
基于长短期记忆近端策略优化强化学习的等效并行机在线调度方法
2022-02-28 02:16:00贺俊杰汪俊亮
中国机械工程 2022年3期
贺俊杰 张 洁 张 朋 汪俊亮 郑 鹏 王 明
1.东华大学机械工程学院,上海,2016202.上海交通大学机械与动力工程学院,上海,200240
0 引言
在晶圆制造、航天制造等生产系统中,各工序生产单元通常需要连续不断地将动态到达的工件指派到多台并行设备上,该类生产单元的调度问题是典型的等效并行机在线调度问题。以航天制造业为例,航天企业迫切需要实现短周期、高品质、快速响应的生产模式[1],但航天产品制造过程中有的零件包含复杂曲面,其特征复杂且加工质量要求高,需采用昂贵的多轴精密数控机床进行加工。此类零件的加工时间长且在加工过程中易报废,使得复杂曲面的数控加工工序成为航天零件实际生产过程中的瓶颈工序。航天零件生产具有设计迭代快、生产批量小的特点,需要车间调度人员快速作出调度响应。为降低生产成本,该类零件往往安排在同一车间生产,通过其中的任意一台同型号的数控机床进行加工。此外,晶圆生产的光刻区调度、炉管区调度,以及纺织品生产的织机调度、染缸调度,钢铁生产的转炉炼钢等都可抽象为此类调度问题。面对这类生产调度问题,在实现快速响应的同时最大程度上实现调度优化,是满足客户要求的必要条件,具有重要的理论意义和工程实际应用价值。
目前针对等效并行机在线调度问题的研究方法分为两种,一是启发式规则,BANSAL[2]和LEONARDI等[3]提出了最小化流动时间的启发式算法;SITTERS[4]和HALL等[5]提出了最小化完工时间的启发式算法,这种方法执行时间短,能够实现快速响应,但往往针对一种特定场景设计,缺乏自适应性[6]。二是智能算法,柳丹丹等[7]设计了改进遗传算法应用于等效并行机在线调度问题;许显杨等[8]提出了面向设备动态性的蚁群算法,该方法虽能精确求解,但求解时间长,无法实时响应,且频繁的滚动调度会导致准备工作效率低下[9]。在半导体制造、纺织品生产[10]等行业,因在制品众多且无法抢占加工,调度时需考虑等待未来到达的工件,进一步优化调度方案,因此,是否等待是最关键的问题。有学者在加权最短加工时间优先(weighted shortest processing time first, WSPT)规则[11-12]的基础上设计等待机制,如ANDERSON等[13]提出D-WSPT规则以优化单机的加权完工时间和;TAO[14]进一步提出针对等效并行机的AD-WSPT算法,但以上两种方法对在线调度的自适应性不足。
