
基于迁移学习的示功图诊断方法
2022-02-26 01:40段志刚李汉周司志梅叶红赵庆婕
石油化工自动化 2022年1期
段志刚,李汉周,司志梅,叶红,赵庆婕
(中国石化江苏油田分公司 石油工程技术研究院,江苏 扬州 225009)
游梁式抽油机是油田开发的主要设备之一[1],及时掌握抽油机的作业情况对于提高石油产出量具有重要作用。由于井下环境复杂,抽油机在作业过程中往往会受到一些干扰导致作业异常[2],常见的作业异常包括: 上/下行遇阻、不平衡、供液不足、凡尔失灵、气体影响等几十种,其形成原因与表现形式各不一致,如何及时有效地识别不同作业故障非常具有挑战。
现阶段国内对于抽油机的故障诊断主要依据采油工程师对于示功图的分析和油井管理经验来确定[3-4]。悬点示功图,也称地面示功图或光杆示功图,是抽油井采油现场采集的第一手资料。示功图不同的几何形状则代表着作业的不同工况,标准无异常的示功图为平行四边形,如果油井发生供液不足,示功图的形状则类似于一把刀,如图1所示。传统的示功图故障检测基于专家系统[5],对不同形状的示功图进行总结分析[6]。然而实际测量出的示功图千变万化,形成原因与故障对应关系错综复杂,过于依赖专家知识导致系统开发费时费力,且鲁棒性较低。基于支持向量机算法(SVM)等分类模型也可以获得不错的效果[7],但前提是合理的特征选择,同样需要一定程度的领域知识和实验分析。因此笔者尝试从深度学习的角度出发,将示功图的故障检测问题转化为图像分类问题,实验表明,无需大量领域知识和特征选择即可实现对传统方法的有效提升。
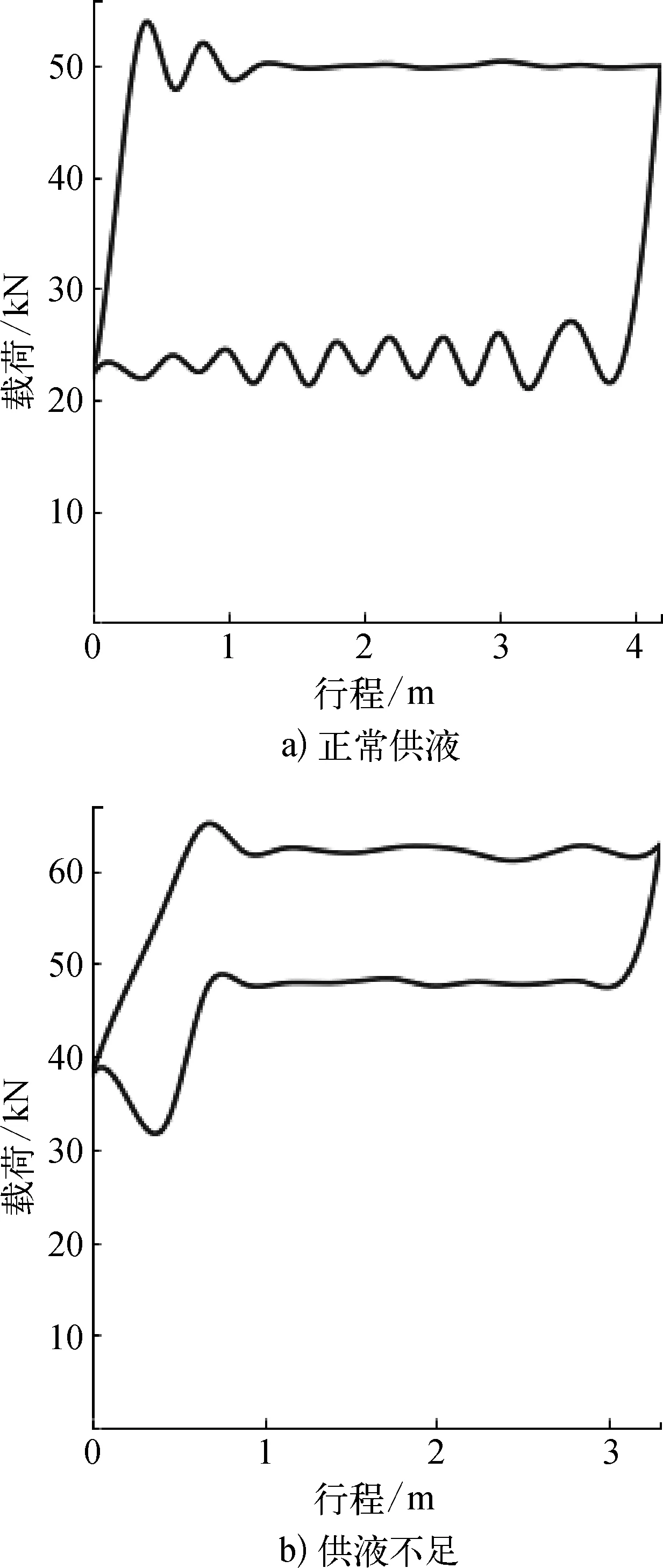
图1 标准示功图与供液不足时示功图对比示意
该方法主要内容如下:
1)针对专家系统的性能限制,提出了利用基于卷积神经网络的图像分类方法实现对示功图的异常诊断。
2)由于人员和成本的限制,很难获得大量有标注的数据。本文基于预训练的残差网络在少量示功图标注数据上进行微调,将ImageNet数据集上标注好的语义信息迁移到示功图分类上,避免了网络从零初始化的过程。通过迁移学习使模型在少量有标注数据的情况下,依然取得了不错的效果。
1 示功图诊断的相关工作
1.1 基于示功图的作业诊断方法
示功图作为油田作业诊断的第一手资料,一直受到国内外学者的广泛关注[8]。早期学者将专家系统用于抽油机工况诊断,利用领域知识与经验建立了典型示功图的规则集合的知识库,可以使用推理机解析规则识别示功图,实现识别诊断[9]。周宁宁等[10]通过模糊理论实现示功图诊断,解决示功图表示不明确的问题,将特征缺失面积与缺失行程定义为隶属变量,设计隶属函数求解出最佳隶属度作为样本类别。杨洋等[11]基于灰色理论,将经过归一化后消除量纲、尺度的示功图利用网格法得到灰度矩阵,再求解其灰度关联特征得到6个元素的特征向量,最终与基准库的11种典型示功图特征作灰度关联分析,从而实现诊断。Sun等[12]通过不变矩理论提取示功图的几何特征作为输入,分别使用BP神经网络和SVM作为分类器识别示功图类型,其中SVM表现更好,83%的正确率高出BP神经网络5个百分点。而随着深度学习的发展,仲志丹等[13]通过稀疏自编码器自动提取示功图图像特征,并通过softmax分类器做分类,在其测试集上获得了98%的准确率[14]。
