
基于孪生网络融合多模板的目标跟踪算法
2022-03-02 08:32:00孙力帆付主木张金锦常家顺
计算机工程与应用 2022年4期
杨 哲,孙力帆,付主木,张金锦,常家顺
河南科技大学 信息工程学院,河南 洛阳471023
视频目标跟踪在自动驾驶、视频监控、人机交互等领域有着广泛的应用,是计算机视觉中基本的问题之一,它的任务是在视频序列中自动定位指定目标[1]。如何在目标形变、快速运动、背景干扰和遮挡等复杂环境中实现视频目标的有效跟踪是视频目标跟踪技术的一大挑战,是视频目标跟踪领域的研究热点。
视频目标跟踪的指标可归纳为两类:鲁棒性和实时性。传统的基于相关滤波的方法[2]利用循环矩阵和傅氏变换极大地提升了跟踪速度,核函数的引入将非线性问题映射到高维空间处理,进一步提高了算法性能。随着GPU技术的快速发展,深度学习技术在目标跟踪等机器视觉任务中得到广泛的应用,尤其是卷积神经网络引入深度特征,使跟踪算法的鲁棒性得到了很大的提升。但是卷积神经网络反向传播过程计算量较大,使得ECO(efficient convolution operators for tracking)[3]、C-COT(continuous convolution operator tracker)[4]等基于模型在线更新策略的跟踪算法在取得高精度的同时无法获得较快的速度,无法满足实时性需求。
近年来,基于孪生网络(siamese network)的目标跟踪算法由于其优越的精度和速度表现,在目标跟踪领域引起了人们的广泛关注。SINT(siamese instance search tracker)算法[5]和SiamFC 算法[6]将跟踪问题简化为模板匹配过程,即利用第一帧中提取的模板特征与下一帧中得到的搜索实例特征,通过比较相似度大小确定目标位置,选择相似度最高的候选框作为目标位置区域。其中SINT 算法和SiamFC 算法分别使用欧式距离和相关运算的响应值度量相似度,均取得了不错的跟踪效果。SiamRPN 算法[7]将检测任务中使用的RPN(region proposal network)网络应用到目标跟踪任务中,以锚框的形式取代了多尺度卷积过程,进一步提升了跟踪速度和精度。虽然这些跟踪方法取得了不错的效果,但由于使用固定不变的模板进行跟踪,在目标发生旋转、形变和运动模糊等外观变化时会出现模板匹配出错情况,从而进一步导致跟踪失败。因此,在跟踪过程中适时地进行模板更新是必要的。
关于跟踪过程中的模板更新问题,国内外学者进行了许多探索。CFNet算法[8]将相关滤波器作为可微层引入SiamFC 算法框架中,以岭回归的方式在跟踪过程中对初始模板进行微调。Guo等人[9]提出一种动态Siamese网络,通过一个快速转换学习模型,可以有效地从历史帧中在线学习目标外观变化。Guo 等人[10]在跟踪过程中使用生成对抗网络生成需要的模板,取得了一定的效果。以上算法在一定程度上提高了跟踪性能,但是在目标外观发生变化时跟踪失败情况仍然存在。
为解决SiamFC 算法在跟踪过程中的模板更新问题,本文提出一种基于孪生网络融合多模板的目标跟踪算法(siamese network fusing multiple templates,Siam-FMT)。该算法在特征级上建立模板库,以储存目标不同形态下的外观信息,然后通过多模板匹配获得多张响应图,最后融合多个响应图得到更加准确的目标位置。为提升模板库的有效性,本文使用平均峰值相关能量(average peak-to correlation energy,APCE)[11]度量目标被遮挡程度,避免遮挡物被引入模板库,然后根据模板相似度对冗余模板进行剔除。在OTB2015[12]和VOT2016[13]数据集上进行性能验证,实验结果表明本文算法在目标外观发生变化的多种复杂环境下均能有效跟踪运动目标,并取得较其他算法更高的跟踪精度。
1 卷积神经网络的平移等变性
对于步长为k的卷积过程g来说,参数共享的特殊形式使其具有平移等变的性质[14],此性质可使用式(1)进行描述:

