
针对基于随机森林的网络入侵检测模型的优化研究*
2022-02-16 08:34:00李洪赭李赛飞
计算机与数字工程 2022年1期
章 缙 李洪赭 李赛飞
(西南交通大学信息科学与技术学院 成都 611756)
1 引言
随着云计算、大数据等信息技术的发展和应用,各种服务器集群网络的规模都在变得越来越庞大和复杂,同时也面临着越来越多的网络安全威胁[1]。网络入侵检测是提高网络安全的有效手段之一,它根据网络流量数据或者主机数据来判断正常行为或者异常行为,可以抽象为分类行为,而机器学习在解决分类问题时具有强大的能力,因此很多研究尝试在入侵检测模型中使用机器学习算法[2]。
在各种基于机器学习模型的入侵检测方法中,基于随机森林模型的方法在训练时间、误报率、未知攻击的检测能力上都具有较好的效果[3],因此很多研究都使用随机森林或者随机森林与其他算法结合的模型来进行入侵检测判别。文献[4]提出了一种主成分分析算法与随机森林结合的入侵检测算法,首先使用主成分分析算法对数据特征进行降维,然后使用随机森林进行分类,在提高准确率上取得了较好效果。文献[5]使用TF-IDF 算法提取文本中有效载荷的特征,并使用随机森林算法进行分类来识别正常流量与攻击流量,对攻击流量的检测能力非常好。文献[6]使用One-R快速属性评价来解决遇到高维数据时随机森林模型在选择属性时过度随机导致的效率不高的问题,并在实验中取得了较好的时空性能以及较低的误报率和漏报率。文献[7]使用基于Snort的传统误用检测,结合基于随机森林的离群点异常检测方法,实现了一种混合入侵检测系统,能够达到高检测率和低误报率。文献[8]提出了使用KNN 删除离群数据后再结合多层次随机森林来检测网络攻击的方法,在KDD CUP99 数据集上能有效检测出Probe,U2R,R2L 等攻击。文献[9]通过利用随机森林进行误用检测、K 均值算法进行异常检测构建了一个混合入侵检测系统,具有较高的准确率和较低误报率。文献[10]通过引入随机性来降低网络流量特征字段噪声的影响,提高了随机森林模型的检测效果。上述研究大部分是通过结合随机森林与其他模型来提高入侵检测能力,也取得了较好的效果,但只有少数研究考虑了传统随机森林模型本身的一些不足。此外,对入侵检测场景下存在的数据集不平衡的问题的研究也较少。
针对传统随机森林用在入侵检测时存在的不足,本文提出了一种针对基于随机森林的入侵检测模型的优化方案,在随机森林的构造和决策过程中加入了精英选择、加权投票和上采样的方法来提高模型的效果。实验结果表明基于优化随机森林的检测模型相比基于传统随机森林的检测模型具有更好的检测能力。
2 决策树与随机森林
2.1 决策树
决策树是一种分类器模型,也是组成随机森林的基础。常见的决策树生成算法主要有ID3[11]、C4.5[12]、CART[13]等,其中ID3 算法是第一个具有影响力的决策树生成算法,后两种算法都是在其基础上进行优化或者借鉴了其思想。ID3 算法引入了信息论中的信息熵的概念,并定义了特征属性的信息增益。
