
基于改进的SVR-GRNN风暴潮灾害损失组合评估模型
2022-02-22 08:29贾丙宏
北京测绘 2022年1期
贾丙宏 杨 帅 冉 姝
(1. 山东科技大学 测绘与空间信息学院, 山东 青岛 266590; 2. 济南市勘察测绘研究院, 山东 济南 250000; 3. 山东省巨野县委宣传部, 山东 菏泽 274900)
0 引言
风暴潮是由热带气旋或温带气旋等气象条件在海洋表面的切向风应力推动海水淹没陆地的过程[1]。我国东南沿海是世界上风暴潮灾害最严重的地区之一,全球约三分之一的台风来源于西北太平洋,我国东南沿海位于西北太平洋台风的主要移动路径上[2]。因此,一定的地理因素导致我国东南沿海长期遭受台风风暴潮。其中,浙江省是我国损失最严重的省份之一。据《中国海洋公报》统计,2019年各类海洋灾害中,最严重的为风暴潮灾害,占总直接经济损失的99%。其中,最严重的省是浙江省,达到了87.35亿元。中央财经委第三次会议上,习近平总书记对海洋防灾减灾工作作出重要指示,明确提出要“提升抵御台风、风暴潮等海洋灾害能力”[3]。积极响应国家战略,及时、准确地评估风暴潮灾害造成的直接经济损失,对减灾政策的制定具有指导意义,根据损失的程度和大小确定灾后补偿和重建的力度,能为灾后的救助工作提供强有力的理论依据和数据支持。
近年来,风暴潮灾害损失评估越来越受到重视,相关的科学研究也越来越多,投入产出模型、灰色模型(Gray Model,GM)[4]以及神经网络等方法被广泛利用。但这些评估方法精度较差,有待优化,并且结构单一,一个模型只能反映整个风暴潮系统特征的部分信息,组合模型的研究较少[1]。鉴于此,本文提出了基于麻雀搜索算法优化的SVR和GRNN组合模型,对风暴潮灾害造成的直接经济损失进行评估。
1 数据源和指标筛选
1.1 数据源
本文选取1990—2020年浙江省记录完整的29个风暴潮历史灾情数据作为数据集。风暴潮灾害资料主要统计于《中国海洋灾害公报》[5]、《中国风暴潮灾害史料集》[6]、国家减灾中心统计数据和浙江省统计年鉴[7]。
1.2 指标选取
本文充分考虑风暴潮灾害的形成机理、灾害系统理论和风险管理理论,从致灾因素、孕灾背景、承灾体脆弱性和防潮减灾能力4个方面选取指标建立风暴潮灾害损失评估指标体系,如图1所示。
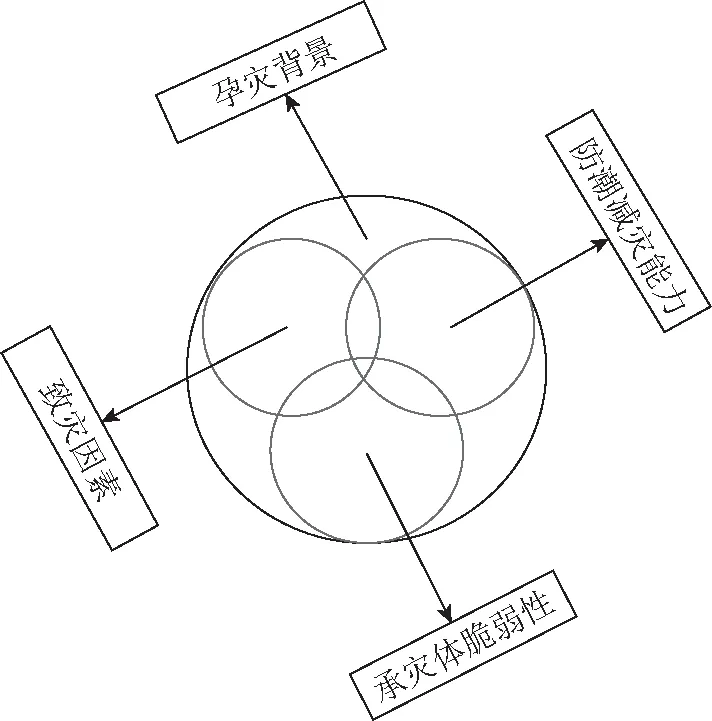
图1 风暴潮灾害损失评估指标体系
1.2.1致灾因素