式中,L为平移变换函数,τ为平移距离,即图像x先平移kτ步再通过卷积过程g与直接对g(x)平移τ步等效。
卷积神经网络(convolutional neural network,CNN)的平移等变性如图1所示,ϕ为特征提取过程,*为卷积运算。搜索区域中图像A 和模板图像E 经过特征提取和卷积运算得到响应值R1;在下一时刻,区域A经过一段位移到达区域B,区域B 和区域E 经过特征提取和卷积运算得到响应值R2;若跟踪正确,R1 和R2 应分别是两张响应图中最大值,并且在响应图中的距离(绿色箭头)与区域A 到区域B 之间的距离(黄色箭头)呈比例关系,此比例系数为网络总体步长。本文将跟踪结果映射回特征向量,通过在特征向量上的直接裁剪避免重复特征提取过程,从而加速跟踪进程。
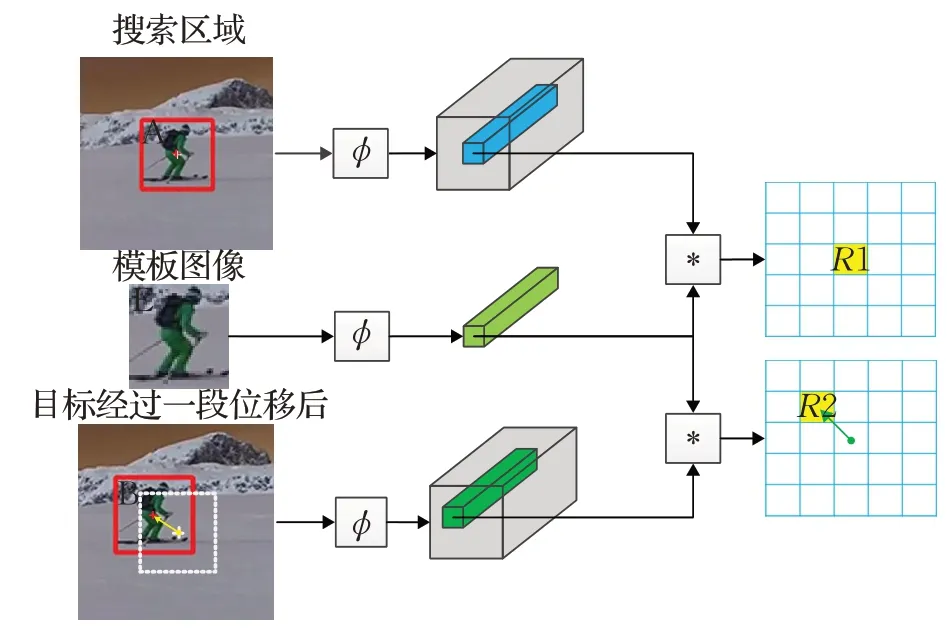
图1 卷积神经网络平移等变性Fig.1 Translation equivariance of CNN
2 多模板融合目标跟踪算法
随着目标外观不断发生变化,基于孪生网络的目标跟踪算法仅仅使用第一帧提供的模板信息则无法满足跟踪需求。因此,本文通过构建模板库来记录目标在不同形态下的外观信息,使用多模板匹配和响应图融合以适应在跟踪过程中目标外观发生变化,提高跟踪准确率。此外,本文从特征级别建立模板库,避免在引入新模板时再次重复模板特征提取过程,在保证跟踪速度的同时有效提升了跟踪精度。
2.1 网络结构
SiamFMT的网络结构如图2所示,输入部分是典型的孪生网络结构,拥有模板分支和搜索分支两个输入,模板分支和搜索分支的输入分别为模板图像Z和搜索图像X。模板图像Z根据视频序列第一帧提供的目标位置信息裁剪得到,搜索图像X是由视频序列的后续帧根据上一帧跟踪结果裁剪得到,跟踪过程中部分序列的模板图像和搜索图像如图3 所示。ϕ代表卷积神经网络特征提取过程,本文采用修改后得到的AlexNet[14]作为特征提取网络主干结构框架,网络各层参数如表1所示。
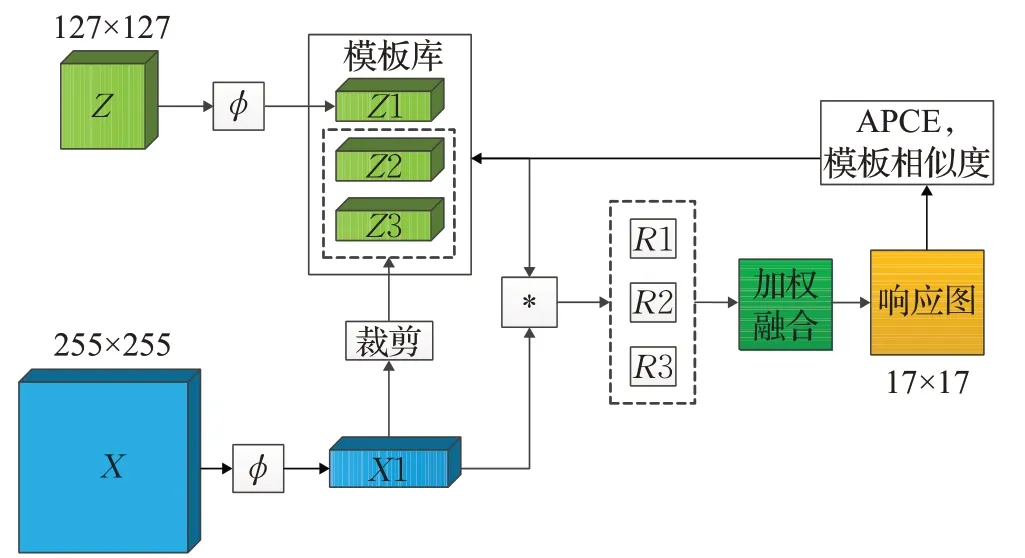
图2 SiamFMT网络结构图Fig.2 SiamFMT network structure

