
基于变分自编码器的谣言立场分类算法
2022-02-24 05:06郭奉琦孟凡荣王志晓
计算机工程 2022年2期
郭奉琦,孟凡荣,王志晓
(中国矿业大学计算机科学与技术学院,江苏徐州 221116)
0 概述
目前,在线社交媒体已经成为人们获取信息和新闻消费的主要途径。据美国媒体报告显示,三分之二的美国成年人通过社交媒体获取新闻,其中推特(Twitter)是使用最多的平台[1]。研究者通过调查发现,观察社交媒体用户对谣言的观点导向是对谣言报告真实性做出正确判断的关键[2],而未经验证的谣言可能会引起恐慌[3-4]。有研究表明,最终被证实为虚假的谣言比最终被证实为真实的谣言更容易引发大量的否认推文[5]。本文中所提及的谣言是指未经证实便在网络上流传的消息,并不是单纯指代虚假的消息,而谣言立场就是人们在在线社交网络中对突发事件的看法。
在谣言立场分类任务中,从数据结构信息的角度可将目前的研究工作分为基于单条推文和综合考虑推文上下文结构两类,后者是目前的主流研究方向。在此类方法中,部分算法需要根据不同类别、不同主题之间的差异提取大量的人工特征,这样虽然能够提高针对数据量较少的类别的分类准确性,但是扩展性较差,并且消耗大量的时间,而过长的时间消耗可能导致错过控制谣言传播的最佳时期[6]。在自动提取特征的方法中,许多基于上下文结构的分类算法都使用了神经网络,包括卷积神经网络、长短时记忆(Long Short-Term Memory,LSTM)网络等,但并没有针对非平衡数据进行优化和改进,并且为了获得更好的分类效果,部分算法在完成特征提取后还是会添加手动提取的特征。优化非平衡数据的思路一方面可以针对数据进行加权,另一方面可以提取原始数据的特征,将原始数据映射为一个固定的分布,从而缓解因数据类别之间分布差异过大而带来的问题,同时还能挖掘更深层推文特征的应用空间。
本文设计一种能够自动提取推文特征且无需添加任何额外特征的谣言立场分类算法。该算法引入变分自编码器(Variational Auto-Encoder,VAE),在使用VAE 生成推文特征之前,先执行预处理步骤,再使用gensim 包[7]在word2vec[8]模型上对谷歌新闻数据集进行预训练,将得到的词向量作为VAE 的输入。在此基础上,将推文向量输入到VAE 中进行特征提取,然后使用LSTM 处理得到的深度特征序列并进行分类。
1 相关工作
1.1 谣言立场分类
对推特平台上的推文进行谣言立场分类的任务最早是由QAZVINIAN 等[9]提出的,在这之后人们对这项任务的兴趣逐渐增加。QAZVINIAN 等人基于一个长期存在的谣言对每条推文执行二分类任务(支持或反对),例如在推特上流传许久的巴拉克·奥巴马信仰穆斯林的谣言,其利用过去的推文来训练分类器,然后将其应用于讨论同一谣言的新推文。ZENG 等人[10]也对突发新闻相关的谣言进行了立场分类,其中包括4 个分类,分别是支持、否定、质疑、评论[11](即与事件本身无直接关系的发言),具体的立场示例如图1 所示,该图显示了推特中的一个会话结构,为了便于理解,本文将其翻译为中文形式,但在进行训练和测试时使用重叠的谣言数据。
