
基于机器学习的移动客服终端运维状态自主感知方法
2022-02-21 01:38王旭勇
通信电源技术 2022年22期
王旭勇
(深圳供电局有限公司,广东 深圳 518000)
0 引 言
移动客服终端的运维状态将直接影响用户对企业服务的评价,进而影响企业的营销绩效[1]。在企业日常的经营管理过程中,感知移动客服终端的运维状态并监测其各项基本功能是否正常运行是1项十分重要的工作内容。目前关于设备状态感知的研究成果较多,但是应用客服终端运维状态感知的相关内容较少。文献[2]针对变压器的状态感知问题,利用信息属性约简技术提升了复杂工况下对变压器状态感知的准确性。文献[3]设计了1种应用于电力生产区域的安全管理状态感知系统,利用生产区域内的传感设备,获取生产设备运行数据进行逼近理想解排序法(Technique for Order Preference by Similarity to Ideal Solution,TOPSIS)分析,保障生产区域安全。对于设备运维状态感知主要是利用模糊理论、概率统计、灰色模型等分析数据之间的关系,确定设备状态。上述方法需要大量的先验样本,无法保证感知效率与感知精度。而机器学习具有良好的学习性,能够减轻对先验样本的依赖。根据上述分析内容,为了确保终端能够正常向用户提供服务,将机器学习算法引入该领域,研究1种基于机器学习的移动客服终端运维状态自主感知方法。
1 移动客服终端运维状态数据预处理
移动客服终端在向用户提供相关服务时,会产生大量缓存数据和终端运行数据,这些数据中包含了为用户提供服务的详细后台数据、用户的反馈信息以及上行指令等。终端中存储的数据日志和终端与服务响应中心管理服务器间的通信数据中含有大量的终端运维状态数据序列,在深入分析终端运维状态数据序列前,需要对其进行基础预处理,以提升感知效率。
为了减少数据量纲对终端运维状态数据序列分析的干扰,使用最大-最小值法将同类来源的运维数据转换为[0,1]区间上的无量纲数据。移动客服终端在运维过程中会随着时间推移持续不断地产生数据日志,导致数据量级较大。经过无量纲化处理后,运维数据的体量仍然较大,难以处理。使用时间窗将终端运维数据分段,得到较短时间内的运维数据。分割终端运维数据的时间窗长度计算公式为

式中:β为时间窗长度的决定参数,取值范围为(0,1];Tp为终端运维状态数据的基础循环周期;T1为终端采集运维状态数据的时间间隔。在数据序列上移动时间窗,保留时间窗内的数据,从而完成按照时间特性对数据序列的分割处理。为了便于对状态数据序列进行处理,将时间窗分割后的数据转换为多维结构形式,并进行兴趣区域识别。
