
Multimodal Emotion Recognition Based on Facial Expression and ECG Signal
2022-02-28 09:37,,,
包装工程 2022年4期
,, ,
(1.School of Mechanical Engineering, University of Science and Technology Beijing, Beijing 100083, China;2.China Astronaut Research and Training Center Beijing, Beijing 404023, China)
ABSTRACT: As a key link in human-computer interaction, emotion recognition can enable robots to correctly perceive user emotions and provide dynamic and adjustable services according to the emotional needs of different users, which is the key to improve the cognitive level of robot service. Emotion recognition based on facial expression and electrocardiogram has numerous industrial applications. First, three-dimensional convolutional neural network deep learning architecture is utilized to extract the spatial and temporal features from facial expression video data and electrocardiogram(ECG) data, and emotion classification is carried out. Then two modalities are fused in the data level and the decision level, respectively, and the emotion recognition results are then given. Finally, the emotion recognition results of single-modality and multi-modality are compared and analyzed. Through the comparative analysis of the experimental results of single-modality and multi-modality under the two fusion methods, it is concluded that the accuracy rate of multi-modal emotion recognition is greatly improved compared with that of single-modal emotion recognition, and decision-level fusion is easier to operate and more effective than data-level fusion.
KEY WORDS: multi-modal emotion recognition; facial expression; ECG signal; three-dimensional convolutional neural network
In the process of human-robot interaction, people are no longer satisfied with the robot can only passively accept the command and control, and expect it to actively understand the user’s emotion and intention.Emotion recognition is to give the machine the ability to recognize the user’s emotion. On this basis, the machine can give the corresponding response and possesses the ability of thinking. Emotion recognition is an important branch of human-robot interaction, which can be applied in various fields such as transportation, service,medical treatment, helping the elderly and disabled.
As an internal subjective experience, how emotion can be accurately and effectively recognized is the fundamental problem in the research of emotion recognition. At present, emotion recognition methods mainly include facial expression recognition, speech signal recognition, human posture recognition and physiological signal recognition[1]. Emotion recognition technology based on facial expression and electrocardiogram has been widely used in medicine, entertainment,education and other fields, and there are quite a number of application systems and products based on emotion recognition function. Social psychology believes that facial expression is more intuitive and plays an important role in emotion recognition, while neuroscience believes that physiological signals are mainly controlled by human autonomic nervous system and endocrine system, which is not easy to be controlled by personal subjective consciousness, and can reflect individual emotional state more truly[2]. Therefore, more and more researchers pay attention to emotion recognition based on multi-modality.
This paper proposes a new method for multi-modal emotion recognition based on facial expressions and ECG signals. The organization of the paper is as follows. In section 2, the previous related work is discussed. In section 3, we briefly introduce the database used in the experiment. In section 4, we present the feature extraction and fusion method of facial expression and ECG signal. In section 5, we present the facial expression recognition results, ECG signal recognition results and multi-modal emotion recognition results. In section 6, the paper concludes with a brief discussion of the results and future work.
1 Related Works
1.1 Emotion Recogni tion B ased on Facial Expressions
Facial expression is directly related to people’s emotional state, and has been proved to be an important information source of emotional state. Since around 2012, deep learning has developed rapidly in the whole field of machine vision, and the “deep” era of face recognition has officially begun[3]. Deep learning provides an “end-to-end” learning method. The whole learning process does not need artificial sub problem division,but is completely handed over to the deep learning model to directly learn the mapping from the original data to the desired output. In recent years, convolutional neural network is generally used in image detection and recognition tasks. In this case, two-dimensional convolutional neural network is used to extract features from spatial dimensions. However, this method can not deal with the dynamic expression features in video sequences, which often contain very important information. Therefore, more and more expression recognition methods based on video sequences are proposed. He et al.[4]proposed an expression recognition method based on 3DCNN-DAP, in which DAP refers to variable action units. The 3D convolutional neural network is used to extract the spatial and temporal features of facial expressions. Jaiswal et al.[5]combined convolutional neural network and bi-directional long short term memory network for the first time, and achieved better results than the 2015 Fera champion algorithm. Farhoudi et al.[6]applied 3D-CNN and CNN-RNN to audio-visual emotion recognition, and the results show that the performance of this method in video emotion recognition is superior to manual features and other advanced information fusion models.
Einstein robot[7], which made its debut at the Conference of “Technology, Entertainment and Design” in the United States in February 2009, can be regarded as a masterpiece in the field of robot humanoid face. It was designed by David Hanson, the chief designer of Hanson Robotics Company in the United States. It can recognize human expressions based on training and learning from a million images of facial expressions. Besides, it can understand expressions such as anger, sadness and confusion, and realize simple movements such as simulated human nodding.