假设一个总样本集合D 根据目标属性可以分成m个不同的类别,那么这个样本的信息熵为
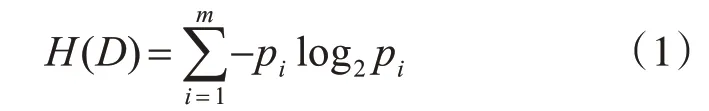
其中pi为第i种类型的子样本集合Di在总样本集合D中所占的比例,或Di出现的概率。
一个属性给总体带来的信息增益,就等同于总体的信息熵与选出属性后剩余信息熵的差值。假设要得到A 属性的信息增益,且A 属性有k 种不同的值,那么首先要根据属性A的值将总样本分为几个子样本(D1,D2,…,Dk),分别计算出每个子样本的熵,然后加权求和得到剩余信息熵
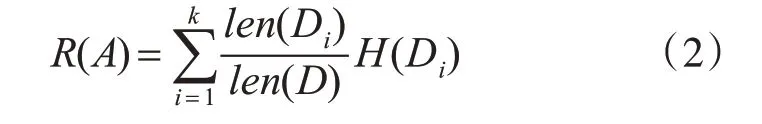
其中len()表示括号中的样本集的大小。根据总信息熵和剩余信息熵就可以得到A 属性的信息增益为
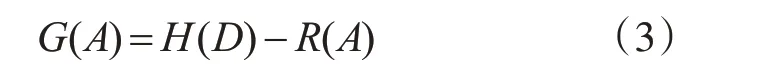
根据信息熵理论,当总样本中每种类型的子样本出现概率均相同,即对于任意i,都有pi=1/m 时,信息熵最大为log2m;而如果总样本某种类型的子样本出现概率远大于其他类型的子样本,那么信息熵越小,当只有一种类型的子样本时信息熵为最小值0。因此ID3算法的关键思想就是根据某种属性进行分类后可以让剩余信息熵最小,这样划分后的每个子样本的纯度就越高。ID3 算法每次挑选分裂使用的特征属性的时候,都需要计算出所有特征属性的信息增益,选择其中信息增益最大的特征属性,根据这个特征属性将样本分成几个子样本,之后重复这个过程,直到所有样本都属于同一类,或者绝大部分样本属于同一类为止。
2.2 随机森林
由于决策树在面对维度较高的样本时容易过拟合,因此实际应用中大多使用基于决策树的集成模型,其中随机森林就是一种由多个相互独立的决策树构成的分类器[14]。随机森林具有泛化能力强、训练速度快、能处理高维度的数据且不需要进行特征选择等优点,在很多分类问题中都得到了广泛应用。
随机森林的训练过程实际上就是构建若干个决策树,直到每个决策树都构建完毕,随机森林就训练完成。其中每个决策树的训练样本都是通过Bootstrap 方法从整个训练样本中采样得到,每个决策树用来进行分类用的特征属性都是从所有的特征属性中随机挑选得到,通常挑选的数量小于特征属性的总数。
随机森林在测试时,对于任意测试样本,每一个决策树均会对样本的类别进行独立判断,最终整个随机森林的分类结果由所有决策树的分类结果进行投票得到。假设对于某一个测试样本X,第k棵决策树的输出为

其中i表示某个类别的序号,则输出为i的决策树的序号的集合为
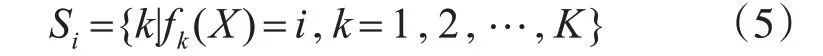
其中K 表示决策树的个数。于是整个随机森林的输出为