近年来,机器学习中的强化学习方法因具有自适应能力,被应用于解决许多具有挑战性的决策问题[15-18],利用强化学习算法求解调度问题也成为了研究热点[19]。首先将调度问题转化为马尔可夫决策过程(Markov decision process, MDP),在MDP中状态s描述了车间状态,强化学习智能体(agent)观察状态s,然后采取调度决策a,并从车间环境获得奖励值R,通过与车间环境交互获取调度经验,并以数据驱动的方法学习经验,最大化奖励的同时最优化调度策略[20-21]。GABEL等[22]提出了基于策略梯度(policy gradient, PG)的作业车间调度方法,在状态矩阵中设计了下一道工序预览。王世进等[23]提出基于Q-Learning的单机调度方法,适用于多目标动态切换的调度环境。WANG等[24]将Actor-Critic算法用于晶圆制造系统调度,对多目标采用加权的奖励函数。ZHANG等[25]以工件到达和机器释放事件触发调度,在动作空间中考虑了等待并对奖励函数进行证明。基于强化学习的方法适合解决调度问题,但现有基于强化学习的方法仅根据实时状态进行调度,应用于在线调度问题还需考虑车间的动态变化情况。近年来提出的近端策略优化(proximal policy optimization, PPO)算法是一种基于策略的深度强化学习算法,该算法交互的经验数据可进行重复利用使得采样效率更高,该算法独有的损失函数裁剪使得该算法学习稳定性更强,在交通[26-27]、机器人[28-29]、车间调度[30-31]等智能控制领域得到了实际应用,且明显优于策略梯度(policygradient, PG)[32]、信任区域策略优化(trust region policy optimization, TRPO)[33]、优势动作评论(advantage actor critic, A2C)[34]等深度强化学习算法。因此本文基于PPO算法展开研究,考虑到长短期记忆网络(long short-term memory,LSTM)具有记忆与预测功能,将其引入强化学习智能体以适应在线调度环境。
考虑到加权完工时间和是提升客户满意度和降低库存成本的重要指标,本文针对等效并行机在线调度问题,以最小化加权完工时间和为优化目标,提出基于长短期记忆近端策略优化(proximal policy optimization with long short-term memory,LSTM-PPO)的等效并行机在线调度方法。针对任务在线到达的不确定性,设计了考虑等待策略的在线调度决策流程;针对进行等待所需考虑的全局信息,在强化学习智能体结构中引入LSTM实现时间维的车间状态信息融合,构建高效的LSTM-PPO在线调度算法。
1 问题描述与分析
1.1 问题描述
有n个工件需在m台相同的设备上进行加工,每个工件j有到达时间rj、权重wj和加工时长pj,直到工件到达才已知该工件的所有信息。工件一旦开始加工则无法中断。当一个工件到达后就可进行加工,且一个工件仅能在一台机器上加工一次[14]。因此,本调度问题用三元描述法描述如下:
Pm|rj,online|∑wjCj
(1)
式中,Pm表示等效并行机;online表示在线环境;Cj为工件j的完工时间。
1.2 问题分析