Sarala et al.[8]proposed a driver-assisted emotion recognition system. The system utilized the images of facial expressions as input, and transformed the sound of the driver assistance system according to the current emotional state of the recognized driver. In the event of detecting negative emotions, the system changed the sound to raise the driver’s alertness.
1.2 Emotion Recognition Based on ECG Signals
In the research of emotion recognition based on ECG signals, the multimedia emotion computing research team led by Professor Picard of Massachusetts Institute of Technology (MIT) first used physiological signals as the data source of emotion recognition, and verified the feasibility of emotion recognition through physiological signals through experiments[9]. Kim K H et al.[10]collected three physiological signals of galvanic skin response (GSR), ECG and skin temperature (SKT),extracted several emotional physiological features, and finally used support vector machine classifier to classify and identify four different emotions, with an average classification accuracy of 61.8%. Emotion recognition of physiological signals has been extended from the traditional single physiological signal recognition to multi-modal physiological signal recognition. Panahi et al.[11]explored the validity of ECG and GSR signals in emotion recognition accuracy through Fractional Fourier Transform (FrFT) method, and the results showed that with ECG and GSR signals, the phase information of FrFT coefficient achieved significant effect in emotion recognition.
AIZoubi et al.[12]developed AutoTutor system (an intelligent tutoring system with dialogue function) to induce non-basic emotional states in natural emotional states (such as boredom, happiness, doubt, curiosity and concentration), collected signals such as electromyogram (EMG) and ECG, and then conducted feature processing. The results show that the user-independent model is not feasible, but the accuracy rate based on the user-dependent model is medium, which proves that it is feasible to identify the natural emotional states induced by the AutoTutor system based on physiological signal classification. Katsis et al.[13]established an integrated telemedicine platform named AUBADE, which is used to assess individuals’ physio-affective state. Five predefined emotional categories (high stress, low stress,disappointed, happy and neutral state) were evaluated by using features extracted from EMG, respiration(RESP), GSR and ECG signals. The classification accuracy of emotion was 86.0%. The system is designed for the use of subjects working under extreme stress conditions, particularly race car drivers, as well as patients with neurological and psychological disorders.
1.3 Emotion Recognition Based on Multi-Modality
With the deepening of single-modal emotion recognition research, scholars at home and abroad began to try the related research work of multi-modal emotion recognition, and through a large number of experimental studies, it is proved that using the complementarities of multi-modality information can improve the recognition rate of emotion recognition model. Multimodal information fusion technology can be divided into three categories: data-level fusion, feature-level fusion and decision-level fusion. Salama et al.[14]proposed multimodal emotion recognition based on facial expression and EEG signal. Firstly, 3D-CNN deep learning architecture is used to extract and classify facial expressions and EEG signals, and then the recognition results are obtained by fusing information from the data level and the decision level respectively. Finally, the experimental results show that the recognition accuracy is higher after information fusion, and the recognition result of decision-level fusion is better than that of data-level fusion. Valentina Chaparro et al.[15]proposed a multimodal emotion recognition model based on visual signals and physiological signals. At the feature level, the facial expression feature and the ECG signal feature are connected in series to form a multi-modal feature, and experiments have proved that the recognition rate of the multi-modal feature is higher than that of the single modality.
2 Database
The establishment and use of a real and reliable emotion database is the basis of emotion recognition research. This section will introduce the selection and establishment process of the database for emotion recognition research.
2.1 MAHNOB-HCI Database
The MAHNOB-HCI multi-modality emotion database was collected by the University of Geneva (http://mahnob-db.eu/hci-tagging/). The experiment recruited 30 subjects, including 13 males and 17 females, aged between 19 and 40 years old (M=26.06,SD=4.39). In addition, they have different ethnic and educational backgrounds, and they have a wide coverage. The experiment used 20 video clips as stimulus materials to induce 9 emotions including sadness, happiness, disgust, neutral, pleasure, anger, fear, surprise and anxiety.And we collected peripheral/central nervous system physiological signal data, facial video data, audio data and eye movement data under each emotion. MAHNOBHCI database data information is shown in Table 1. This paper mainly uses facial video data and ECG signals.The following focuses on these two aspects.