风暴潮灾害是由严重大气扰动引起的海水异常升降淹没陆地的现象[1],最大增水量和潮位变化是最直接的标志。于是,选取相关性较强的中心最大风速Z1、登陆中心气压Z2、最大风暴增水Z3、最大超警戒潮位Z4作为致灾因子。
1.2.2孕灾背景
受灾地区的地形地貌等因素与风暴潮造成的损失有较强的相关性,并且人口密度等指标也与损失程度息息相关。根据指标的可量化性,选择了农业产值Z5、渔业产值Z6以及人口密度Z7指标。
1.2.3承灾体脆弱性
该类指标反映了受灾体的抗损失能力。在风暴潮灾害的承灾体中,受影响的农田、人口以及海洋工程的破坏是比较直观的。因此,本文以农田受灾面积Z8、受灾人口Z9、房屋倒塌Z10、水产养殖受灾面积Z11、防护工程损毁Z12以及船只损毁Z13作为评估指标。
1.2.4防潮减灾能力
以往的研究中经常忽视防灾减灾这一维度的指标,实际上,近年来国家很重视风暴潮的防御以及防护工程的建设。防灾能力可以减少经济损失,帮助灾后的生产恢复。鉴于这一维度的覆盖面极广,选取每千人配比床位数Z14、医药卫生单位数Z15、人均国内生产总值(Gross Domestic Product,GDP)Z16、人均储蓄存款Z17、城镇人均可支配收入Z18、农村人均可支配收入Z19以及财政总收入Z20作为指标因子。
1.3 指标预处理
从4个维度选取的20个指标因子间存在相关性,易出现信息冗余,需要进行科学筛选。本文利用熵权法[8]对指标因子进行处理,熵权法是根据各因子的变异程度,计算出熵值,确定各个指标间的离散程度。具体步骤如下:
(1)通过归一化处理,消除掉单位不统计问题,并使得不同量级的指标亦能进行衡量。
(1)
式中,xij为第i个样本的第j个指标的原始数值;yij为第i个样本的第j个指标标准化后的数值(i=1,2,…,n,j=1,2,…,m)。
(2)计算第i样本在第j项指标中的占比
(2)
(3)计算熵值
(3)
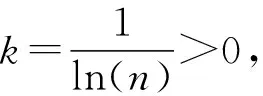
(4)计算信息熵冗余度
(4)
(5)计算权重值并排序
(5)
根据以上步骤,将计算得到的各指标权重值由大到小进行排序,如表1所示。从中筛选出权重值累计贡献率85%的指标,最终将{Z4,Z5,Z6,Z8,Z9,Z11,…,Z20}作为评估模型的指标输入量,在表1中用方框标出。
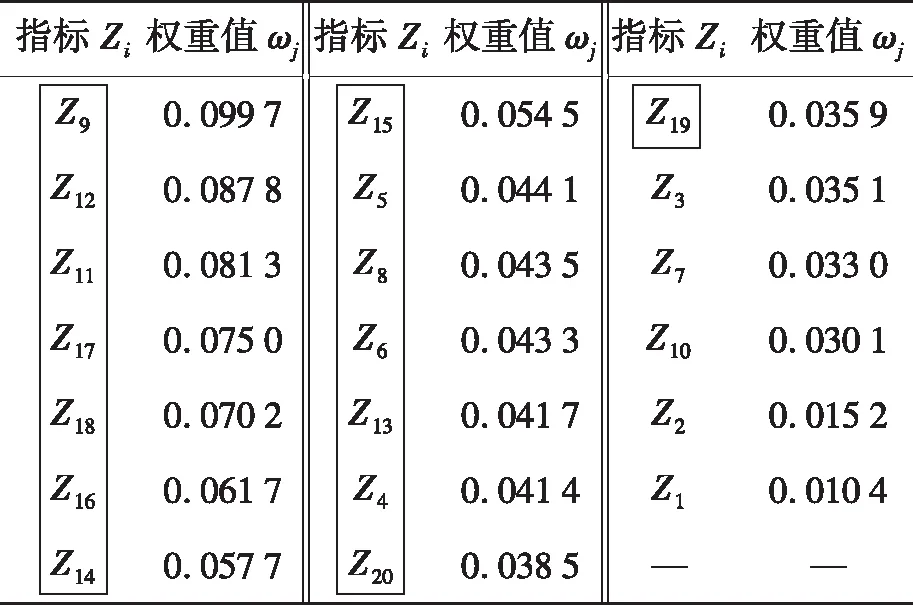
表1 指标权重值排序结果
2 组合评估模型
2.1 评估模型2.1.1 支持向量回归
