
一种拟态存储元数据随机性问题解决方法
2022-02-24 05:06杨珂,张帆,郭威,赵博,穆清
计算机工程 2022年2期
杨 珂,张 帆,郭 威,赵 博,穆 清
(1.战略支援部队信息工程大学,郑州 450001;2.数学工程与先进计算国家重点实验室,郑州 450001)
0 概述
近年来,云计算和大数据技术的发展普及推动了互联网服务模式的快速变革,以数据中心为代表的新一代信息基础设施成为国内外社会建设发展的重点方向。数据存储系统作为信息基础设施中的重要组成部分,未来将承载更多的核心业务数据与用户隐私数据,因此,其安全性也越来越受到关注和重视。然而,随着“棱镜门”[1]等各类网络安全事件的频发,产业界和学术界逐渐意识到传统安全手段的缺陷,以防火墙[2]、IDS[3]、IPS[4]等为代表的被动防御方法已经难以满足新一代信息技术背景下人们对网络安全的需求[5]。
网络空间拟态防御(Cyberspace Mimic Defense,CMD)[6]是一种新型的主动防御技术,其基于动态异构冗余(Dynamic Heterogeneous Redundancy,DHR)的拟态构造模型,赋予目标对象内生安全[7]功能属性,使其能够有效应对未知漏洞、后门等攻击威胁,从而克服传统防御手段的不足。拟态存储是CMD技术在数据存储系统上的具体实现,是解决新一代信息基础设施中数据与存储系统安全性问题的可行方案[8]。目前,研究人员已经在分布式存储架构中成功导入拟态DHR 模型,并验证了其提升数据与系统安全的有效性[8]。但与此同时,学者们也总结出拟态存储系统中需要进一步关注并解决的诸多问题,包括大规模集群异构冗余化带来的开销和可实现性问题、执行体运行状态不一致问题、拟态构造的调度和裁决策略问题等[9]。
本文针对拟态存储中执行体运行状态不一致问题展开研究,介绍拟态防御技术的相关研究以及拟态存储基本架构,分析和验证系统运行过程中由元数据随机性所导致的问题,在此基础上,设计实现相应的校正同步方法,并在实际系统中对元数据再同步方法的性能进行验证。
1 相关工作