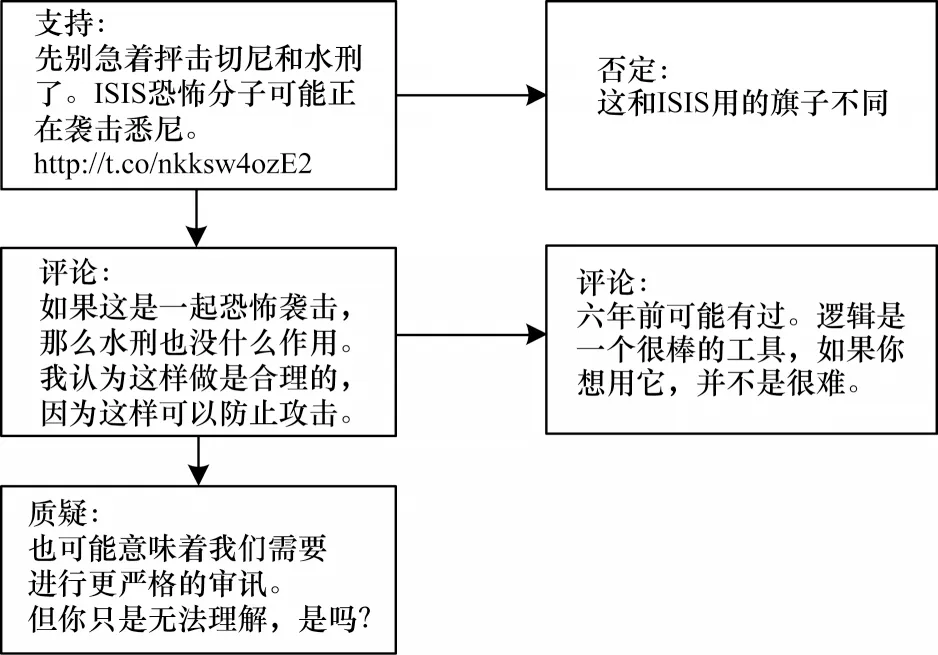
图1 谣言立场示意图Fig.1 Schematic diagram of rumor stance
AUGENSTEIN 等[12]提出的基 于目标的双向LSTM 编码模型,在SemEval-2016 Task 6 数据集上取得了较优的效果,而LUKASIK 等[13]通过霍克斯过程(Hawkes Process,HP)对推文进行基于时间序列的分类,证明了在不考虑对话结构的条件下同时使用推文的文本内容和时间信息的重要性。为了整合推文的时间顺序,LUKASIK 等[14]还研究了高斯过程方法。ZUBIAGA 等对源推文和后续回复的会话结构进行建模,得到线性链和树。该方法使用线性和树状的CRF 分类器,性能优于LUKASIK等[15]提出的方法。KOCHKINA等[16]针对SemEval-2017 Task 8 研究推文会话的分支结构,构建了基于会话分支结构的Branch-LSTM 模型,达到了较优的效果。VEYSEH 等[11]则将时序自注意力引入立场分类中,使用时间轴中相邻的推文作为上下文向量来捕捉用户立场演变中的时间动态信息。
常用的机器学习方法没有针对非平衡数据进行优化,而优化非平衡数据的思路一方面可以针对数据进行加权[17],另一方面可以提取原始数据的特征,将原始数据映射为一个固定的分布,从而缓解因数据类别之间分布差异过大且不平衡而带来的问题,因此,本文引入变分自编码器,将数据映射为高斯分布以提取有效的深度特征。
1.2 变分自编码器
变分自编码器(VAE)是 由KINGMA 等[18]于2014 年提出的基于变分贝叶斯(Variational Bayes,VB)推断的一种深度生成模型。如图2 所示,VAE 包含2 个部分:一个是用于原始输入数据的编码,生成隐变量的变分概率分布,称为编码过程;另一个是根据生成的隐变量变分概率分布,还原生成原始数据的近似概率分布,称为解码过程。
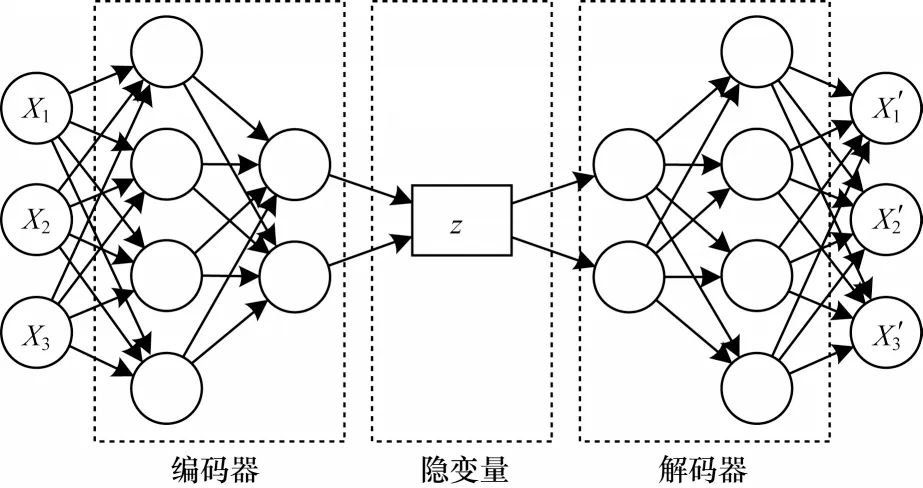
图2 变分自编码器结构Fig.2 Structure of VAE
2 基于VAE-LSTM 的谣言立场分类
针对谣言立场分类中推文序列数据分布复杂且不均衡带来的问题,本文使用VAE 进行深度特征提取,同时使用LSTM 处理时序特征的分类任务。此外,使用dropout 方法[19]防止因数据量少而出现过拟合现象。