支持向量机(Support Vector Machine,SVM)是基于统计学习理论构建的一种新型机器学习方法,根据应用方面不同分为:支持向量分类(Support Vector Classification,SVC)和支持向量回归(Support Vector Regression,SVR)。基于交叉验证(Vapnik-Chervonenkis,VC)维数理论和统计学习理论中的结构风险最小化原理,支持向量机最终转化为二次优化问题[9]。SVR的优点是用于小样本预测问题具有较好的效果,本文利用支持向量机解决回归问题,其基本思想是寻找某个最优分类面使得样本距离该分类面的误差最小[10],如图2所示。原理是将原始空间样本数据投影到高维特征空间中,核函数进行非线性转换和映射。核函数选择径向基(Radial Basis Function,RBF)核函数:

图2 SVR基本思想示意图
(6)
式中,x表示输入空间的样本;xi表示第i个样本;σ为均方差,RBF核函数能够通过调节σ值调整核函数,具有较高的灵活性。
图2中,ε表示能够容忍的模型输出值与真实值的最大偏差;δ为偏差绝对值大于ε时产生的损失。
2.1.2GRNN
神经网络具有强大的非线性拟合能力,广义回归神经网络(Generalized Regression Neural Network,GRNN)[11]是由Specht教授于1991年提出基于非线性回归理论的人工神经网络模型,具有良好的非线性逼近性能,一般由4层网络结构组成,分别为输入层、模式层、求和层和输出层,如图3所示。图3中,GRNN结构的模式层和输出层用不同的样式符号进行区分。GRNN的优势在于其方便的网络参数设置功能,只需调节一个平滑参数Spread即可建立预测模型,增加人为可控性。Spread的大小直接影响了整个网络模型的评估性能,Spread越大,函数逼近越平滑;Spread越小,函数拟合性能越好。基于拟合能力以及样本数量的考虑,本文采用四折交叉验证的方法来确定最佳Spread值。
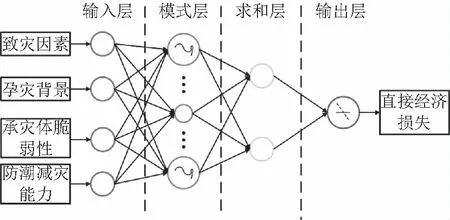
图3 GRNN结构示意图
2.2 优化算法
神经网络算法通过构建更广泛、更复杂的学习网络来拟合多维变量之间的复杂非线性关系,可以提高损失评估的精度。然而,样本数据少,收敛速度慢等问题也造成了风暴潮灾害研究效率和精度上的障碍。研究表明,采用优化算法对初始参数进行优化后再对网络进行训练能在很大程度上提升网络性能,避免网络拟合缺陷[12]。
SSA[13]是基于麻雀的群体智慧、觅食行为以及反猎食行为建立的群搜索算法。其生物原理为:麻雀群为寻找食物分为发现者与加入者两类,发现者负责标记食物方向,加入者追随发现者的食物信号,一旦麻雀中的警惕者觉察到危险,会立即变化位置。依据这一原理,麻雀能够获取食物并躲避攻击。