网络空间拟态防御是实现信息系统内生安全的一种普适性方法,目前已经在工业控制处理器[10]、路由器[11]、DNS 服务器[12]、SDN[13-14]等领域得到一定的应用。拟态DHR 是网络空间拟态防御方法中的核心模型,其结构如图1 所示。
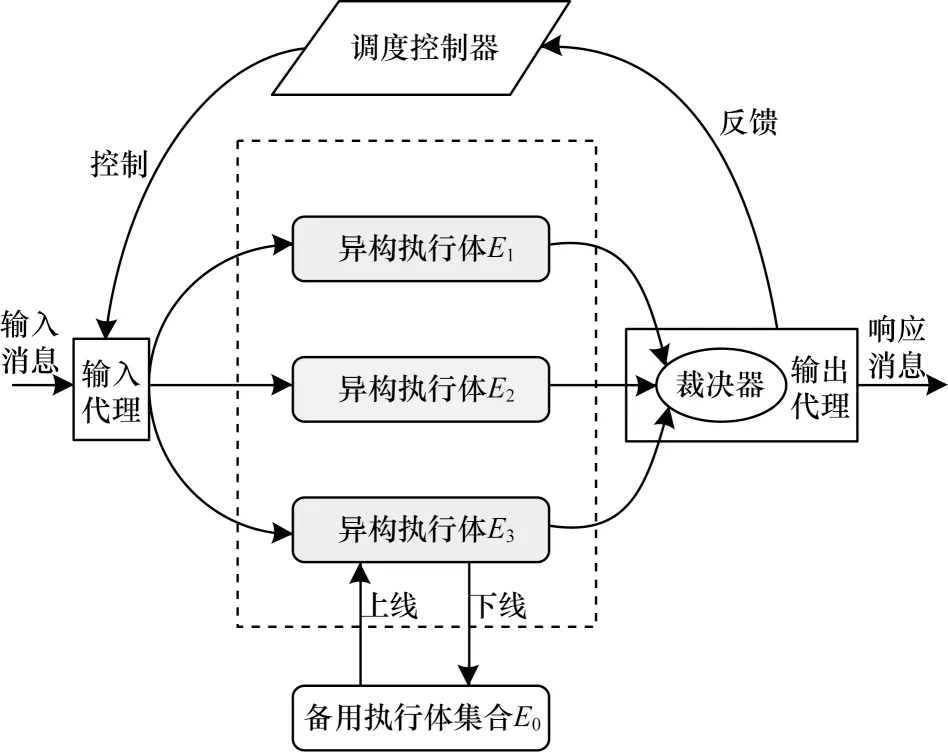
图1 拟态DHR 模型Fig.1 Model of mimic DHR
DHR 模型[15]的构建基础是一定数量的异构执行体,它们在功能上等价,但基于不同的硬件平台、操作系统、运行环境等,因此,不同执行体所携带的漏洞后门也不完全相同,会对不同的攻击产生独立的响应输出。通过对多个执行体输出进行比较验证,能够有效判断系统状态,屏蔽异常而得到正确的结果,并且有针对性地对受攻击执行体进行清洗、替换等操作。拟态DHR 模型具有构造安全的普适性,对已知和未知漏洞后门等均能实现有效防御,大幅增强了网络应对外部入侵和内部渗透的能力[6,16]。文献[6]指出,DHR 结构的防御成本随着执行体数量N线性增加,但防御效果是非线性增加的,当N≥3 时,其安全性已经取得大幅提高。综合考虑成本和安全性,在已实现的拟态防御系统中,一般采用3 个异构执行体,因此,本文在模型分析和实际测试时,将执行体数量设为3。
由于DHR 模型需要对防护目标构建异构冗余的多执行体,因此在分布式存储架构中导入拟态防御方法要尽可能选取系统核心功能与数据的承载体,避免造成过大的成本和性能开销。文献[8]比较了分布式存储系统中对不同对象进行拟态化设计的成本、可实现性以及有效性,最终确定将元数据功能节点(NameNode)作为拟态防护边界,以尽可能取得最大的安全/成本收益比,其拟态存储的基本架构如图2 所示。
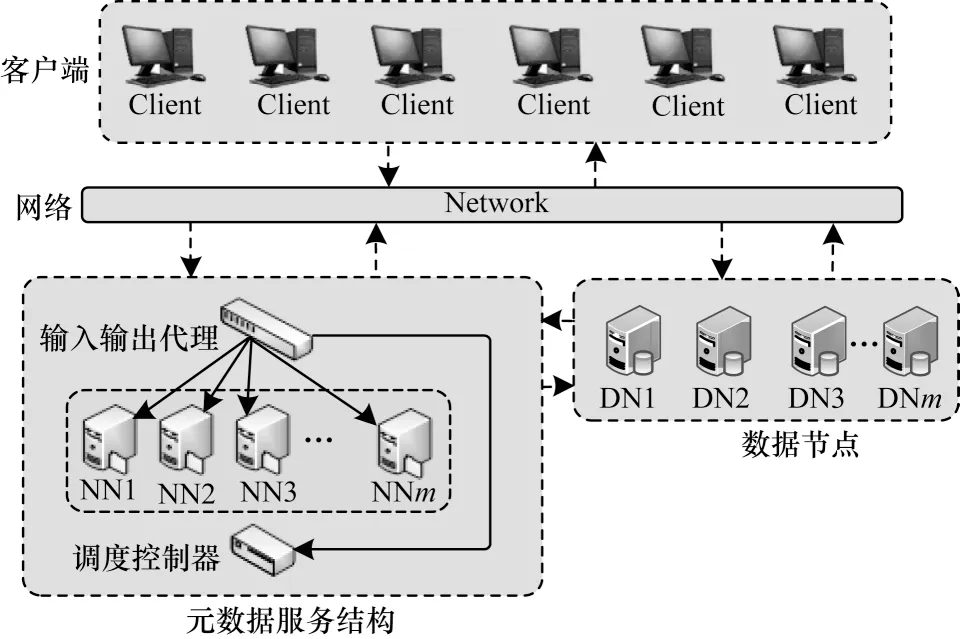
图2 拟态存储的基本架构Fig.2 The basic architecture of mimic storage
面向元数据服务的拟态存储架构主要对元数据服务器进行拟态化改造,包含异构冗余化的执行体集合、配合分发裁决代理和调度控制器,从而实现防御功效。拟态存储用拟态化的元数据服务结构取代一般分布式存储系统中单一的元数据节点,对外的基本功能一致,但内部结构和处理流程对外是不可见的。在拟态化元数据服务结构内部,主要包括以下3 个模块:
