
主数据驱动视角下多源数据数字化挖掘系统设计
2022-02-17 12:11廖嘉炜严俊斌宋强赵小凡徐炫东
电子设计工程 2022年3期
廖嘉炜,严俊斌,宋强,赵小凡,徐炫东
(广东电网有限责任公司广州供电局,广东广州 510000)
信息技术革命以来,数据迎来了爆炸式的增长,企业档案属于企业生产经营管理活动中的符号,如何顺应时代潮流,更好地挖掘企业档案数据,对企业档案工作人员来说是一个重要挑战[1]。更好地挖掘企业档案数据,实现资源共享与流通,为企业未来制定多源信息资源规划提供必要的理论支撑。如今,企业数据等多源数据的数字化挖掘逐渐受到重视,其已经为许多领域的科学生产、管理、经营和决策给出了依据和帮助[2]。
利用统计方法挖掘出有用的统计规律等信息和知识,即统计方法挖掘知识。挖掘网络访问量的计算知识统计方法在网络访问中的应用性很强,鲁棒性却很低,容易出现挖掘数据遗漏、不全面、准确率低等问题,在此基础上,提出了主数据管理驱动下多源数据数字化挖掘方法,通过在传统数据数字化挖掘的基础上,结合主数据管理驱动,使得多源数据信息获取、储存、分配等过程的准确率以及运行效率都得到显著提高,具有很大的研究价值与实际应用意义。
1 主数据管理驱动挖掘原理
利用主数据驱动实现了多源数据的建模,并通过服务的方式向外部提供数据。作为该驱动的核心,具有实现异构数据转换、业务编排、业务路由、安全控制、业务监控等功能[3-5]。传统数据挖掘系统中的多源数据受驱动方向双向同步,而基于主数据驱动管理的业务系统通过ESB 使用或发布服务,由此适应不同协议、标准化和成品使用。
主数据管理驱动结构如图1 所示。
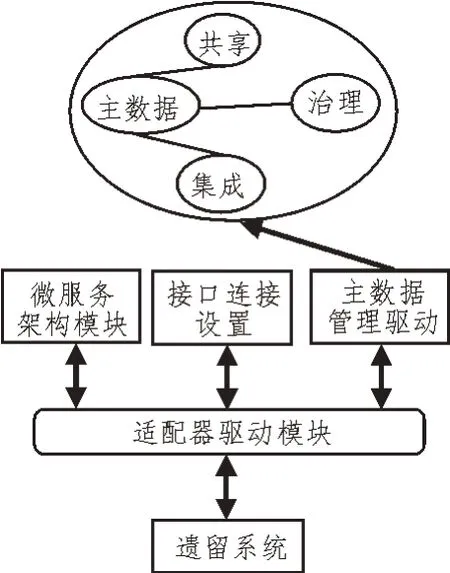
图1 主数据管理驱动结构
主数据驱动服务接口允许采用SOAP 协议制,以此完成数据信息传递与分批处理。主数据管理驱动中枢基于业务流程管理平台,可实现对主数据操作、治理、可视化展示[6-7]。
1.1 基于适配器驱动数据传递
主数据管理驱动中的适配器,能够改善现有数据的保存与管理问题,使数据分配处理,达到所有资源能够全部被使用的目的[8-10]。主数据驱动中主单片机是整个适配器的核心,在主单片机上主要使用嵌入式操作系统的软件业务程序,处理总线上下行数据挖掘。适配器驱动模块结构如图2 所示。
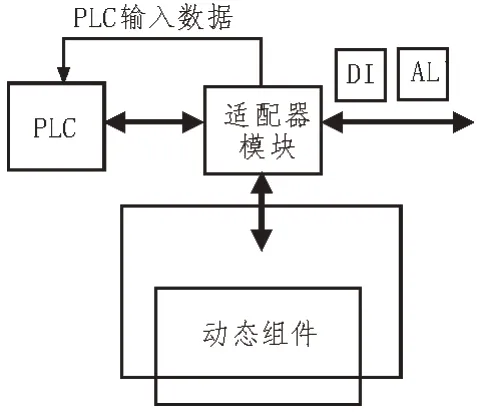
图2 适配器驱动模块结构
信息处理平台通过对收集到的原始信息进行组织加工、分类整理,然后将原始信息划分为相应多源系统的各种资源列表,然后分别分配给多源数据驱动相应数据库[11-13]。信息发布模块的任务主要是发布和查询各种信息,在信息发布过程中,信息传递能力主要表现为服务方式的多样化、服务功能的完备性、服务平台的易用性和技术的维护能力[14]。这是适配器驱动模块运行的关键环节,由此为多源数据提供数字化挖掘技术。
1.2 基于接口器支配与处理数据