2.1 特征提取
在常用的谣言立场分类数据集中,数据在不同类别的分布不均衡,评论类占高达66.18%的比例,这就导致通过从推文向量本身压缩数据提取特征非常困难。因此,针对这一领域的研究大多是通过普通的特征提取后再手动添加特征,如分析发帖人说话时的情绪或者分析推文中携带的表情符号的意义。如果能够让提取的推文特征充分反映输入数据的特征,那么就可以在一定程度上忽略数据量不均衡带来的问题。
与前人提出的方法相比,注意力模型的原理是计算词向量的注意力权重从而使神经网络能够更加关注权重高,即更加重要的向量进行训练,但缺点是一旦重要向量的加权出现偏差就会导致训练的失误,尤其是在没有进行手动添加特征的情况下,因为在可以手动添加特征时,需要依据经验给明确有用的特征分配高权重,并且卷积神经网络模型和自动编码器模型得到的特征都是对词向量简单压缩,并不能很好地表征推文文本。而VAE 作为一个生成模型可以为数据对应的隐变量加上先验,将原始数据转换为服从高斯分布的特征形式,通过采样,最后能获得符合高斯分布的反映输入数据分布特性的特征向量,简单来说就是先预先设定所有特征在4 类分布中服从最符合规律的正态分布,再依据正态分布对这些特征进行训练与采样,当训练出的特征分布最接近正态分布时,就代表模型训练完成。因此,通过对比可以发现,在不手动添加特征的端到端学习中,使用VAE 能够更好地完成任务。
设X是与训练数据对应的随机变量,Z对应为影响数据分布的隐变量。以本文所进行的实验为例,Pθ(Z)表示数据集内各条推文对应深度特征的概率分布,随机变量Z代表单条推文的深度特征,X代表这条推文的文本向量。在训练完成后能得到2 个结果:1)对训练数据的模拟X',即与训练数据同分布的结果;2)VAE 能为数据集中每个数据生成一个隐变量Z。训练和生成的过程如下:基于数据X生成隐变量Z,隐变量Z服从参数为θ的分布Pθ(Z),但由于p(X)和p(Z|X)难以估计,因此使得θ的值难以优化。在这种情况下,VAE 引入qφ(Z|X)来替代无法确定的真实后验分布Pθ(Z|X),并且假设qφ(Z|X)是一个已知的分布形式,是一个对复杂情况的简单估计,通过X得到分布qφ(Z|X)再得到Z的这一过程是编码过程,而通过Z和分布Pθ(Z|X)中得出X′的过程是解码过程。
为了使qφ(Z|X)和真实后验分布Pθ(Z|X)近似相等,VAE 使用KL 散度来衡量两者之间的相似度,并通过优化约束参数θ和Φ使KL 散度最小化,即:
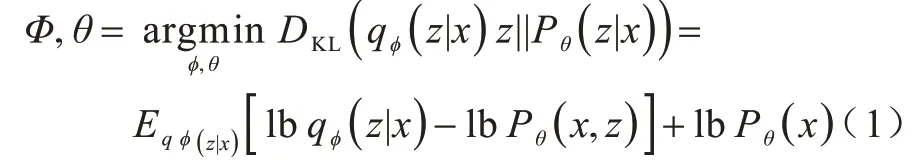
经过计算得到:
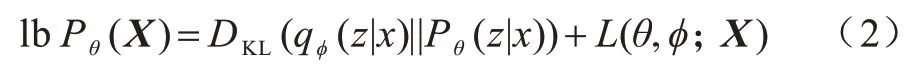