图3 跟踪过程中模板图像与搜索图像Fig.3 Template images and search images in tracking process
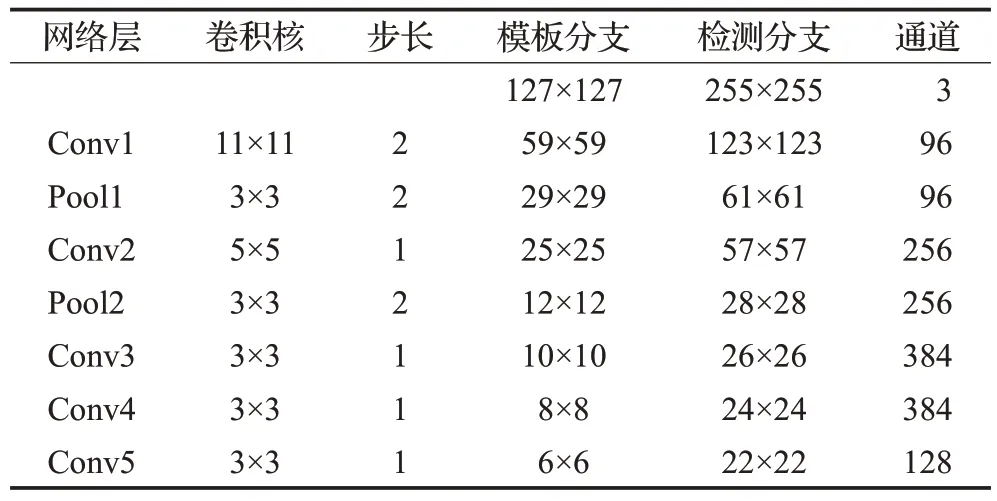
表1 特征提取网络各层参数Table 1 Feature extraction network parameters of each layer
通过实验发现,模板库中的模板数量设置为3时可以取得相对较好的跟踪速度和精度。因此,模板库中共包含3 个模板Z1、Z2、Z3,其中Z1 为原始模板图像Z经过特征提取网络ϕ提取得到的特征向量,Z2 和Z3是根据跟踪结果对特征向量X1 进行裁剪得到。模板库中的3个模板Z1、Z2 和Z3 分别与X1 进行卷积运算得到响应图R1、R2 和R3,本文以线性加权的形式对R1、R2 和R3 进行融合,从而得到更加可靠的响应图,以提升跟踪精度。其中R1、R2 和R3 的权重分别设置为0.8、0.1、0.1。
2.2 模板库的构建与更新策略
