
一种用于异常检测的自动日志分析方法
2022-03-03 13:46葛志辉李陶深
小型微型计算机系统 2022年3期
葛志辉,谭 悦,李陶深,叶 进
(广西大学 计算机与电子信息学院,南宁 530004)
1 引 言
随着现代大型系统的应用,各种支持全天侯在线服务的场景越来越多.然而,现代大型系统在为人们提供更好服务质量的同时,其对于系统的安全性需求变得愈加严苛.由于现代大型系统是全天候在线运行的,所有发生在这些系统中的任何异常事件,如由攻击引起的计算机或网络服务中断的行为,都有可能使系统崩溃和造成巨大的经济损失[1].为了能及时发现这些阻碍系统正常运行的异常行为,避免造成更大的损失和影响,因此需要对系统进行异常行为的检测和潜在安全隐患的挖掘[2].
系统日志详细地记录了服务器、应用软件等相关活动中必要的信息,是系统异常检测的主要数据来源.对于传统的独立系统,管理人员通常采用人工检查的方式来获得表明故障的日志.然而,随着现代大型系统的普及,日志的复杂性增大,在此背景下,直接依靠人力检查的传统异常检测方式变得不再现实.为了满足现代大型系统的异常检测需求,以数据驱动为核心的自动日志分析技术得到了广泛的研究和发展.其通过自动化地学习日志模式和分析内在联系,从而有效识别出日志中的潜在异常.然而,现有的方法大多只是在单一视角通过特定的异常特征对日志直接进行分析,缺少在多视角下对日志的深度分析及对异常日志所包含的信息量的利用.此外,单阶段的单一技术检测方式虽然在理论上可行,但是在实际应用中还存在有计算困难、效率低等局限性.针对以上情况,我们提出了一种融合Canopy算法和谱聚类技术的多阶段日志异常检测方法CSCM,该方法通过提取日志中的信息量和在多视角下分析日志间的关联性来实现异常数据的有效挖掘.本文的贡献点如下:
1)提出引入信息熵以提取日志中蕴含的信息量,并基于信息熵理论将原始日志集表征为多维加权信息点.
2)提出了一种预聚类下细化分析与多视角异常提取相结合的分阶段多技术的检测方式.首先,通过Canopy进行快速预聚类,提取子集重叠部分数据以减少后续计算量;其次,利用谱聚类技术对提取的数据进行细化分析,并结合预聚类结果进行优化,以解决谱聚类第2阶段中的初始化问题;最后,针对聚类后的数据进行多视角下的异常提取.
3)提出了多视角下异常日志的提取方法.通过在全局与局部视角下对日志间的内部关联进行分析,分别提出显性异常对象与隐性异常对象的定义,并结合稀疏簇各质心特征向量的分析及信息点异常度指标的计算,最终实现了异常数据的提取.
2 相关研究
基于自动日志分析的异常检测技术有多种实现方式,主要可分为两大维度:监督类的方法和无监督的方法.其中,监督类的方法通常依赖标签日志集(如正常或异常)进行检测.例如,Reidemeister等人[3]通过学习训练已知标签的日志集来构造C4.5决策树分类器,从而实现系统日志故障的自动化检测.Kimura等人[4]通过训练已知标签的日志矢量数据来构建高斯核支持向量机,用以检测系统可能发生的故障.但是,由于标签日志在现实中难以获取,所以监督类的方法在实际中的应用存在一定的局限.与监督类方法不同,无监督的方法由于不需要先验知识,因此可以很好的应用于真实的生产环境.其检测思想是通过分析数据间的关联性来构造正常行为基准,而偏离基准的数据将被视为异常.例如,Lin等人[5]设计了一种基于层次聚类的异常检测方法LogCluster,其通过知识库的使用来构建日志行为基准,用以检测偏离基准的异常日志.Chen[6]等人提出了一种基于增强型DBSCAN聚类的异常检测方法.其通过对比正常日志的行为轮廓来进行异常的识别.然而,这些方法只采用了单一的技术方法进行分析,随着日志数据的复杂性增大,由于技术本身的局限性,可能会出现检测效率低或准确度不够的情况.为了解决以上的挑战,最近的研究逐渐趋向于分阶段多技术相结合的方式,即通过在不同的阶段中结合不同的技术来解决单一技术不能满足检测效率和准确度平衡的问题.因此,在基于自动日志分析的异常检测研究中考虑分阶段多技术相结合的方式对于检测性能的提升有着重要意义.
