
基于机器学习的白洋淀生态数据的异常检测
2022-02-17 07:39:26吴琼,李永飞
电脑知识与技术 2022年35期
吴琼,李永飞



摘要:异常数据检测的问题近年来日益成为统计分析、机器学习、数据挖掘等诸多领域的研究热点之一,异常数据检测是实现数据质量提升的一个关键。异常数据检测中存在物联网数据来源不可靠、异常数据检测结果不稳定和不准确等问题,实验采用基于机器学习的异常数据检测算法,通过python数据分析,采用真实的数据即白洋淀生态物联网数据进行实验验证,对比几种基于机器学习的异常检测算法的异常检测效果,采用真实数据具有一定的应用意义。
关键词:真实数据;异常数据检测;聚类分析;K-means算法;DBSCAN算法
中图分类号:TP181 文献标识码:A
文章编号:1009-3044(2022)35-0007-03
1 概述
白洋淀是华北地区最大的湿地生态系统被称为“华北之肾”,多年来由于上游生活污水和工业污水的排放、机械船只增多等因素,白洋淀水质不断恶化。自2017年4月1日起,白洋淀生态环境治理和保护攻坚战打响。修复白洋淀生态的关键在于水域环境,改善水域内水体环境才能保障和恢复生物的多样性。白洋淀的生态数据通过物联网传感器实时采集,为了保证白洋淀生态物联网数据的真实性和可信性,需要对采集到的数据做出预处理。异常数据影响数据质量,异常数据检测能实现数据质量的提升与潜在信息的挖掘。在当前生态环境监测中应用物联网技术,建立自动监测站实现全天实时监测。物联网技术可以对数据信息精准识别和快速传递,让生态监测的整个过程变得系统化和透明化。
异常数据检测方法是通过统计分析、数据挖掘等技术来识别数据中的“异常点”,是指从数据中找出明显与其他数据不同的数据。离群点检测的概念最早由Hawkins在1980年提出,异常是指非随机产生的不同于数据集其他数据的数据[1]。异常数据可能是噪声,也可能是有价值的数据。异常数据检测是数据挖掘应用中的一项关键技术,是指从数据集中找出与预期行为不符的模式。异常数据检测对保障数据的可信性有重要作用,异常数据通常占比可能较小但可能蕴含丰富的内容。因此异常数据检测方法具有重要的研究意义和实践应用,并且其对保障检测数据可行性方面也有积极的作用。异常数据检测作为数据分析的任务模块之一,数据分析工作进行异常数据检测的价值在于及时发现异常,进而准确发出风险预警信息或以此科学有力的信息辅助分析决策者如何做好系统下一步风险决策。比如消除安全隐患、扩展国内市场份额、提高公司经济效益、生态环境监测等。异常数据分析中涵盖大量有用数据信息,是当今数据科学前沿中一个广泛研究的问题。异常数据的检测已逐渐成为数据挖掘等领域的热点研究之一[2]。根据异常检测面向的数据类型、研究领域等的不同,各种各样的异常数据检测方法不断被提出和改进。关于异常检测领域的一个较为深入详细的研究工作是 C. C. Aggarwal 等人做出来的。由于不同领域数据的差异性较大,根据其正、异常状态情况。异常检测方法为入侵攻击检测、欺诈交易检测、故障检测[3]、图像处理、安全与监控、文本数据异常数据检测、传感器网络异常检测、应急管理、医疗公共卫生、网络信息安全等领域的应用提供重要的参考依据[4]。