在线环境下有效的等待策略是优化∑wjCj的关键。图1的案例展示了在t1时刻是否等待的两种情形,案例中任务j1和j2的参数如表1所示。t1时刻无等待的调度方案先加工j1再加工j2;t1时刻等待的调度方案则先加工j2再加工j1,因j2的权重较大且加工时间短,j1的加工时间长且权重较小,故有等待的调度方案加权完工时间和比无等待的多45。但由于t1时刻未知j2的到达时间等参数,因而在t1时刻合理的调度决策较困难。在线环境下,有效融合时间维度的任务和机器状态对当前时刻的调度决策有重要意义。

图1 有无等待的调度方法对比

表1 案例中的任务参数
2 基于LSTM-PPO强化学习的等效并行机在线调度系统
在基于强化学习的调度系统中,强化学习智能体通过与车间环境进行交互,感知车间的状态变化并尝试各种调度行为,获取奖励值作为调度决策的评价,通过反复试错以获取更高的奖励值,实现最优的调度策略。基于强化学习的等效并行机调度系统交互流程如图2所示。

图2 基于强化学习的等效并行机调度交互流程
2.1 调度智能体
LSTM-PPO强化学习调度智能体是一种Actor-Critic结构类型的智能体,如图3所示,由3个模块组成,包括记忆与预测模块LSTM,策略模块Actor,评价模块Critic。Actor根据当前的并行机环境进行调度决策,Critic对调度决策的优劣进行评价。策略模块采用前馈神经网络(back propagation neural network,BPNN)逼近最优的调度策略π*,表示为π(a|sk,mk,θ,ψ),其中θ为网络参数,sk为第k次调度时的车间状态,mk为记忆与预测模块提供的时序信息,ψ为LSTM网络参数。评价模块同样采用一个BPNN作为值网络,对真实值函数Vπ(sk)进行逼近,可表示为V(sk,mk,ω,ψ),其中ω为值网络参数。
LSTM记忆与预测模块的输入为每次调度时的环境状态和对应的调度决策,通过编码后输出记忆与预测信息,如图3中LSTM模块所示。记忆与预测模块的运行可表示为

图3 LSTM-PPO智能体结构
mk=LSTM(sak-1,hk-1,ck-1,ψ)
(2)
sak-1=(sk-1,ak-1)
(3)
式中,hk-1和ck-1为k次决策后LSTM网络输出的隐状态;sak-1为k次决策的车间状态sk-1与调度决策ak-1组成的向量。
在功能方面,将输出的记忆与预测信息mk与车间实时状态sk拼接,输入给策略模块和评价模块,使智能体调度时的输入信息更完备,包括实时信息与车间时序动态信息。在网络结构方面,mk作为中间变量将LSTM网络输出层与值网络的输入层、策略网络的输入层相连,使得LSTM网络成为值网络和策略网络共享前缀网络。
将记忆与预测单元对历史调度决策的记忆编码输出作为下次调度的输入,使智能体调度时可对历史调度进行考虑,对前后调度决策之间的相互关联与影响进行表征,实现全局优化。
2.2 调度状态空间