另一类工作则集中在结合不同技术来分析日志文件的异常检测研究.其通常采取的阶段方式为:
1)初步筛选处理数据,以辅助后续分析;
2)对初筛后的数据进行分析,以识别异常.
例如,Ji等人[7]通过结合低维可视化技术PCA和K-Means聚类算法实现了DNS日志的异常检测.其采取先降维后聚类的阶段方式有效的解决了高维日志数据计算困难的问题.Hajamydeen等人[8]提出两阶段的检测策略,通过结合两种聚类技术实现了对异构日志数据的异常检测.Liu等人[9]提出了一种融合了K-prototype聚类和K-NN分类技术的日志异常检测方法.该方法通过采用“聚类-过滤-细化”的多阶段异常检测方式有效的减少了待检测的日志数据.然而,这些工作多数只针对于特定的应用服务场景.此外,它们大多没有关注到日志本身所蕴含的信息量及对异常候选日志多视角分析,使得方法在检测性能上还有待提升.为了解决上述挑战,受到相关启发,本文通过利用日志中的信息量和分析多视角下的日志特性,提出了一种结合Canopy算法和谱聚类技术的多阶段异常检测方法CSCM( Model combining Canopy and Spectral Clustering),用以进一步提高异常检测性能.
3 CSCM日志异常检测模型
为了提升模型的异常检测性能,本文设计了一个基于自动日志分析的异常检测模型CSCM.该模型包含了多个检测阶段,分别为基于信息熵的数值化过程、Canopy预聚类分析、谱聚类细化分析和多视角异常对象提取.CSCM模型的检测工作流程如图1所示.
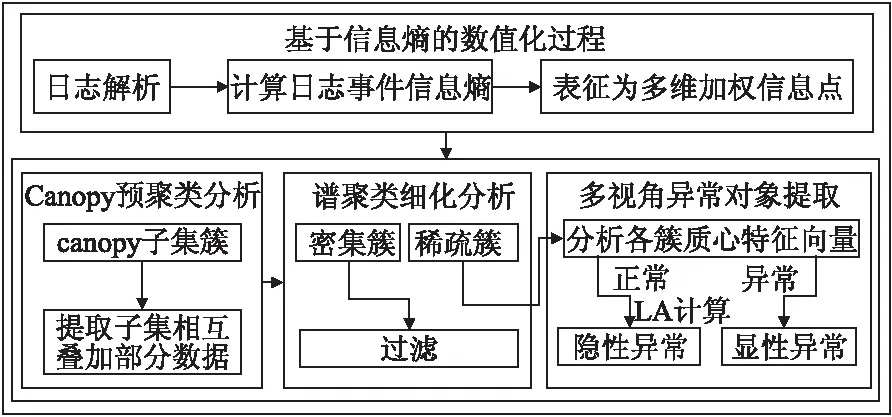
图1 CSCM模型检测工作流程图Fig.1 Workflow of the CSCM model
3.1 基于信息熵的数值化过程
原始日志通常为无结构化的文本数据,不利于检测模型的识别.为了能应用于检测模型的输入,原始日志需要进行日志的数值化过程.首先,对于无结构化的原始日志,采用文献[10]中的方法对其进行日志解析,形成结构化的日志文件,并生成日志事件.然后,通过分组技术划分日志文件,构建日志事件计数矩阵.
信息熵理论通常被用于度量事物所包含的信息量,因此,为了能提取出日志中所包含的信息,提出在数值化过程中引入信息熵.认为不同的日志事件在异常识别上具有不同的重要性,其能提供的信息量也是不相同的.对于发生概率较低的日志事件,例如,异常事件,其比经常发生的正常日志事件更能提供较多的信息量.为了能最大程度的表征出日志中的信息,我们为每个日志事件计算其信息熵,并采用熵权法[11]为日志事件进行加权.
式(1)从概率统计方面给出了信息熵的定义:
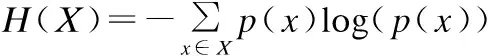
(1)
其中,H(X)为信息熵,X为随机变量,p(x)代表X中发生随机事件x的概率.根据上述定义,引入信息熵为日志事件Ej进行加权,方法如式(2)所示:
(2)
其中,Wj为日志事件Ej的权重,m为事件类型数,H(Ej)为日志事件Ej的信息熵.H(Ej)的取值如式(3)所示:
(3)
其中,n为日志序列总数,c为归一化系数,p(Eij)表示在全部日志序列的Ej事件中,第i条日志序列中Ej事件发生的概率.c和p(Eij)的取值如式(4)、式(5)所示:
c=(lnn)-1
(4)
(5)
其中,Dij为第i条日志序列上Ej事件发生的次数.