In the experiment, six different cameras were used to simultaneously record facial expressions, including one color camera and five monochrome cameras. The screen resolution is 780 px×580 px, and the screen smoothness is 60 frames per second. The two cameras above the monitor respectively recorded color and monochrome video of a near-frontal view of the subject’s face. In the research of this paper, the near-frontal facial video recorded by a color camera is selected as the research object of facial expression recognition. The collection of physiological signals uses the Biosemi active II system with active electrodes. A total of threechannel ECG signals were collected in the experiment,and the collection locations were located at the upper right corner of the chest under the clavicle (channel 33),the upper left corner of the chest under the clavicle(channel 34) and the left abdomen (channel 35). This paper chooses the 34th channel ECG data as the research object of emotion recognition based on ECG signal.

Tab.1 MAHNOB-HCI database data information
Due to technical problems and physical conditions of the subjects, only 24 subjects had complete data.There are 3 subjects lacking some samples of facial video data and physiological signal data, and one of them lacks a lot of data from the sample, which is not selected in this study. In addition, the data of 3 subjects were completely unavailable. Finally, a total of 513 sets of data are available. This paper selects samples with four labels of disgust, happiness, neutral, and sadness as the experimental data for emotion classification and recognition research. The sample sizes are 52, 82, 109,and 64 respectively.
2.2 Multi-mo dal Emotion Database
We adopted a video-induced method to build a multi-modal emotion database containing facial expressions and ECG signals. Emotion inducing materials are shown in Table 2.
2.2.1 Setting of Experimental Environment
As the expression of emotion is easily affected by the external environment, we chose a conference room with good sound insulation effect as the experimental site. Data acquisition experimental environment is shown in Figure 1, the height of the table in the conference room is 700 mm, the height of the chair is 400 mm, and the distance between the display and the subjects is 650 mm. In addition, the indoor light is sufficient, which is conducive to the collection of facial expression video.
2.2.2 Selection of Experimental Equipment
The collection of facial expression videos and ECG signals requires cameras and ECG recorders, respectively. The camera model selected in this paper is Logitech C310, the screen resolution is 1280×720, and the fluency is 30 frames per second. The ECG recorder equipment is a good friend single-lead Holter recorder,which can record 30s static ECG data and 7×24 hours Holter data, and can be played back through a computer.In the experiment, a Xiaomi notebook computer wasused to play emotion-inducing videos. The computer screen size is 15.6 inches, the resolution is 1920×1080,and the video playback picture is clear. The computer model used for facial expression video recording in the experiment is HP ZHAN 99, the operating system is Windows 10, 64-bit system, the screen size is 15.6 inches, and the resolution is 1920×1080.

Tab.2 Emotion inducing materials

Fig.1 Data acquisition experimental environment
2.2.3 Experimental Procedure
In this experiment, a total of 30 subjects’ facial expression data and ECG signal data were collected,including 17 males and 13 females. The age of the subjects is between 22 and 26 (M=24.00,MD=1.05). Before the experiment started, the subjects first needed to read the informed consent form. After understanding the experiment purpose, experiment procedure, precautions and confidentiality of personal information, the informed consent was signed. Then the subjects needed to fill out a questionnaire, which was mainly used to determine whether the subject’s current physical condition has an impact on the experiment. After confirming that the subjects can participate in the experiment, the tester put on the subjects’ ECG equipment. After attaching the ECG patch, the subjects were calmed down for 5 minutes and then the first emotional induction video was played. A 5-minute period of classical music was interspersed between every two emotion-inducing videos to calm the subjects’ emotions, so as not to affect the next stage of emotion induction. After each emotion-inducing video during the period ends, the subjects needed to press the button on the ECG device to mark, and then turn off the ECG device to generate a separate file for each emotion.
3 Methods
The main purpose of this paper is to study the effectiveness of deep learning method and multi-modal information fusion technology in emotion recognition.This study is mainly divided into three stages: In the first stage, three-dimensional convolutional neural network is used to learn and classify the emotional features of facial video; in the second stage, three-dimensional convolutional neural network is used to classify the emotional features of ECG signals; in the third stage,facial expression and ECG signals are integrated at different levels to classify and recognize emotions.
The 3D convolutional neural network architecture adds time dimension to the traditional neural network architecture, which can capture both spatial and temporal features.