异常数据检测方法一般分为基于统计学的、基于聚类的、基于距离的、基于密度的、基于分类的、基于预测的等等。异常数据检测的应用最早出现在统计学领域。基于统计学的异常检测方法在处理异常数据时,一般会构建一个概率分布模型,并会计算数据对象符合该统计模型的概率,把概率较低的对象视为异常。基于统计学的检测方法有无参数的代表直方图和有参数的代表高斯模型等,该模型方法优点是基于数据分布快速且精准、鲁棒性比较好,不足是需要预先假设数据的分布情况,而且通常不适用于高维的数据。随着计算机科学及相关技术的更新换代,计算机方向的专家和学者利用在数据管理方面的经验可以对多种类型的数据进行异常的分析,之后基于机器学习的异常数据检测方法逐渐成为一种趋势。基于机器学习的方法按照是否需要进行人工标记则可以分为无监督模式、半监督模式和有监督模式。在有监督的模式下需要有标签的数据作为支撑,而样本标签的获取具有很大的代价。在无监督的模式不需要依赖任何标签,也不完全依赖完善的先验知识,可以通过聚类分析等方法获取边界条件以检测出异常值,因此无监督模式在异常数据检测领域里应用会更加广泛。目前基于聚类分析的异常检测方法是异常检测技术中最常用的一类方法[5]。
聚类算法的分析是数据挖掘和机器学习领域的重要研究课题之一,它是无监督模式识别,可以根据数据的相似度把数据划分为多个类或类簇[6]。在计算机学科的领域中,聚类算法是数据挖掘和人工智能应用中不能或缺的研究基础,它起着不可或缺的作用。并且异常数据的检测是聚类分析方法下的重要组成部分,用于检测数据样本中所有的异常点。异常点在聚类分析中表现为单个聚类簇,可以明显区分出正常样本和异常样本。比如经典的DBSCAN算法可以在聚类的同时,也可以识别出异常数据。基于专用的异常数据检测算法,这些算法不像基于聚类算法的异常点检测只是一个附加项,它们的目的是专门用来检测异常数据的,主要的算法代表是One Class SVM算法和Isolation Forest算法。基于近邻的方法包括基于距离和基于密度的方法,其代表算法有LOF算法和COF算法。基于最近邻的方法[7]利用计算各数据实例之间的距离进而实现对该数据实例的分析,当结果中某个实例远离它的邻居时,则该实例被视为异常数据。这种类型的方法不依赖数据的任何先验知识,但缺点是所设定的输入参数对检测结果则存在很大的影响,而且计算各数据实例之间距离的成本会比较大。基于密度的检测方法是通过比较每个点和其邻域点的密度来判断该点是否为异常点。当一个点与包围其邻居的密度不同时,则为异常点。
2 基于机器学习的异常检测算法
基于聚类的方法其代表算法有K-means算法和DBSCAN算法,采用距离、密度等信息,将相似度高的数据聚为一个簇,如果最终数据不属于任何一个簇的離群点,则视为异常[8]。K-means算法实现比较简单、聚类效果也不错,不需要数据标签和先验知识。基于密度的方法其常用的算法主要有LOF算法和COF算法,可以依据异常的程度给一个定量的值,具有较好的鲁棒性。还有其他基于专用的异常检测方法主要有One Class SVM算法,它是无监督不需要标记训练集和输出标签,适合用于解决极度不平衡的数据;还有Isolation Forest算法具有线性时间复杂度,处理异常数据快速且准确,并且可以满足实时性的要求。表1介绍了基于机器学习的异常数据检测算法。
3 算法实现及结果分析
3.1数据来源
