
基于Storm的变压器PRPD参数提取与模式构造
2022-02-19 10:23赵铭滕朱永利
计算机应用与软件 2022年2期
赵铭滕 朱永利
(华北电力大学控制与计算机工程学院 河北 保定 071003)
0 引 言
伴随着智能电网的飞速发展,输变电设备的增多,状态监测也逐渐推广应用在电网的电力设备上。众多高压电力设施可以通过许多手段来判别绝缘状态和异常,而局部放电(Partial Discharge,PD)是其中重要评估根据之一[1]。局部放电是因为电场中部分场强过高引起绝缘介质被击穿或局部放电的现象。如果场强高于一定值,也可能会发生在液体中[2]。局部放电对电网安全和电力设备危害非常大,大部分电力设备如变压器等故障都是由它引发的[3]。正因如此,近些年来局部放电一直得到电网的重视,对局部放电数据进行分析,识别出放电类型,对判定最终的放电位置具有非比寻常的考量价值。目前对局部放电进行识别首先要进行的是模式构造,其次是提取特征量,最后是设计分类器。模式构造是第一步,它的构造效率和正确性直接影响后续步骤和整个局部放电识别的性能。快速对PD数据进行模式构造,有利于快速提升对局部放电的识别速度,同时也对保障电网的运行效率与安全具有重大的意义[4]。
Storm从2010年12月被提出到2014年9月正式加入Apache旗下,因为其高度可扩展性[5]、易于使用和能提供低延迟保证数据处理等优点而被广泛使用。模式构造相关论文大部分都是理论讲解,即便涉及实验,在Storm下进行实验并分析的也非常少。鉴于Storm的各种优势,针对传统方法处理大量局部放电信号时的瓶颈问题,本文研究基于Strom的并行化方法,高效准确地提取放电数据中的基本放电参数进行模式构造,生成局部放电相位(Phase Resolved Partial Discharge,PRPD)图谱。