接口连接功能模块是支撑核心功能模块和管理功能模块的基础。其能够保证在多源数据数字化挖掘过程中,主数据的管理驱动对于多源数据的支配与处理的有效性,即保证了数据数字化挖掘的来源合理性。其工作原理是终止UN1,支撑A/D 转换和信号转换,处理UN1 承载路径,完成UNI的测试和用户界面的维护、管理和控制。
接口器连接硬件介于使用者和硬件之间,设计彼此交互沟通的相关构件,目的是使用户能方便、高效地进行硬件操作以达到双向交互,完成相关工作任务。
2 多源数据数字化挖掘
2.1 基于克里格数据挖掘参数优化
克里格方法是一种基于变异函数理论和结构分析的空间局部估计方法[15-16],是一种在有限区域内对区域化变量的聚类,对集合无偏最优估计。此方法首先定义线性估计量:
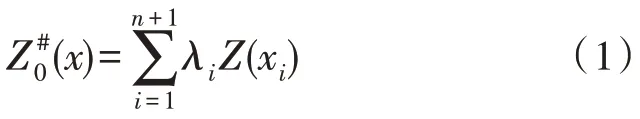
式(1)中,Z(xi)代表样本数据;代表待估计值;λi代表各个样点的权重,也叫做克里格系数;=1;针对任意一个估计值,实际值与估计值之间均存在一定的误差,本质上是Z0(x)的一种线性无偏最优估计;
借助克里格算法进行数据挖掘时,关键是克里格系数的确定,具体表示形式如下:
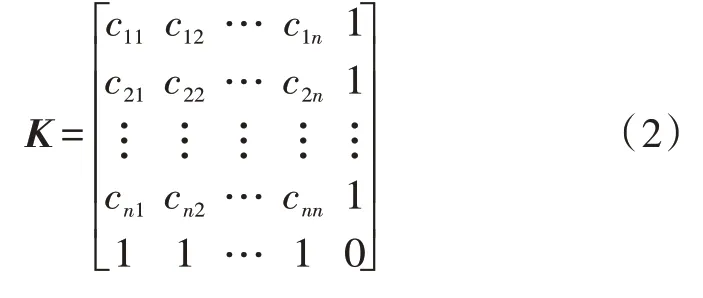
式(2)矩阵K中,cij代表原尺度s中样本i与样本j间的协方差。通过克里格数据挖掘算法能够得到数据挖掘的基本参数最优化估计值,使得数据挖掘的信息准确性得到保证,将数据最优化后,选取、分析数据的繁琐性降低,是多源数据数字化挖掘的基础。
2.2 数据挖掘流程设计
在保证挖掘参数优化条件下,结合挖掘对象问题空间和数据的独立性,通过数据预处理、数据选择、数据分析,判断数据挖掘任务,确定相关大数据估计研究方向。利用数据挖掘技术,可以从大型数据库或数据仓库中的相关数据集中提取知识信息,从而使大型数据库具有丰富、可靠的知识归纳功能。数据挖掘流程如图3 所示。

图3 数据挖掘流程
由图3 可知,先要有一个选择过程,然后从这个挖掘任务需要挖掘的源数据库中,根据服务用户的需要和要求,提取出一组数据来进行挖掘操作,这组数据是该挖掘任务中需要进行的一系列挖掘操作的对象,如图表中显示的目标数据;但在第一个步骤中,选择出的目标数据并不一定就非常适合进行挖掘操作,可能其中包含了一些噪声,数据应用的值有缺失或某些记录有重复出现等,这时就需要对这些“脏数据”进行一系列的预处理,如图4 所示。

图4 “脏数据”处理流程
由图4 可知,处理“脏数据”后,将这些数据作为安全数据进行挖掘操作,最后对前一个步骤中得到的安全数据按照挖掘任务所需格式转换,将数据原类型转换为方便操作处理的所需类型,由此完成多源数据数字化挖掘。
3 实 验
为每一个测试用户配置客户端PC,安装测试浏览器软件,采用IE 内核浏览器进行系统访问。在测试过程中,兼容性采用其他相关浏览器软件进行测试。将统计多源数据挖掘方法与主数据管理驱动下多源数据数字化挖掘方法的挖掘精准度对比分析。