状态空间S的定义与优化目标密切相关,需反映车间调度相关特征和车间状态变化。设定任务缓冲区和等待队列,对不确定数量的任务实现固定数量的参数表征。新任务到达后随机进入空闲缓冲区,避免智能体学习过程中的样本不平衡。若任务缓冲区已满则进入等待队列,按照先入先出原则进入任务缓冲区中待调度。状态矩阵s=[f1f2f3]从缓冲区、任务等待队列、设备3个维度对并行机在线调度环境进行描述,使强化学习智能体对生产状态进行完备的观察。其中缓冲区状态f1=(f1,1,f1,2,…,f1,k,…,f1,q),缓冲区k的状态向量f1,k=(f1,k,1,f1,k,2,f1,k,3,f1,k,4),其中任务等待队列状态f2仅包含等待队列占用率一个参数;机器状态f3=(f3,1,f3,2,…,f3,i,…,f3,m),其中设备i的状态向量f3,i定义为(f3,i,1,f3,i,2,f3,i,3),参数表达式如表2所示。

表2 并行机环境状态参数
综上,设缓冲区数量为nslot,机器数量为m,得到一维等效并行机环境状态矩阵尺寸ns如下:
ns=nslot×4+1+m×3
(4)
2.3 调度动作空间
调度动作空间A即调度决策集合,主要包括以下调度决策:
(1)选择第k个缓冲区。若该缓冲区中存在一个工件j,则将该工件加载到任意一台空闲机器上;若该缓冲区为空,则作用同调度决策(2)。通过选缓冲区间接选择工件,改善了规则选择可能导致的解空间缩小和冗余的问题:
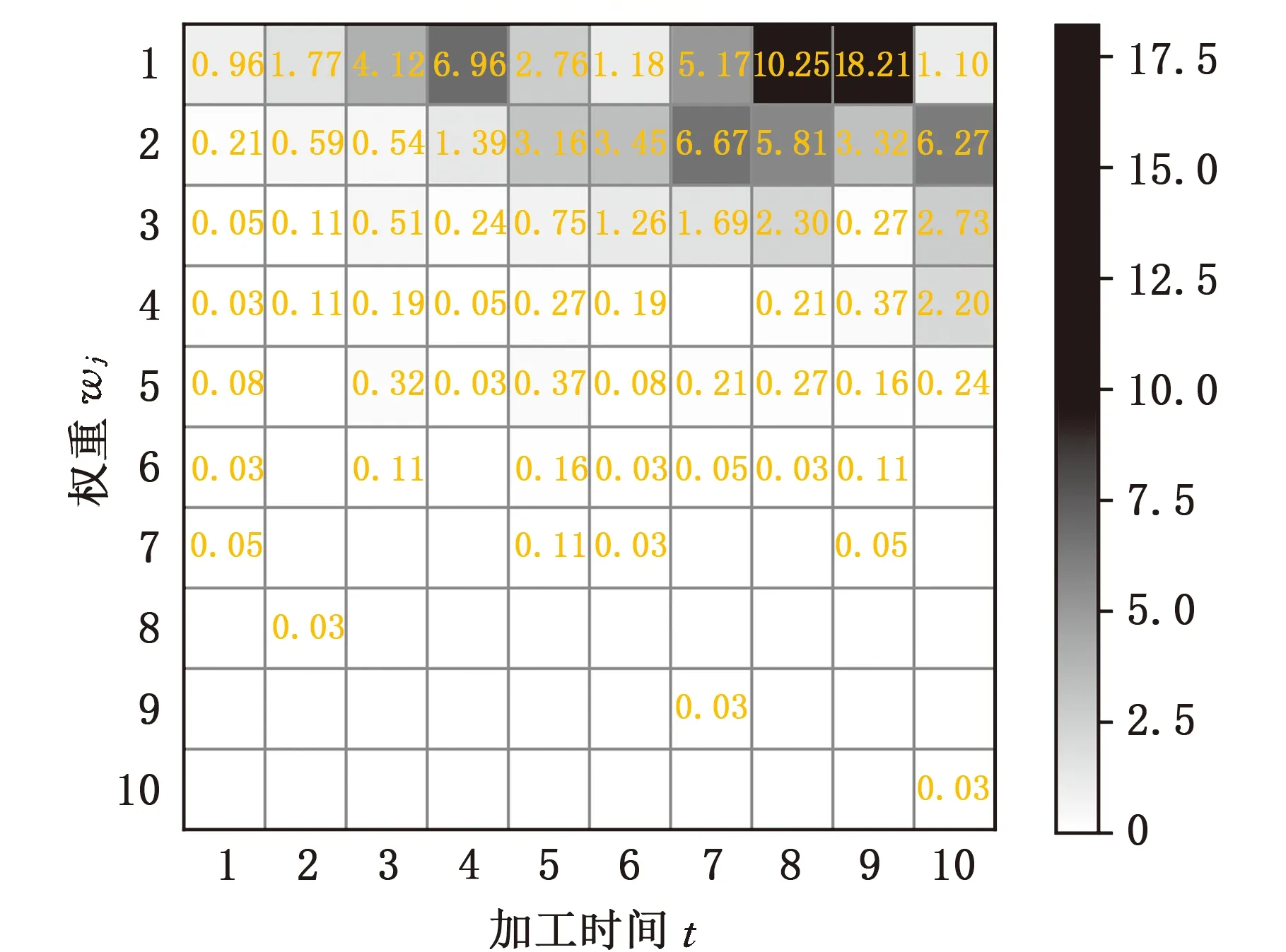
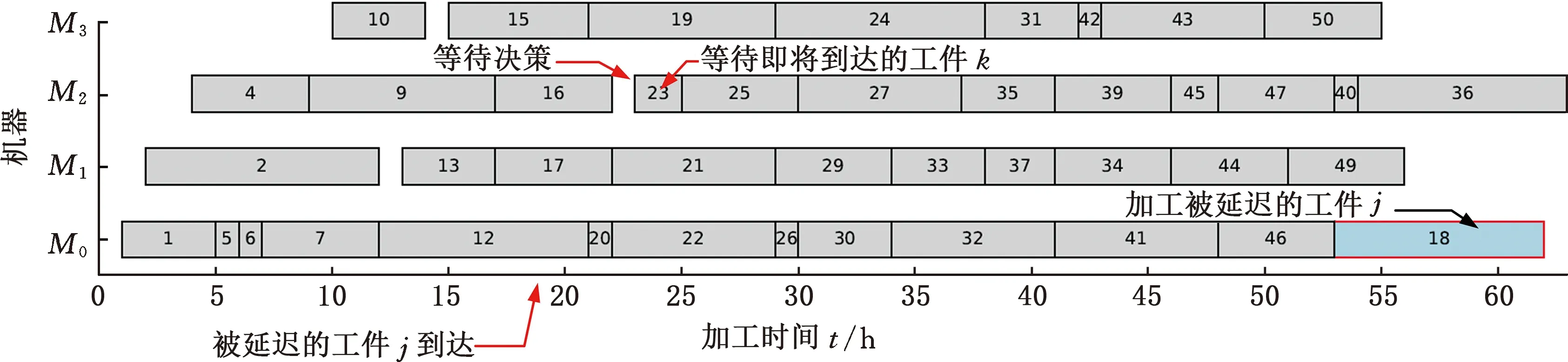
a=k0≤k (5) 式中,q为缓冲区的最大数量。 (2)等待。不选择任何工件进行加工。通过将等待引入到调度的动作空间,使智能体可在调度时选择等待: a=q (6) 强化学习在最大化奖励值R的同时实现目标最优化。奖励函数R对智能体的调度决策对目标函数做出的贡献进行量化评估,为智能体学习调度策略提供有效指导。将目标函数∑wjCj分解,转化为每次调度决策的奖励值,避免奖励稀疏: (7) 因式(7)中到达时间rj与加工时间pj为常量,所有优化目标等效于最小化加权的等待时间和,进一步通过下式分解到每个单位时间: (8) (9) 式中,sj为任务的加工状态参数,判定任务是否处于等待状态。 因此,最小化加权完工时间和实际上等效于最小化每一时间节点的待加工任务数权重之和,据此推论设计奖励函数R如下: (10) 式中,St为t时刻的状态。 对式(10)中的加权等待时间取相反数,因此目标函数∑wjCj越小,奖励值R越大。 强化学习智能体通过与等效并行机在线环境交互获取大量的经验数据(mk,sk,ak,rk),并通过经验数据对智能体的3个模块进行参数更新。采用现有的PPO算法对模型进行更新,此外,因LSTM网络是策略网络和值网络的共同前缀层,因此在模型更新阶段值网络和策略网络的损失均回传至LSTM网络以实现整体网络优化,并通过下式对值网络参数θ、ψ进行更新: θ←θ+αθJ(θ,ψ) (11) ψ←ψ+αθJ(θ,ψ) (12) 通过下式对值网络参数ω、ψ进行更新: ω←ω-αωL(ω,ψ) (13) ψ←ψ-αωL(ω,ψ) (14) 因此,值网络和策略网络更新时,梯度均回传至LSTM网络并更新其参数ψ,如图3中损失传播路线所示。