
固定翼无人机多工况聚类及识别研究
2022-02-21 04:42:50卢俊钢张世荣梁少军
兵器装备工程学报 2022年1期
卢俊钢,张世荣,梁少军,杨 毅
(1.武汉大学 电气与自动化学院, 武汉 430072;2.陆军工程大学 军械士官学校, 武汉 430075)
1 引言
无人机具有易开发、成本低、灵活性强等特点,近年来在军事、民用领域得到了长足发展和广泛应用。其中,固定翼无人机(Fixed-Wing Unmanned Aerial Vehicles,FW-UAVs)集成技术先进、造价高、系统复杂,一般应用于速度快、距离远和续航久的场景。FW-UAV的性能会随着运行时间增加逐渐衰退,导致故障发生率增高。FW-UAV一旦因故障坠毁会导致较大的经济损失甚至引发军事、政治和社会影响。故使用故障预测和健康管理技术提升无人机设备的可靠性与可用性具有重要意义,众多学者围绕此问题进行了大量深入研究。
FW-UAV的设备复杂性、任务规划多变性和环境多样性导致其工作状态反复切换,呈现多工况特征,这给基于数据的故障预测和健康管理带来诸多挑战。因此,有必要对无人机的多工况问题进行研究。从数据挖掘角度看,FW-UAV的多工况分析是典型的数据分组问题,可以使用聚类算法解决,在线数据分类则属于模式识别问题。常见的聚类算法有层次聚类、密度聚类和谱聚类等。目前已经出现了基于相似性(距离)、基于神经网络和基于机器学习等方法的模式识别,并被广泛应用于工业、军事等领域。例如,张俊楠等将支持向量机与二叉树结构相结合对分布式光纤扰动传感系统的扰动模式进行了有效识别。别锋锋等利用ICEEMDAN算法提取了往复泵的故障特征,并使用GRNN神经网络进行故障识别,有效提高了识别准确度。王烁等基于反向传播神经网络对多因素作用下破片对靶板的侵彻毁伤模式进行了有效识别。刘凡等利用小波包分解提取了电力变压器的多维度能量特征,进而使用近邻算法实现局部放电超高频信号的模式识别。张阳阳等使用概率神经网络对齿轮箱典型故障进行了有效识别。
以上方法在不同领域应用收到了较好效果,但无法直接应用于FW-UAV工况分析。主要原因在于:含类标的FW-UAV数据很难获取,导致监督模式识别算法无法应用;FW-UAV数据链传输速率快,在线数据量大,对工况识别算法时效性要求高。为解决以上问题,本文将聚类分析与模式识别算法相结合,采用组合算法来实现无人机多工况的高效分析。拟提出一种基于分组的非监督密度聚类(Group-based DBSCAN,G-DBSCAN)算法,在不依赖数据工况类标基础上实现多工况分析;并将提出一种基于多维度分解的快速工况识别算法(Pattern Recognition based on Dimensional Decomposition,PRDD),PRDD将进一步与聚类算法深度融合以实现FW-UAV在线数据工况识别的快速性和准确性。