1)输入输出代理,主要负责分发客户端请求、对执行体执行结果进行裁决和反馈。
2)异构元数据执行体集合,包括若干个异构的元数据执行体,各自独立地执行客户端请求并分别向输入输出代理反馈执行结果。
3)调度控制器,按照一定规则对执行体进行下线、清洗、上线等操作。
当元数据服务结构收到来自客户端的请求消息时,输入输出代理将消息分发给所有在线的执行体,执行体分别执行操作并将结果发送到输入输出代理,输入输出代理按照一定规则对执行结果进行裁决,得到最终的输出消息,同时将裁决结果发送给调度控制器,调度控制器根据裁决结果对执行体进行下线、清洗、上线等操作。为了保证多个执行体的功能等价,不仅需要在设计和开发阶段保证执行体功能的一致性,还需要在存储系统工作过程中保持执行体状态的一致性,否则存储系统将无法正常运行。
2 元数据随机性问题
所有执行体是独立运行且互不可见的,而每一个元数据执行体中都保存着用户所有的元数据信息,如果这些执行体中保存的元数据信息出现了不一致的情况,将会导致执行体输出不一致、裁决出现异常等问题,严重影响拟态存储系统的正常工作。
在元数据节点NameNode 中存在随机性的算法和逻辑,在工作正常的情况下也会出现若干NameNode 执行结果不一致的问题,如写入文件指令会引发执行体随机性逻辑,客户端发送一个写入文件的指令,执行体会随机选择一个数据节点,然后在该节点的同一机架和其余机架上分别再随机选择一个数据节点,即每个执行体会给出3 个具有一定随机性的写入地址,此时不同的执行体内部状态就会大概率出现不一致的情况。不同步的元数据执行体示意图如图3 所示。

图3 不同步的元数据执行体示意图Fig.3 Schematic diagram of unsynchronized NameNode executors
图3 所示流程为:
1)客户端写入一个文件M。
2)执行体返回3 组不同的写入地址。
3)裁决器按照一定策略对执行体的返回结果进行裁决。
4)客户端得到最终的写入地址。