为了验证基于机器学习的异常数据检测算法的有效性,采用真实的数据即白洋淀物联网生态监测数据。该数据集包括温度、COD、叶绿素等元素,本实验数据分析是采用静态数据即走航数据,该数据用excel表格存储。以数据本身特征为研究对象,研究物联网数据的基本特征即可变性、真实性、复杂性等。
3.2数据预处理
异常数据检测可以保证物联网数据的可信性和完整性。异常数据检测算法是建立在数据特征上的,因此研究数据特征具有重要作用。首先为了避免数据受到不必要的干扰,要正确的、真实的、完全的代表实际数据发生的方式收集、记录、报告和保存数据。其次由于采集到的数据本身存在噪声、不一致、不可靠等问题,因此首先对数据进行预处理,然后进行下一步的数据分析处理,最后再选择合适的异常数据检测算法。实验中对原始数据进行预处理,然后对5200多条数据样本做数据分析,采用基于机器学习的异常数据检测算法对白洋淀生态数据集进行多次异常数据检测[9]。
3.3异常数据检测流程
异常数据检测的基本流程是数据采集、依据物联网数据特征进行数据预处理、再进行异常数据检测、最后进行异常数据判断。异常数据检测流程图如图1所示。
3.4实验环境
实验硬件环境:CPU是Intel(R)Core(TM)i5-6200U @2.30GHz,内存为8GB,操作系统是Windows10。实验采用真实数据即白洋淀生态物联网数据集。
实验软件环境:编程采用Python语言,仿真软件环境为Pycharm,采用Sklearn機器学习框架下实现异常数据检测算法。
3.5实验过程及结果分析
实验采用数据预处理方法得到的5200多条数据样本。选取白洋淀物联网生态数据中的两列即“温度”和“COD”两个字段,利用基于聚类的、基于密度和基于其他专用异常数据检测算法共三类算法做异常数据检测工作。
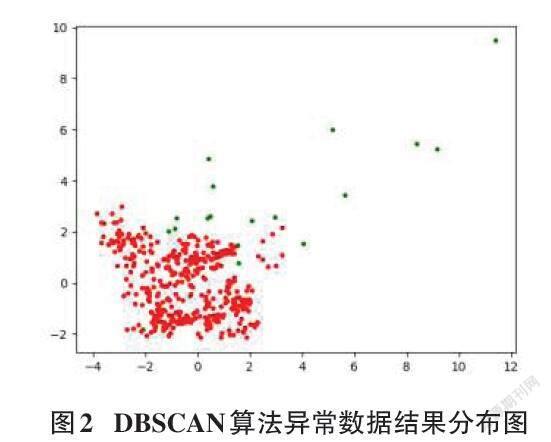
数据可视化展示采用PCA降维方法,通过PCA降维后,用二维坐标展示异常数据结果分布图。采用DBSCAN算法进行异常数据算法使用数据中“温度”和“COD”两个字段,每个字段选取500条数据,结果异常数据量为21个,DBSCAN算法异常数据结果分布如图2所示。
采用K-means算法进行异常数据算法是使用数据中“温度”和“COD”两个字段,每个字段选取500条数据,结果异常数据量为101个,K-means算法异常数据结果分布如图3所示。
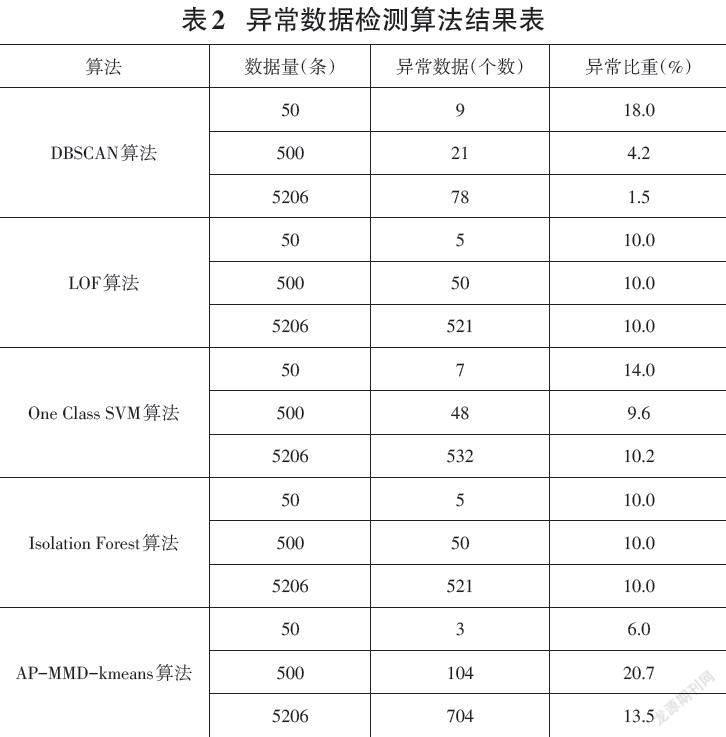
通过实验同样的数据集采用的算法不同异常数据检测的结果也不同,同一种算法选取数据量不同则异常数据量占比也不同,具体算法实现结果表2所示。
4 结论
1)通过算法实现,同样的数据集采用不同的算法异常数据检测的结果也不同,同一种算法选取数据量不同则异常数据量的占比不同。为了异常数据检测的结果更准确,可以对比几种算法的结果最终在确定异常数据情况。一个思路是在基于机器学习的异常数据检测中没有一种算法适合所有的情况,可以考虑采用基于集成学习的思路,把各个算法看成学习器,采用投票的方式来判断数据是否属于异常。另一个思路是改进算法,比如K-means算法属于随机选取的初始聚类中心点,因此会导致聚类结果不稳定,影响异常数据检测的结果。改进初始聚类中心选取的方法可以提高聚类结果的稳定性方向出发,比如处理聚类中心点的可以引入“最大最小思想”到算法中,避免陷入局部最小。