2 FW-UAV多工况分析
FW-UAV执行任务的全流程包含起飞、巡航、遂行任务、返航、回收等多个阶段,属于典型的多工况过程,若将其简单处理为一个工况,则会因模型失配降低故障预测、故障诊断、剩余寿命预测等数据驱动算法的准确率。
这里以某FW-UAV实际飞行数据集中纵向控制回路与速度控制回路相关数据为例,展示其多工况特征并说明工况分析的必要性。FW-UAV纵向控制回路与速度控制回路均是闭环反馈回路,相关的变量包括俯仰角、升降舵偏角、发动机缸温、发动机转速和高度共5维数据。图1为某飞行时间段该5维数据归一化后的飞行曲线。从图1可以看出,随着时间推移曲线幅值波动较大且各维度数据呈现非线性关系,无法从直观角度辨识工况。为进一步分析无人机工况特征,下一节将基于数据分布特征,提出一种密度聚类算法对其进行多工况分析。
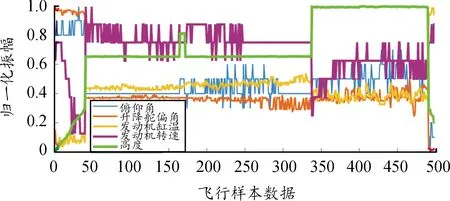
图1 FW-UAVs某飞行时间段飞行曲线
3 多工况分析与识别算法
3.1 工况聚类
DBSCAN作为基于密度的聚类算法,能够在数据集中找出具有不同大小和形状的簇,对噪声有较强的鲁棒性,能基于数据自主推测聚类个数。DBSCAN的主要参数为扫描半径和核心点最小数据量Min,算法将数据集中的样本点分为核心点、边界点和离群点3类。在DBSCAN算法中定义了两点之间3种特殊关系:直接密度可达、密度可达以及密度相连。经典DBSCAN算法将原始数据集中的所有样本点视为潜在的核心点逐个扫描,若确认为核心点则将与其密度相连的所有数据点视为同一类。以下提出了一种基于分组的DBSCAN算法,它将数据分布特性融入经典DBSCAN算法,旨在提高算法的效率。
对于数据集中的给定点,∈,令,表示点和之间的距离,,()表示点到其第个最近邻点()的距离。在距离基础上进一步定义分组核心点、分组离群点和分组待定点。
1) 分组核心点:对于给定点∈,若,(Min)≤,则将该点标记为分组核心点。这就意味着点与其第Min个最近邻点的距离小于。
2) 分组离群点:对于给定点∈,若,(Min)>2,则将该点标记为分组离群点。

3) 分组待定点:给定点∈,当<,(Min)≤2时,将其标记为分组待定点。显然,边界点以及离群点都有可能是待定点,因此还需进一步采取策略进行识别。