因为KL 散度DKL(*)≥0 恒成立,所以lbPθ(X)≥L(θ,φ;X)恒成立,因此,L(θ,φ;X)被称为集合X对数边际似然lbPθ(X)的变分下界函数。
在这个模型下,从一个分布中采样的过程是离散的,无法求偏导数。为了利用反向传播算法来优化参数,从而简化参数学习过程,本文采用重参数化技巧。最终使用的VAE 模型如图3 所示。
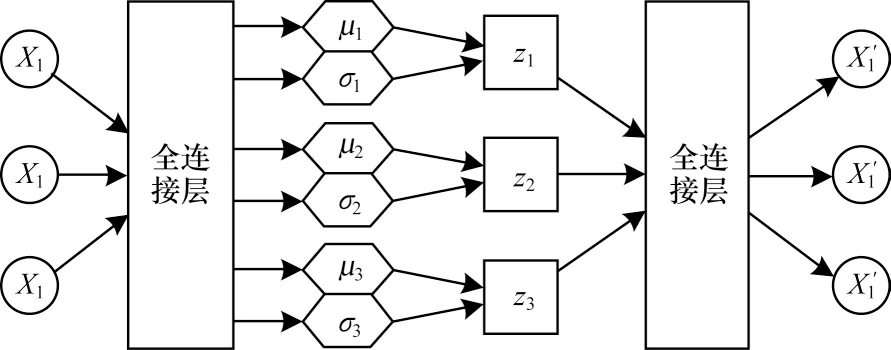
图3 本文使用的VAE 模型结构Fig.3 Structure of the VAE model used in this paper
本文VAE 模型的训练过程为先假设推文的深度特征Z符合正态分布,当损失函数值达到最优时,就代表真实分布极大的接近正态分布,这时得到的隐变量Z就是后续学习所需要的深度特征向量。
2.2 基于LSTM 的序列数据处理
经过VAE 提取,可以得到推文深度特征矩阵,每行代表一条推文,每列则对应每条特征。为了能够更好地处理每条推文的特征序列,本文使用LSTM网络[20]。现有自然语言处理中的情感分类等研究成果表明,在短文本中使用LSTM 方法能够更好地进行学习,而长文本情况下使用卷积神经网络能够减少训练时间。原因是长文本的数据量较大,使用卷积神经网络能够减小参数规模,从而缩短学习时间。在实验使用的推特数据集中,文本最大长度被限制在了280 个字符,而且有相当一部分用户并不会发到280 个字符,所以文本量是不足的,模型需要在较少的文本环境下进行学习判别,因此,本文在学习过程中使用LSTM 网络。
与循环神经网络(Recurrent Neural Network,RNN)相比,LSTM 网络解决了RNN 无法处理长距离依赖的问题。由于RNN 的隐藏层只有一个状态h来保存当前状态的信息,因此RNN 对短期记忆十分敏感,而LSTM 则增加了一个状态c用于保存长期状态信息,所以能够兼顾长短期的信息。两者结构对比如图4 所示。其中:Xt是当前时刻网络的输入值;ht-1是上一时刻LSTM 的输出值;ct-1是上一时刻的单元状态;ht和ct则分别代表当前时刻LSTM 的输出值和当前时刻的单元状态。
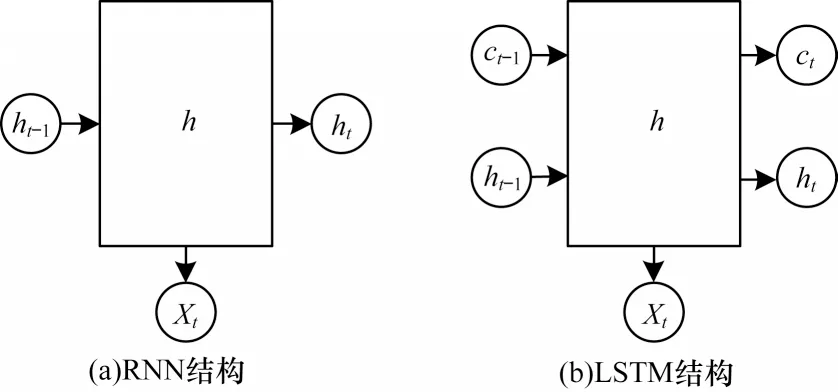
图4 RNN 与LSTM 结构对比Fig.4 Structure comparison between RNN and LSTM
为实现控制长短期信息的目的,LSTM 采用3 个门来控制信息的输送,分别是遗忘门、输入门和输出门。遗忘门决定上一时刻状态信息ct-1有多少保留到当前状态信息ct;输入门决定当前时刻的输入Xt有多少保留到当前状态ct;输出门决定当前时刻状态信息ct有多少传递到当前时刻输出ht。每个门的实现依靠一个sigmoid 函数和一个点乘操作。LSTM 网络结构如图5 所示。
