
智能运维平台协同过滤信息推荐系统设计
2022-02-17 12:11王丹丹梁志远崔晓萌
电子设计工程 2022年3期
张 耀,王丹丹,梁志远,崔晓萌
(1.国网天津市电力公司,天津 300010;2.天津三源电力信息技术股份有限公司,天津 300010)
随着政府和企业面向云端服务发展,混合云在政府和企业用户中越来越流行。在需求驱动下行业进一步发展和更替,出现了华为云Stack8.0平台[1]。随着网络普及,信息化服务不断升级,信息服务系统为用户提供越来越多的选择,然而其结构也变得更加复杂化[2]。用户往往在大量信息中检索出不符合实际需求的信息,无法顺利确定信息来源[3]。使用推荐系统能够依据用户在浏览器中搜索的记录对目标用户感兴趣信息进行推荐,保证用户能够快速找到所需信息[4]。现有的个性化推荐系统可分为两类:内容过滤推荐系统和数据挖掘技术推荐系统。其中基于内容过滤的推荐系统简单有效,可离线完成项目间的建模和相似度测量,推荐响应速度快[5],其缺点是难以区分信息属性,无法找到用户感兴趣的信息;基于数据挖掘技术的推荐系统服务器能够收集大量相关信息,存储用户访问系统所需的日志数据,其中包含丰富的用户和市场信息[6]。但是,协同过滤推荐需要用户明确输入对象的主观价值评分,使用起来极为不便,在用户评分数据相对较少的情况下,推荐质量难以得到保证。
为此,提出了智能运维平台协同过滤信息推荐系统。基于华为云Stack8.0 平台,基于智能化运营和自动化运营,利用机器学习技术,从历史数据中提取规则,生成相关分析方法,为运营提供实时数据分析能力,改进和完善现有运营方法。
1 系统硬件结构设计
提出的智能运维平台协同过滤信息推荐系统硬件结构如图l所示。
由图1 可知,系统硬件结构包括数据处理子系统、聚类子系统、关联规则子系统、推荐子系统[7]。由于用户访问网站时,信息大多以不同内存大小及属性存储到后台数据库中,无法满足数据精准筛选需求。为此,需要预处理用户信息。在用户聚类系统之中,利用混沌遗传算法根据预处理后的数据寻找相似用户集。通过推荐子系统可以判断用户所属类别,使用协同过滤技术能够为用户提供感兴趣信息[8]。该硬件结构中,只有协同过滤推荐子系统在线,而预处理、聚类、关联规则子系统均属于脱离主机、独立运行模式[9-10]。
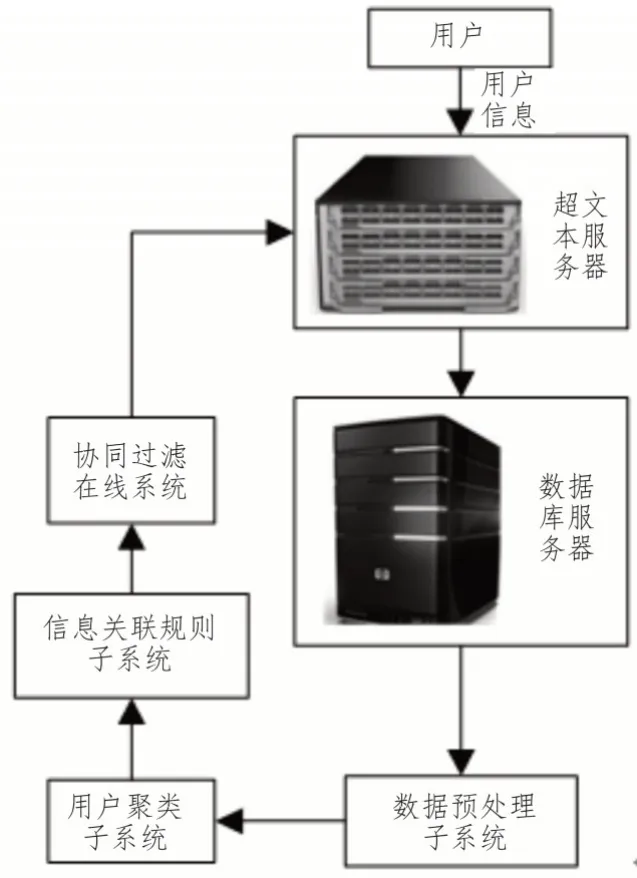
图1 推荐系统硬件结构
用户在访问网站时,信息需通过服务器传递到数据库中,预处理子系统定期从数据库中提取相关数据,并提交分类处理结果[11]。基于数据定期聚类算法,可在聚类子系统中保存聚类结果[12]。通过关联子系统,可快速挖掘关联数据,并依据当前用户信息,选择用户偏好数据,并将选择结果推荐给反馈服务器。
1.1 超文本服务器
超文本服务器属于网络文本服务器,通过超链接使不同版本信息均存储到同一空间中。
1.2 索引器
索引器的选择是搜索引擎中较为核心的问题,通过网络蜘蛛搜索网页中的链接,它从网站的一个页面开始,阅读该页面的内容,寻找其他链接,然后用这些链接找到下一个页面,不断重复,直到该站点的所有页面都被访问[13-14]。