1 局部放电模式构造
1.1 局部放电检测的主要方法
目前局部放电检测可以分为两大类:停电检测和在线监测[6]。两大检测类中主要的方法大致包括常规和宽频带脉冲电流法[7]、特高频法[8]、光测量法和超声波测量法[9]。局部放电主要的研究技术主要有局部放电源定位[10]、局部放电信号特征提取与模式识别[11]。
1.2 模式构造使用的主要模式
目前主要使用的是基于电测法的特征提取与模式识别,而模式构造是特征提取必要的前期工作。局部放电的模式构造使用主要模式大概分为以下几种。
1.2.1基于局部放电时间分布模式
该模式主要是对单个局部放电脉冲波形或者单个周期的局部放电信号进行波形的特征量提取,包括局部放电脉冲波形的时域特征[12]、基于各种小波变换的特征提取[13]等,该模式也被称脉冲波形模式。虽然有实验表明局部放电缺陷与其脉冲波形有直接关系,但是有许多其他因素也与波形有直接关系,如传播路径、检测系统等[14]。因为本文的源数据类型和TRPD(Time Resolved Partial Discharge)的相关缺点,本文不考虑使用该识别方法。
1.2.2基于相位分布模式
该模式主要描述局部放电脉冲中φ、q与n之间的关系(φ、q、n分别表示局部放电脉冲对应的工频相位、放电量或放电幅值、放电率或放电次数)。该模式与时间无关,是局部放电分析中最常见的模式。因为局部放电的强随机性,导致基础参数分散,所以需要对较多周期的局放信号进行统计分析以增加准确性,所需信号量较多[15]。同时对应的工频电压相位信息也是必不可少的。但是该模式具有特征提取方法简单、参数符合标准、实用性较强、易于可视化等优点[16]。鉴于该模式的优点以及实验本身的要求,本文选用相位分布模式进行相关研究。
1.2.3基于脉冲序列分布模式