The three-dimensional convolutional neural network architecture is composed of five convolution layers, five maximum pooling layers, two full connection layers and softmax layers. The number of convolution cores of the five convolution layers are 32, 64, 128, 128 and 256, respectively. Simonyan et al.[16]pointed out that the kernel size of 3×3 is better than that of 5×5 or 7×7 in deep convolutional neural network. Therefore,the size of 3D kernel used in this paper is 3×3×3, and the step size in space and time dimension is 1. The output of each convolutional layer is activated using the ReLU function. In order to retain time information in the early stage, the size and step size of the first pooling layer are set to 1×2×2, and the size and step size of the other 4 pooling layers are all 2×2×2. After multi-layer convolution and pooling, it is output through two fully-connected layers, and finally through the Softmax layer and optimized with cross entropy as the goal.
3.1 Faci al Expression Analysis
The construction of facial expression recognition model is mainly composed of three steps: image data preprocessing, facial expression classifier selection, and facial expression feature learning.
To build the facial expression recognition model in this paper, the input data for training model parameters should be selected first. Because it takes a process for video clips to induce emotion, in order to avoid invalid data, improve model accuracy and reduce unnecessary training time, and to avoid the influence of equipment startup and other factors in the initial stage of acquisition, the data of the first 30 seconds of each video segment will be removed. In addition, to ensure that the number of frames input to the network is consistent, and the length of the video collected is about 2 minutes, we cut the facial expression video into 1 minute segments from 30 seconds to 1 minute 30 seconds. Then one frame per second is extracted to form a 60 frame image sequence as the input of the model.
Then the input image sequence is preprocessed,including face clipping and normalization. Face detection is to determine whether there is a face in an image.If there is a face, the position of the face is located. In this paper, Haar classifier is used to detect the face in the image and form the face sequence of the corresponding image. Image de-averaging refers to subtracting the average image from any image input to the neural network in order to make the input centered on 0.Each pixel in the average image is calculated by the corresponding pixels (i.e. the same coordinates) in all images in the data set.
Then Softmax classifier is selected as the classifier of facial expression recognition. In facial expression recognition model, feature learning and expression classification are two major steps at the same time. Because the deep neural network needs to learn and improve the parameters of the neural network automatically according to the results of the classifier and the loss function, we need to select a suitable classifier for the model.
3.2 E CG-based Emotion Analysis
In the traditional feature extraction process of ECG signals, there are some problems such as the loss of feature information and the inability to explore potential features. Convolutional neural network can automatically extract the implicit and effective emotional features from ECG signals. Therefore, based on the time-frequency characteristics of ECG signals, this paper proposes a method of feature learning and classification of ECG signals using three-dimensional convolutional neural network.
Firstly, we use wavelet threshold denoising method to denoise ECG signal in MAHNOB-HCI database.Because the ECG data collected by ECG equipment is uploaded to the backend of the system and denoised,this paper can only get the ECG waveform, but not the original ECG data. ECG signal collected by a good friend’s electrocardiograph is shown in Figure 2. In order to correspond with the sampling frequency of ECG signal in MAHNOB-HCI database, and facilitate the corresponding processing of two parts of ECG signal at the same time in the later stage, this paper obtains the ECG data of 256 points with equal interval from the ECG waveform per second.
On this basis, the ECG data in the two databases are processed at the same time. As the same processing method of facial expression video, this paper removes the first 30s data of continuous ECG signal, and from the 31s, the continuous 60s ECG data is the experimental data for emotion recognition research in this paper.Then 60s of ECG data are cut into a small segment every second, and then superimposed to form a sequence of 60 consecutive frames in the time dimension,which is one-to-one corresponding to the frame sequence of facial expression video in time dimension. In addition, in order to adapt the ECG signal to different sampling frequencies, this paper resampled the ECG signal, and obtained ECG data with frequencies of 512Hz and 1024Hz using cubic spline interpolation.The ECG data under the three frequencies are set as a group of 64 numbers, and the data does not overlap each other, and 4, 8, 16 groups of ECG data can be obtained, respectively. In the process of sub-sampling, it is easy to cause problems of missing data association and missing emotional key points. For this reason, this paper takes the ECG data segment with a length of 64 at each segment with the segment node as the center, and obtains 3, 7, 15 groups of ECG data at three sampling frequencies. Then, this paper randomly collected 11 sets of 64-length ECG data from the original frequency ECG signal. The arrays collected above are spliced, and each frame of ECG signal data is sorted into a 64×64 tensor.Considering the duration of the ECG signal (60 frames),the input data of the ECG signal required by the three-dimensional convolutional neural network can be obtained.
3.3 Fusi on
In the research of this paper, the facial expression and ECG signal modalities are fused in the data level and the decision level and related experimental analysis is performed.