2)在数据处理模型中聚类分析法具有较为广泛的应用场景,但在产生海量数据时存在计算速度较慢的问题。因此在当前大数据背景下,需要考虑对基于机器学习的异常数据检测算法进行改进优化,进而提高在异常数据检测中的优势。物联网监测所产生的海量实时数据,已经对传统异常数据检测方法带来了新的挑战。实时的异常检测开始成为一种趋势,对于工业生产安全、医疗技术发展、网络入侵、实现数据预测等领域实时的异常检测有着重要的意义,可以避免发生意外和减少经济损失。
参考文献:
[1] 孟海东,孙新军,宋宇辰.基于数据场的改进LOF算法[J].计算机工程与应用,2019,55(3):154-158.
[2] 蒋华,武尧,王鑫,等.改进K均值聚类的海洋数据异常检测算法研究[J].计算机科学,2019,46(7):211-216.
[3] 马速良,武亦文,李建林,等.聚类分析架构下基于遗传算法的电池异常数据检测方法[J/OL].电网技术:1-11[2022-12-06].DOI:10.13335/j.1000-3673.pst.2021.1871.
[4] 李科心,李静,邵佳炜,等.多层次序列集成的高维数值型异常检测[J].计算机与现代化,2020(6):73-82.
[5] 卢梦茹,周昌军,刘华文,等.基于二阶近邻的异常检测[J/OL].计算机系统应用:1-10[2022-12-06].DOI:10.15888/j.cnki.csa.008968.
[6] Breunig M M,Kriegel H P,Ng R T,et al.Lof[J].ACM SIGMOD Record,2000,29(2):93-104.
[7] Branch J W,Giannella C,Szymanski B,et al.In-network outlier detection in wireless sensor networks[J].Knowledge and Information Systems,2013,34(1):23-54.
[8] 祁超帅,何文思,焦毅,等.无人机飞行数据异常检测算法综述[J/OL].计算机应用,2022:1-11.(2022-11-28).https://kns.cnki.net/kcms/detail/51.1307.tp.20221125.0927.002.html.
[9] 丁卫东.基于聚类分析的异常数据检测[J].电子技术与软件工程,2020(15):185-186.
【通联编辑:唐一东】
猜你喜欢
商情(2016年39期)2016-11-21 08:45:54
新媒体研究(2016年19期)2016-11-18 19:48:34
大经贸(2016年9期)2016-11-16 16:16:46
哈尔滨理工大学学报(2016年4期)2016-11-10 22:48:52
中国市场(2016年33期)2016-10-18 12:16:58
科技视界(2016年20期)2016-09-29 12:32:48
电脑知识与技术(2016年16期)2016-07-22 19:21:00
电脑知识与技术(2016年6期)2016-06-06 23:11:23
企业导报(2016年9期)2016-05-26 21:08:14
电脑知识与技术(2016年7期)2016-05-19 13:38:03