在跟踪过程中,目标模板被过于频繁地更新不仅可能会导致跟踪漂移现象,而且会影响跟踪速度,因此模板更新的频率要适度。本文设定在目标外观发生变化时进行模板更新,在目标被遮挡时停止模板更新,具体流程如图4所示。
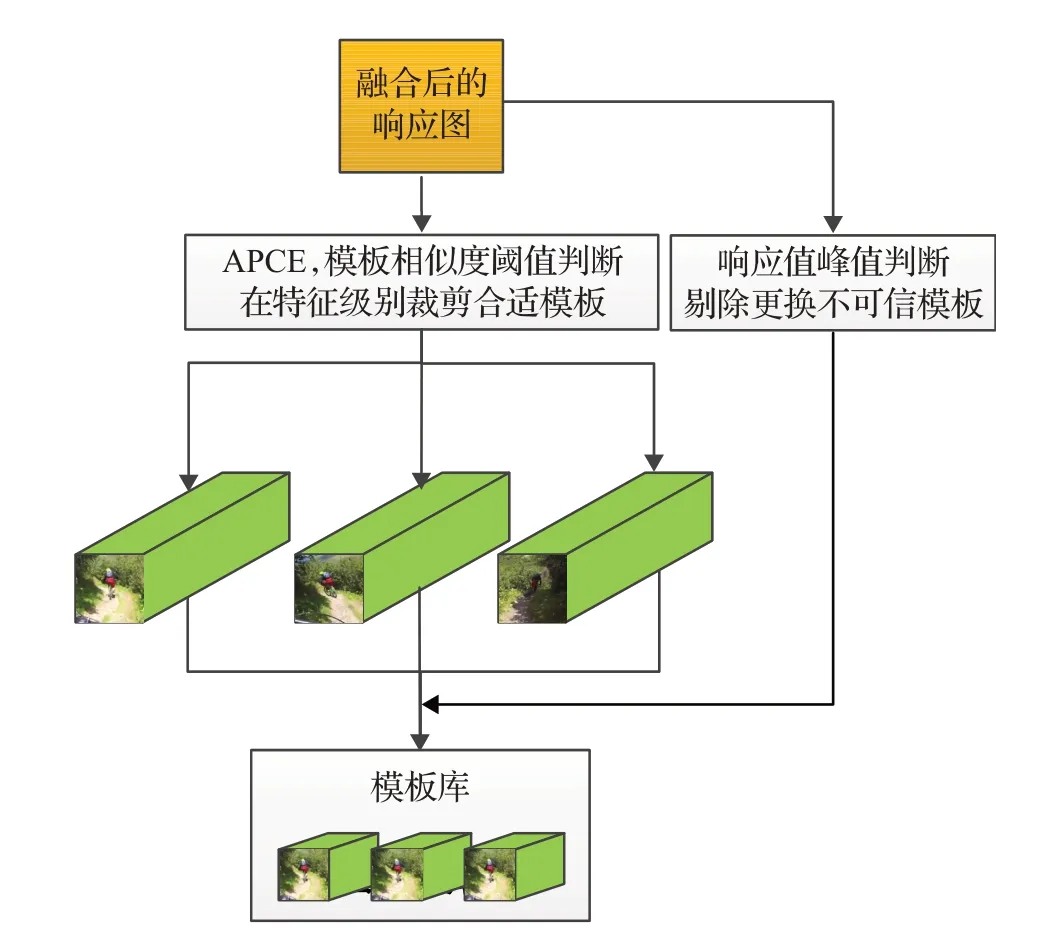
图4 模板库构建流程Fig.4 Flow chart of building template library
为避免在目标发生遮挡时进行模板更新,而将干扰物引入模板库。本文采用平均峰值相关能量APCE 对目标被遮挡的程度进行度量,计算公式如下:
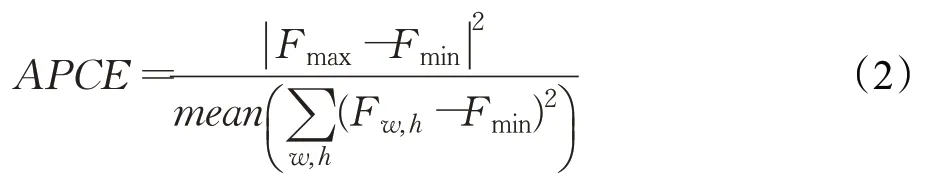
式中,Fmax、Fmin、Fw,h分别代表响应图中的最大值、最小值和坐标(w,h)处对应值。分子部分反映响应图中峰值大小,代表了当前响应图的可靠程度,分母表示响应图的平均波动程度。如图5 所示,在目标未发生遮挡时,响应图会呈现单峰状态,峰值较高且APCE值较大;而在目标发生遮挡时,如图6 所示,响应图会呈现多峰状态,峰值较低且APCE 值较小。本文利用这一特性,通过APCE值的大小来判断目标发生遮挡的程度,从而保证模板更新的有效性。