1.2 基于深度卷积网络的图像分类
深度学习[15]作为机器学习的一大分支,一直是业界的研究热点之一,近年来,尤其在机器视觉和自然语言处理等领域获得了重大突破。深度学习的概念起源于人工神经网络,多层感知机就是一种最基础的深度学习结构,无需手动设计特征,浅层输入随着网络深入进行特征组合并在高层获得更加抽象的表示,再通过梯度下降算法优化训练损失就可以自动迭代地学习出恰当的样本表达。图像分类是深度学习最广泛的应用场景之一,其主要任务是将图片数据中同种类型的图片识别出来,强调对图像整体的语义理解。相较于多层感知机,深度卷积神经网络通过卷积核进行特征抽取,结合池化层进行采样,既使得模型对图片的平移,放缩等变化具有一定程度的抗干扰能力,也可以有效降低网络的复杂性,减少参数量,在图像分类领域中应用最为广泛。Alex等[16]提出的AlexNet首次将深度卷积网络应用于大规模图像分类ImageNet上,大幅超越传统算法。谷歌团队在ILSVRC2014上发布的GoogleNet[17]基于Network in network思想进一步提出Inception模块以稠密组实现了有效降维,减少了模型参数的同时也减轻了过拟合问题。随后不久又提出的batch normalization进一步提升GoogleNet的泛化能力,获得了更好的效果。然而随着网络深度的进一步加深,模型却由于过拟合和梯度消失等原因出现了退化现象,直到深度残差网络ResNet的出现[18],通过残差结构将网络深度成功地加深到152层,进一步解放了深度学习的上限[19]。
与此同时,研究者经过可视化方法发现,处理图像任务的神经网络其底层特征具有较高的一致性,大多为线条,纹理等信息,仅在上层任务相关的部分存在较大差别,将大量有标注数据的源领域知识迁移到少量标注或无标注目标领域的方法便称为迁移学习[20]。由于ImageNet具有数据集规模大、种类多、信息丰富的特点,基于ImageNet预训练好的模型通常具有很强的泛化能力,因此是机器视觉任务中最常见的源领域数据集。将该预训练模型进一步在其他任务上进行微调时,相较于一个从头训练的模型,微调模型不但能提高精度,且在少量有标签数据的情况下就可以获得不错的效果。
2 解决方案
2.1 问题定义
示功图诊断指将油田作业示功图分类至正常、不平衡、气体影响、供液不足、凡尔失灵等30个类别中,属于图片多分类问题。常规示功图数据在数据库中以二进制编码的形式保存,经由Python程序解码后在画布上作图而形成图片,保留横纵坐标轴为模型识别提供尺度信息,并以224×224的分辨率保存在本地。
2.2 模 型
整个模型架构如图2所示,输出通过中间的预训练模型进行特征提取,预训练模型内部包括多个残差块;再通过全连接层将特征向量变成目标分类的概率分布实现模型预测;最后通过以softmax激活函数将概率分布归一化,获得最终的分类结果。
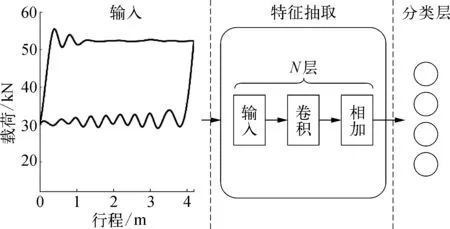
图2 示功图诊断神经网络模型结构示意
2.3 基于深度残差网络的特征抽取模块
残差网络泛指以多个残差块堆叠而成的深层网络,每个残差块中又可以包含多个卷积层。残差网络的主要思想是: 将网络的输入与输出相加作为该结构的最终输出,使得模型在前向传播的时候可以保持上一层信息不丢失地传入下层,而在反向传播时,又可以将梯度直接传递到上一层,从而避免梯度消失问题,大幅提高了模型的泛化能力。具体地,以ResNet为例,其残差结构如式(1)所示:
hl+1=Relu(hl+F(hl,wl))
(1)
式中:hl,hl+1——分别为该残差块的输入和输出;F——残差映射函数,如卷积操作等;wl——对应参数。Relu的激活函数如式(2)所示:
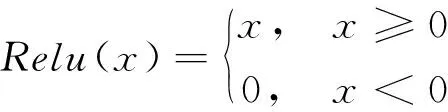
(2)
先将残差网络在ImageNet的有标注数据集上预训练,接着删除最顶层的分类层,把中间的输出层作为特征抽取模块。以该预训练参数作为初始化进行迁移学习,可使模型获得一定与图像相关的先验知识,使得模型无需重新学习低级语义信息,避免了参数从零初始化的窘境。
2.4 Softmax分类器
模型上层是任务相关的分类器,由一个全连接层加Softmax模型的激活函数组成。分类器函数如式(3)所示:
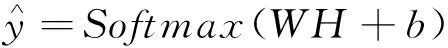
(3)
式中:H——最后一层输出特征;W,b——对应全连接层的可学习参数。经过全连接层将向量维度修正为N维向量Z,每一维度代表着该次预测在对应示功图分类的概率大小。Softmax模型的激活函数如式(4)所示:
(4)
通过Softmax分类器对概率分布进行归一化,取概率最大值所在维度作为最终预测结果。
3 实 验
3.1 数据准备
实验数据取自某油田作业数据库,通过人工标注出30个示功图类别,将整个数据集以3∶1的比例划分为训练集和测试集,取典型7种示功图的实验结果进行分析,包括: 正常、抽喷、不平衡、供液不足、气体影响、气锁和杆断。具体数据分布见表1所列。

表1 训练数据分布
表1中,正常、供液不足、抽喷、气体影响等都属于样本充足的类型,不平衡是稍微欠缺,气锁和杆断则属于十分稀少的类别,因此该数据集存在很严重的样本不均衡现象。每张图片都经过数据增强来提高数据集质量,数据增强方式包括: 旋转、放缩、裁剪,但不包括翻转,因为示功图翻转之后有可能改变其所属类别。
3.2 实验设置
首先,预训练的特征抽取模块不固定参数,而是随着整个网络一同训练,学习率为0.000 1,使得模型主要更新任务相关部分,而不至丢失预训练信息。优化器为adam,具有较好的收敛效果。每批次实验采样个数为64,可较好地平衡训练速度和精度。损失函数为交叉熵,评价指标为准确率,综合评价指标为宏平均与微平均,其中宏平均是先对每一个类统计指标值,然后在对所有类求算术平均值,微平均是根据样本数量采用加权的方式再取平均,可以更好地衡量模型对不平衡样本的性能。详细实验参数设置见表2所列。
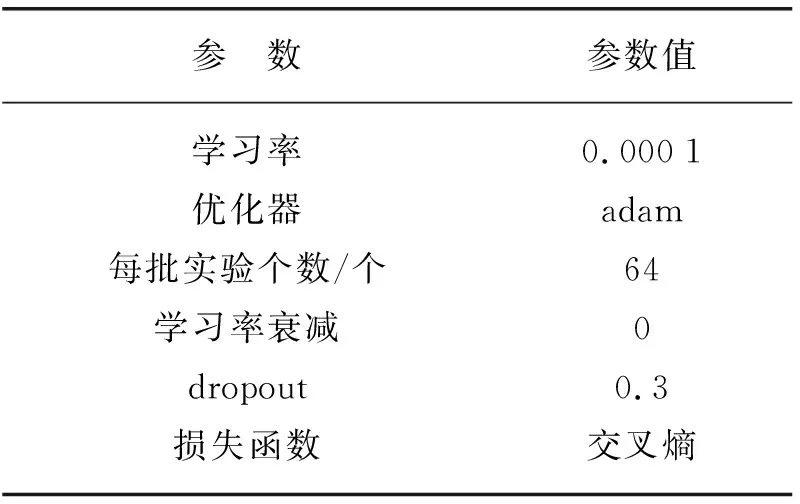
表2 实验详细参数
3.3 不同模型的实验对比
本文探究了不同残差网络作为特征抽取器的效果,包括ResNet,DenseNet与MobileNet。
ResNet由微软研究院的何恺明等人提出,率先将残差结构引入深度神经网络中,将网络深度首次突破100层,是目前最经典图像处理网络之一。
DenceNet[21]是对ResNet的一次拓展,相较于ResNet,每个残差块是前后直连,DenceNet提出来一个密集连接机制,即网络中的所有层都互相连接,具体而言,每一层网络都会接受其前面所有层的输出作为其输入。在同等参数量时,具有比ResNet更好的性能。