In the process of data-level fusion, this paper uses the migration learning strategy to replace the initial weight of the network with the weight of the trained facial expression recognition network, giving the network a higher starting point. In the fusion process at the decision level, considering the differences in the performance of different emotion recognition by different modalities, this paper uses a weighted fusion strategy to give different modalities different weights[17].
3.3.1 Data-level Fusion
In the process of data fusion, this paper combines the face module and the ECG module to form a fusion block as the input of the network. The processing method in this paper is to superimpose each second of the face frame and the ECG signal frame, and then combine the consecutive frames in the same way. Thus, a fusion module with a width of 64, a height of 128, and a depth of 60 is created, and the fusion module is used as the input of the network. The schematic diagram of data-level fusion method is shown in Figure 3.
3.3.2 Decision-level Fusion
This paper adopts a weighted decision fusion strategy to improve the recognition effect by using the complementarities between multiple modalities. Firstly,two sub-classifiers are constructed based on facial expressions and physiological signals, and the recognition results of the two sub-classifiers for 4 different emotional states are obtained. Then, for the classification results of the two modalities, the final recognition results are obtained through weighted voting, and the schematic diagram of the weighted decision fusion process is shown in Figure 4.

Fig.2 ECG signal collected by a good friend’s electrocardiograph
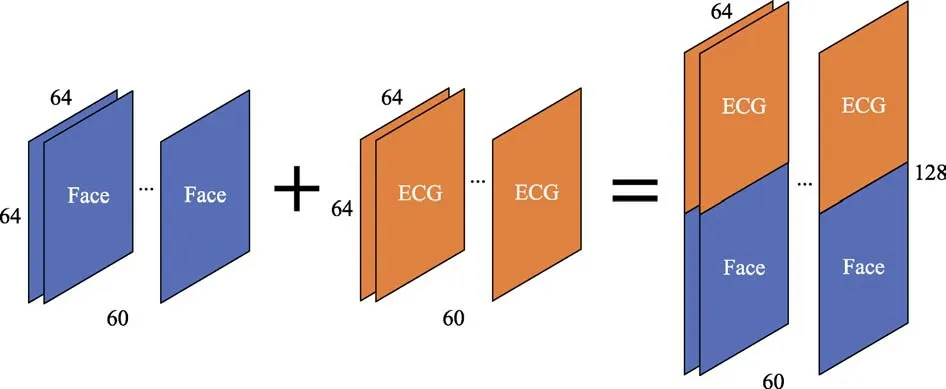
Fig.3 Schematic diagram of data-level fusion method
The calculation steps are as follows:
1) Train and test the sub-classifier based on a certain mono-modality separately, and get the recognition rate of each modality for 4 different emotional states:
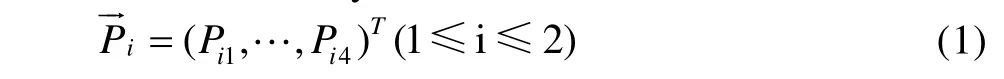
Then, the weighting matrix of each modality according to the recognition rate is:
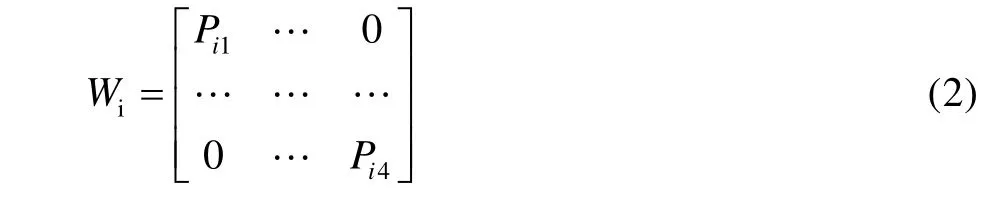
Among them,iWis the weighting matrix of the i-th modality.
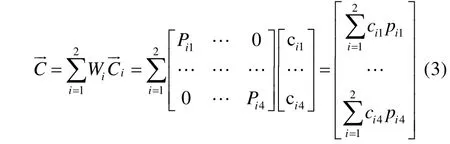
3) The k-th emotional state with the highest score is the final recognition result:

4 Experiments
This paper collects a total of 307 facial expression video samples from the MAHNOB-HCI database.Among them, the number of samples of disgust, happiness, neutral and sadness are 52, 82, 109 and 64, respectively. In addition, this paper also collects 30 facial expression videos of each of the four emotions of disgust, happiness, neutral and sadness. We combine the two groups of samples according to different emotion types. At this time, the numbers of the four samples of disgust, happiness, neutral and sadness are 82, 112, 139 and 94, respectively. This paper adopts the method of random sampling to divide the data set into 80% training set and 20% test set according to different emotion types.