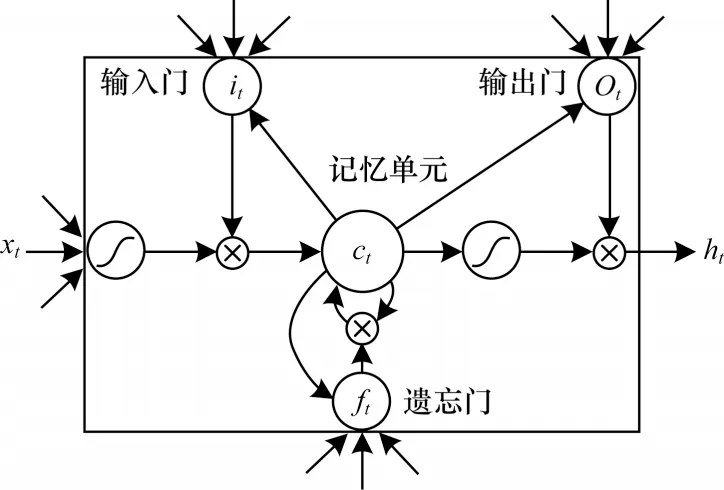
图5 LSTM 网络结构Fig.5 Structure of LSTM network
2.3 VAE-LSTM 模型
考虑到质量较高的带有标签的数据所带来的时间和资金成本,本文采用基于自监督的VAE 模型用于提取推文向量的语句结构特征,该模型是基于自监督的,可以在一定程度内有效减少成本,随着设计的误差函数的损失值不断减少,模型提取向量的特征能力将会越来越强。考虑到推文语句并不是孤立存在的,而是具有上下文语境,这些信息序列含有大量的内容,信息彼此之间有着复杂的语序关联性,为了捕捉到推文语句在上下文的语境信息以及LSTM在机器翻译、语音识别中表现,本文采用LSTM 网络结构。综合上述考虑,本文构建了VAE-LSTM 模型,使用VAE 解决推文的深度特征提取问题,使用LSTM 进行特征向量序列处理。如图6 所示,该模型先向VAE 输入包含推文信息的推文向量,经过VAE模型的训练得到符合真实分布的特征向量,进行叠加后得到全部推文的特征矩阵并输入LSTM 层,利用分类交叉熵损失函数对LSTM 模型进行训练,在通过多个密集的ReLU 层后,再利用softmax 层获得各个类别的概率,同时引入dropout 层来解决过拟合问题。
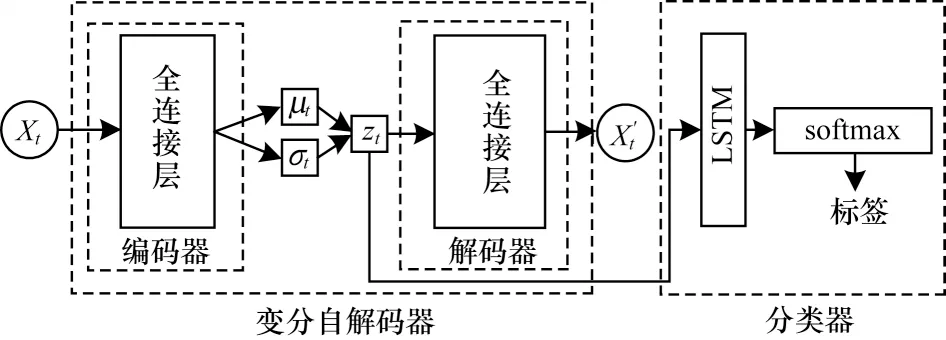
图6 VAE-LSTM 模型结构Fig.6 Structure of VAE-LSTM model
VAE-LSTM 模型具有以下优点:
1)无需额外根据不同事件特点和不同语言习惯添加特征,能够在很大程度上节省人力成本。同时,在新的突发事件发生时并没有足够的上下文信息可以利用,而VAE-LSTM 模型能够只根据单条推文的文本得到较好的分类效果。
2)在得到训练好的VAE 模型后,能够依照先验知识自行“伪造”非平衡数据,交由VAE 编码器进行编码,将编码器得到的特征输入给LSTM 网络进行分类,进一步强化整个模型的分类性能。
3 实验与结果分析
本文实验使用TensorFlow 和Keras 深度学习框架,采用Nvidia Geforce GTX 1660Ti GPU。Batch 大小为32,优化器选择的是Adam,训练次数为100,学习速率为0.005,激活函数使用ReLU。
3.1 数据集
本文实验使用SemEval 2017 Task8.A 数据集,该数据集包含5 568 条标注的推文。数据集中最具挑战性的问题之一是数据极度不均衡,如表1 所示。可以看出,否定和质疑类的数据分别只占总数据的7.45%和8.33%,评论类的数据占比则高达66.18%,虽然这样不均衡的数据分布会在很大程度上影响分类效果,但也符合现实场景,即只有少数用户的发言是和事件相关的,必须在这种不均衡的情况下准确地完成分类任务。