综上得到基于LSTM-PPO的等效并行机在线调度算法: 1: 随机初始化智能体参数θ,ω,ψ 2: for each episode do: 3:k=0 4: 初始化任务序列、记忆与预测信息mk、经验缓存池和状态sk 5: while not done ork≤Kdo: 6: 根据策略π采取调度决策ak~π(a|sk,mk,θ,ψ) 7:sk+1,rk,done←Env(sk,ak) 8: 刷新LSTM信息mk+1=LSTM(sak,hk,ck,ψ) 9: 将经验[sk,mk,ak,rk]保存至经验缓存池 10:k←k+1 11: 更新并行机环境状态s←s′ 12: end while 13: 计算折扣奖励 14: if缓冲区经验数目>小批量数目Mdo: 15: forepoch=1,2,…,Ndo: 17: 更新策略网络和LSTM(θ,ψ)←(θ,ψ)+αθJ(θ,ψ) 18: 更新值网络和LSTM(ω,ψ)←(ω,ψ)-αωL(ω,ψ) 19: end for 20:θold,wold,ψold←θ,w,ψ 21: end if 22: end for 使用Pycharm软件进行编程,在Windows10操作系统、2.9 GHz CPU、16G内存的计算机和Python3.5环境下运行。以面向对象的形式搭建了并行机环境类,包括机器类、工件类等,并用Pytorch实现了智能体的模型搭建。 在仿真算例实验中,采用与文献[14]相同的算例生成方法:设工件的到达规律服从泊松分布,且每个工件有不同的权重wj和不同的加工时间pj,wj~U(1,pmax),pj~U(1,pmax),pmax为工件的最长加工时间。为验证本方法的泛化能力,随机生成了100个算例作为训练集,30个算例作为测试集,测试集仅用于对比各方法的性能,不作为训练过程的问题输入。在实验中,取机器的数量m=4,最长加工时间pmax=10,泊松分布参数λ=0.4,每个算例的模拟调度时间为200 h。 在模型训练开始之前,本文算法的参数主要根据经验值以及智能体交互过程的实际数据情况进行设置。首先,LSTM-PPO强化学习智能体的Actor网络和Critic网络均为BP神经网络,隐含层的神经元个数设置为100,LSTM单元的隐层神经元个数设置为32,LSTM输出的消息长度为8,取Actor网络的学习率α1=0.001,Critic网络的学习率α2=0.002,累积折扣因子γ=0.9,损失裁剪参数ε=0.2,为加快收敛速度,采用Adam算法[35]对网络参数进行更新。缓冲区的数量是本算法最关键的参数,数量过多会导致网络复杂,同样任务到达情况下空闲的缓冲区多,智能体选中任务的难度更高,学习更慢;缓冲区过少则导致缓冲区长时间饱和,可能造成优先级高的工件无法及时进入缓冲区。通过监控交互过程中的缓冲区和等待队列的情况,设置缓冲区数量nslot=20,等待队列最大容量为10,时间窗口设置为1 h。