脉冲序列分布模式(Phase Resolved Pulse Sequence,PRPS)主要用来表示脉冲的周期与相位的具体情分布况,主要涉及到放电信号的幅值,相位以及放电周期[17]。本文并未使用该方法,就不再赘述。
2 Storm框架下参数提取分析
2.1 Storm平台架构
虽然目前很多研究都是基于Hadoop进行的,但是考虑到放电数据实时性与复杂性,以及Storm的编程方便性、更短耗时、更灵活等强大特点还是决定采用Storm进行放电数据的处理。除此以外Storm在对突发事件的处理与增量方面也有很好的性能,可以补充实时性差方面的短板。其次使用Storm可以对未来的研究起到更好的铺垫作用和辅助作用,使未来处理其他电力设备监测状态数据的实验更加方便进行。
在Storm中有在工作节点(Worker node)上运行Supervisor守护进程和在主控节点(Master node)上运行的Nimbus进程。主控节点Nimbus负责监控各个节点的工作状况以及向各个节点发送代码和任务。工作节点是负责作业处理的节点,根据主控节点发送的要求控制相关工作进程Worker的开关。此外主控节点的数量不能超过一个,但工作节点在集群中可以有很多。主控节点与工作节点之间还需要Zookeeper服务器端进程节点作为中间的协调节点。Zookeeper是广泛用于状态监控和配置管理的一种状态协同服务。整个框架所用的外部资源都来自于Zookeeper。当主控节点以及工作节点突然中断时,Zookeeper可以保证它们重新启动后依然能够继续运行。以上三者关系的示意图如图1所示。
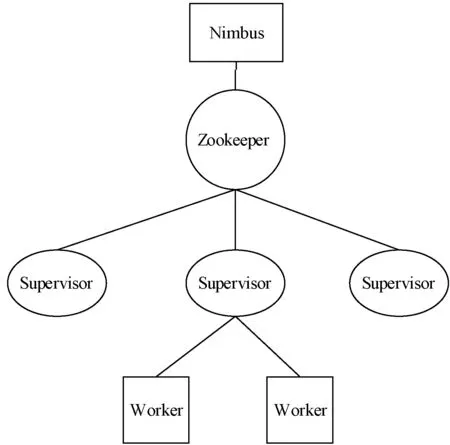
图1 Nimbus、Zookeeper与Supervisor的关系示意图