After dividing the training set and the test set, we extract one frame per second from the 31st second of each emotional video, extract 60 frames from each video as the input of the model, and adjust each frame of the face after cropping to 64×64 grayscale image.Since we cannot know exactly at which moment the subjects produced the corresponding emotion, this paper will not divide each video into smaller segments. In order to prevent certain segments that do not contain emotional responses from being labeled as the original emotional video, the network will learn wrong features.In addition, in the process of training, the part of training set is verified by nine-fold cross validation. The data corresponding to each emotion is randomly divided into nine parts, one of which is used as verification set to test the performance of the network trained in each cycle, and the remaining eight are the training set. This step is repeated for each training round of model, and the final result is the average of each test result.
In this paper, Keras framework is used to build a three-dimensional convolutional neural network[18]. The number of batch samples is set as 16, the initial learning rate is 0.001, and the training cycle is 80. In the training process, the weight of the neural network is updated iteratively by using Adam optimization algorithm[19].
4.1 Faci al Expression Recognition
The accuracy and the loss of the training set and validation set with respect to the number of iterations(facial expression) are shown in Figure 5. The network achieved 86% accuracy on the training set and 74%accuracy on the validation set.
After the network training is completed, we test it on the test set of the facial expression module. Finally,the confusion matrix of the recognition result of the test set (facial expression) is shown in Figure 6.
In the confusion matrix, the abscissa represents the prediction result, the ordinate represents the real label,and the value on the diagonal is the probability that each emotion state is correctly identified. Finally, the average recognition accuracy of the trained network on the test set of facial expression module is 72.25%. In addition, the network has the highest recognition accuracy of neutral at 80%. Happiness is the next most accurate at 75%. Sadness is the least accurate at 65%.
4.2 ECG-ba sed Emotion Recognition
The accuracy and the loss of the training set and verification set with respect to the number of iterations(ECG signal) are shown in Figure 7. The recognition accuracy of the network on the training set reaches 79%, while the recognition accuracy on the verification set stays at about 65%.

Fig.4 Schematic diagram of the weighted decision fusion process
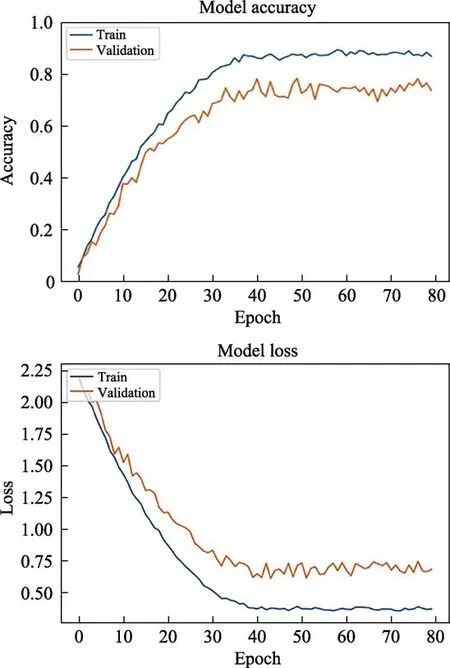