可以看出,虽然客户端得到了预期的返回消息,但是此时3 个执行体所存储的元数据不一致,即执行体的状态不一致。本文在真实的拟态存储环境中进行测试,结果如图4 所示,可以看出,当执行存在随机性的指令时,执行体状态出现了不一致的情况,此时如果访问写入的文件,就会出现不可预知的错误。

图4 执行体状态不一致的测试结果Fig.4 Test results of inconsistent states of the executors
元数据的状态同步是拟态裁决机制正常工作的基础,然而元数据随机性问题会使得系统产生误判,导致整个拟态存储系统无法正常运转。因此,在拟态存储中,解决NameNode 同步问题显得尤为重要。
3 元数据再同步方法
3.1 解决思路
不同于传统的关系型数据库,在分布式存储系统中存在CAP 原则,即在分布式系统的一致性(Consistency)、可用性(Availability)、分区容错 性(Partition Tolerance)3 个属性中,最多只能同时满足2 个,三者不可兼顾。因此,在拟态存储架构设计中必须有所取舍,根据分布式系统CAP 原则,要保证可用性和分区容错性,只能牺牲一致性[17]。一致性一般分为如下3 类:
1)强一致性,即客户端操作完成之后马上就可以访问更新过的值。
2)弱一致性,即客户端操作完成后,不能保证马上访问到更新过的值,系统也不保证访问时效。
3)最终一致性,其为弱一致性的特殊形式,保证在没有后续操作的前提下系统最终返回上次更新的值[18]。
在工程实践中,为了保证系统的可用性,通常将强一致性需求转换成最终一致性需求[19-20]。基于这个思路,本文考虑用最终一致性的流程和相关机制来解决元数据的随机性问题。
3.2 再同步方法
针对上述拟态存储中元数据的随机性问题,本文提出一种元数据再同步方法,其基本流程如图5所示。
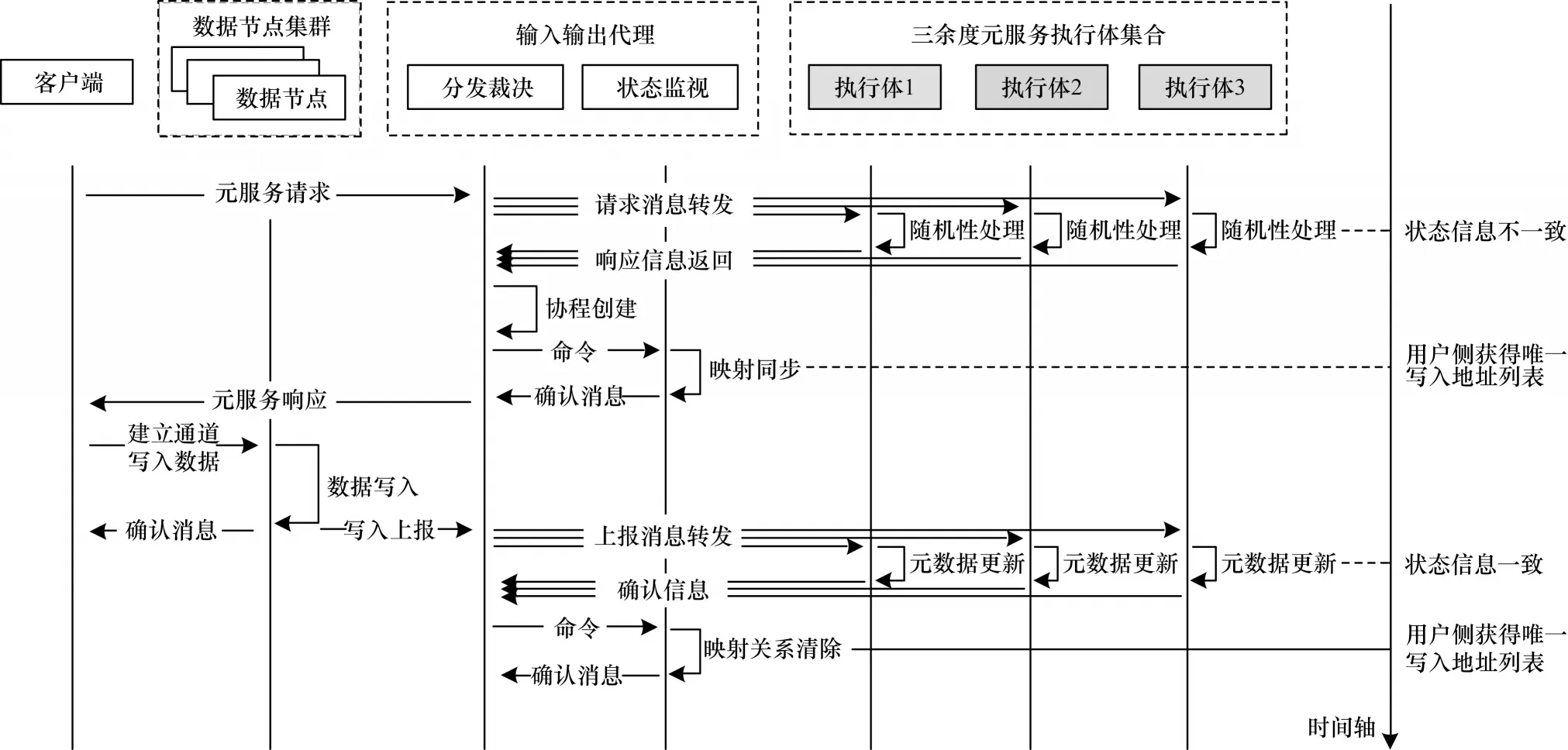
图5 元数据再同步方法流程Fig.5 Procedure of metadata resynchronization method
本文元数据再同步方法在输入输出代理中增加NameNode 执行体状态监视模块并引入映射同步机制,系统工作流程如下:
1)客户端发送请求消息。
2)输入输出代理将消息转发给各个执行体。
3)执行体进行消息处理,并将响应结果发送给裁决器。
4)输入输出代理将裁决结果发出。
5)状态监视模块检测到执行体状态不一致,建立映射同步,记录输入指令和输出结果的映射关系。
6)输入输出代理收到上报消息。
7)状态监视模块将上报信息反馈给各个执行体进行同步。
8)同步完成后执行体给状态监视模块发送确认信息。
9)状态监视模块清除映射同步信息,完成同步。
在同步过程中,整个流程最关键的步骤在于映射同步的建立。当状态监视模块检测到执行体状态不一致时,立即记录客户端的指令和裁决器的输出结果,建立两者的映射关系。在元数据再同步的过程中,如果客户端再次访问该条元数据而不经过执行体,通过映射同步可以直接给出访问结果。如果缺少映射同步,客户端访问时执行体状态尚未完成同步,依然无法得到正确的结果。映射同步仅存续在元数据同步期间,当同步完成之后,映射同步失去作用并随即清除,从而减少资源占用。
4 实验评估
本节将对元数据再同步方法进行实验,以验证该方法的有效性,并评估其对服务性能的影响,从而为后续研究提供依据。实验内容主要分为2 个部分:
1)功能测试,即在真实的拟态存储环境中添加再同步方法的相关功能代码,测试其能否有效解决元数据随机性问题。
2)性能测试,主要通过对比测试的方法观察元数据同步过程中的开销,以评估再同步方法对拟态存储系统性能的影响。
4.1 实验环境
本次实验在拟态存储工程样机上进行。在硬件环境方面,基于异构化组件构建物理服务器,部署3 台元数据执行体和4 台数据节点,另外还包括1 台分发裁决节点、1 台内部管理节点以及相应的交换机、测试客户端机。在软件方面,在元数据执行体上分别部署CentOS、Solaris 和国产麒麟操作系统,存储中间件使用典型的大数据分布式存储Hadoop 2.7.3,抓包工具采用Tcpdump version 4.9.2,libpcap version 1.5.3,分析工具使用集成hadoop 协议的wireshark 版本,性能测试采用TestDFSIO 标准软件工具。整个实验环境拓扑如图6所示。