2.2 Storm基本概念
在Storm中,处理的数据大部分具有连续性或者实时性,其中处理数据基本的单元是经过打包处理的拓扑作业。拓扑是Topology的直译,任何语言的拓扑都可以提交到Storm上。Topology由Bolt 与Spout组成,其结构如图2所示。
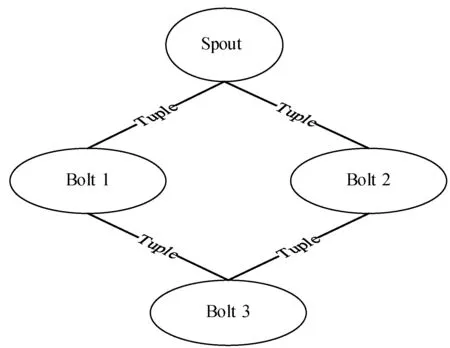
图2 Topology的结构
Bolt与Spout这两种组件是Storm下数据处理的的基本原语且分别负责数据的处理和消息的生产。Spout获取外部数据同时发送Tuple元组到组件Bolt。Spout在发送时十分灵活,当数据对可靠性有要求时可以使用可靠处理,当数据少部分丢失且不影响整体处理时可以使用非可靠处理,这也是Spout的众多优点之一。Spout的简单结构如图3所示。
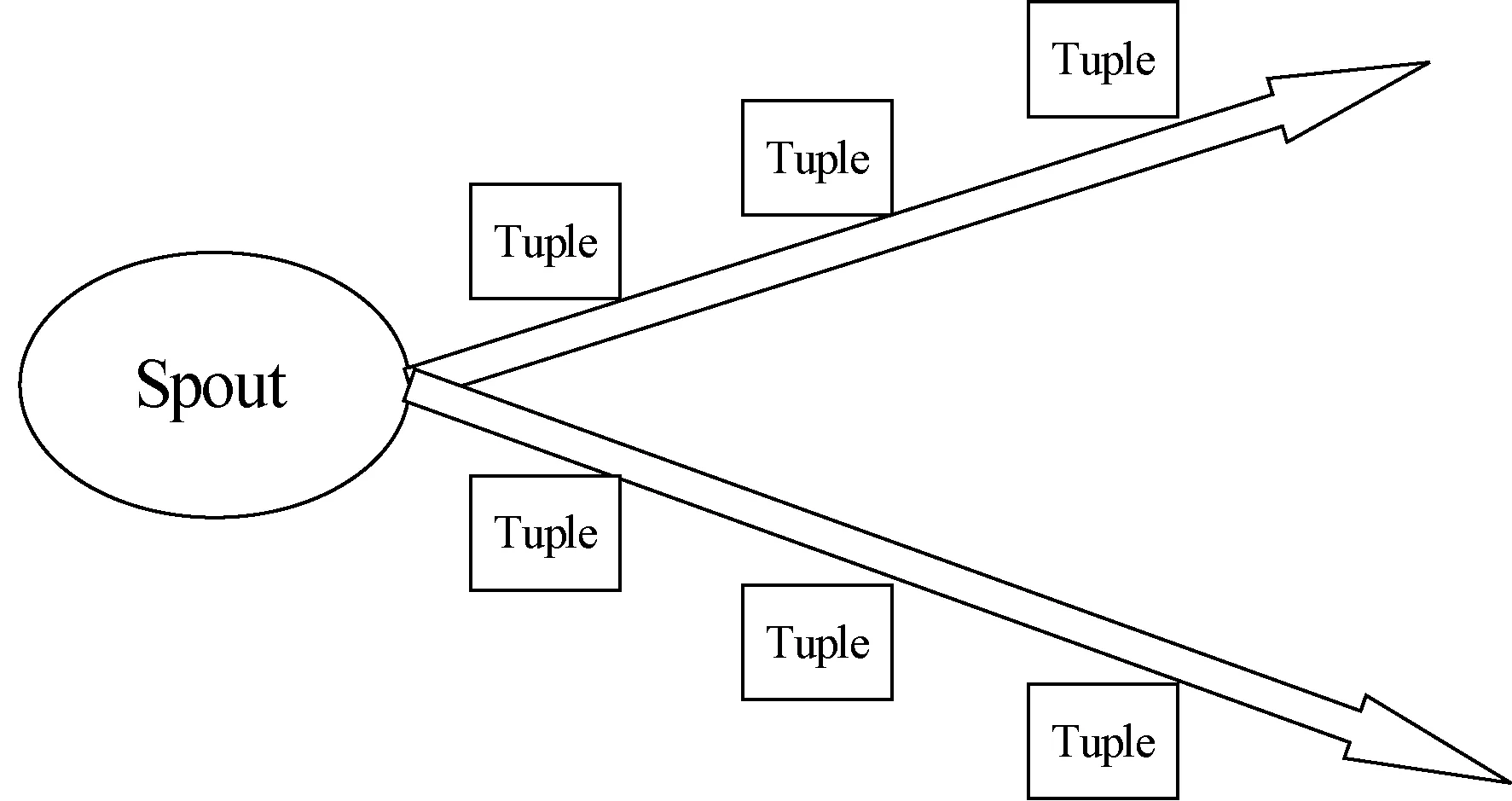
图3 Spout的简单结构
Bolt是拓扑的基本处理单元,同时也是框架中的编程单元,它不仅可以进行简单的流转换或者复杂计算也可以向下游的Bolt发送元组,进行数据处理。此外,数据处理进程用术语Worker描述,在Topology中部分tasks通过Worker启动的线程进行执行,同时这部分tasks也可以属于不同的Topology。在一般情况下,Storm会合理地分配Worker以及给Worker分配的tasks。
2.3 局部放电相位分布分析
放电量q、放电所在相位φ与放电次数n是构成单个工频周期内PRPD模式的三个基本参数。由于局部放电的随机性导致参数分散,所以先对工频周期的放电量与放电次数进行统计,再将其折算至一个单位时间或者工频周期内,这样可以更好地反映出它们的统计规律和放电特性。在放电量q、放电所在相位φ与放电次数n的基础上,主要采用的图谱有以下三种:
(1)q-φ统计图:描述幅值与相位的关系,横坐标为相位,纵坐标为信号幅值。以柱状图表示,反映最大放电幅值与相位分布的关系。
(2)n-φ统计图:描述一段时间内放电次数与相位的关系,横坐标为相位,纵坐标为放电次数。以柱状图表示,反映放电次数与相位的分布关系。
(3) PRPD统计图谱:描述相位分辩的局部放电,将带有标识的局放脉冲按照相位表现出来,同时以图形颜色深浅来描述放电次数多少。该图是一种平面点分布图,横向为相位,纵向为幅值,点的颜色深度表示放电脉冲的密度,根据点分布情况可以掌握信号主要集中的相位、幅值及放电次数。
2.4 双阈值过滤参数提取算法
除去信号采集、降噪等预处理,参数的提取是第一步,其结果会直接影响模式构造的准确性和效率。本文决定采用双阈值过滤法用于基本参数的提取,因为该方法简单有效且在Storm下易于实现,通过使用代表放电幅值的垂直方向和代表放电幅值的水平方向相结合对局部极值点进行双重过滤来确定一次放电。图中x为局部放电的监测源序号,t是一个图谱所需的信号个数(为了实验的可靠性,一般在50以上),m为某监测源当前要绘制的图谱序号,y为绘制图谱时对信号的计数。该算法具体流程如图4所示。其中参数提取和绘制图谱两个子过程中,每个子过程完成后都可以将结果保存至本地或者数据库。
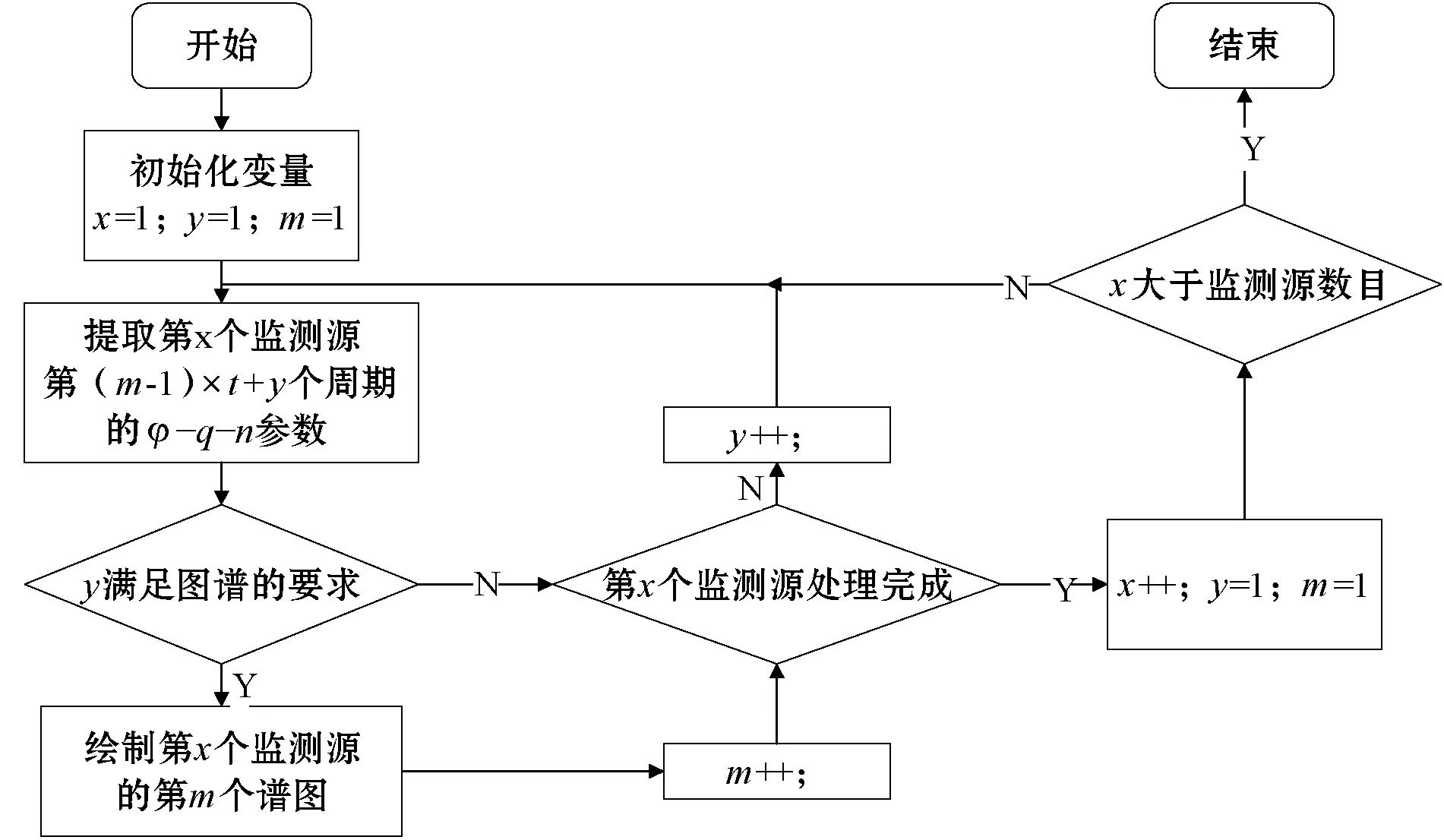
图4 算法具体流程
3 实 验
3.1 实验数据
变压器局部放电类型中较为常见有匝间放电、油纸放电和尖端放电等。本文的实验数据来源于某合作公司对放电类型进行监测得到的基本参数(放电次数)。源数据监测周期一般为一个周期,约20 ms。通道个数为4,每个通道包含点个数为10万。源数据一般格式为二进制,int16即每16个字节代表一个数。