在所有的事件权重计算完成后,将会生成日志事件权重矢量W,W=(W1,W2,W3,…,Wm),然后,利用事件权重矢量W为计数矩阵进行加权.最终,可将原始无结构化的文本日志数值化为m维空间下的多维加权信息点,以用于检测模型的输入识别.
3.2 Canopy预聚类分析
通常,数据的规模和模型的初始值是影响异常检测模型的检测性能的重要因素.在数据量大的情形下,检测模型容易出现计算困难,检测时间延长的现象.同时,不合理的初始值及繁琐的初始化过程也会降低模型的检测效果和加大计算量.为了提升模型的检测性能,可以从减少数据量和优化初始值选取的角度进行分析.其中,减少数据量的方向之一是可以采用针对大规模数据处理的聚类算法先对数据进行预聚类,然后,再针对聚类后的簇集进行后续的处理.这类算法往往执行速度快,计算简单,可以将大规模的数据快速聚集成簇,使得研究对象从单个的数据点转换成包含多个相似点的簇集,从而减少后续需要分析的数据.
Canopy是一种计算复杂度较低、执行速度较快的聚类算法,可以快速地将海量高维数据聚类成簇,十分适用于数据的预聚类阶段[11].其算法的基本思想是:通过初始定义中心点和区域半径T1、T2,将数据集简单快速地粗聚类成若干可重叠的子集,如图2所示.Canopy算法步骤如下:
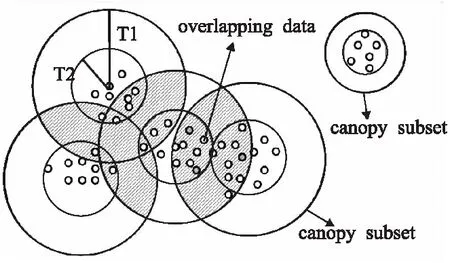
图2 Canopy聚类生成图Fig.2 Result of Canopy clustering
Begin
Step1.从数据列表中任取一个样本P作为第一个Canopy质心,并将样本P从数据列表中删除;
Step2.从数据列表中任取一个样本Q,用低成本的方式快速计算Q到所有Canopy质心的距离,选择其中最小的距离D;
Step3.若T2
Step4.重复步骤2、步骤3,直至数据列表为空.
End
由于Canopy算法对数据执行的是“粗聚类”,其精度较低,故聚类后的簇集还需进一步处理.为了提高模型的检测效率和减少后续的计算量,我们只提取Canopy子集中相互交叠部分的数据进行下一步的处理.这是因为交叠部分的数据被Canopy粗聚类到了多个子集中,是属于多个子集的共同元素,需要后续的进一步划分.而未处于交叠处的数据由于只归属于某一子集,所以无需额外的处理分析.因此,通过Canopy的预聚类过程及对子集交叠处数据的提取,可以减少后续阶段的计算量,避免可确认数据的重复计算,从而提高模型的检测效率.
3.3 谱聚类细化分析
在提取出Canopy子集交叠处的数据之后,需要采用聚类精度更高的算法对提取的数据进行进一步划分,以便于后续的异常提取,故本文采用谱聚类算法进行细化分析.
谱聚类是一种从谱图理论中发展出来的聚类算法,其主要思想是将聚类问题转化为最优子图的划分问题[13].相较于传统的聚类算法,谱聚类在多维稀疏数据上的表现十分良好.谱聚类算法可分为两个阶段.第1阶段:根据数据构造相似矩阵并计算得到Laplacian矩阵,将Laplacian矩阵进行特征分解获得相应的特征向量;第2阶段:采用K-Means算法对特征向量进行聚类.
然而,谱聚类算法的稳定性极易受到第2阶段K-Means算法的影响[14],其主要表现在K-Means算法对于初始中心点及簇数k值的敏感性上.K-Means复杂度如式(6)所示:
K-Means_time=O(mndk)
(6)
其中,m为迭代次数,n为数据点的个数,d为数据维度和k为簇集数.由于K-Means的初始值是完全随机选取的,k值过多的枚举尝试和不合理初始中心点将会造成算法的迭代次数m增大,从而导致计算量增加和聚类效果不稳定.为了减少谱聚类算法中的不稳定因素,需要对谱聚类第2阶段中的初始化问题进行优化.