利用词之间的共现信息自动生成词语,该词语在形式上是单词的组合[15]。所以,在同一上下文中,相邻词同时出现的次数越多,其形成一个词的可能性越大。词与词结合的频率和可能性更能反映出构词的可靠性,此方法将K组的索引与来自相同索引项的数据组合在一起,从而生成以索引项作为主键的倒排文件索引——倒排索引[16]。索引包括正向索引和反向索引,如图2 所示。

图2 由正向索引建立反向索引
如图2 所示,在分析页面之后,将得到一个以页码作为主键的前向索引表。利用反演方法产生k组的反演指标。这种方法把k组的索引和相同索引项的数据组合在一起,最后得到一个倒排文件索引。
1.3 数据库服务
一个或多个在局域网上运行的计算机和数据库管理系统组成一个数据库服务器,为客户提供诸如查询、更新、管理、索引、缓存和用户访问控制等服务,无需对数据进行重新分配。以服务器为基础的存储器非常重要,作为服务器主要存储器设备的硬盘技术含量高、制作精良,服务器硬盘已达10 000 转/分,普通SATA 硬盘非常接近这个速度。实际上一个小问题就可以导致服务器硬盘故障,所以一般的服务器租用都是用RAID 磁盘阵列存储,可以增加服务器硬盘故障容量。
1.4 华为云Stack8.0平台端信息查询电路
华为云Stack8.0 平台采用中央处理器,通过远程终端可向移动客户端发送查询结果。使用者可通过用户端扫描相关信息,并查询相关二维码,获得所需信息。
华为云Stack8.0 平台端信息查询电路设计如图3 所示。
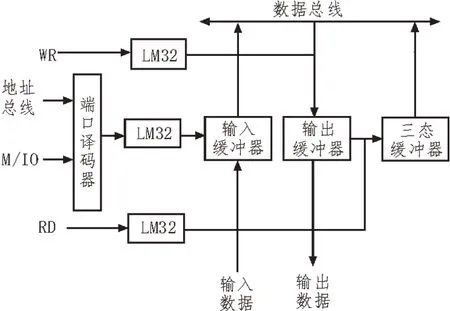
图3 华为云Stack8.0平台端信息查询电路
由图3 可知,以微RF007 型键断接收器芯片为核心,采用SOP (M)-8 封装模式,0 模式的芯片内部电路包括转换器、解调器和基准控制器。该控制系统包括两个外部电容、晶体振荡器和电源去耦电容。采用MicroRF007 芯片自带窄射频内调谐实现无线数据输入输出。Query I/O 模式也是条件传输模式。在中央处理机和外围输入输出接口中,除了数据端口外,还需要一个状态端口,用于查询输入输出信息。
2 系统软件部分设计
2.1 基于机器学习信息过滤
机器学习作为模式推理统计模型,在没有明确指令的情况下,能高效地完成特定的任务。由于缺乏明确的任务执行计划,机器学习算法建立在样本学习基础上,用于信息过滤。
基于机器学习的信息过滤流程如图4 所示。

图4 基于机器学习的信息过滤流程
由图4 可知,该信息中包含噪声信息,为此还需过滤噪声信息,具体步骤如下:
步骤1:读入机器学习数据和测试数据;
步骤2:对学习数据进行分词、去除停用词预处理;
步骤3:从步骤2 中获取处理后的数据,并提取词特征;
步骤4:从步骤2 中获取得到处理后的数据,并提取语义特征;
步骤5:串行融合步骤3和4,提取文本特征,并获取最终文本特征;
步骤6:将步骤5 中获取的文本特征传递给不同分类器,并获取分类模型;
步骤7:基于步骤6 中得到的模型,根据测试集参数调整模型,最终获取过滤噪声信息后的信息。
2.2 协同过滤信息推荐
用户所需信息是从云Stack8.0 平台中的信息端口获取的,除了基本云平台通信信息外,在智能运维平台中也能获取用户访问信息。将智能运维平台的访问信息作为关联规则挖掘输入信息,因此,提出了关联规则信息挖掘方法,获取用户所需信息。