3.2 Storm集群搭建
本文实验使用最经典的虚拟机配置,使用三台虚拟机组成集群,其中除了一个主节点外其余的均为从节点。将虚拟机master作为主控节点,worker01和worker02作为工作节点。Storm使用的版本为1.0.1,ZooKeeper使用的版本为3.4.8,构建于其中3台虚拟机之上。搭建步骤如下:1) 在各个节点上安装 Storm需要JDK(Java Development Kit)等相关资源,安装结束需要检测java-version的一致性,如果版本一致的话,则可以顺利进行下一步安装。2) 搭建ZooKeeper,搭建成功的标志就是集群的各台机器可以实现相互通信。其中比较重要的一条是如须关闭防火墙,三台机器的防火墙必须全部关闭,而且必要的时候禁止防火墙开机的时候自动启动,否则会出现ZooKeeper配置搭建已经完成,但无法使用或者使用异常,甚至导致机器间无法通信。搭建成功后运行,在每台虚拟机中输入指定命令就会显示其担任的身份。3) 在所有节点上下载并解压Storm,修改配置文件,然后启动后台进程。Storm是否运行正常可以通过UI界面的显示来判断,成功搭建后部分显示结果如图5所示。
图5 Storm搭建完成后部分UI界面
3.3 双阈值过滤参数提取算法的编程实现
算法利用StormSubmitter来提交拓扑,其中参数主要有名称、配置对象和拓扑本身。Spout从本地文件夹中读取二进制文件并发送字节流,每个字节流包含200 000 B。解析字节流信号,发送int16数组信号,串行解析200 000 B耗时约150 ms。扫描放电波形统计基本放电参数、放电幅值Q、放电次数N、放电数据datalist。对PD信号进行基本参数提取,发送谱图和基本参数的统计量。
3.4 Storm下双阈值过滤法性能测试