此时,由于已经对数据进行了Canopy的预聚类分析,所以可以结合预聚类的结果对第2阶段初始值的选取进行优化,从而达到提高谱聚类算法稳定性的目的.我们将Canopy预聚类生成的簇数作为谱聚类第2阶段中K-Means算法的k值,已生成的聚类中心作为谱聚类第2阶段中K-Means的初始中心点.通过结合Canopy预聚类结果获取相应的初始值,不仅可以增加初始值的可信度和算法的稳定性,还能降低因过多的枚举尝试和迭代计算造成的额外计算量.从优化初始值选取的角度减少模型的计算量,并提高模型的整体稳定性和检测精度.优化后的谱聚类算法的细化步骤如下:
Begin
Step1.将Canopy预聚类生成的聚类中心作为聚类初始中心点;
Step2.取任意两个canopy子集交叠部分的数据,并将其从数据列表中删除;
Step3.为交叠数据构造相似矩阵,通过Laplacian矩阵进行特征分解并获得相应的特征向量;
Step4.将特征向量分配到最近的簇集,更新聚类中心;
Step5.重复步骤2、3、4,直至列表中交叠数据为空.
End
在谱聚类完成之后,交叠处的数据被细化地聚类到了每一簇中.此时,为了能更好的服务于后续异常对象的提取,针对聚类后的簇集,将根据簇集所包含数据点的规模进行密集簇和稀疏簇的划分.划分阈值为Q,Q=N/K,其中,N为数据点的总数,K为生成的簇数.若簇中数据点的规模不小于阈值Q,该簇将被划分为密集簇,反之,则为稀疏簇.
3.4 多视角异常对象的提取
异常对象通常被定义为与其它数据显著不同,并且偏离其他数据预期典型行为的对象.为了能充分识别出异常对象,本文根据不同视角下的日志分析,提出显性异常对象与隐性异常对象的定义.将全局视角下明显偏离数据集预期典型行为的对象定义为显性异常对象,将局部视角下相对偏离数据集预期典型行为的对象定义为隐性异常对象,用以实现多视角下异常对象的提取.
通常,服务器在大多数的情况下为正常的运行状态,因此,其生成的日志数据往往是由大量表征正常运行的日志和少量表征异常状况的日志组成.而这些表征正常运行的日志在行为上大多是高度相关的,所以在聚类上通常会表现为大规模的密集集群,而异常日志由于与日志集中大多数正常日志的行为偏离,故会被聚类成小规模的稀疏簇[15].由于密集簇代表了日志集中大量日志的预期正常行为,因此,只需针对稀疏簇进行异常对象的分析与判定.此外,质心点通常代表了一个簇的总体向量特征,可以通过对稀疏簇各质心点特征向量的分析来帮助实现异常对象的提取.
3.4.1 显性异常对象的提取
基于显性异常对象的定义,将质心为异常特征向量的稀疏簇中的所有数据均识别为显性异常对象.这是因为这一部分数据的总体向量特征为异常状态,且在全局的视角下,可以观察到其明显地偏离于密集簇的大量典型正常行为.例如,某个时间段内的连续身份认证失败或频繁断开连接等规模性较小的异常行为,通过聚类,将会被聚集成包含全部异常点且质心为异常状态的稀疏簇.因此,通过对稀疏簇异常质心的分析,可以快速有效识别出显性的异常对象.
3.4.2 隐性异常对象的提取
由于稀疏簇集中也会存在由正常行为聚集成的小规模簇,为了能检测出局部视角下相对偏离的隐性异常对象,我们为质心是正常特性向量的稀疏簇中每个数据点分配了一个基于局部异常因子(LOF)计算的异常度指标LA.LA通过对比一个点与其邻居的局部可达密度的情况来获取该点的异常程度.因此,若一个点的局部可达密度与其邻居们的局部可达密度均值的对比值越大,该点的局部异常因子就越大,则它的异常度指标LA也就越高.
设o是簇中的任意一点,Nk(o)为点o的k距离领域,p为k近邻中的点,则点o的异常度计算如式(7)所示:
(7)
其中,ρ(o)表示点o的局部可达密度,如式(8)所示:
(8)
其中,d(o,p)为点o与点p的距离.