图5 无遮挡情况(APCE=12.03)Fig.5 No occlusion(APCE=12.03)
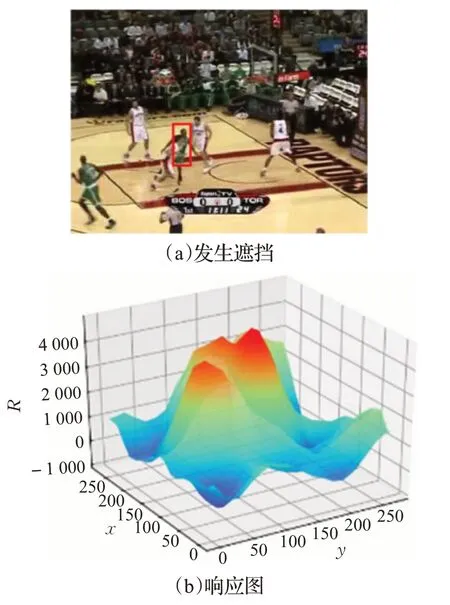
图6 有遮挡情况(APCE=3.26)Fig.6 Occlusion(APCE=3.26)
在模板更新过程中,要避免引入外观较为相似的冗余模板,冗余模板的引入会造成有效模板的损失。本文将模板间卷积运算的响应值之比定义为模板相似度S,公式如下:

式中,Tnew为新模板,Ti为原始模板,i为模板数量,∗为卷积运算。通过计算新模板与各个旧模板之间的相似度,设置适当的阈值范围对冗余模板进行过滤,避免被引入模板库。本文选取的模板相似度阈值范围是0.6~0.8,即两模板之间的相似度不高于80%且不低于60%。
模板更新过程中始终保留原始模板Z1,当模板Z2和Z3 对应的响应图中峰值小于融合后响应图峰值的80%时,本文认为该模板已经不再适用于后续帧,并将其标注为需要更新的模板,在新模板到来时完成替换。如图7 所示,S1、S2 和S3 分别为当前经裁剪所得模板与模板库中Z1、Z2、Z3 模板间的相似度。视频序列第79 帧对应的APCE 值超过了设定阈值9,模板相似度S1、S2 和S3 均在阈值区间0.6~0.8 内,并且模板Z2 此前被标记为待更新模板,此时将对模板Z2 进行更新,将其替换为新模板;视频序列第80帧的APCE值虽然超过了阈值9,但与模板库中第3个模板间的相似度为0.92,不在阈值区间内,故不再进行更新。

图7 模板更新过程Fig.7 Template update process
2.3 相似性学习
本文通过离线学习的方法训练特征提取网络,模板图像X和搜索区域图像Z通过权重共享的卷积神经网络提取特征,提取到的特征向量经过相似性度量函数f(Z,X)得到图像X和图像Z之间的相似程度,即:

其中,∗代表卷积运算,ϕ(⋅)代表卷积神经网络的特征提取过程,响应值越高就证明图像间的相似程度越高。图像X的尺寸一般要大于图像Z的尺寸,在进行相似性度量之后会得到包含多个响应值的响应图:

训练过程中,相似度学习的目标为在目标所在位置获得最大响应值,可公式化如下:

式中,Y为样本标签,θ为网络参数,N代表样本数量,损失函数L定义为:

其中,R(u)为响应图中位置u对应的响应值,u∈D,D为响应图中位置索引集合;Y(u) 为真实样本标签且Y[u]∈{+1,-1},{+1,-1}分别代表正负样本,其由位置u与响应图中心位置c之间的欧式距离决定,即:
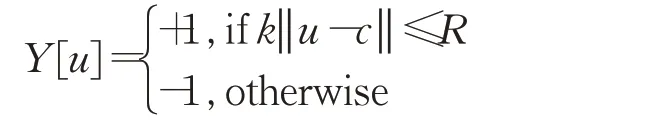
式中,R取16作为设定好的阈值,k为网络步长。
在跟踪阶段,以上一帧跟踪结果作为当前帧图像的搜索中心,得到的当前帧中最大响应值相对于响应图中心的位移,乘以网络总步长,就得到了目标在帧与帧之间的位移,从而获得当前帧中目标的中心位置。
3 实验分析
本文算法在Intel®Xeon®Sliver 4110 2.1 GHz CPU和NVIDIA GeForce RTX2080 GPU的计算机硬件平台上,Pytorch环境下编程实现。使用常用数据集OTB2015和VOT2016 对算法性能进行验证,参与对比算法为开源代码或根据原文复现得到,并在同一硬件平台上进行性能对比,软件操作界面如图8所示。

图8 软件操作界面Fig.8 Software operation interface
3.1 训练阶段
SiamFMT 在离线训练阶段采用ILSVRC2015 数据集[15]进行训练。该数据集拥有4 500 个训练视频序列,可以很好地满足训练需求。训练过程中使用随机梯度下降算法(stochastic gradient descent,SGD)进行网络参数优化,学习率设置为0.01,训练30轮,取后10轮中的最优结果。训练损失曲线如图9所示,可以看出训练过程中训练损失和验证损失逐渐下降,说明模型逐渐收敛,最终在25轮之后损失曲线下降不再明显,逐渐趋于稳定。

图9 训练损失曲线Fig.9 Training loss curve
训练完成后,将卷积层的部分通道输出结果可视化,如图10 所示。从图中可以看出浅层网络如Conv1和Conv2提取到边缘、形状、轮廓等基础特征,深层网络如Conv4和Conv5提取到一些较为抽象的语义特征。

图10 各卷积层输出结果Fig.10 Output results of each convolutional layer
3.2 模板数量的确定
模板库中模板数量的确定是本文算法的关键,模板数量过多,跟踪速度会明显下降,模板数量过少又会由于有效信息不足而造成跟踪精度下降。
本文在OTB2015 数据集上取多组参数进行实验,如表2所示。当模板数量超过3时跟踪性能上升不再明显,而跟踪速度持续下降,并且当模板数量为3时,跟踪精度和速度均有不错的表现。因此,本文确定模板库中的模板数量为3。