2 终端运维状态数据兴趣区域识别
若分割后的终端状态片段为z、数据维度为d,依据设定的时间窗长度从不同维度观测数据序列,得到多维结构化数据为
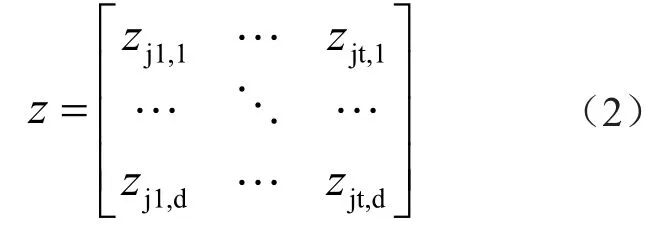
式中 :Zjt,d表示当时间窗分割后的数据序列长度为t时,在维度d下以截片j为基准观测到的终端数据。
由于并非所有的数据均表示终端的真实状态数据,利用聚类算法识别状态序列中的兴趣区间,选择D密度峰值聚类算法(Density Peak Clustering,DPC)与k均值聚类算法(k-means Clustering Algorithm,kmeans)相结合的方式得到状态感知的主要数据兴趣区域。结构化形式的运维数据集为,其中M为运维数据集中的数据点。数据集某一数据点Zi及其邻域数据的局部密度ρi为
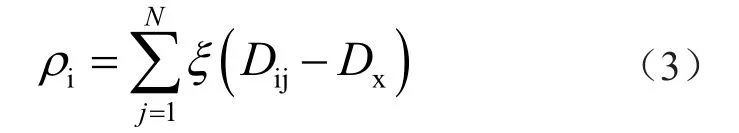
式中:Dx为选定数据截断基准片段后基准片段截断序列的距离;Dij为数据点Zi及其邻域数据点Zj之间的欧式距离[4];ξ(·)为参数函数,其取值表达式为
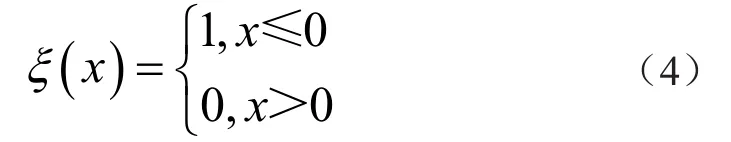
在DPC算法中输入截断距离Dx作为输入参数,预先选择数据序列兴趣区域初步聚类范围。将序列中的所有数据均按照局部密度ρi的大小降序聚类,得到k-means聚类的初始聚类簇。从初始聚类簇中随机选择数据点作为对应簇的聚类中心,使用高斯核函数作为权值计算聚类中心与剩余数据点间的加权欧式距离。按照k-means聚类结果,聚类簇中密度最大的区域即为运维状态感知的兴趣区域。
3 基于机器学习的终端运维状态感知方法
考虑到终端运维数据维度较高,使用机器学习中的卷积神经网络算法分析上文识别的兴趣区域内数据,得到运维状态感知结果。
本研究使用的卷积神经网络由1个输入层、4个卷积层、3个池化层、1个全连接层以及1个输出层组成。其中,输入层节点数量与终端运维数据的维度相同,卷积层的卷积核大小分别为12×12、9×9、5×5以及3×3,池化层交替采用平均池化和最大池化2种方式对输入池化层中的数据进行处理,全连接层将卷积层和池化层在激活函数处理下的数据进行重新加权组装,最终的结果由输出层输出。全连接层中的权重矩阵根据移动客服终端运维指标特征重要性确定[5]。全连接层输出为

式中:fs为激活函数;Wq为权重矩阵;fc(0)为池化层与连接层的偏差函数;bf为输出偏置。