3 针对模型的优化方案
传统的随机森林模型用在入侵检测中时,由于本身的一些不足以及数据集的问题,导致性能不够好。首先,在传统的随机森林分类器中,会不挑选地直接生成K 个决策树,并且每个决策树进行投票时都具有相同的权重,这种方法构建的随机森林没有考虑到每个决策树的分类能力的差别,如果其中某些分类能力较差的决策树投出错误的票数,就可能影响整个随机森林的分类能力。其次,入侵检测环境中不同类别样本的数量存在严重的不平衡问题,某些攻击类型的样本数量非常小,这样训练出来的模型容易出现高误报和漏报的情况。因此,针对这两种问题,本文使用了精英选择、加权投票和上采样的方法来提高基于随机森林的入侵检测模型的判别能力。
3.1 精英选择和加权投票
针对随机森林中可能存在分类能力较差的决策树,以及这些决策树投出错误票数导致随机森林效果下降的问题,本文使用精英选择和加权投票方法来提高模型的效果。
在上文中提到随机森林中每个决策树的训练样本都是从总样本中进行Bootstrap采样得到的,剩余未被采样到的样本并没有使用到,因此这些剩余样本可以用来作为验证数据集,验证每个决策树的分类能力,并将测试分数作为这个决策树的权重:
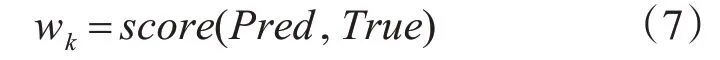
其中score 是决策树分类能力评价函数,Pred 是决策树在验证集上的分类结果,True是验证集的真实分类结果。根据这个权重就可以对决策树进行精英选择,以及对决策树的投票结果加权。
精英选择的过程是通过筛选出若干组候选决策树中表现较好的个体完成的。随机森林在构建的时候,每一轮生成个Nc个候选决策树,根据权重排序,然后选择其中的前Nadd个决策树作为精英决策树,将这些精英决策树加入到决策树集合中。其中Nadd的计算公式如下:

决策树集合中每次添加了新的精英决策树后,还要根据权重进行排序并将排名倒数Ndel个决策树淘汰。其中Ndel的计算公式如下:

经过多轮筛选后,随机森林中的决策树就基本都是具有较好的分类能力的个体。
加权投票的过程考虑到每个决策树所具有的分类能力的高低,不再认为每个决策树投出的票具有相同的影响力。当随机森林在进行最终分类判别投票时,每个决策树的票数不再是1,而是变为其权重,于是随机森林的输出由式(6)变为
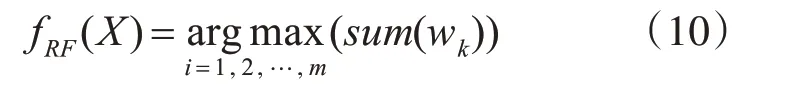
其中k∈Si,Si由式(5)得到。
3.2 针对非平衡数据集的优化
针对使用非平衡数据集训练决策树导致模型对可能具有高误报和漏报的问题,本文通过引入SMOTE[15]上采样算法来使得随机森林构建时的数据集平衡。
SMOTE 算法是一种基于插值的使用少数类合成新样本的上采样方法,其思想是通过在少数类的相邻样本之间插入新的样本来扩充少数类的数量。假设原数据集中某个少数类的样本数量为N,其中一个样本为Xi,首先需要从N 个少数类样本中找出Xi附近的k 个近邻Xi,j,j∈[1,k],并随机选择其中一个近邻Xi,r,然后得到一个新的样本:

其中r是一个0~1之间的随机数。重复上述过程多次后就能得到多个新的少数类样本,将新的少数类样本添加到原始数据集中构造出新的平衡的数据集,然后根据上文中随机森林的构建过程,使用该数据集替代原始数据集来训练随机森林。经过上采样后的数据集中每个类别的样本数量都是一样的,在一定程度上可以减小原始数据集中不平衡的问题带来的影响。
4 实验与分析
4.1 实验数据
本文使用的实验数据来源于UNSW-NB15 数据集[16],该数据集涵盖了正常流量报文数据和九种类型的攻击流量报文数据,各种类型数据的数量及比例如表1所示,从表中可以看出数据集确实存在类别不平衡的问题,出现最多的类别的数量比出现最少的类别的数量高了几个数量级。
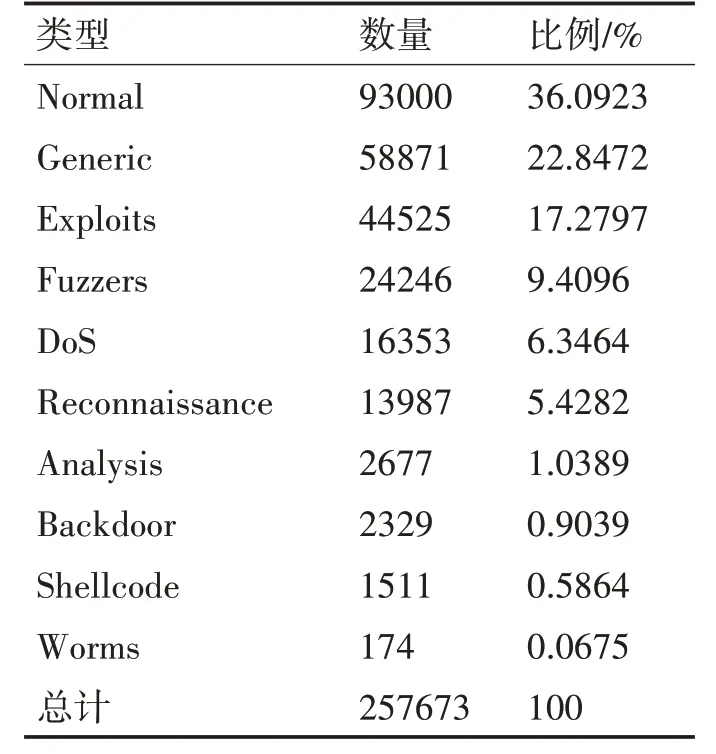
表1 数据集中各类型数据的数量及比例
4.2 模型评价指标
随机森林在入侵检测模型中通常作为一种分类器使用,对于分类器通常采用准确率Accuracy、精确率Precision、召回率Recall以及F1 这几个指标来评价模型的效果。设TP代表真实类型和预测类型都为正例的数量,TN 代表真实类型和预测类型都为反例的数量,FP 代表真实类型为反例但预测类型为正例的数量,FN 代表真实类型为正例但预测类型为反例的数量,则上述指标的计算公式如式(12)~式(15)所示。

由于模型的输出有多个类别,因此计算总体的Precision、Recall、F1 这几个指标时需要先分别计算出每种类型的数据的这几个指标,然后进行平均,平均的方法常见的有micro、macro、weighted 三种。本文使用weighted 方法,这是一种加权平均方法,其中每个类的权重为其数量在总数量中的占比。以精确度为例,整体的精确度计算公式为

其中ni表示第i 类数据的数量,Precisioni表示第i 类数据的精确度。
4.3 实验流程及结果
实验流程如图1 所示。原始数据集在被用来进行模型拟合前需要先经过一些预处理。首先,原始数据集中存在一些无效数据,这些无效数据通常是包含NaN、Infinite的样本,无法用来计算,因此需要先对数据进行过滤,把无效数据删除。其次,数据集中不同特征属性的数据具有不同的量纲,这样不同特征属性带来的信息增益无法进行比较,因此为了去除量纲带来的影响,需要对数据按照特征进行归一化处理,本文使用MinMax 归一化方法。最后,由于数据标签是字符串,无法参与计算,因此需要对标签进行编码,每一种标签都对应一个数字。预处理完成后将数据集划分为训练集和测试集。训练集用来对模型进行拟合,训练过程中需要使用网格搜索加上5 折交叉验证的方法来寻找最优超参数。模型训练完成后,使用测试集来评价模型的分类效果。