表2 模板数量对性能指标的影响Table 2 Impact of number of templates on performance
3.3 响应图融合
大小为17×17的响应图R1、R2、R3经过双线性插值尺寸转化为255×255,将其映射到原图,如图11所示,可以看出R1 和R3 受到右上角相似人物和下方背景干扰较为严重,R2 受干扰程度较轻。若使用单模板跟踪策略,会出现跟踪漂移现象,导致跟踪失败。在进行多响应图加权融合之后,响应图下方和右上角的干扰得到抑制,受干扰程度明显降低。
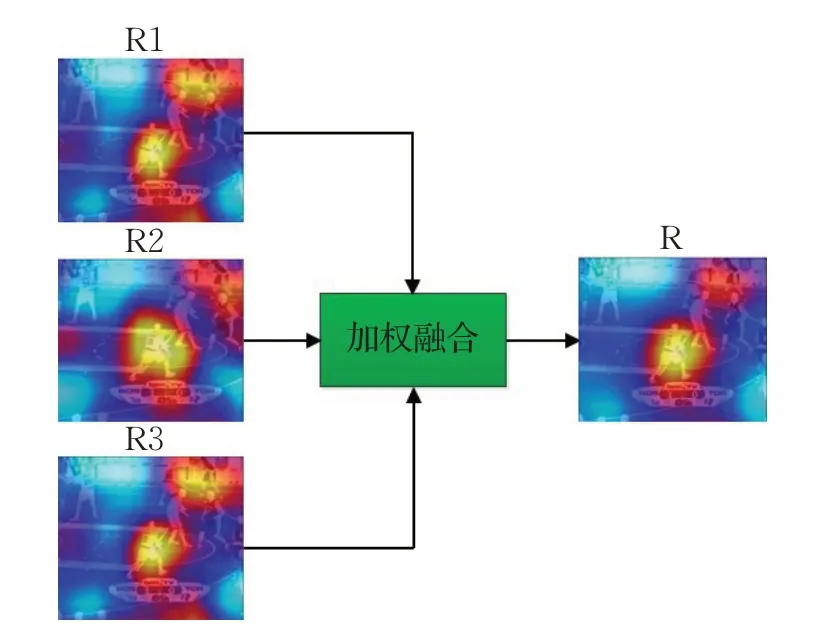
图11 多响应图融合Fig.11 Multiple response maps fusion
3.4 OTB2015基准实验
OTB 是目标跟踪领域最常用的数据集之一,其中OTB2015(OTB100)数据集拥有100 个视频序列,包含遮挡、快速运动和光照变化等11 种复杂情况。本文依据精确度和成功率两个指标对跟踪算法进行评价,并使用这两个指标绘制出精度图和成功率图。精确度代表跟踪结果和数据集标注中心位置的欧式距离小于一定阈值的成功帧数与总帧数的比值,成功率代表跟踪框覆盖率大于一定阈值的帧数和总帧数的比率,其中覆盖率是指预测跟踪框与标注跟踪框之间交集部分面积和并集部分面积之比。
如图12 所示,本文算法SiamFMT 在与SRDCF[16]、Staple[17]、CFNet、SiamFC、fDSST[18]的对比实验中均取得了领先水平,跟踪精确度达到了0.824,成功率达到了0.609。其中和SiamFC算法相比较,精确度提升了6.7%,成功率提升了3.7%,这表明SiamFMT的模板库机制是有效的。

图12 OTB2015数据集对比结果Fig.12 Comparison results of OTB2015 dataset
为进一步分析本文算法在不同复杂情况下的表现,将本文算法在OTB2015数据集中11种复杂情况下的精度图绘制出来,依次是低分辨率(low resolution,LR)、平面内旋转(in-plane rotation,IPR)、非平面旋转(out-ofplane rotation,OPR)、尺度变化(scale variation,SV)、运动模糊(motion blur,MB)、遮挡(occlusion,OCC)、形变(deformation,DEF)、快速移动(fast motion,FM)、离开视野(out-of-view,OV)、光照变化(illumination variation,IV)、复杂背景(background clutters,BC)。
如图13所示,在11种复杂情况下,本文算法SiamFMT与单模板策略算法SiamFC 相比均有所提升。其中,在平面旋转IPR、尺度变化SV、运动模糊MB 和形变DEF属性下,本文算法的精确度均提高了10%以上,这表明模板库可以很好地记录在各种形态下目标信息,与初始模板起到互补作用,提升了在目标外观发生变化时的跟踪精度,部分视频序列跟踪结果如图14所示。

