模型混淆矩阵对比Fig.8 Confusion matrix comparison of different models
3.4.2 模型时间性能分析
本文将AA-PSFC与文献[12]的CNN、文献[13]的CNN-BiLSTM、RNN及LSTM前500轮每一轮的训练时间对比,进行了详细的时间性能分析。如图9所示,CNN的每轮训练时间最长,平均每轮训练时间约为30.0 s;AA-PSFC的每轮训练时间最短,平均约为5.0 s;LSTM、RNN、CNNBiLSTM等的每轮训练时间约为11.0、6.0、5.6 s。虽然CNN的检测性能与本文提出的AA-PSFC较为接近,但是平均每轮训练时间大于AA-PSFC;CNN-BiLSTM的每轮训练时间虽然与AA-PSFC较为接近,但准确率、精确率、F1值均较低。

图9 各模型的训练时间Fig.9 Training time of each model
上述实验表明,AA-PSFC相对于已有模型,在提高检测性能的同时,有着较短的训练时间。
4 结语
本文提出一种融合代码抽象语法树和深度神经网络的PowerShell恶意代码家族分类方法AAPSFC。该方法通过BiGRU网络提取语法树每个节点的上下文特征,融合注意力机制放大局部重点特征,实现了PowerShell恶意代码的家族分类,准确率、召回率较高,时间损耗较低。但本文工作也存在一定的局限性,如模型的分类对象局限于简单功能的PowerShell命令,基于抽象语法树的线性序列形式过于单一等。随着APT攻击的发展,基于PowerShell的攻击样本势必会更加复杂,未来将考虑添加抽象语法树本身的树特征进行恶意家族分类。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
新高考·高一数学(2022年3期)2022-04-28
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年4期)2021-11-24
软件(2017年6期)2017-09-23
新高考·高二数学(2016年7期)2017-01-23
股市动态分析(2016年17期)2016-10-20
股市动态分析(2016年17期)2016-10-20
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