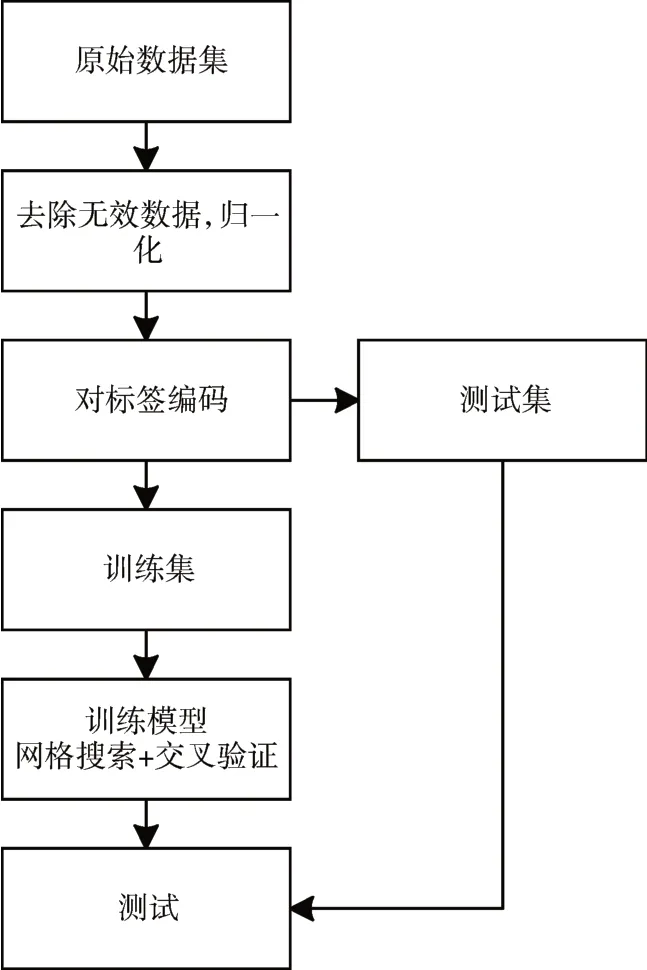
图1 实验流程
模型在训练集和交叉验证集上的学习曲线如图2 所示,由于F1 值是对模型精确率和召回率的综合体现,因此曲线中使用F1 值作为评价指标。为了方便表示,图中以及后文中均使用E 代表使用了精英选择优化,W 代表使用了加权投票优化,S代表使用了上采样优化,RF 代表随机森林。从图中可以看出,在训练集和交叉验证集上,本文引入的几种优化方法均能够提高随机森林的分类效果。不过模型仍然存在高方差的情况,可能需要更多的训练数据来减小方差。
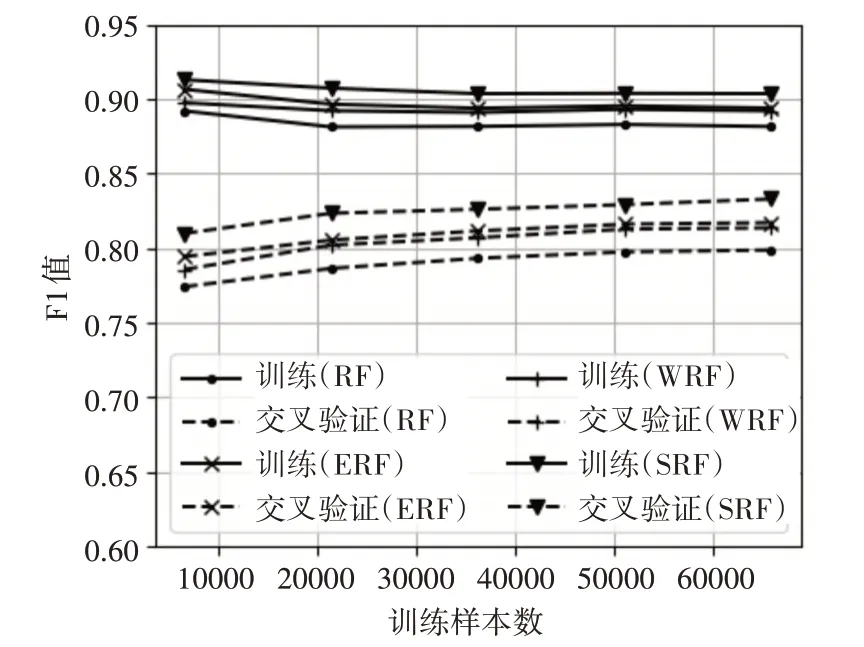
图2 模型学习曲线
由于在训练集和交叉验证集上表现较好的模型还可能存在过拟合问题,因此还需要使用测试集进行验证。验证结果如表2 所示。从验证结果可以看出,在测试集上三种优化方法也均能使得随机森林的准确率、精确率、召回率、F1 值有所提高,且随着优化方法的不断添加,某些指标的提升幅度会变小。但是由于加入了上采样和精英决策树筛选的过程,并且上采样后训练数据集规模扩增,模型的训练时间也相应变长。
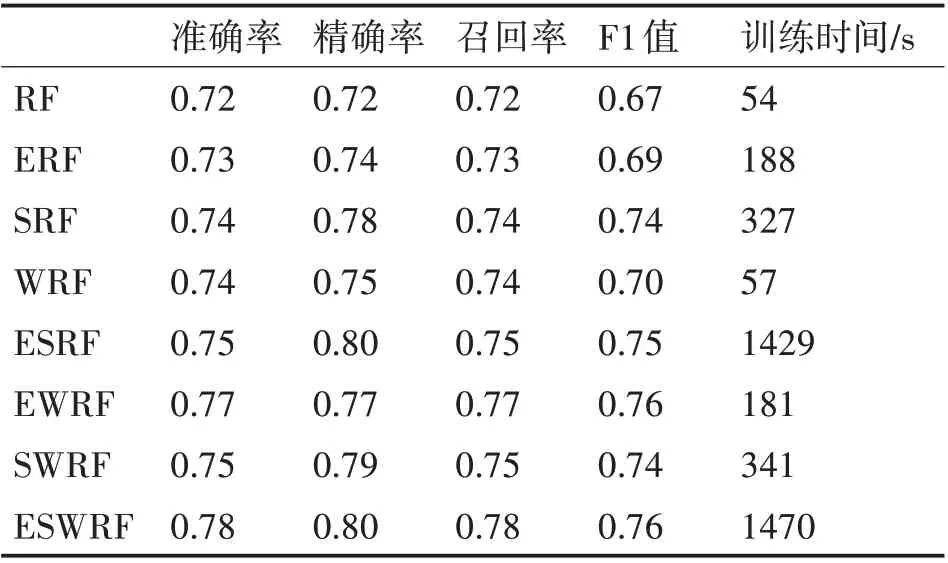
表2 测试集验证结果
5 结语
针对传统随机森林用在入侵检测场景下由于森林构建过程中的不足,以及数据集极度不平衡的问题,本文在随机森林的构建和决策过程中引入了精英选择、加权投票和上采样优化的方法。模型首先对原始不平衡数据集进行上采样产生新的平衡数据集,然后利用新的数据集构建精英决策树集合,最后使用加权投票的方法来决定随机森林的分类结果。实验结果表明基于优化的随机森林的入侵检测模型具有更好的检测效果。但是,由于加入了上采样以及精英筛选的过程,导致优化后的模型在训练时间上更长。下一步需要研究本文的优化方法用在其他集成学习模型上的可行性,以及训练时间优化的方法。
猜你喜欢
军民两用技术与产品(2022年1期)2022-06-01 06:28:50
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年16期)2018-09-26 03:27:06
电子测试(2017年12期)2017-12-18 06:35:48
雷达学报(2017年6期)2017-03-26 07:52:58
作文大王·笑话大王(2017年1期)2017-02-21 16:08:53
作文大王·笑话大王(2016年10期)2016-10-18 14:58:58
作文大王·笑话大王(2016年7期)2016-08-08 11:28:43
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
作文大王·笑话大王(2016年2期)2016-02-24 11:27:15