设X和Y为推荐内容项目集,Z为关联规则集合,X和Y采用相同的基础关联规则,在用户访问X项目集时,用户也以最大概率访问Y项目集。基础内容关联规则是基于华为云Stack8.0 平台信息提取的,内容关联规则是信息推荐的基础,具有以下约束条件:
①信息种类实际计算中,若支持度大于阈值,则属于最高支持度项集,其计算公式为:

式(1)中,XZ、YZ分别表示信息种类实际表中的项目集合,n表示信息总数。
②每个项集F中,都存在非空子集F′,其置信度计算公式为:
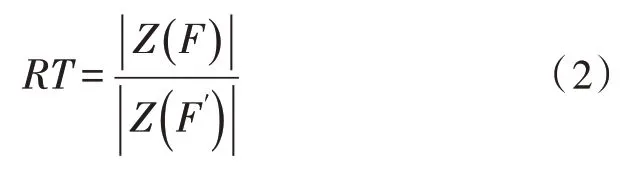
如果置信度大于用户指定的阈值置信度最小值,则生成关联规则。
信息推荐是依据上述规则实现的,通过展示渠道将推荐结果展示给用户。
3 实 验
3.1 实验环境设置
针对华为云Stack8.0 平台安全运行的实验条件,设置了复杂网络环境,网络拓扑结构如图5 所示。
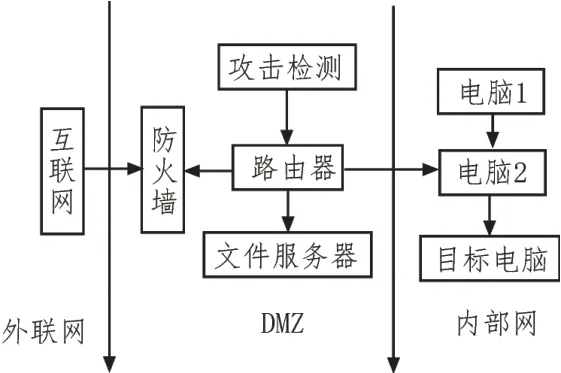
图5 网络拓扑结构
由图5 可知,要想盗取网络信息,黑客必须得到允许才能进行攻击。但是由于防火墙的限制,服务器只能通过主机不能通过内部网络进行访问。所以要获得主机访问资格,首先要获得内部访问权限,黑客只能进行一次攻击,没有多次同时攻击的现象。
3.2 实验结果与分析
在噪声信息干扰情况下,对比内容过滤推荐系统、数据挖掘推荐系统和智能运维平台协同过滤信息推荐系统的噪声干扰影响程度,如图6 所示。

图6 3种系统噪声干扰影响程度
由图6 可知,使用内容过滤的推荐系统受到影响,随着噪声变化,最终影响程度为35%;使用基于数据挖掘技术的推荐系统受到影响,随着噪声变化,最终影响程度为65%;使用智能运维平台协同过滤信息推荐系统受到影响程度较小,最终不受影响。
对比3 种系统推荐精准度,如图7 所示。
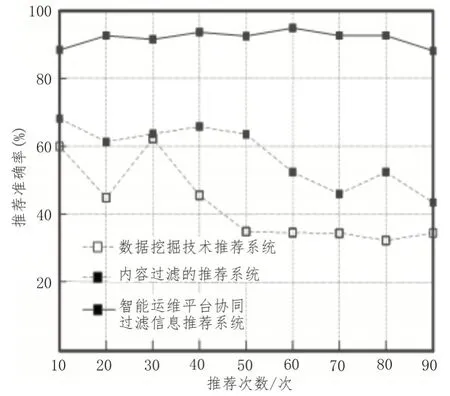
图7 3种系统推荐精准度对比分析
由图7 可知,使用内容过滤的推荐系统最高推荐精准度为68%,最低为42%;使用数据挖掘技术推荐系统最高推荐精准度为62%,最低为33%;使用智能运维平台协同过滤信息推荐系统最高推荐精准度为95%,最低为88%。由此可知,使用该系统推荐效果较高。
4 结束语
通过对文本信息过滤,为用户推荐感兴趣信息,设计了智能运维平台协同过滤信息推荐系统,经过实验验证,推荐精准度高。
虽然使用该系统具有精准推荐效果,但还存在一定问题。华为云Stack8.0 平台用户评论与推荐系统之间具有交互作用和相关性,充分考虑用户评论相关性,通过机器学习技术,改善传统运维模式,为平台提供实时运维能力。
猜你喜欢
舰船科学技术(2022年21期)2022-12-12
网络安全和信息化(2020年9期)2020-12-31
铁道通信信号(2020年3期)2020-09-21
网络安全和信息化(2020年7期)2020-08-07
铁道通信信号(2020年11期)2020-02-07
中国交通信息化(2019年5期)2019-08-30
网络安全和信息化(2019年8期)2019-08-28
能源(2018年8期)2018-09-21
山东工业技术(2016年15期)2016-12-01
网络空间安全(2016年3期)2016-06-15