使用基于KD树的最近邻搜索算法获取数据集中的每个点到其第Min个最近邻点的距离,并将得到的距离值以升序进行排序,就可以得到距离曲线(Min-th distance Curve,MC),如图2所示。
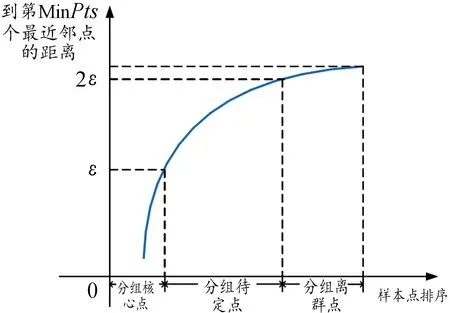
图2 样本点到其第MinPts个最近邻点的距离曲线
令、、分别表示分组核心点、分组待定点以及分组离群点。以图3(a)为例,此时Min=3,所有核心点、、、、均属于。因为,(3)=,>2,故点属于,而另外2个真实离群点与被临时收集在中。此例说明包含了所有的核心点,包含了部分的真实离群点,而包含了边界点和离群点。其中中的离群点并不参与最终的聚类结果,因此可以被直接剔除以提高算法效率。由于核心点将决定最终聚类的形状、大小以及数量,因此可以对使用经典DBSCAN算法,并设置Min=1,以获得聚类结果,如图3(b)所示。由于已经获得了数据间的距离矩阵,聚类结果获取时可直接调用该矩阵以进一步提高算法效率。
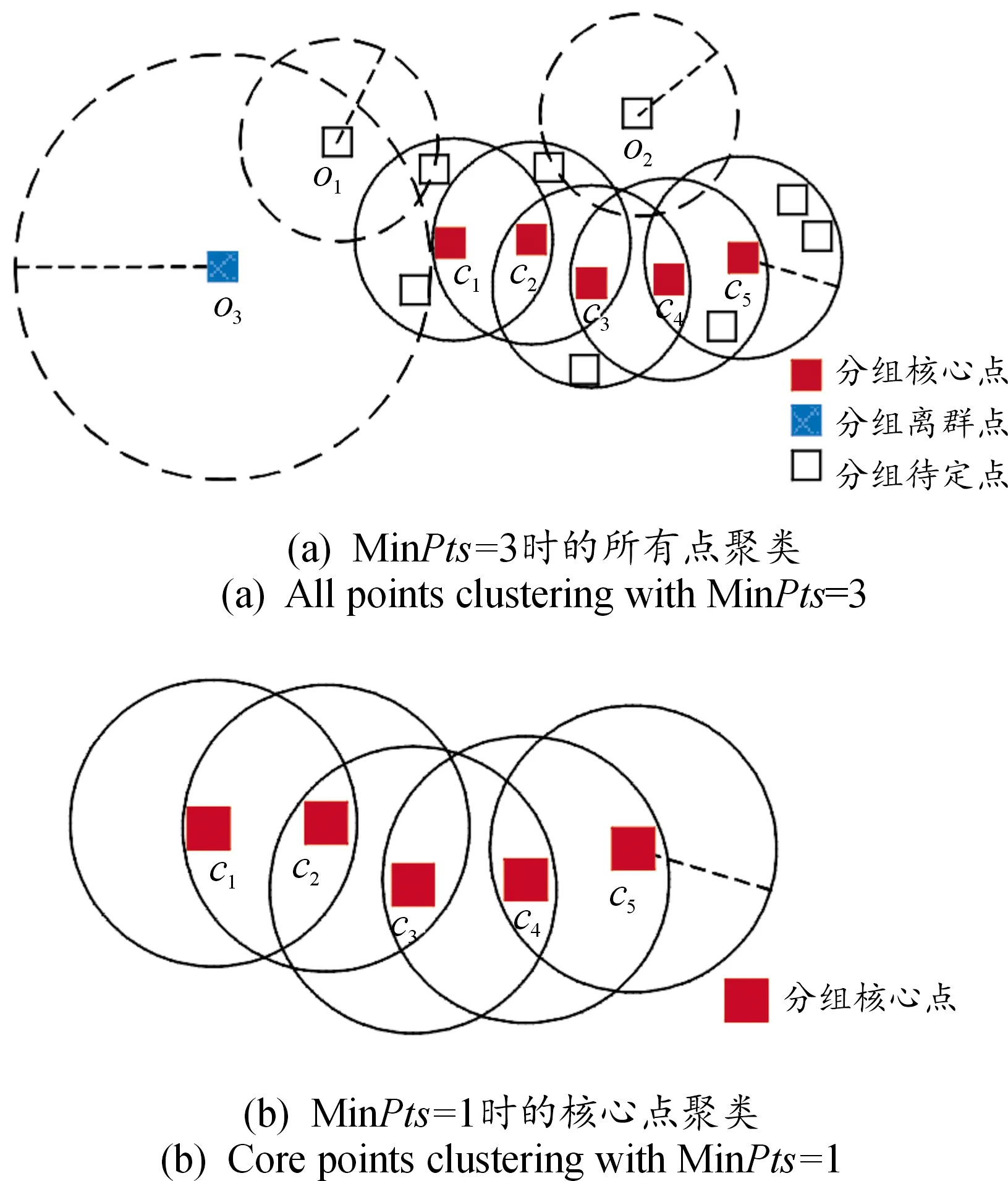
图3 2种方法的聚类结果示意图
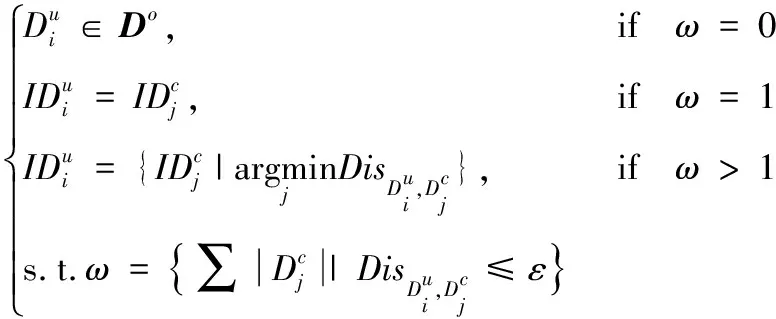
(1)

输入:
(1):原始数据集
(2):扫描半径
(3) Min:核心点最小数据量
输出:
(1)、、:分组核心点、待定点、离群点类标
方法:
(1) 初始化=,=,=
(2) 使用基于KD树的最近邻搜索获取MC曲线及距离矩阵
(3) for中每个点
if≤then=∪
else if<≤2then=∪
else=∪
end if
end for
(4) 将中的所有点都标记为噪声
(5) 执行DBSCAN算法(,,1)来获得每个核心点的簇ID


end if
end for
3.2 工况识别
前一节使用G-DBSCAN算法对FW-UAV原始数据完成聚类分析后,会将原始数据集分为若干个簇,并标以不用的类标,即完成数据分组。本文将密度聚类算法与工况识别深度结合,充分利用已完成聚类的核心点信息,融合主成分分析法,提出一种基于多维度分解的模式识别算法(PRDD),完成新数据的聚类类标模式识别。
该算法首先将聚类获得的核心点数据以及新数据使用主成分分析法(principal component analysis,PCA)降维,以提高运算效率,进而对两类数据进行维度分解,通过判断各个维度上新数据一定邻域内核心点数据的分布情况,结合逻辑运算粗略推定新数据周边有无核心点。之后根据核心点数量以及与新数据的真实距离准确识别测试数据的类标。