在测试数据选择方面,同时采用真实业务数据和模拟数据的方式进行测试,保证所测试的数据能够满足各种情况下的业务处理要求,从而保证数据管理工作的相关功能能够适应各种业务处理。
3.1 实验参数
利用开放源代码的性能测试平台soapUI 进行测试分析,设置相关运行参数,通过soapUI 对系统HTTP 访问成功率、响应时间进行分析,并对测试参数进行如下配置:
1)设置200 个并发数;
2)测试时间设为8 小时。
安装soapUITools,在服务器端设备上运行并执行测试。
3.2 实验结果
在测试数据选择方面,同时采用真实业务数据和模拟数据的方式进行测试,保证所测试的数据能够满足各种情况下业务处理的要求。选择8 000 个实际多源数据,分别用统计挖掘方法与文中挖掘方法进行实验分析。
1)挖掘完整度
将文献[5]方法、文献[6]方法与文中挖掘方法的数据挖掘完整度进行对比分析,结果如表1 所示。
由表1 可知,使用文中方法在检测数据为4 000个时,与实际值相差最大为326 个。在检测数据为2 000 个时,与实际值相差最小为40 个,而其他方法与实际值差距较大,由此可知,主数据管理驱动挖掘方法数据挖掘完整度较高。
2)挖掘精准度
将文献[5]方法、文献[6]方法与文中挖掘方法的数据挖掘精准度进行对比分析,结果如图5 所示。
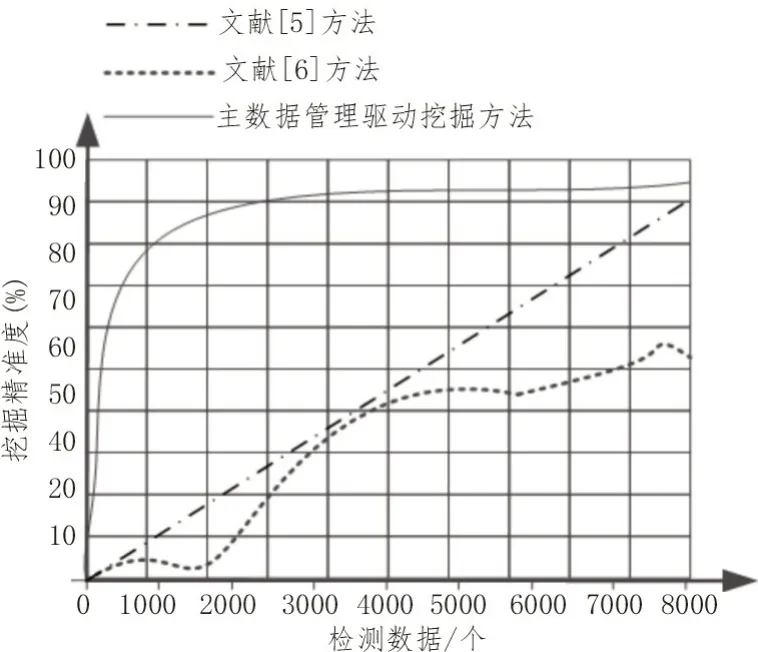
图5 两种方法数据挖掘精准度对比分析
由图5 可知,在检测数据为8 000 个时,使用主数据管理驱动挖掘方法达到最高挖掘精准度95%,而其他方法的挖掘精度一直低于文中方法,由此可知,主数据管理驱动挖掘方法数据挖掘精准度较高。
4 结束语
针对挖掘全面性不强、数据挖掘精准度低的问题,提出了主数据管理驱动下多源数据数字化挖掘方法,利用主数据管理驱动、克里格数据挖掘算法实现多源数据数字化挖掘。利用主数据驱动管理,使企业档案信息的获取、存储、分配等过程中的连接程度、准确性和操作效率显著提高,具有很大的研究价值和实际应用价值。
资源信息化建设一直是科学研究发展关注的重点,但单独针对多源数据数字化挖掘问题的研究却是在当今大数据背景下一次全新的挑战。在资源获取、信息集成整合以及数据应用创新方面制定的可行性措施也并不一定适用于所有的数据处理模式,因此,在今后研究进程中,多源数据的数字化挖掘研究过程需更加注重实用性、通用性的研究发展,以便适应当今社会的需求与发展。
猜你喜欢
汽车实用技术(2022年10期)2022-06-09
汽车实用技术(2022年5期)2022-04-02
海洋信息技术与应用(2021年2期)2021-11-02
铁道通信信号(2020年4期)2020-09-21
当代陕西(2020年24期)2020-02-01
安阳工学院学报(2018年6期)2018-11-28
科学与财富(2017年24期)2017-09-06
舰船科学技术(2017年5期)2017-06-19
电脑爱好者(2016年22期)2016-12-16
轻兵器(2015年20期)2015-09-10
