
基于R软件对医学研究中多选题的数据清洗与分析
2022-02-22 14:16:20张婷婷李伟郝晓艳
东南大学学报(医学版) 2022年6期
张婷婷,李伟,郝晓艳
(1.南京医科大学附属儿童医院 医务处病案统计室,江苏 南京 210009; 2.南京医科大学附属儿童医院质量管理办公室,江苏 南京 210009)
多项选择题是同一道问题含有两个及两个以上的选项,也称多重应答题。多项选择题的设置常用于流行病学研究中。常见的多选题数据编码方式有二分法编码、分类法编码和原始编码3种[1]。现有文献[1]提及当多选题备选项数目超过9时,转换中使用的语句或软件会发生混乱,给分析带来不便从而限制了研究问卷的设计。目前,基于R软件对多选题进行描述性分析(包括频数分析和列联分析)和假设检验(常用卡方检验)[2]较少,常使用SPSS软件[3- 4]。R软件统计编程环境是开源的,统计分析功能较之SPSS更为强大和灵活,且能使用dplyr、tidyr等软件包[5- 6]。作者主要以某次健康素养调查问卷为例,基于R软件介绍一组多选题原始编码数据转换为二分法编码。
1 材料与方法
1.1 数据来源
2018年江苏省大学一年级学生健康素养调查问卷共包含53题。其中判断题9题,单选题26题,多选题17题(不包含情景题中多选题),情景题1题(含单选题3题、多选题1题);每道多选题均设立5个备选项(1、2、3、4、5)。调查对象所选答案以字符串形式依次录入Excel文件中。
1.2 多选题数据转换
在多选题原始编码中,设置多选题为变量var,按调查对象的选择顺序连续录入被选中的编码,以“,”分开编码,如1,2,3。将多选题的每个备选项对应转换为新变量var1,var2……varn。在原始编码变量var中,调查对象所选答案所对应的新变量值记为“1”,未选中的值记为“0”,即多选题所有备选项均转化成“是”与“否”的二分类问题[7]。
1.3 统计学处理
软件使用与下载:使用R i386 4.0.4 for Windows和R Studio V1.4.1106。使用read.csv()函数将原始数据导入R软件,建立数据对象表。主要运用dplyr等软件包进行数据转换和分析,转换多选题编码方式的操作语法更为灵活[8]。多项选择题数据经转换后,即可对新变量进行统计描述和统计推断。
2 结 果
2.1 数据预处理
在多选题编码转换前,先检查数据框中缺失值信息,并对其进行恰当的处理。简易处理缺失值的办法通常包括缺失值删除、缺失值填补[9]。本数据共有48个缺失数据,对其类别及产生原因进行识别和判断。语句“md.pattern(sy)”识别缺失数据的模式。使用aggr(sy, prop=F, number=F)对缺失数据进行可视化处理。本案例属于随机缺失模式,可以删除含缺失值样本所在的行,“na.omit(sy)”即可实现此功能。
2.2 多选题编码转换
本研究以“SY01”题为例进行转换,使得“SY01”题最终转换为二分法编码数据。
第一步,生成一组新变量。将“SY01”列分列生成“v1”“v2”……“v5”列,调查对象所选选项按顺序依次分入各列,例如id为5402的调查对象的选项为“1,3”,该对象第1个填写答案为“1”,则“v1”的值记为“1”,第2个填写的答案为“3”,则“v2”下记为“3”,再无其他选项,“v3~v5”缺失,缺失值记为“NA”,见图1。对应的语法:

图1 separate()函数对变量“SY01”分列后结果
separate(SY01, paste0(“v”, 1∶5), remove=F)
第二步,实现新变量行列互换。创建一个新变量“V”,将“v1~v5”列变量换至新变量“V”下;另创建新变量“val”,每个id在“v1” ~“v5”的值随之对应入“val”变量中,将列数据回归到行中。同时删除第一步 “val”变量中产生的缺失数据所在的整条记录,最终保留每个样本选择的答案详见图2。R语句为:

图2 gather()函数对“v1~v5”列数据回归行数据后的结果
gather(V, val, v1∶v5)
na.exclude()
第三步,对所选答案赋值为“1”。为方便区分,将“val”的每个字符串前加上“SY01_”,并对变量“V”重新赋值为“1”,此步骤可实现调查对象所选答案赋值为“1”。对“val”变量进行分列,变量“V”的值随之对应入各列。5种答案将按顺序分为5个变量,所选答案下为“1”,未选择的答案下记为“NA”。该步语句为:
mutate(val=paste0(“SY01_”, val), V=1)
spread(val,V)
第四步,填充缺失值。使用mutate_at()函数对缺失值赋值为“0”,最终转换后效果见图3。此时,所选答案记为“1”,未选答案记为“0”,完成原始编码向二分法编码的转换。句法结构:

图3 mutate_at()函数对缺失值重新赋值
mutate_at(vars(SY01_1:SY01_5),.funs=list(~replace(.,is.na(.),0)))
至此完成对“SY01”多选题原始编码数据向二分法编码数据的转换。在进行转换前需下载及加载“dplyr”“stringr”“tidyr”软件包。
利用dplyr包的管道函数“%>%”简化过程,管道函数的作用是将左件的值发送给右件的表达式,并作为右件表达式函数的第一个参数,省略中间的赋值步骤,大量减少内存中的对象。
原始编码向二分法编码转化过程代码如下(#为注释):
# 读取文件
sy<- read.csv(“E:/Lenovo/Documents/sy.csv”,header=TRUE,sep=“,”)# E:/Lenovo/Documents/为文件所属路径。
# 安装软件包
install.packages(“dplyr”)
install.packages(“stringr”)
install.packages(“tidyr”)
# 加载包
library(“dplyr”)
library(“stringr”)
library(“tidyr”)
# 编码方式转换
sy<- sy%>%
+separate(SY01,paste0(“v”,1:5),remove=F)%>%
+gather(V,val,v1∶v5)%>%
+na.exclude()%>%
+mutate(val=paste0(“SY01_”,val),V=1)%>%
+spread(val,V)%>%
+mutate_at(vars(SY01_1:SY01_5),.funs=list(~replace(.,is.na(.),0)))
2.3 多选题数据初步分析
完成编码转化后,使用“table()”“prop.table(table())*100”语句进行描述性分析,结果见表1。8 763例样本,共选择了24 341个答案。SY01_1被选择的频数最多,占35.926%(8 590/24 341);SY01_5最少,占0.296%(72/24 341)。可以发现频数差异较大,查看列联系数和卡方检验确定选项独立性。χ2值为35 685,P<0.001,列联系数为0.67。因此选项间具有相关性,可进一步挖掘选项间相关关系。
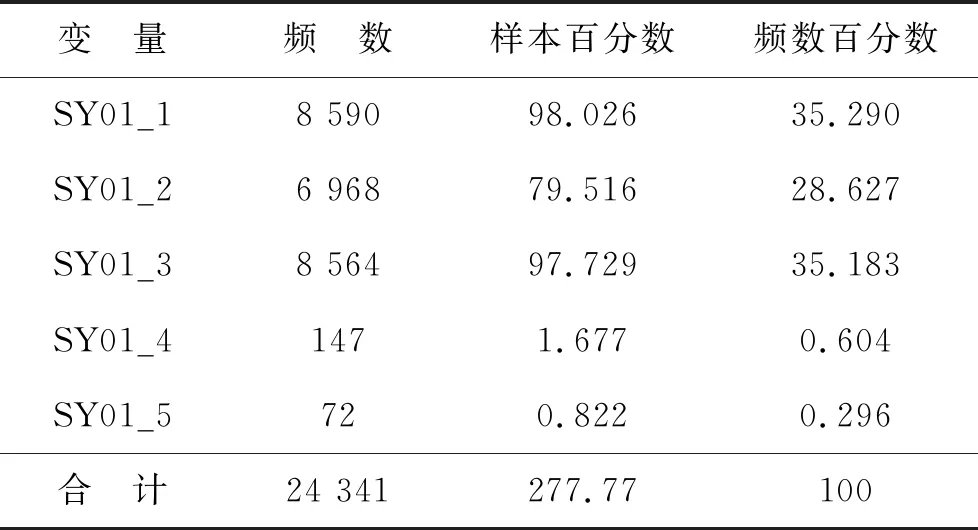
表1 SY01的频数分析
3 讨 论