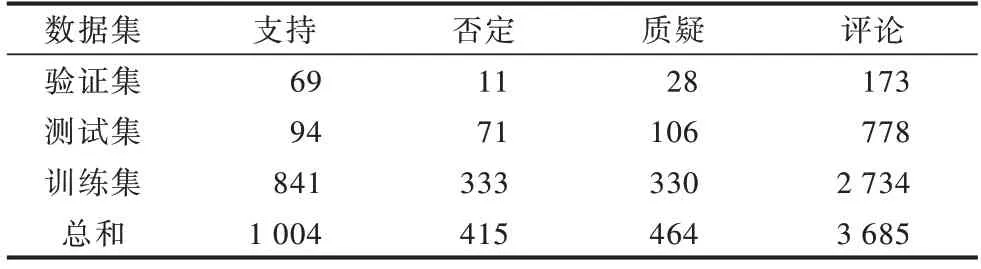
表1 实验中使用的SemEval 2017 Task8.A 数据集Table 1 SemEval 2017 Task8.A dataset used in the experiment
3.2 评价指标
准确性是评价分类器处理多类分类任务性能的一个重要评价指标。但在本文实验中,各类别数据量是不平衡的,在这种情况下,仅基于准确性的评价是不够的,因为一个分类器总是能够预测一个不平衡数据集中数量很多的类别,即使这个分类器在实践中是无用的,也能获得很高的准确率。因此,本文同时使用F1 得分来进行性能评价。
准确率为计算正确分类的数据占总数据的比例,而F1 得分则与召回率和精度有关,精度P的计算公式和召回率R的计算公式如下:

以实验中的支持类为例对Tp、Fp和Fn进行解释:Tp代表的是本身标签为支持且分类为支持的数据数量;Fp代表的是本身标签并非支持但分类为支持的数据数量;Fn代表的是本身标签是支持但并没有分类为支持的数据数量。
F1 得分就是精度和召回率的调和均值,能够在数据量不均衡的情况下取代准确率作为更好的评价指标。F1 得分的计算公式为:

3.3 实验结果对比与分析
3.3.1 与单条推文分类算法的实验结果对比
表2 列出了5 个单推文分类算法在准确率和F1得分上的性能比较结果。由于数据集是不平衡的,大部分属于评论推文,因此多数分类器在准确率方面表现较好,这也表明应基于F1 得分进行再次评估。之前在立场分类方面的工作研究了各种各样的特征,这些特征可以被分为不同种类,如基于语言、基于消息和基于主题包括否定词的使用、标点的信息以及情感等诸多特征。在这一部分的对比实验中,这些分类算法使用了上述的特征进行训练。
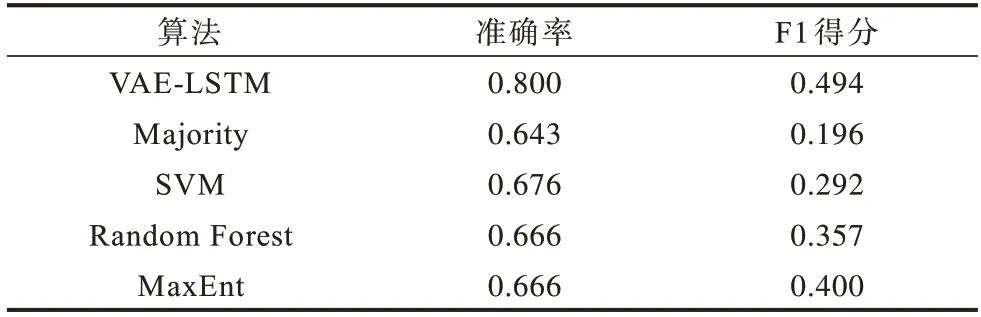
表2 单条推文分类算法的准确率和F1 得分Table 2 Accuracy and F1 score of single-Tweet classification algorithms
表3 列出了按类别F1 得分的性能比较结果。可以看出,分类算法只有在准确率方面表现良好时才会在多数类别上表现良好(评论)。然而,所有的分类算法都很难对否定进行分类,而造成这种情况的主要原因之一是否定类是数据集中的少数类别之一。虽然质疑类推文的数据也很少见,但是一些像问号这样的特性高度表明推文属于质疑类,因此它们更容易分类。
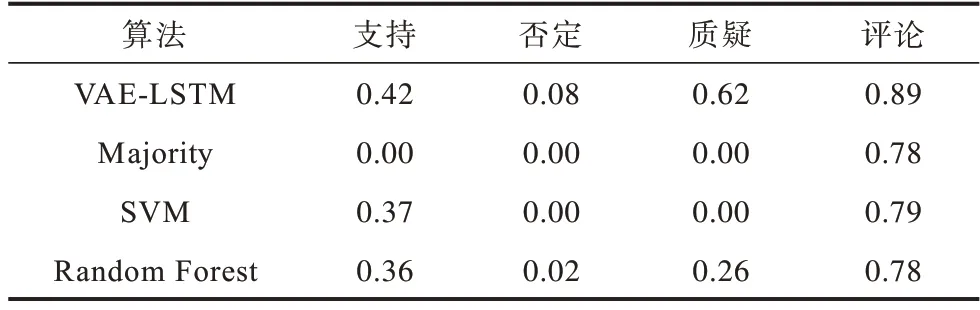
表3 单条推文分类算法各类别的F1 得分Table 3 F1 score of various classes of single-Tweet classification algorithms