输入:
(1): G-DBSCAN中的核心点矩阵
(2): G-DBSCAN中的核心点类标矩阵
(3): 测试数据,即新数据
(4): G-DBSCAN算法中邻域半径
输出:
(1):新数据的多工况识别类标
方法:
(1) 基于实现、的降维
(2) 初始化类标矩阵
(3) for中每个点do
创建的邻近点集合,并初始化
for中每个点do
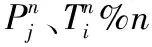

将加入邻近点集合
end if
end for
end for
if=then
标记为噪声点
else if()==1 then仅一个核心点
if ‖-‖≤then‖·‖为二范数计算
else 标记为噪声点
end if
else 从中剔除与距离大于的核心点
if=then
标记为噪声点
else if()==1 then
else if()>1 then
if中所有核心点类标相同 then
end if
end if
end if
end for
以上算法相比较于传统模式识别算法具有以下优势:
1) 无额外参数。该算法仅需输入G-DBSCAN算法(或是其他以密度聚类为核心的算法)的扫描半径,因此可摆脱部分机器学习算法中所存在的超参数调节困扰;
2) 无需建模。该算法在深度研究密度聚类算法的基础上,从维度分解以及数学规律层面对新数据进行工况识别,无需依靠训练数据进行建模,故也不存在模型过拟合、欠拟合以及陷入局部最优的问题;3) 开销小。该算法充分利用维度分解的便利性,在各个维度上分别执行查找运算,之后通过逻辑判断将待处理范围缩小后再运行计算开销较大的距离运算。与其他基于相似性/距离、基于神经网络和基于机器学习的模式识别方法相比,本算法具有显著的计算优势。
4 验证
4.1 无人机多工况分析平台
工况聚类和在线工况识别是无人机故障诊断和健康管理的前提,多工况分析平台设计如图4所示,该平台可进一步服务于无人机故障诊断和健康管理系统。图4中,机载飞行控制计算机采集飞机俯仰角、升降舵偏角、高度、发动机缸温和转速状态信息,并编码形成遥测数据通过数据链发送至地面设备。地面设备接收并处理遥测信息,在对遥测数据清洗和采样后存入历史飞行数据库。终端设备封装了G-DBSCAN算法以及PRDD工况识别算法,执行多工况聚类与识别算法运算。以下首先以获得的实飞数据为例进行算法验证。
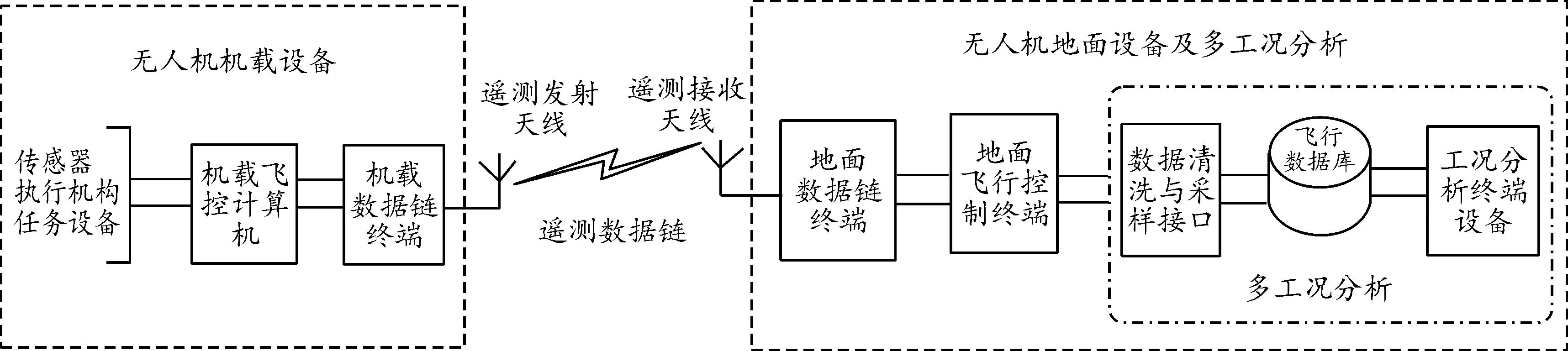