Fig.5 Accuracy and loss of training set and validation set with respect to the number of iterations (facial expression)
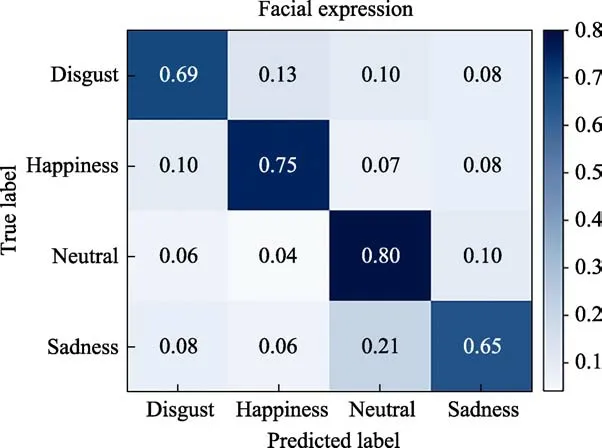
Fig.6 Confusion matrix of the recognition result of the test set (facial expression)
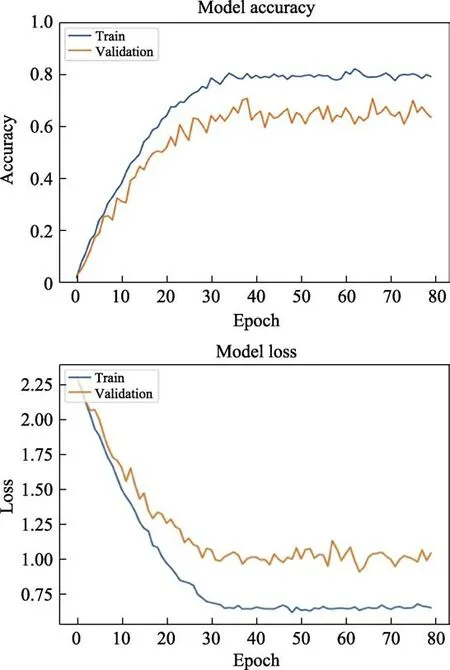
Fig.7 Accuracy and loss of training set and verification set with respect to the number of iterations (ECG signal)
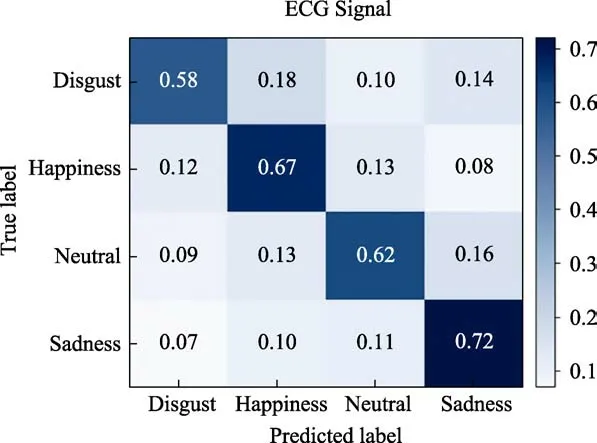
Fig.8 Test set identification result confusion matrix (ECG signal)
Test set identification result confusion matrix(ECG signal) is shown in Figure 8.
According to the confusion matrix, the average recognition accuracy of the trained network on the ECG module test set is 64.75%. In addition, we can also find that the network after training has the highest recognition accuracy of 72%, which is higher than that of facial expression modality. The recognition accuracy of disgust is only 58%.
4.3 Multi-mo dal Emotion Recognition
4.3.1 Data-level Fusion
We need to give the initial weights before the network training. In the deep learning technology, one of the most effective strategies is to replace the initial weights with the weights of the pre-trained models, so as to make full use of the information learned by the pre-trained models instead of training them from scratch. This strategy is called transfer learning, which can not only save the training time, but also achieve better recognition effect[20]. In this paper, the initial weight of the model training is replaced by the weight of facial expression recognition model. The accuracy and loss of the training set and the verification set with respect to the number of iterations (data fusion) are shown in Figure 9.
As can be seen from Figure 9, the performance of the network tends to be stable after 39 iterations. Finally, the network achieves 92% accuracy on the training set and 80% on the verification set. In addition, we can find that this training has a higher starting point. At the beginning of training, the accuracy of the network is close to 40%. This is due to the application of transfer learning strategy in this paper. The information learned from facial expression module is transferred to the training.
After the network training is completed, we test it on the test set. Finally, confusion matrix of test set identification results (data fusion) is shown in Figure 10.
It can be seen from the confusion matrix that after data fusion, the average recognition accuracy of the network on the test set reaches 80.5%, which is 8.25%higher than that of single-modality facial expression recognition, and 15.75% higher than that of singlemodality ECG emotion recognition. The trained network has the highest recognition accuracy of 87%. The accuracy rate of sadness recognition is the lowest, which is 75%, but it is also improved compared with single modality.