MobileNet[22]是一种轻量级的神经网络,采用深度可分离卷积代替普通卷积操作,以降低模型的计算量和参数量。MobileNet在尽可能保证图像分类精度的同时,大幅缩短了网络推理速度,是追求实时性应用的不二之选。
3.4 实验结果与分析
不同模型精度的实验对比见表3所列,从表3来看,三个模型在微平均精度上差距不大,MobileNet最高,为98.75%,ResNet其次,为98.71%,DenceNet则稍低一些,为98.27%,比前两者低了0.5个百分点。在宏平均精度上的差距较为明显,ResNet具有最高的宏平均精度为97.13%,相较于宏平均精度第二的MobileNet高出1.2个百分点,且大幅超过DenceNet的宏平均精度。

表3 不同模型精度的实验对比 %
具体从各个类别分析,对于样本数量十分充足的类别: 正常、气体影响、抽喷和供液不足,三个模型均取得了不错的效果,对于样本数量相对较少的不平衡示功图,各个模型都达到了99%以上的准确率,甚至高于样本充足的四种示功图。但是随着样本数量进一步减少时,气锁和杆断的训练集样本均小于1 000个,模型精度大幅下降。以ResNet为例,在训练样本为756的气锁示功图上,精度为94.44%,相较于前五种示功图下降了4个百分点,训练样本数为240的杆断,效果最差,精度只有91.25%,低了7个百分点。其他两个模型也存在着同样的现象。由此可见,在该数据集上1 000个训练样本是划分长尾样本的分割线,数据量达到1 000之后对精度就不会有有效提升,数量在1 000以下则影响巨大。
从三个模型对于气锁和杆断等不均衡样本来看,ResNet具有最强的鲁棒性,DenceNet最差,可见DenceNet各个层的充分连接带来的强大拟合能力在此处反而使得模型忽略了少数样本的特征。MobileNet更加简洁,因此效果更好,但是相较于ResNet更为强大的迁移学习能力,在少样本上自然稍逊一筹。
4 结束语
本文探索了深度学习背景下的示功图诊断方法,一方面将示功图诊断作为图像分类问题进行建模;另一方面基于预训练的深度残差网络在示功图分类上做迁移学习,既提高了模型的精度,也减少了训练对大量样本的依赖。实验表明,该方法简洁有效,具有较强的实用性。
在未来的工作中,将重点研究示功图故障样本不平衡问题,尤其是少样本示功图的处理方法,尝试结合数据挖掘等方法进一步提高少样本故障的检测精度。
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
网络安全与数据管理(2022年3期)2022-05-23
一重技术(2021年5期)2022-01-18
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2020年10期)2020-11-14
电子制作(2019年13期)2020-01-14
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年11期)2019-07-04
电子制作(2018年11期)2018-08-04
北京航空航天大学学报(2018年1期)2018-04-20