图4 无人机多工况分析平台框图
4.2 FW-UAV的工况分析与识别
利用图4所示分析平台获取了FW-UAV的实飞数据集,以下取某次飞行数据用于算法验证。从数据集中选取数据量=500的数据样本,数据维度=5(飞行数据曲线见图1)。首先使用PCA算法降至二维,并设置G-DBSCAN算法参数Min=8,=007,算法首先得到飞行采样数据MC曲线。根据MC曲线纵轴距离值与的关系可将飞行采样数据划分为分组核心点、分组待定点和分组离群点。如图5所示,图中纵轴距离值小于等于的区间聚集了所有的分组核心点,在与2区间聚集了待定点数据,在大于2的区间收集了分组离群点,这一结果与3.1算法描述一致。
本文算法测试环境为Matlab 2020b,终端设备配置为主频2.2 GHz,内存16 G。根据G-DBSCAN算法步骤,图6(a)、图6(b)和图6(c)为使用分组策略所获取的3种不同数据的聚类结果。图6(a)为算法筛选出的离群数据。图6(b)为筛选得到的分组核心点数据在重新设定Min=1之后执行经典DBSCAN算法所获得的聚类结果,从图中可以看出分组核心点被聚为5类,由于分组核心点聚类结果表征了聚类的大致分布结构,因此可以断定最终聚类结果将被分为5类,且边界点将分布在此5类核心点数据簇的边缘。在图6(c)中,分组待定点中的边界点被划分到各核心点组成的簇中,而离群点被单独标记。此过程将针对分组待定点的聚类分析过程转化为了聚类类标识别过程,提升了算法效率。汇总以上结果即可得到算法最终聚类结果,如图6(d)所示。图6(e)为传统DBSCAN算法聚类结果,对比G-DBSCAN算法,后者在保证了不影响原有聚类效果的前提下,平均运行时间从0.021 27 s减少到0.006 3 s,有效提高了算法的效率。
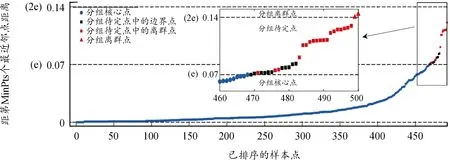
图5 无人机飞行数据的MC曲线
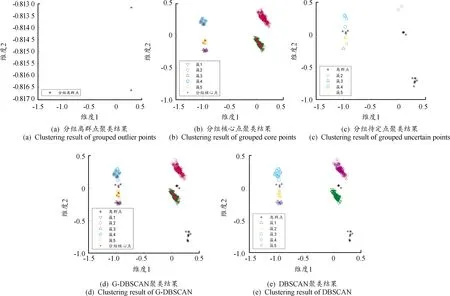
图6 FW-UAVs飞行数据聚类结果示意图
综上,G-DBSCAN算法能更快获取到聚类核心点,无需重复遍历原始数据集,结合后续模式识别算法将有效提高整体技术路线运行效率。
从已完成聚类分析的数据集中提取核心点矩阵及其对应的类标矩阵,同时从该数据集中分别随机选取20、35、50的数据制成测试数据20、35、50用于PRDD工况识别算法的验证。首先使用PCA算法将核心点矩阵及3组测试数据降至2维,并将降维后的、20、35、50以及参数(聚类时设置的参数)输入PRDD算法,结果如图7所示。该算法在3种测试数据集下的识别率均达到100%。