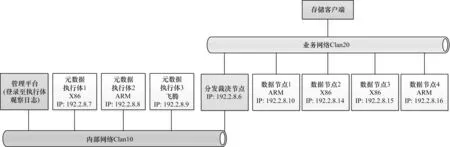
图6 测试环境拓扑Fig.6 Test environment topology
在功能测试中,通过外部存储客户端发起可触发元数据执行体随机性逻辑的上传文件指令,然后在分发裁决节点进行抓包分析,并在内部管理平台登录查看各个执行体的工作日志,观察系统是否能够通过再同步方法解决随机性逻辑导致的状态不一致问题;在性能测试中,通过外部存储客户端分别对再同步功能开启前后发起基本读写命令,以评估本文方法的实际运行开销。
4.2 功能测试
通过文献[21-22]可知,Hadoop 分布式存储HDFS 的数据块分配算法Block_allocate 具有随机性,因此,本次实验选取能够触发该算法的数据写入操作(hdfs-put)进行测试,各个元数据执行体(简记为NNx)返回的消息包结果如图7 所示。

图7 数据块分配返回的消息包对比Fig.7 Comparison of message packets returned from data block allocation
图7 显示,NN1 分配的数据节点为DN1、DN3、DN4,而NN2 和NN3 分配的数据节点为DN2、DN3、DN4,元数据执行体Block_allocate 算法的随机性被触发。从图8 可以看出,各个NN 对上传文件的初次分配位置不同,其内容与图7 中网络消息包的返回一致,即元数据执行体运行状态发生不一致的情况,此时继续在分发表决节点抓包,观察实际存储的数据节点是否发起了再同步消息。
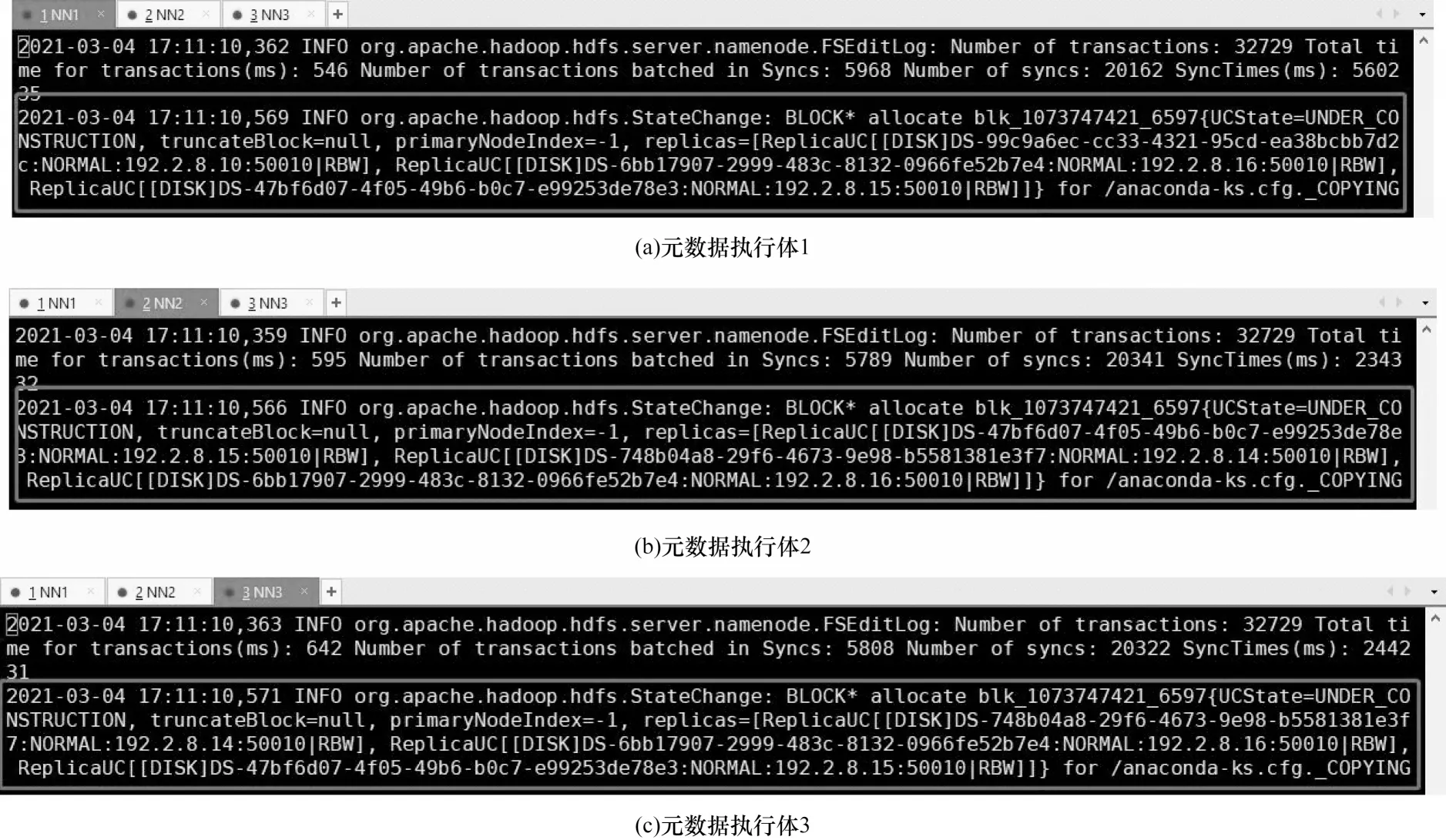
图8 不同执行体上的块分配日志记录Fig.8 Block allocation logging on different executors