2.3 优化评估模型2.3.1 SSA-SVR
SVR进行建模时,惩罚参数(C)与核参数(g)对模型的性能有着重要的影响。利用麻雀搜索算法对该参数进行寻优计算,可以提高SVR的网络性能,减少评估误差。具体优化流程如图4所示。
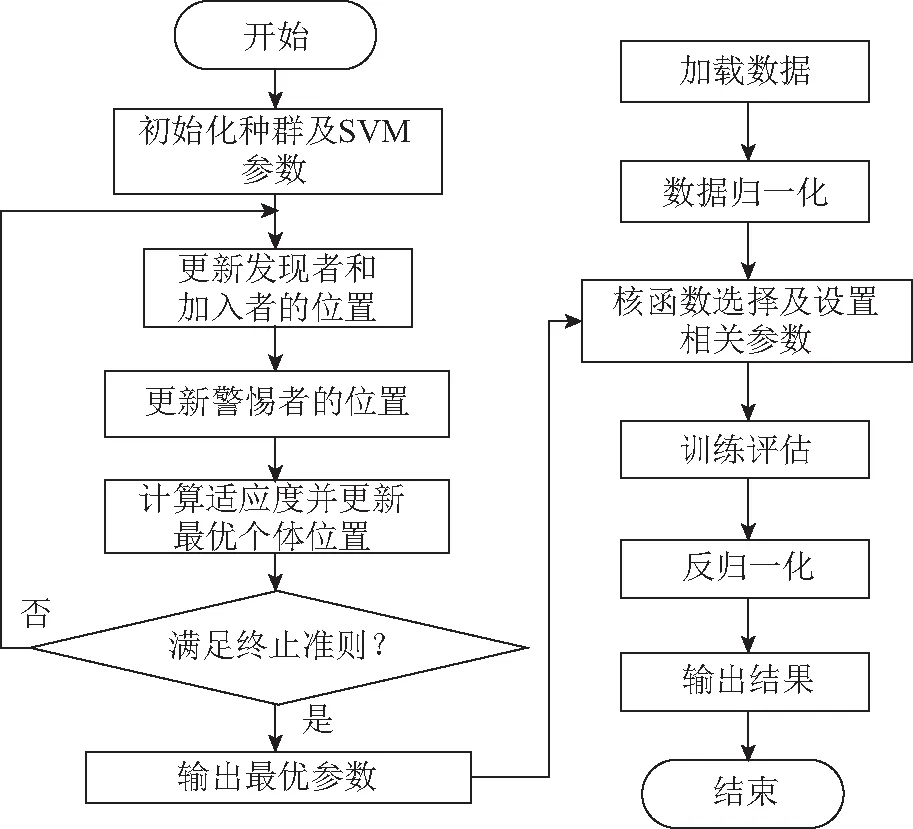
图4 SSA-SVR评估模型流程图
2.3.2SSA-GRNN
根据GRNN网络模型的原理,只需要调节一个平滑参数Spread就可以影响整个网络的性能。本文利用麻雀搜索算法主要对GRNN的Spread参数进行优化,设计适应度函数。优化评估模型结构如图5所示。
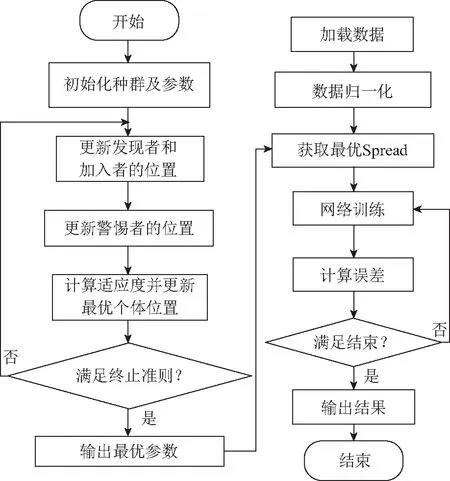
图5 SSA-GRNN评估模型流程图
2.4 组合评估模型的建立
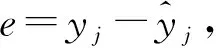
(7)
式中,n为风暴潮样本的个数;m为评估模型的个数;eij为第i个评估模型中第j个样本的误差值;∑wi=1,wi≥0。
3 实验与讨论
本文收集整理了浙江省记录完整的29个风暴潮灾害样本,依次利用其中的28个样本训练预测剩余的一个样本的直接经济损失值,以此来提高小样本评估测试的说服力。15个筛选指标作为输入因子,直接经济损失为输出因子。以MATLAB 2018b为平台进行实验,决定系数R2、均方根误差(Root Mean Square Error,RMSE)以及希尔不等系数Theil IC检验评估模型的性能,公式如下:

3.1 单一模型实验结果
鉴于文本样本数量29个,输入因子维度为15,模型搜索过程不太复杂,麻雀搜索算法的初始规模设置为30、最大迭代次数30,其他设置如下:发现者的数量占比0.7、感应危险的麻雀数量占比0.2、安全值为0.6。实验结果如下:SSA-SVR模型R2值为0.847 3,拟合结果如图6所示;SSA-GRNN模型R2值为0.882 8,拟合结果如图7所示。
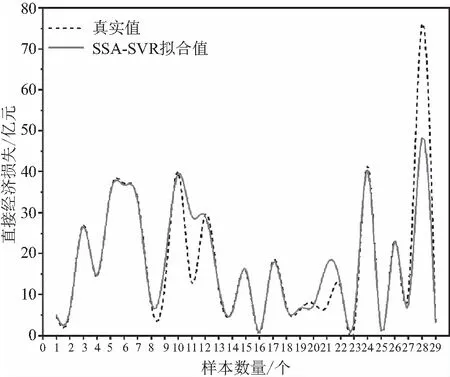
图6 SSA-SVR模型拟合图
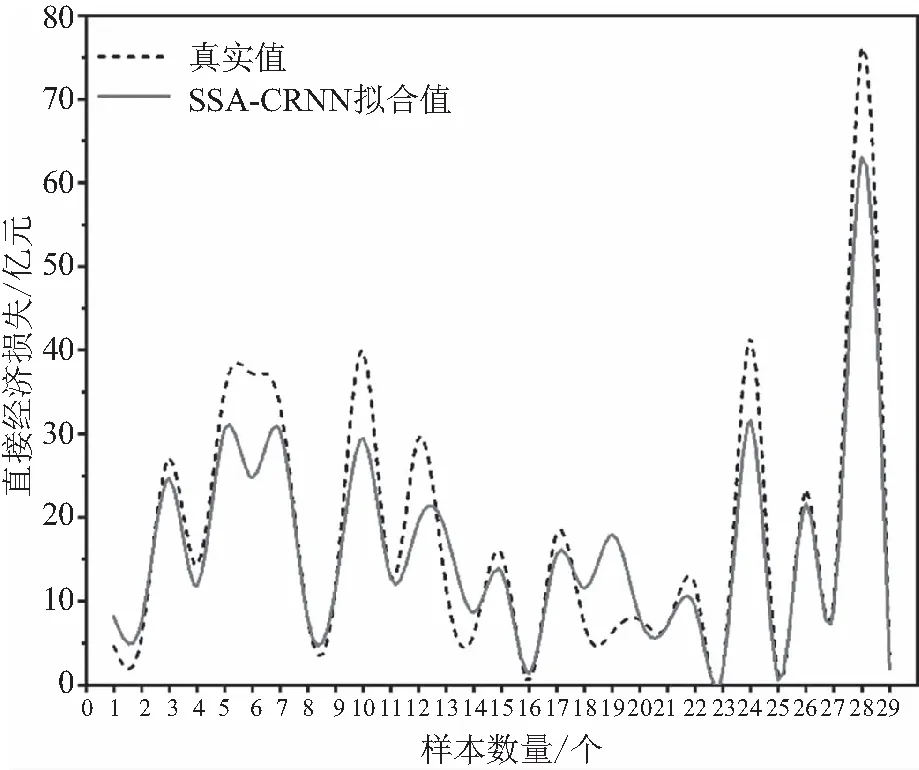
图7 SSA-GRNN模型拟合图
3.2 组合评估模型