图7 3种测试数据集下的识别结果示意图
为了进一步检验该算法的优劣,选取了几类常见的模式识别算法进行比较:加权近邻算法(weighted-nearest neighbor,WKNN)、反向传播神经网络(back propagation neural network,BPNN)、概率神经网络(probabilistic neural network,PNN)以及支持向量机(support vector machine,SVM)。从数据集中随机选取80%作为上述算法的训练数据,剩余20%作为测试数据,使用上述算法分别对无人机工况进行识别,并将识别结果与PRDD算法的结果列表。如表1所示。
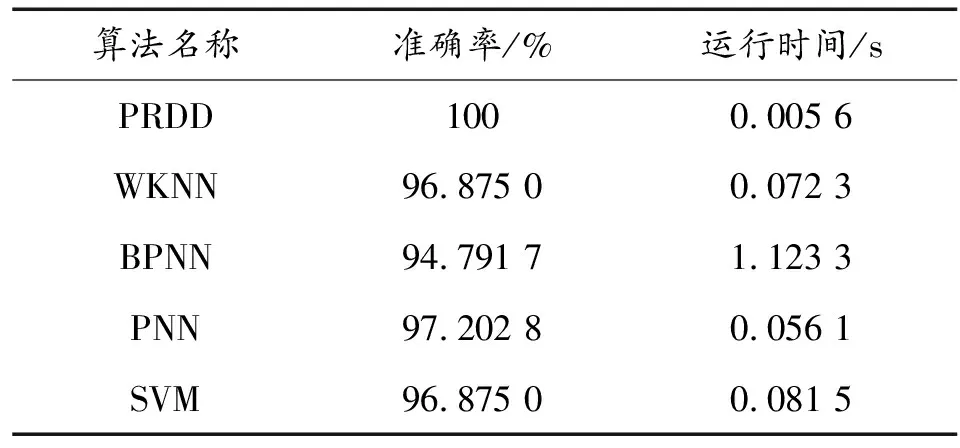
表1 不同模式识别算法的识别结果
由表1可知:文章所提算法在识别准确率和运行时间方面较其他算法具有明显优势,进一步验证了算法的有效性和实用性。
5 结论
提出了“聚类分析-模式识别”相结合的多工况识别技术路线。聚类分析阶段从数据挖掘角度分析FW-UAV飞行数据,使用非监督改进型密度聚类算法G-DBSCAN解决了FW-UAV工况划分难题,与工况识别紧密结合,融合主成分分析法,提出了基于多维度分解的快速工况识别算法。在已有聚类核心点类标的基础上,充分利用维度分解的计算便利性,通过执行查找和组合逻辑运算减小了计算开销,并进一步进行精确识别。相比较于传统模式识别算法,能够在保持较高工况识别准确率的同时有效提高算法效率。
猜你喜欢
小学生学习指导(低年级)(2019年3期)2019-04-22 03:34:48
小学生学习指导(低年级)(2018年9期)2018-09-26 05:59:42
小学生导刊(低年级)(2017年1期)2017-06-12 12:07:42
电子测试(2017年23期)2017-04-04 05:06:50
智能系统学报(2017年5期)2017-01-22 11:21:30
中国房地产业(2016年9期)2016-03-01 01:26:47
作文评点报·低幼版(2015年5期)2015-05-30 10:48:04
智能系统学报(2015年3期)2015-01-29 15:20:12
西安交通大学学报(2014年8期)2014-04-16 05:07:06
上海电机学院学报(2014年3期)2014-02-28 14:29:45