在感知卷积神经网络(Convdution Neural Networks,CNN)中,选用整流线性单元(Rectified Linear Unit,ReLU)函数作为各层计算处理的激活函数。感知CNN各项参数需要经过样本数据训练得到,为实现对设备运维状态的自动感知,对CNN进行如下训练。
由专家给出移动终端运维状态数据特征的权重,建立全连接层中的数据特征权重矩阵。初始化感知CNN中的各项参数,进行前向和后向训练。前向训练中,向感知CNN输入样本数据,根据输出层与样本数据之间的相对误差调整CNN参数。反向训练中,设定样本数据的期望输出E(o),利用似然估计原理计算E(o)与实际CNN输出R(o)之间的误差。根据数据梯度下降速度,动态调整CNN的学习速率。判断感知CNN的训练输出误差是否收敛,若误差收敛则停止训练,确认感知参数。将兴趣区域内的数据输入CNN中,经过卷积、池化处理得到客服终端运维中状态感知数据,从而完成基于机器学习的移动客服终端运维状态自主感知。
4 实验验证
从理论层面对状态感知方法进行研究后,设计实验方案对该方法的性能和应用效果进行验证与分析。
4.1 实验方案设计
为了对所提方法的性能和应用取得的成效进行验证,从状态感知方法的感知效率、状态数据感知误差2个方面对比本文所提感知方法与文献[2]所提方法、文献[3]所提方法的应用表现。
使用相同参数的移动客服终端开展对3种运维状态感知方法的验证实验,共计150个终端。将移动客服终端随机均分为3组,分别记为实验组A、实验组B、实验组C。将客服终端投入实际的使用环境中,通过人工技术处理对实验组内终端的运维状态进行调整,实验组A、B、C中的客户终端每5个进行相同的运维状态人工调整处理。记录人工处理后终端运维状态数据的理论变化值,将该值作为实验结果分析的参考标准。由3种不同的方法分别感知实验组A、B、C中的终端运维状态,并以每5个终端方法的感知数据平均值作为最终的记录结果。根据相对误差计算原理公式,计算实验组A、B、C终端状态感知结果与参考标值之间的相对误差。通过指标数据的分析,衡量本文所提出感知方法的应用效果。
4.2 实验数据分析
使用3种不同的终端状态感知方法对实验组A、B、C中的终端运维状态进行感知,得到各个方法的感知结果与设定的标准参考值之间的相对误差如表1所示。为7.8%;文献[2]所提方法的感知相对误差最高为27.9%,最低为19.8%;文献[3]所提方法的感知相对误差最高为29.7%,最低为21.8%。基于机器学习的感知相对误差上下限之间的范围更小,说明该方法对于终端状态的感知更加精准。