在每次迭代中,强化学习智能体在每个训练集算例上重复8次独立实验。 图4a展示了LSTM-PPO方法的训练迭代过程。在迭代次数为0时,由于强化学习智能体中网络参数均初始化为随机数,故LSTM-PPO方法与随机调度非常接近,而随着迭代次数的增加,本文方法获得的奖励函数值逐渐超越现有的几种启发式算法。启发式算法和随机调度因不具学习能力,故奖励值和目标函数值均不随迭代次数发生变化。通过与环境的交互获取经验并学习,可见LSTM-PPO智能体可快速学习如何调度以获取更高的奖励值。同时,图4b表明在训练集上的加权完工时间和也在相应地减小,验证了所设计的奖励函数指导优化智能体优化目标函数的有效性,直至迭代7000次已基本收敛,且在这些训练集上训练迭代7000次时,强化学习智能体的平均水平已优于现有的几种启发式算法。 (a)训练过程累积折扣奖励 将训练后的LSTM-PPO模型进行保存,在测试集上与改进前的PPO算法、现有启发式算法进行对比,仿真的测试集包括30个算例,智能体在学习过程中未学习过这些测试算例。首先将本文提出的LSTM-PPO算法与现有的PPO算法进行对比以验证融入LSTM的有效性,如表3中的前两列所示,在相同训练次数与迭代条件下,LSTM-PPO算法优于未改进的PPO算法,融入的LSTM网络能结合过去的历史状态和历史调度进行预测,并将预测的消息片段辅助智能体进行调度。 将经过训练后的强化学习智能体与现有的3种启发式算法进行对比。D-WSPT和AD-WSPT为两种改进的WSPT规则,可根据当前时间和任务权重以及加工时间判定是否等待。训练结束后最终测试结果的均值和方差见表3,LSTM-PPO方法的均值和方差最优;除本文方法外,性能最好的是WSPT规则,D-WSPT规则和AD-WSPT规则的等待策略对具有不确定性的在线调度环境缺乏自适应性。 表3 不同方法的时间对比 对本文方法在调度过程中的等待决策进行分析。若存在机器空闲且有待加工工件,调度决策为等待,则这些待加工工件定义为被延迟。记录所有的等待决策,分析工件被延迟的频率。如图5所示,每个方块中的数值表示该权重和加工时间的工件被延迟的频率。由图可知,加工时间越长且权重越小的工件被延迟的频率越高,这是智能体从数据中学习的等待策略。工件延迟加工,若短时间内到达加工时间更短或权重更大的工件即可减小加权完工时间和∑wjCj。图5表明权重大且加工时间短的任务会有更高的加工优先级,极少被延迟加工,若可加工任务均权重较小且加工时间较长,则被延迟加工的概率较高。智能体学习到的策略是一种提升的WSPT规则,调度输入的是更全面的车间状态矩阵和时序动态信息,通过神经网络梯度下降进行策略学习,得到了通过合理等待实现目标优化的调度策略。 图5 不同权重和加工时长的工件被延迟的频率 将本文提出的算法应用于某航天机加车间的真实调度算例。该车间有4台设备,43个历史加工任务,各工件的加工时间等相关参数见表4。