图13 OTB2015数据集11种属性对比Fig.13 Comparison of 11 attributes on OTB2015 dataset

图14 6种算法跟踪结果对比Fig.14 Comparison of tracking results among 6 algorithms
3.5 VOT2016基准实验
为进一步验证本文算法性能,本文选择在VOT2016数据集上对算法进行评估,参与对比的算法有SiamFC、Staple、DeepSRDCF[4]、SRDCF、STRUCK[19]。VOT2016包含60 个具有挑战性的视频,通过准确率(accuracy,A)、鲁棒性(robustness,R)和平均重叠期望(expected average overlap,EAO)对算法性能进行定量评价。准确率和平均重叠期望分数越高,鲁棒性分数越低,跟踪算法性能越好。对比结果如表3和图15所示,本文算法SiamFMT的各项性能指标均优于参与对比的其他算法。本文算法与单模板策略的SiamFC算法相比,EAO提升了25%。
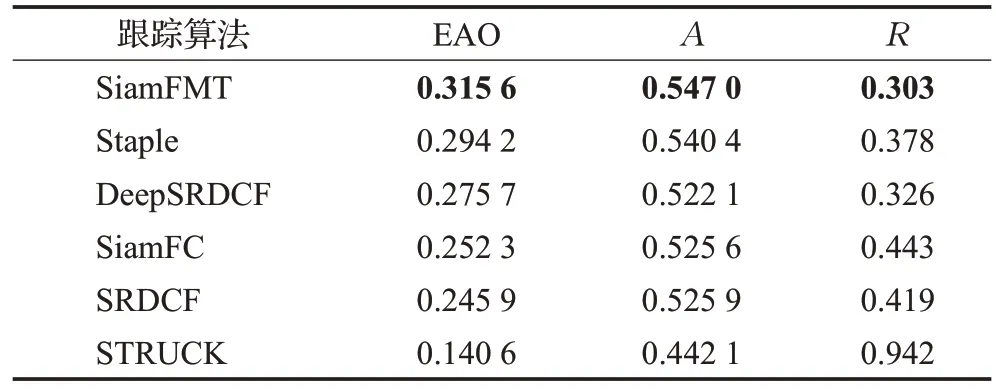
表3 VOT2016数据集跟踪结果Table 3 Tracking results on VOT2016 dataset
4 结束语
为解决目标外观发生变化时跟踪不准确的问题,本文提出了一种基于孪生网络融合多模板的目标跟踪算法。该算法通过构建模板库对目标不同形态下的外观信息进行记录,提升了对目标外观变化的适应能力。在跟踪过程中,以平均峰值相关能量和模板相似度对模板进行有效性评估,同时对冗余模板进行有效剔除。最后,在OTB2015和VOT2016数据集上进行性能验证,结果表明本文算法可以在目标外观发生变化的情况下更加有效地跟踪指定目标,并且在保证跟踪速度的前提下有效提升了跟踪精度。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31 08:59:12
阅读(快乐英语高年级)(2022年6期)2022-06-17 04:48:48
家庭影院技术(2021年10期)2021-11-20 06:08:52
科教导刊·电子版(2021年1期)2021-03-28 03:31:54
环境与发展(2019年11期)2019-02-12 12:35:02
山东化工(2019年1期)2019-01-24 03:00:16
电子制作(2018年19期)2018-11-14 02:37:08
紫禁城(2017年6期)2017-08-07 09:22:52
自动化学报(2017年11期)2017-04-04 02:52:58
噪声与振动控制(2015年4期)2015-01-01 07:08:21