在为簇中的各数据点计算了异常度指标LA之后,我们设定了异常度阈值用以识别隐性的异常对象.若簇中数据点的异常度大于阈值,则该数据点将被识别为隐性异常对象.这是因为该点的局部可达密度与其邻居的显著不同,在局部的视角下,与邻居点较为疏远,因此,极有可能为隐性的异常对象.
4 实验结果
4.1 数据集
实验数据的来源是来自Hadoop分布式文件系统日志的公开数据集[1].所有的日志都被原始领域专家手动标注了标签.原始的日志数据集经日志解析后生成结构化日志文件集,格式如下:< LineID | Date | Time | Pid | Lever | Component | Content | EventID | EventTemplate >,其中,LineID、Pid和EventID分别为数据块、线程和事件的id,Date和Time记录了日志的日期时间,Lever代表日志等级,Componet为日志组件信息,Content为日志具体内容,EventTemplate为生成事件的模板.最终,通过分组技术将507,645条日志划分成了34,558条的日志序列,其中,包含了异常日志序列1747条.
4.2 CSCM性能评估指标
模型性能的分析通常有多种评估方式.为了能客观评价CSCM方法的性能,实验将从CSCM的聚类过程和异常提取进行评估.其中,聚类模型的有效性可通过内部或外部指标进行评估,而DB指数作为聚类效果评估的内部指标,通过对样本的簇内离散度与各簇之间的距离进行分析,可以很好的评估模型在聚类过程中的聚类效果.DB指数的定义如式(9)所示:
(9)
其中,k为簇数,Mi为簇中的样本到其簇中心Ci的平均距离,Cij为簇Ci和Cj的距离.因此,聚类模型的DB指数越小,表示其生成的簇之间的相似度越低,该模型的聚类效果就越好.
而在异常检测的领域,精确度(Precision)、召回率(Recall)和综合评价指标(F1-measure)通常被用于评估检测模型的性能.其中,精确度是描述被提取出来的异常对象中真实异常所占的比例;召回率是描述检测出的真实异常在总异常中的占比;综合评价指标是精确度和召回率的加权调和平均.3种指标的定义如式(10)-式(12):
(10)
(11)
(12)
其中,真阳性(TP)代表了被正确标识为异常的异常对象数目,假阳性(FP)表示了被错误识别为异常的正常对象数目,假阴性(FN)为被错误标识为正常的异常对象数量.
实验将使用内部评价指标(DB指数)来评价CSCM聚类过程的性能,使用3种检测评价指标(Precision、Recall、F1-measure)和运行时间(Runtime)来评估CSCM异常提取的性能.
4.3 CSCM性能评估结果
4.3.1 聚类过程性能评估结果
为了证明传统的K-Means聚类算法在初始值上的敏感性,我们在日志集里随机抽取了100k的数据进行K-Means聚类,并采用公式(9)计算其DB指数.初始值k的选值对DB指数的影响如图3所示.
从图3中可以发现,传统的K-Means算法面对不同的k值进行聚类时,其DB指数性能会随着k值的选值出现较大幅度的波动.其中,当K-Means算法取到较为合理的k值时(k=11),此时,算法的聚类效果最佳(DB=0.238),其初始中心点能够均匀分布,有效的代表各簇的类别;当选取到不合理的k值时(k=5),此时,K-Means算法的聚类效果较差(DB=0.639),其初始中心点可能密集分布,不能有效的表征各簇的类别.因此,与最佳的聚类效果相比,DB指数的变化趋势较大,表现出了K-Means算法对于初始值的敏感性.
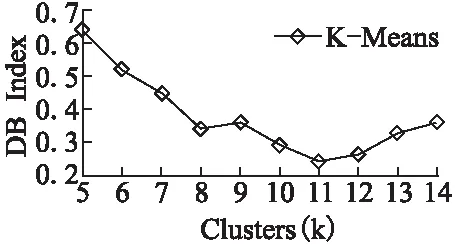
图3 K-Means初始值敏感图Fig.3 Sensitivity of K-Means initialization
为了进一步验证CSCM方法在聚类过程的有效性,将本文提出的CSCM方法与K-Means聚类算法和谱聚类算法进行了比较.从HDFS数据集中随机选取了5组不同规模的数据,分别为Test1、Test2、Test3、Test4和Test5,其对应的数据规模为10k、50k、100k、200k和500k.实验评估结果如图4所示.