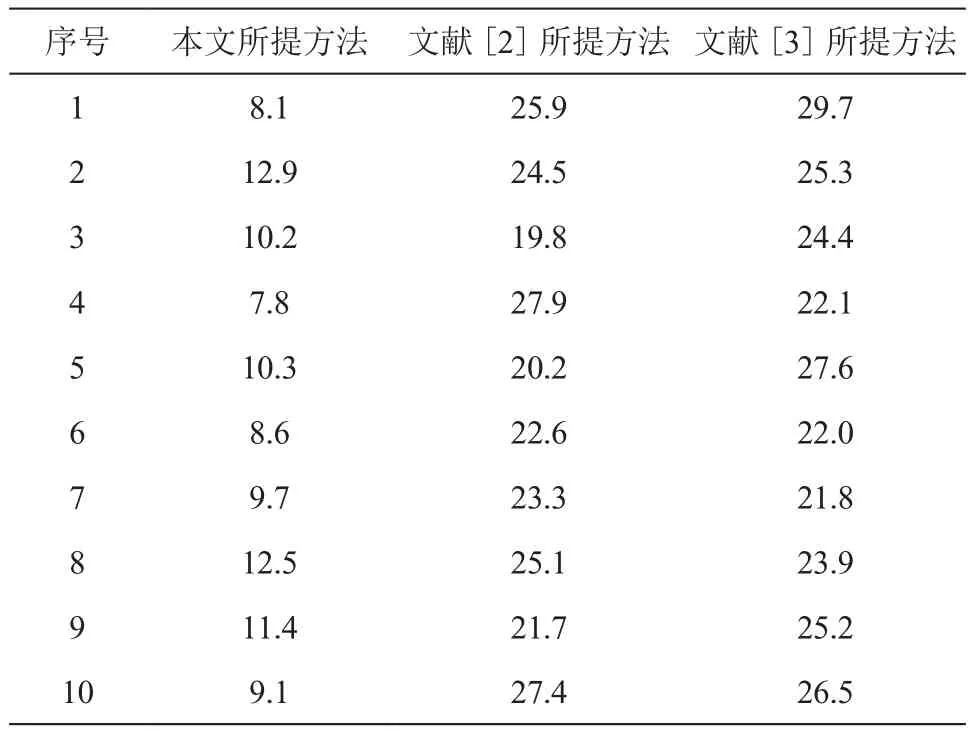
表1 终端运维状态感知相对误差 单位:%
计算表1中各方法的感知相对误差平均值,本文所提方法的感知平均相对误差为10.06%,文献[2]所提方法的感知平均相对误差为24.09%,文献[3]所提方法的感知平均相对误差为24.28%。相对误差数值分布越均衡,表明感知方法对不同情况下的终端运维状态都有较为稳定的感知结果。从各方法感知相对误差范围的中间误差数值波动来看,文献[2]方法相对误差中间值波动幅度较大,误差数值分布不均衡。本文所提的感知方法相对误差中间数值分布更均衡、误差上下限更小,说明对终端状态的感知可靠性更高。
随机从实验组A、B、C中的客户终端抽取同参数的10个终端,人为动态改变终端的运维状态。使用3种方法同时对终端状态变化进行感知,得到如图1所示的方法感知响应效率曲线。
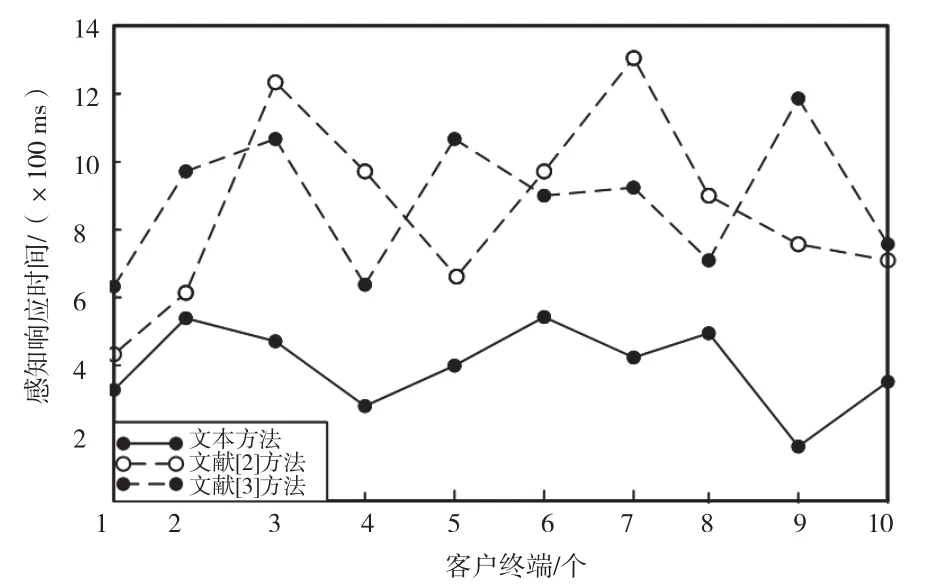
图1 方法状态感知效率曲线
由图1可知,当人为动态改变终端的运维状态时,基于机器学习的方法感知响应时间更短,感应效率更高。从方法感知效率曲线波动性分析,本文所提方法的感知响应时间变化幅度相对更小,对不同程度的终端状态改变都有良好的快速感知能力。
综合上述分析内容可知,在移动客服终端运维过程中应用基于机器学习的方法感知终端状态的相对误差最小,对终端状态变化的感知速度更快。将该方法应用于实际的设备状态管理的可靠性更高,感知效果更佳。
5 结 论
移动客服终端为客户获取优质的商业服务提供了良好的媒介渠道,方便企业及时为客户解决服务问题,能够提升企业的商业化形象。本文研究了1种基于机器学习的移动客服终端运维状态自主感知方法,通过对终端运维状态感知能够获取全面的终端运行数据、控制信息,以期为运维人员掌握终端运行性能提供参考。
猜你喜欢
读者·原创版(2020年2期)2020-02-20
铁道通信信号(2019年6期)2019-10-08
中国交通信息化(2019年5期)2019-08-30
能源(2018年8期)2018-09-21
作文小学中年级(2018年12期)2018-01-25
能源(2017年11期)2017-12-13
雷达学报(2017年6期)2017-03-26
现代工业经济和信息化(2016年8期)2016-05-17
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