对比图6和图7可以看出,SSA-SVR中第11和28号样本的直接经济损失评估出现较大的偏差,SSA-GRNN模型的评估稳定性要优于SSA-SVR,但SSA-SVR在其他点的精度上要优于SSA-GRNN。于是可以根据优势互补将两个模型建立组合评估。
利用最小二乘法将SSA-SVR与SSA-GRNN模型进行最优加权组合,计算所得权重系数w1、w2分别为0.39、0.61,则组合评估模型的表达式可以写作:
(11)
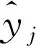
然后将组合模型进行实验拟合,R2值为0.919 0,拟合结果如图8所示。并利用ERMS、CI指标进行精度对比如表2所示。

图8 组合评估模型拟合图

表2 不同模型精度对比
对比单一模型与组合模型的拟合图以及精度评价指标,可以看出,经过最优组合后的评估模型在精度上有所提高,同时也证明组合评估模型在风暴潮灾害损失评估中的适用性。
4 结束语
为了更好地评估风暴潮灾害,本文从致灾因素、孕灾背景、承灾体脆弱性以及防潮减灾能力4个维度建立全面系统的风暴潮灾害损失评估指标体系,使用熵权法来进行指标筛选预处理,筛选出涵盖信息多、权重高、相关性大的10个指标。利用麻雀搜索算法对SVR和GRNN两种评估模型进行优化改进,并将优化后的模型基于最小二乘法建立最优加权组合,将组合评估模型与单一模型进行了实验对比,结果显示:SSA-SVR、SSA-GRNN、组合评估模型的R2值分别为0.847 3、0.882 8、0.919 0;ERMS分别为6.461 3、5.660 4、4.990 2;CI分别为0.139 8、0.127 4、0.111 2。表明组合模型可以有效地从多个模型中收集有用的信息。因此,其评估精度、评估稳定性和对动态系统变化的适应能力远高于单一模型。
风暴潮是非常严重的海洋灾害,危机人民的生命和财产安全。因此,全面研究风暴潮对尽可能减少灾害损失具有重要意义,然而,有限的历史灾情数据可能对风暴潮灾害评估提出了挑战。未来,采用新的评估指标(例如登陆城市的地形要素等),利用新的分析工具(例如地理信息系统、遥感等)可能会在这项研究中发挥重要作用。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
智能计算机与应用(2018年3期)2018-09-05
环球时报(2017-08-14)2017-08-14
电脑知识与技术(2016年30期)2017-03-06
文理导航·科普童话(2016年7期)2017-02-04
紫光阁(2016年4期)2016-11-19
学苑创造·A版(2009年6期)2009-12-07