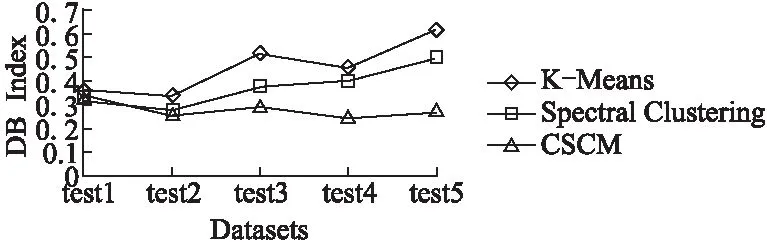
图4 聚类过程性能评估图Fig.4 Performance evaluation of clustering process
从图4中可以发现,当数据量较小时,3种算法的DB指数并没有表现出较大的性能差异.其中,谱聚类和CSCM方法要略优于K-Means算法,这是由于谱聚类和CSCM方法对于高维空间下任意形状数据的聚类表现较为良好.而与这两种算法不同,K-Means算法在面对高维稀疏的数据时容易受到“维度灾难”效应的影响,且受到凸型数据的限制,所以DB指数略高.
当数据不断增大时,谱聚类和K-Means算法的DB指数则出现了较大幅度的波动,而CSCM方法的DB指数总体趋于平稳.这是因为CSCM方法通过结合预聚类的结果提前确定了k值和初始中心点,有效的避免了初始值的随机性和减少了迭代次数m,使其可以在大量的高维稀疏数据的聚类中产生较为稳定的聚类效果,所以DB指数要优于其它两种算法.而由于K-Means算法和谱聚类对于k值及初始中心点的选取为完全随机的,其DB指数会随着初始值的选值而出现较大幅度的变化,因此产生的聚类效果并不稳定.当出现不合理的k值或初始中心点过于密集的情况时,可能会使其在大规模数据的聚类中被误分到同一簇的数据点个数显著增加,使得簇之间距离变小,簇内离散度变大,因此DB指数上升.而相较于K-Means算法,谱聚类由于在第1阶段时通过Laplacian矩阵进行特征分解缓解了“维度灾难”效应,所以其聚类表现要优于K-Means算法.综合以上数据,相较于其它两种单一的聚类算法,CSCM方法可以在聚类过程中产生良好且较为稳定的聚类效果.
4.3.2 异常提取性能评估结果
为了验证CSCM方法在异常提取上的有效性,实验首先评估了CSCM方法对显性异常及隐性异常对象提取的性能.实验评估结果如表1所示.
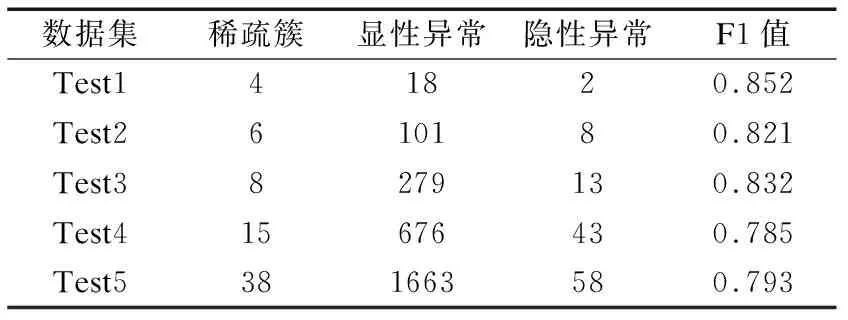
表1 异常提取结果评估表Table 1 Exception extraction evaluation
由表1所得,在对各稀疏簇质心点进行分析之后,通过显性异常和隐性异常的提取,各组异常的提取的综合评价指标均在78%以上.此外,在各组中,通过对正常质心的稀疏簇中各数据点的局部可达密度的计算,可以有效的提取出与正常值相对偏离的隐性异常对象,使得异常提取的有效性得到提升.其中,在Test3中,有8个簇被划分为了稀疏簇,通过显性异常对象提取方法,将序号分别为2、3、5、7、9稀疏簇中的共279个数据点均提取为显性异常对象.然后采用隐性异常对象提取方法对剩余各稀疏簇的数据点进行异常度指标的计算,分别从序号0、6、10的簇中提取出隐性异常对象9、0、4个,最终,通过与真实的标签进行对比,异常对象提取的综合评价指标为83.2%.