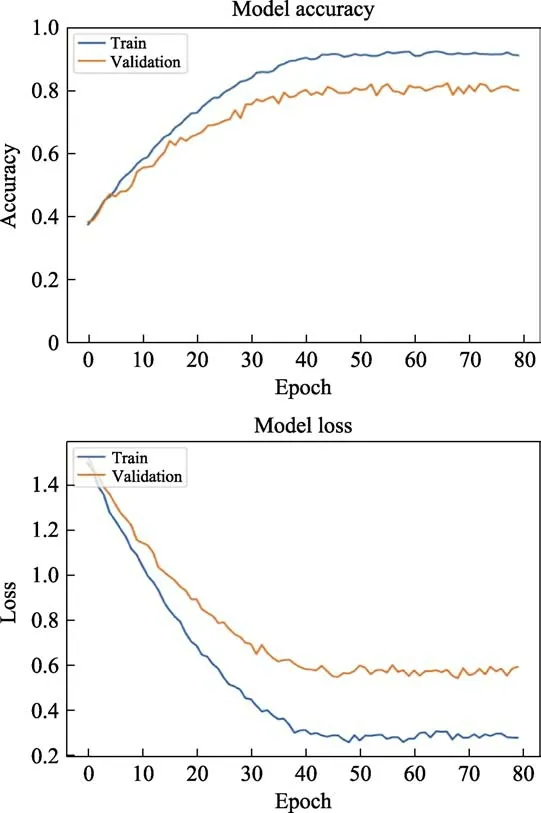
Fig.9 Accuracy and loss of training set and verification set with respect to the number of iterations (data fusion)
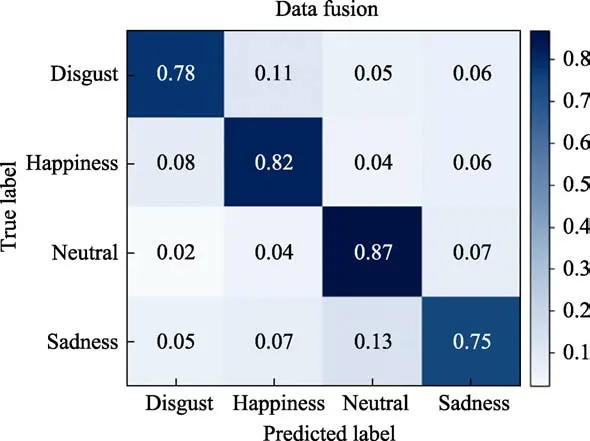
Fig.10 Confusion matrix of test set identification results (data fusion)
4.3.2 Decision-level Fusion
Test set identification result confusion matrix (decision fusion) is shown in Figure 11.
According to the confusion matrix, the recognition accuracy reaches 83.75% after weighted decision fusion, which is higher than that of single modality and data fusion. After weighted decision fusion, the accuracy rate of neutral emotion recognition is the highest,reaching 90%. The recognition accuracy of sadness emotion is low, but compared with the single-modality and data fusion strategy, the recognition accuracy of sadness emotion is also improved.
5 Conclusion
This paper studies a multi-modal emotion recognition method based on facial expressions and ECG signals. In the analysis of facial expressions, the threedimensional convolutional neural network is used to capture the spatial features and temporal dynamic emotional features of facial expressions, and the deep structure is used to learn abstract and differentiated representations layer by layer. In order to remove the influence of irrelevant factors and improve the performance of the network, this paper performs preprocessing operations such as face detection and image de-averaging on the original data. Finally, the selected three-dimensional convolutional neural network was trained on the training set and reached an average recognition accuracy of 72.25% on the test set.
In the emotion recognition based on the ECG signal, this paper focuses on how to construct the denoised ECG signal into input data suitable for the three-dimensional convolutional neural network. In this process, this paper considers the impact of different sampling frequencies and the problem of missing data association and loss of emotional key points caused by segmented sampling. Finally, a three-dimensional convolutional neural network is used to perform feature learning and classification of the ECG signal, and the correct rate is 64.75% on the test set.
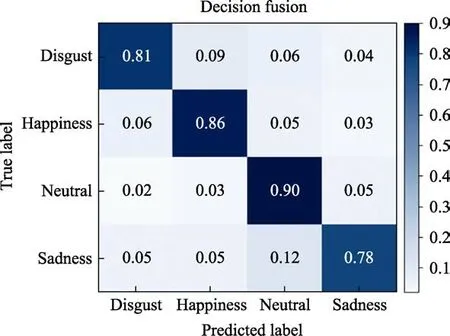
Fig.11 Test set identification result confusion matrix (decision fusion)
In addition, we fused the information of the two modalities at the data level and the decision level respectively. In the process of data-level fusion, this paper uses the migration learning strategy to replace the initial weight of the network with the weight of the trained facial expression recognition network, giving the network a higher starting point. In the fusion process at the decision level, considering the difference in the performance of different emotion recognition by different modalities, this paper uses a weighted fusion strategy to give different modalities different weights. Finally, a comparative analysis of the effect of multi-modality and single-modality on emotion recognition shows that multi-modal fusion recognition performance is better,and of the two fusion methods, the fusion recognition effect at the decision level is better.
In future, we plan to build a larger number of multi-modal emotion databases. Further, we will fuse more modalities by selecting more data sources for emotion recognition research. Finally, special efforts will be put on designing a better structure of three-dimensional convolutional neural networks.