本次实验的主要目标是测试Storm在模式构造时对数据处理的性能,借助流式处理平台提高模式构造的速度和效率,测试的指标为吞吐量和处理延迟。
3.4.1吞吐量
吞吐量在本实验中是指单位时间内所能处理的放电数据总量。本实验主要测试的是模式构造模块与源组件FileFromDirSpout以及数据处理组件BinaryDecimalBolt的线程数之间的关系。保持工作进程和组件并发数不变,改变工作进程。将固定工作进程设置为3,组件并发设计为(2,3),发送间隔为0 ms,计算模式构造模块的吞吐量如表1所示。
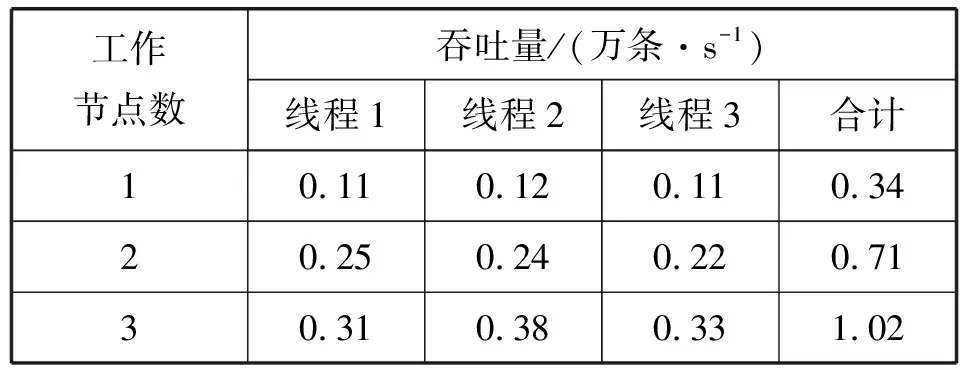
表1 不同工作节点数下的吞吐量
从表1中可以看出吞吐量随节点的增加呈现上升趋势。本次实验因为选择的工作节点较为理想,吞吐量不断增加,但是一直增加工作节点吞吐量不一定会一直增加。对于拓扑程序来说,其性能还与其他因素有关,本文使用的虚拟机较少所以对于其他因素就不多做研究。
3.4.2数据延迟测试
处理延迟一般指的是Storm中单个元组从发送开始到其被完全处理的总时间。本实验主要测试的是模式构造模块的处理延迟,其实数据处理的延迟是与处理模块里面的并行任务数量有关系的。并行任务数量多,则Tuple的等待时间就短,处理延迟就小。首先将Spout的数目设置为2,将Bolt的数目设置为2和5,统计计算前100个元组的处理延迟,结果如图6和图7所示。
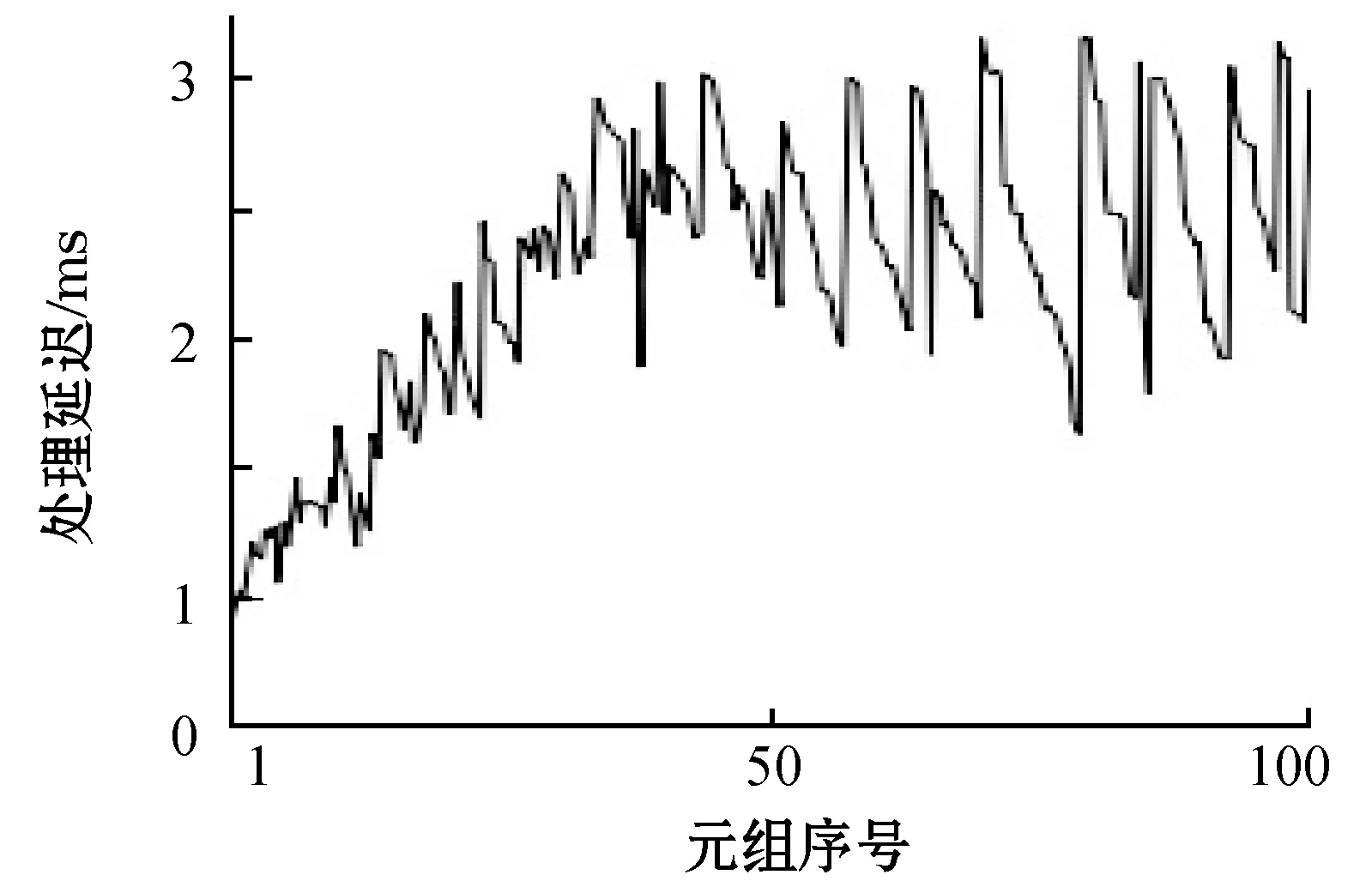
图6 Bolt的数目为2时处理延迟情况
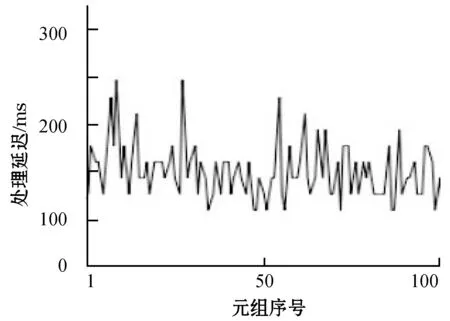
图7 Bolt的数目为5时处理延迟情况