3.3.2 与推文上下文分类算法的实验结果对比
将本文算法的实验结果与以下算法进行对比:
1)KOCHKINA 等提出的Turing算法。该算法使用Branch-LSTM 模型,将源推文作为起点统计所有由回复和转发构成的分支结构,再使用LSTM 网络对其进行处理得到每条推文的立场,LSTM 网络每一层的输入是当前分支结构每一条推文的推文向量。
2)ZUBIAGA 等提出的Tree-CRF 算法。该算法通过收集用户对彼此的响应而形成的嵌套的树结构,使用条件随机场(Conditional Random Fields,CRF)作为分类器,并分别测试了线性链CRF 和树状CRF的效果。
3)VEYSEH 等提出的时序注意力机制算法。该算法在经过word2vec 模型提取出词向量之后,对每条推文中的词向量使用注意力机制分配权重,并将权重与推文的矢量表示相乘。将上下文窗口的所有推文向量加权相加后得到一个表示推文上下文信息的向量,然后进行分类。
4)CHEN 等提出的基于CNN 的算法。该算法通过卷积和池化操作对句子向量进行特征提取,利用卷积神经网络中不同大小的过滤器对短文本进行分类。
5)BERT 和LSTM 的结合算 法BERT-LSTM。BERT 是谷歌提出的一种数据处理方法,其通过对语料库中大量语句上下文的理解和学习达到对新文本的特征提取。
6)结 合VAE、CNN 和一个简 单LSTM 网络的VAE-CNN 算法。该算法通过VAE 提取的特征向量传递给卷积神经网络进行分类,将推文的单词向量序列作为LSTM 输入,从而获得分类结果。
上述分类算法与本文算法的准确率和F1 得分对比如表4 所示,各类别F1 得分对比如表5 所示。由表4 可以看出,本文算法在F1 得分上是最优的,而在准确率上相较时序注意力机制低了0.02。在准确性上稍有不足的原因是,时序注意力机制算法更好地提取了上下文信息,能在一定程度上提升准确率。由表5 可以看出,VAE-LSTM 算法在每个类别的分类效果均优于Turing 模型,只有在支持类的结果相较Tree-CRF、BERT-LSTM、VAE-CNN 模型有少许差距。综合来看,VAE-LSTM 算法的效果最好。
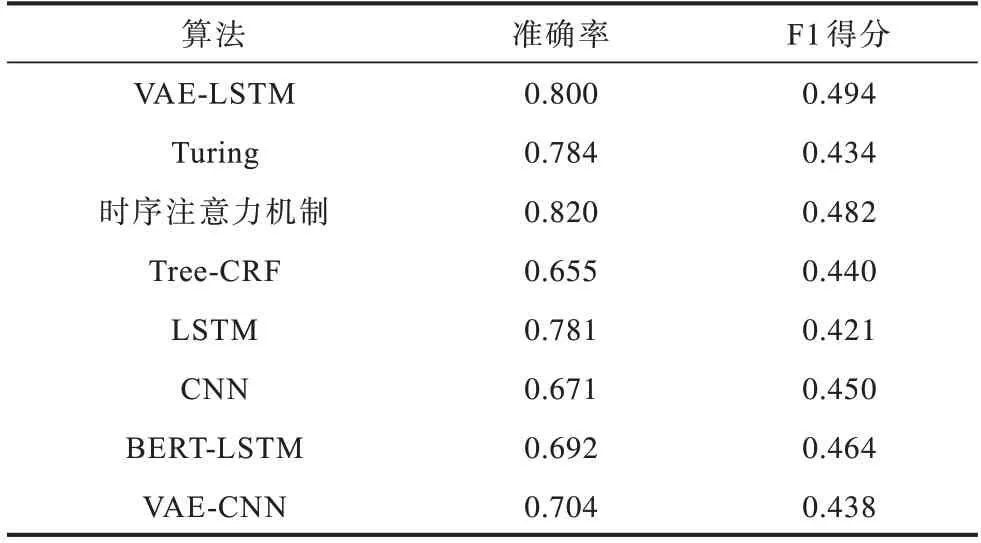
表4 各分类算法的准确率和F1 得分Table 4 Accuracy and F1 score of each classification algorithm
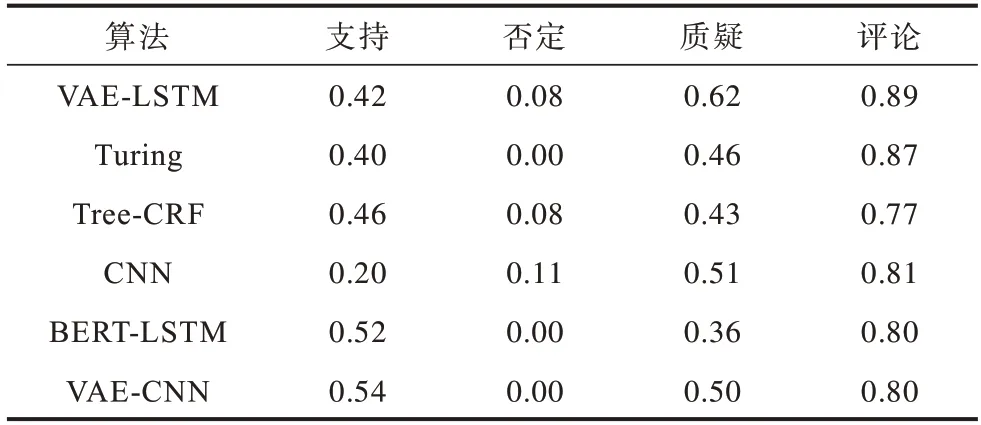
表5 各分类算法各类别的F1 得分Table 5 F1 score of various classes of each classification algorithm