利用不同算法对算例进行在线调度,调度结果绘制成甘特图,如图6所示,每个方块表示一个工件,方块内的数字表示工件的到达时间,被延迟的工件用蓝色标出。由图6可知,LSTM-PPO方法的等待决策发生在机器2空闲时,智能体选择等待即将到达的较短加工时间的工件k,而工件j被延迟加工。由于工件j的加工时间较长,故延迟该工件j的加工而等待工件k有效降低了目标函数值。由甘特图可知,WSPT规则无法等待,D-WSPT规则与AD-WSPT规则的等待触发条件均与当前时刻相关,使得等待决策发生在调度起始的一段时间内,本文方法的在线环境自适应性更强。 (a)LSTM-PPO,∑wjCj=8911 表4 实际历史任务的工件参数 (1)本文针对等效并行机在线调度问题,以最小化加权完工时间和为目标,对任务在线到达的特性和决策等待的难点进行了分析,提出考虑等待的在线调度策略。 (2)针对任务到达的动态性设计了带时序信息融合的LSTM-PPO强化学习智能体,并定义了调度的状态空间、动作空间和奖励函数,成功将LSTM-PPO调度决策智能体应用于等效并行机在线调度问题。 (3)智能体观察车间的实时状态和动态信息进行调度,通过调度交互获取经验并通过梯度下降法更新策略实现最小化加权完工时间和,训练得到的最优调度策略存储在神经网络,调度决策速度快。 (4)实验结果表明,所得模型的调度结果优于3种启发式算法。对调度策略中的工件延迟加工频率分布和甘特图进行分析,证明本文提出的方法通过自学习得到在线环境下自适应等待的调度策略,对动态环境下的生产调度策略探索具有一定参考价值。 在大规模问题中,设计的缓冲区数量决定了输出神经元的个数,随着问题规模的增大,需要的输出神经元数量增大,可能导致网络难以训练。下一步将寻求一种更为弹性的方法以代替缓冲区,且能解决规则选择方法过于压缩解空间的问题。进一步对问题进行深入研究,考虑在线的并行批处理机调度问题,研究如何实现多智能体协作机制,并实现在晶圆制造、航天制造等领域的实际应用。2.4 调度奖励函数
2.5 模型更新
3 实验验证
3.1 模型训练

3.2 仿真算例验证

3.3 调度策略分析
3.4 企业算例验证

4 结论
猜你喜欢
北京工业职业技术学院学报(2024年1期)2024-01-14 06:35:14
铁道通信信号(2020年10期)2020-02-07 01:01:32
成都信息工程大学学报(2019年3期)2019-09-25 08:31:10
制造技术与机床(2019年7期)2019-07-22 03:42:06
三门峡职业技术学院学报(2019年1期)2019-06-27 07:32:58
现代机械(2018年1期)2018-04-17 07:29:48
焊接(2015年9期)2015-07-18 11:03:52
项目管理技术(2015年3期)2015-04-23 08:44:29
组合机床与自动化加工技术(2014年12期)2014-03-01 02:22:54
深圳信息职业技术学院学报(2013年3期)2013-08-22 11:42:34