本研究以江苏省高校新生健康素养调查问卷(2018年)为例,介绍了基于R软件进行多选题的数据清洗、编码方式转换和初步分析方法。调查问卷中设计多项选择题的目的是为了获取准确、全面的信息。由于其复杂性,难免存在缺失数据,采用本研究所叙述的多选题编码转换代码前,需对数据中缺失值进行有效处理。本研究选择删除含有缺失数据的样本,是因为经过判断,缺失类型属于完全随机缺失,即使删除也不会造成偏倚[10]。针对缺失数据的处理需要谨慎对待,本研究尚未提出针对缺失数据新的处理办法,这是本研究的缺陷所在,仅依据判断缺失机制[11]及方法的简便性而选择处理手段;若遇到缺失数据较多或经判断不可轻易对其删除,并且删除会造成信息缺失的情况下,可根据选项比例或者选项组合模式进行填补[12],亦或是采取其他填补方式。但是无论采取何种处理方式,都要保证转换前不包含缺失数据。
不同的编码形式和数据转换是为了高效、准确地分析数据,挖掘更多的信息。本研究采用的软件包解决了多选题数据编码之间的转换问题,与使用基本R函数处理的方法[13]相比,句法结构更简便。此外,先前的研究[1,7]中,无论是采用SAS软件亦或是R软件对多选题编码方式转换中,条件限制较为苛刻,备选项数目不能超过9,显示当多选题备选项数目超过9时[1],使用其他语句或软件会发生混乱,比如“1”与“11”产生的新变量都会转换成“val1”;封永昌等[13]使用基本R函数进行转换时,是将“10”及“10”以上的选项转换成单字母“a”“b”……,替代原始编号,虽然使得超过9个选项的多选题也能被转换为二分法编码,无论是录入方式,还是基本R函数代码都比较复杂,处理难度较大;而本研究代码则无需作特殊转换,录入原始编码时直接输入相应编码,如“10”“11”等,均以“,”分隔即可,如选择“1”“3”“11”3个选项,原始编码输入“1,3,11”。此外,在原始编码录入时,原始编码数据需要严格依从小到大的顺序录入,且代码循环复杂程度较高,而本研究中所使用的方法,即使录入时没有按从小到大的顺序输入,对转换过程也没有影响,克服了先前研究的多种复杂问题。综合来看,本研究使用的方法实用性更强、更加简洁,且利用了3个功能强大的软件包,数据操作的运行时间尤其是分组计算的时间更短。在大样本调查中,往往需运行的数据样本量及变量数庞大。样本含量越大时占用内存越多,采用本研究介绍的R软件包可大大提高计算效率[8]。“dplyr”“tidyr”和“stringr”这3个软件包联合使用有强大的数据清洗能力,在行列互换、计算和字符串的拼接方面的贡献不容小觑[14]。
文献中常将各选项作为二分类变量进行统计描述和假设检验,较少有文献研究选项间相互影响。某些选项的特殊组合是否会导致另一个选项不被选择,也是值得探讨的问题。因此,不去挖掘多选题选项间的信息,造成了信息的浪费。有文献提示二分法编码后每个选项可用来构建回归模型、广义线性模型等[15]。
本研究不足之处:未能提出多选题二分法编码转后系统的分析思路与步骤,只提出是否应探讨多选题各选项间影响关系的假设,需更深层次地挖掘多选题后续分析方式,提出更加系统且全面的多选题处理方案。
猜你喜欢
中国交通信息化(2021年1期)2021-06-11 01:23:44
中学生数理化·自主招生(2021年3期)2021-05-30 10:48:04
中学生数理化(高中版.高考理化)(2021年3期)2021-05-21 02:10:20
新世纪智能(数学备考)(2020年9期)2021-01-04 00:25:06
中学生数理化·七年级数学人教版(2018年3期)2018-05-30 06:58:16
时代英语·高一(2017年5期)2017-11-14 23:23:40
时代英语·高三(2017年4期)2017-08-11 23:17:42
时代英语·高一(2017年4期)2017-08-09 01:07:41
试题与研究·中考英语(2016年3期)2017-01-05 12:47:17
现代检验医学杂志(2014年5期)2014-02-02 02:51:46