如图9所示,DN1、DN3、DN4为实际存储该文件的数据节点,它们在接收到上传数据后向系统上报自己的接收事件(RECEIVED),分发表决器将此消息包再转发至各个执行体进行再同步操作,此时观察NN 上的运行日志。图10 以初次分配DN2、DN3、DN4 的NN3为例,可以观察到,NN3 在收到RECEIVED 消息包后,重新更新测试文件存储位置的信息,将实际发起再同步数据包的DN1、DN3、DN4 添加为对应的存储节点,即本文的再同步设计生效。为了更直观地验证再同步方法的有效性,通过存储客户端对写入的测试文件进行读取,可抓取到系统响应数据包如图11 所示。
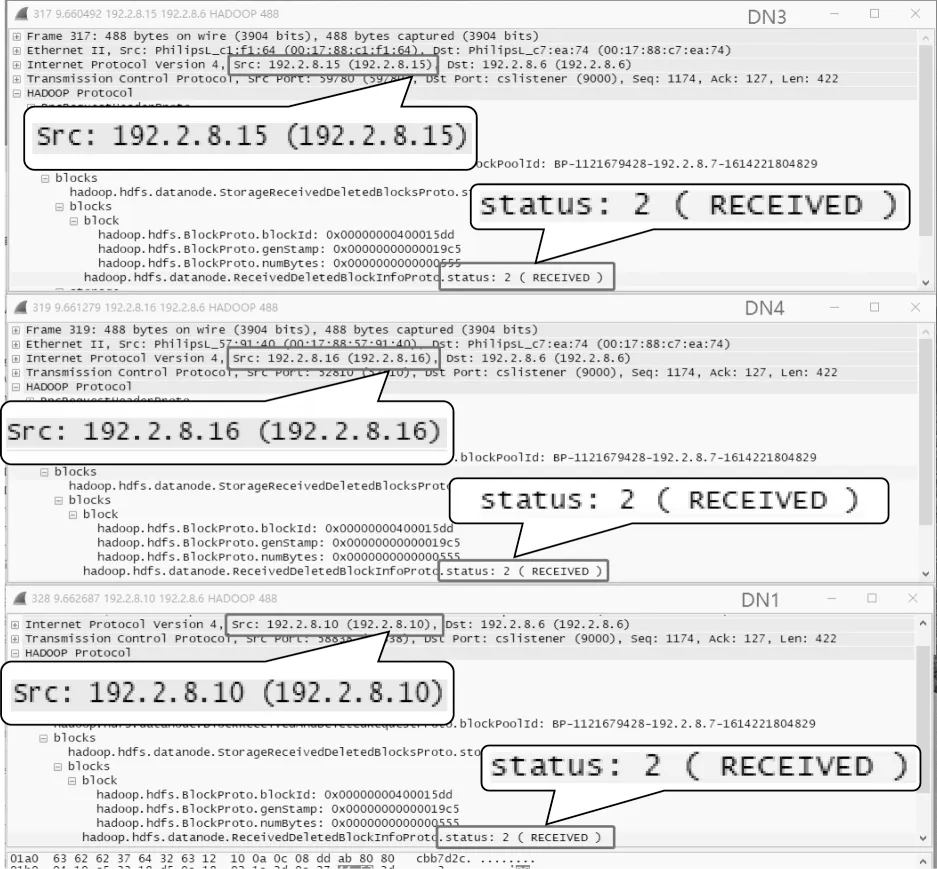
图9 分发表决器收到的再同步消息包Fig.9 Resynchronization message packet received by the distribution and voting machine
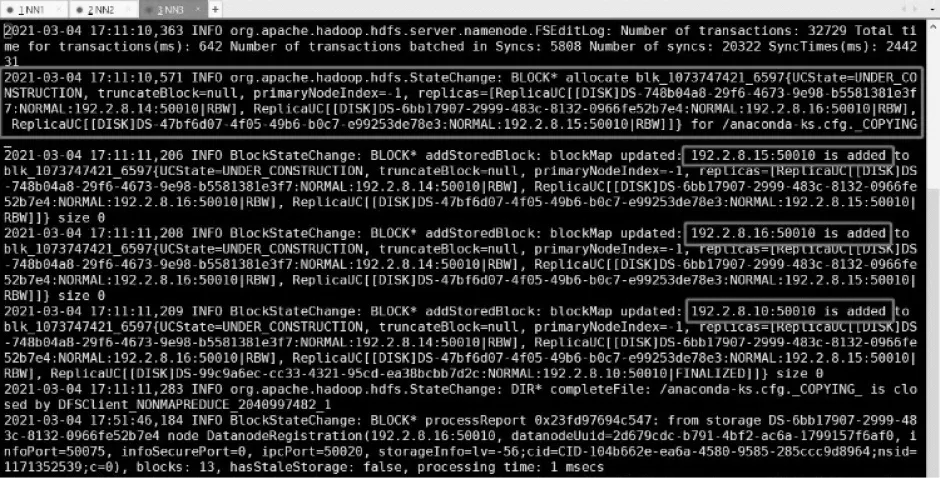
图10 NN3 执行体上的日志记录Fig.10 Logging on NN3 executor
图11 再同步后数据块分配的返回消息包Fig.11 Returned message packet of data block allocation after resynchronization
从图11 可以看出,在经过元数据的再同步后,当外部对测试上传文件发起请求,各个元数据执行体的返回结果均为DN1、DN3、DN4 及其位置信息,可知其对应的元数据已经保持一致。继续重复上述操作并检查执行体状态,再同步机制均能解决元数据随机性问题,同步成功率可达100%。
4.3 性能测试
性能测试基于标准的TestDFSIO 工具对系统发起数据服务请求。由于本文的再同步方法并不涉及数据读操作,其主要解决数据写操作中出现的元数据随机性问题,因此性能测试以写操作作为主要请求内容。写容量大小设定为10 GB,在拟态存储配置单个块64 MB 的条件下,对比再同步机制开启前后的性能。如图12、图13 所示,客户端能够正常运行TestDFSIO 测试工具且生成规定大小的文件,不报错。数据显示,当拟态存储未开启再同步机制时,整个过程耗时337.955 s,写入速率为30.488 MB/s;当拟态存储开启再同步机制后,总用时为349.180 s,写入速率为29.490 MB/s。