LUKASIK 等提出的HP(Hawkes Proces)算法也是本文选用的对比算法。该算法在训练数据中使用时序信息并使用霍克斯过程对推文的生成进行建模。由于LUKASIK 等在训练数据中只使用4 个主题,并使用留一法进行实验评估,因此这种设置也被用在本文的实验中。表6结果表明,对于Sydney Siege、Charlie Hebdo、Ferguson、Ottawa这4个事件,VAE-LSTM算法在准确率和F1 得分方面都取得了较好的结果。仅有BERT-LSTM 方法在F1 得分上略有优势,这是因为BERT 模型的数据处理方法导致其能较好地进行大量数据的学习,而在其余数据量较少的事件上效果并不好,这点由完整数据F1 得分可以看出。这表明VAE-LSTM 能够在高度不平衡的任务中更好地估计标签的分布,在事件突发时期,这是一个强大的优势,能够利用有限的、不均衡的数据更好地平衡分类。
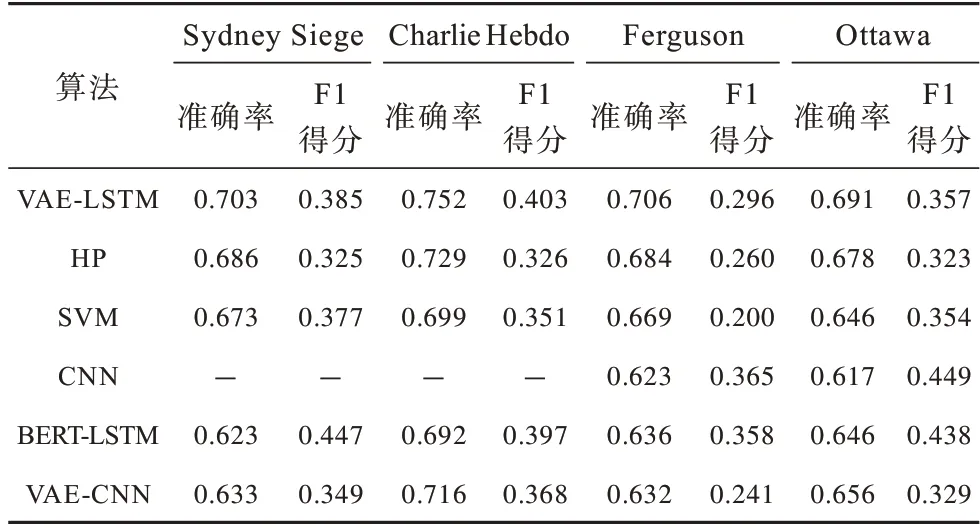
表6 各分类算法针对不同事件的准确率和F1 得分Table 6 Accuracy and F1 score for different events of each algorithm
相较于早期的机器学习方法(如SVM 等),本文方法只是基于自动提取的特征进行实验,并没有手动添加额外的特征,由此节省了前期大量的对数据进行预处理的时间。
4 结束语
本文提出VAE-LSTM 算法,引入变分自动编码器对推文进行深度特征提取,使用LSTM 处理推文特征向量的序列结构。该算法无需根据不同的议论主题和类别进行手工特征提取,因此节省了数据处理时间并具有较好的延展性。此外,本文在VAE 数据特征提取时并不只是对数据以特定规则进行简单的压缩,而是将数据从复杂的概率分布转化成统一的简单概率分布,再从中采样获取有效特征,从而在一定程度上避免数据量较大的推文类别对特征向量的影响。实验结果表明,VAE-LSTM 算法能够获取有效的数据特征,缓解类间不平衡问题,与对比的自动谣言立场分类算法相比具有更高的分类准确性。下一步将借助图神经网络[21]强大的图结构信息提取能力充分挖掘社交网络中语言的结构特性,利用图注意力机制进行权重分配,从而得到更准确的分类结构。
猜你喜欢
环球时报(2022-04-13)2022-04-13
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
科学大众(2020年12期)2020-08-13
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
电子制作(2018年19期)2018-11-14