数据太多会导致模块无法及时处理数据,则数据积累的数量会逐渐增多,最后导致处理延迟的上涨。当本文将Bolt的数目设置为5时,会发现大部分处理的延迟都非常小,可以降低到毫秒级。所以,本文可以得到,只要对任务所在的各个组件的数目进行合理的设置,就可以有效地提高处理性能。
3.5 部分实验绘制图谱
本次实验的主要目标是测试Storm在模式构造时对数据处理的性能,借助流式处理平台提高模式构造的速度和效率。绘制的部分图谱如图8-图10所示。
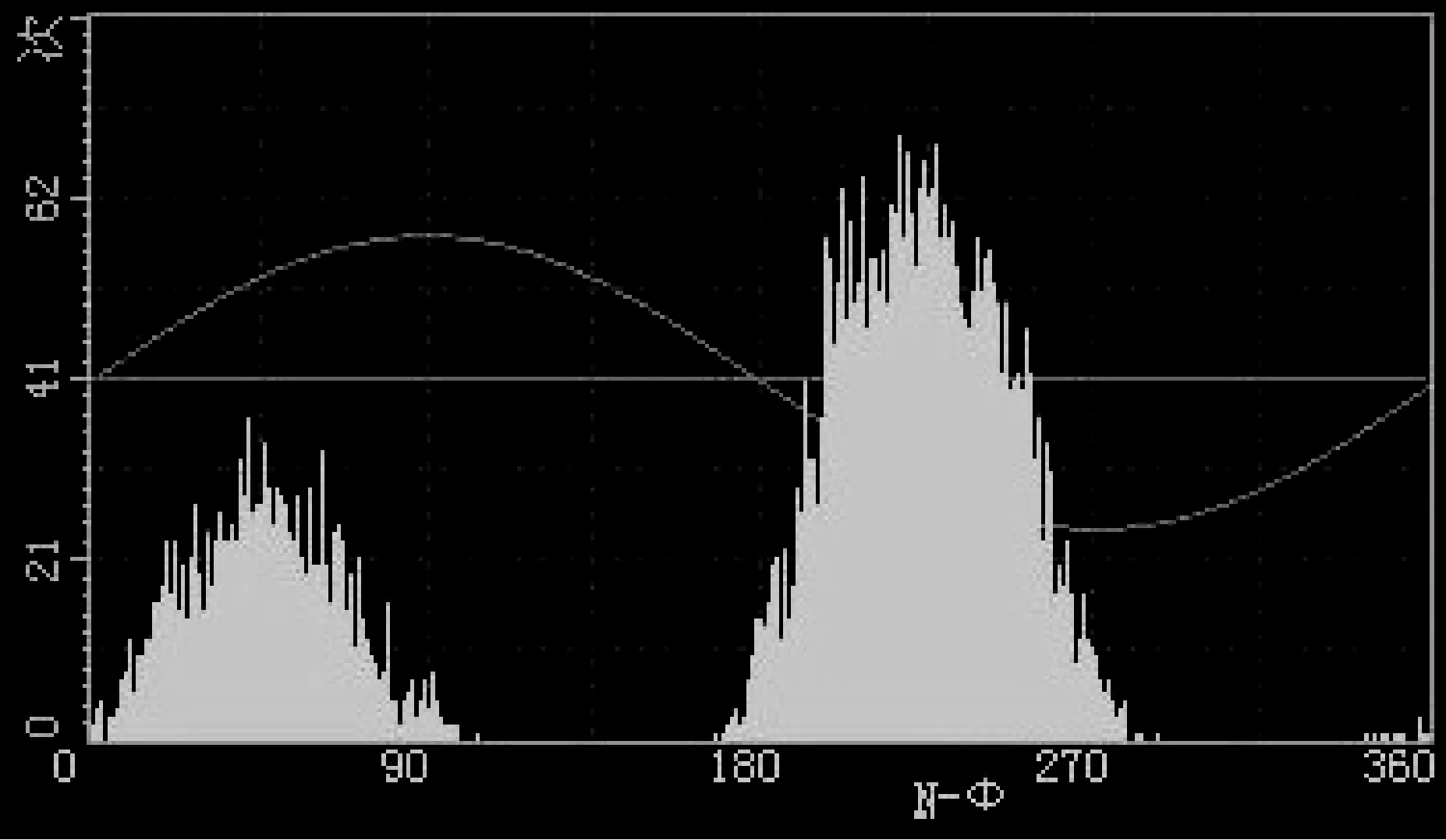
图8 n-φ统计图

图9 q-φ统计图
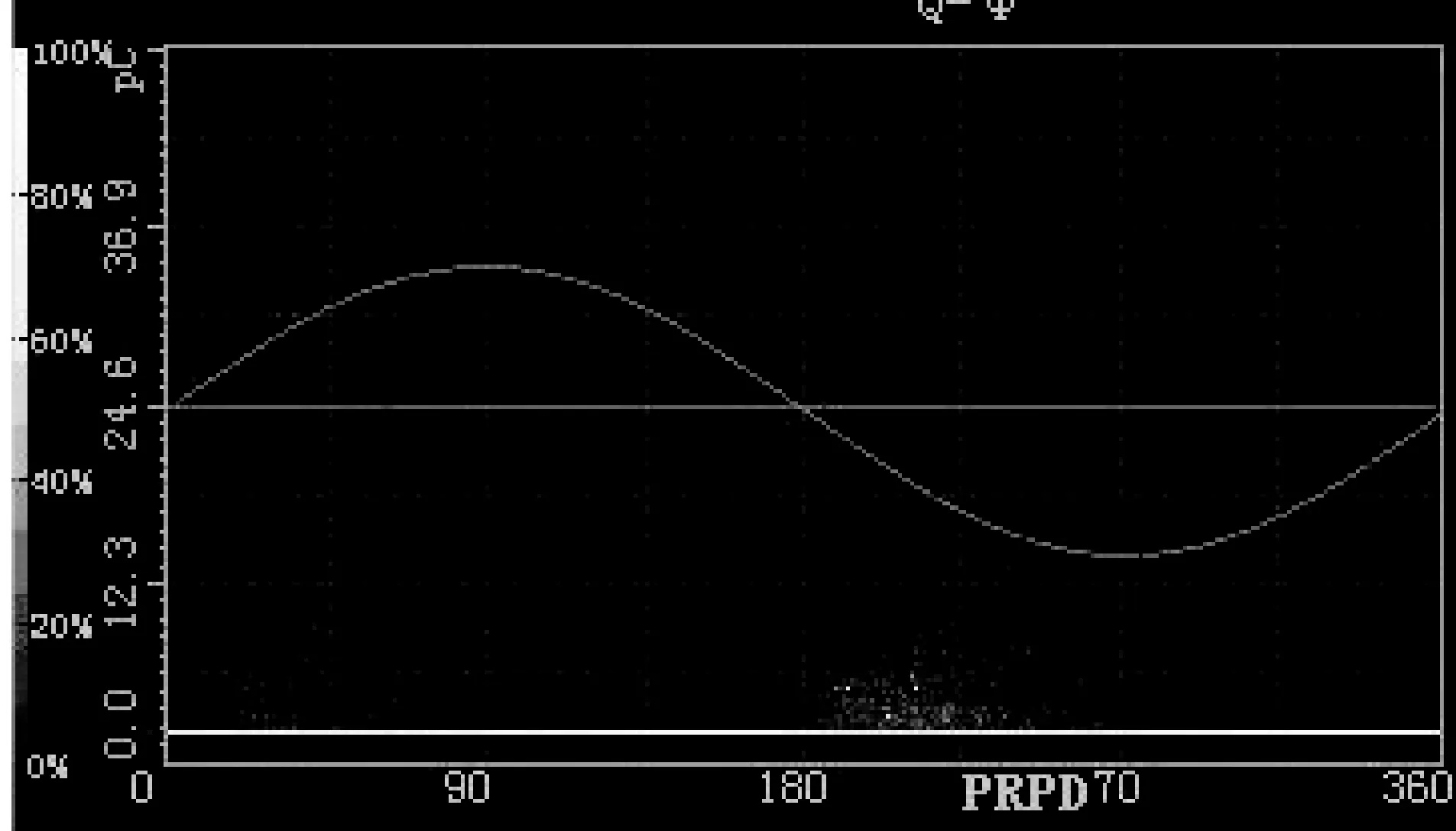
图10 PRPD统计图谱
4 结 语
本文对局部放电数据进行分析,提出了基于双阈值过滤法的参数提取算法和基于Storm的放电相位分布(PRPD)模式构造。首先搭建了Storm集群,然后设计并编程实现了基于双阈值过滤法的参数提取算法,完成了局部放电信号中参数检测,为模式构造提供了基础,得到了模式构造的实验图谱。最后通过分析吞吐量与数据延迟表明该算法不但具有较高的效率,而且适合在Storm下实现。
猜你喜欢
军事文摘(2022年16期)2022-08-24
舰船科学技术(2022年11期)2022-07-15
装备维修技术(2022年7期)2022-07-01
作文周刊·小学一年级版(2021年36期)2021-01-14
阅读与作文(小学高年级版)(2020年8期)2020-09-12
新城乡(2018年6期)2018-07-09
中国新技术新产品(2018年22期)2018-01-05
筑路机械与施工机械化(2016年12期)2017-01-13
现代电子技术(2014年16期)2014-08-20
移动通信(2011年13期)2011-11-13