可以看出,对于一个数量较大的连续写操作,再同步机制会造成一定程度的性能损失,但对于用户而言是可接受的,并且在实际应用场景下,读写操作通常是穿插进行的,再同步机制的开销能够更好地分散在写与写的操作间隙,从而在一定程度上缓解性能损失,提高用户体验质量。
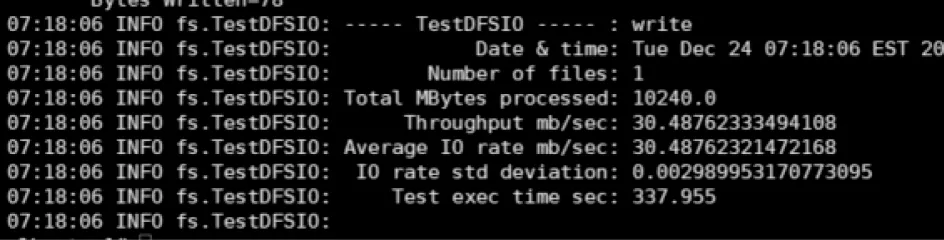
图12 未开启再同步机制的写入测试结果Fig.12 Write test results without resynchronization mechanism
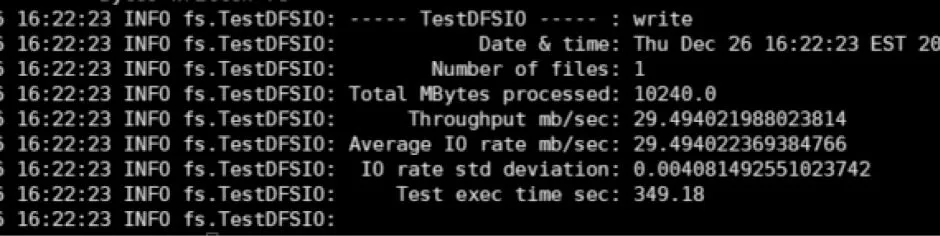
图13 开启再同步机制后的写入测试结果Fig.13 Write test results with resynchronization mechanism
5 结束语
为了解决拟态存储中的元数据随机性问题,本文对拟态存储工作流程进行分析,提出一种元数据再同步方法,以在不影响元数据对外服务的情况下实现NameNode 执行体状态同步。在拟态存储真实环境中的测试结果表明,本文方法能够有效解决元数据随机性问题,保证拟态存储裁决机制的正常运行,提升拟态存储系统的稳定性。后续将进一步优化NameNode 执行体同步过程,将带有随机性逻辑的功能部分迁移到分发表决代理或替换为伪随机工作模式,从而减少再同步的流程步骤,缩短时间开销,尽可能缓解同步过程造成的拟态存储系统处理性能下降问题。
猜你喜欢
小哥白尼(趣味科学)(2021年5期)2021-08-13
哈尔滨轴承(2020年2期)2020-11-06
发明与创新·大科技(2019年12期)2019-03-17
学苑创造·A版(2019年12期)2019-01-10
北方文学(2018年2期)2018-01-27
魅力中国(2017年6期)2017-05-13
中国科技纵横(2016年20期)2016-12-28
弹箭与制导学报(2015年1期)2015-03-11
体育教学(2014年9期)2015-01-30
客车技术与研究(2014年5期)2014-02-28