最后,将CSCM方法与文献[5]及文献[6]中提出的异常检测方法进行了对比实验.实验将从精确度、召回率、F1值和运行时间进行评估,实验分别运行10次,结果取均值,评估结果如图5、图6所示.
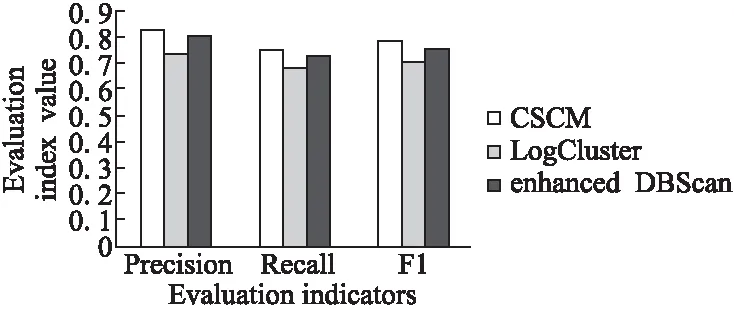
图5 3种指标性能评估图Fig.5 Evaluation value of three indicators
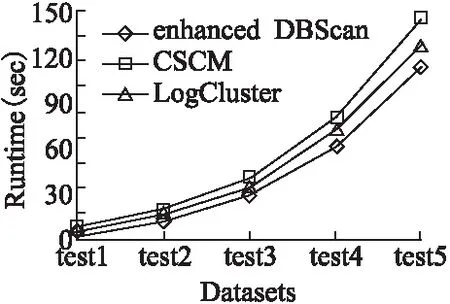
图6 运行时间评估图Fig.6 Performance evaluation of runtime
由图5可以看出,CSCM在3种指标上均优于其它两种异常检测方法.其中,在召回率指标上,CSCM方法的召回率最高(0.75).这是因为CSCM方法通过在簇后对稀疏簇质心进行分析以及对数据点进行显性和隐性异常对象的提取,能够有效识别出与正常值差别较小的异常对象,TP值得到提升.而相较于文献[6]中基于密度度量的方法,由于文献[5]中提出的方法是直接基于对象至正常簇质心的距离来判定异常点,故无法很好的检测出与正常值相差较小的异常对象,其召回率最低.在运行时间方面,3种异常检测方法的运行时间都随着数据规模的增大而显著增加,这是由聚类算法的特性所导致的.其中,由于文献[5]和文献[6]中提出的方法在初始阶段分别需要构建知识库和正常行为轮廓,因此需要进行数据的相似矩阵及邻域数据的计算,其时间复杂度分别为O(n2)和O(nlogn).而CSCM方法通过低成本的Canopy算法对数据进行了预聚类,其时间复杂度为O(n),所以CSCM方法在该阶段中的执行效率较高.即使CSCM方法之后还需要进行复杂度较高的谱聚类运算及显性和隐性异常的提取,但是由于CSCM方法在预聚类阶段中通过提取交叠数据提前减少了后续的数据量,使得谱聚类的输入和各稀疏簇的规模远远小于n,因此时间复杂度并不会显著增加.通过综合以上的分析,可以发现,本文提出CSCM异常检测方法与其它两种异常检测方法相比,可以在不同规模的日志集中实现稳定且综合指标较好的异常提取结果.
5 结 语
针对现代大型系统中系统日志的异常检测问题,提出了一种预聚类下细化分析与多视角异常提取相结合的分阶段多技术的检测方法CSCM.该方法引入信息熵以提取日志中的信息量.在Canopy算法的预聚类下,采用谱聚类技术对子集交叠部分数据进行细化分析,并优化初始值选取问题.最后,通过分析不同视角下的日志特性,提出显性与隐性异常对象的定义,以实现异常日志的识别.实验结果表明,通过预聚类及细化分析过程,并结合多视角下的稀疏簇质心点分析和数据点异常度计算,可以高效准确的检测出日志序列中的异常数据.
猜你喜欢
汽车实用技术(2022年4期)2022-03-07
华人时刊(2021年13期)2021-11-27
廉政瞭望·下半月(2021年5期)2021-07-20
诗选刊(2020年12期)2020-12-03
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
思维与智慧·上半月(2018年10期)2018-11-30
思维与智慧·上半月(2018年9期)2018-09-22
意林(2018年3期)2018-03-02
汽车生活(2018年1期)2018-02-02
电子技术与软件工程(2016年23期)2017-03-06
