
基于语料库的汉英商务二元词块翻译共性研究
2022-02-15 02:19:02李银花
运城学院学报 2022年6期
李 银 花
(运城学院 国际教育学院,山西 运城 044000)
一、引言
翻译共性(translation universals)假设是描写语言学中一个重要的研究领域。这一概念最初由Mona Baker[1]提出,她将其定义为“翻译文本而不是源语文本中出现的典型语言特征,这些特征不是特定语言系统干扰的结果”,即翻译文本中呈现出的相对于母语固有的规律性语言特征,通常包括简化(simplification)、明晰化(explicitation)和规范化(normalization)等。翻译语言这种变体的固有特征可以通过比较翻译文本与目的语母语文本进行发现、描写、挖掘,为翻译过程提供参考[2],亦为凝结翻译规则及深入“第三语码”[3]研究提供证据。
十几年来,利用语料库语言学方法实证翻译共性这一假设已经成为了重要的研究方向,并为描写翻译学带来了巨大生机[4]。其研究途径是比较翻译文本语料库和目标语母语语料库,并通过某些语言标志(linguistic indicator)试图提供实验性依据来验证Baker[1]提出的翻译共性假设及其他假设。许多学者都从不同角度对翻译共性进行了系统的阐述和检验(如Baker[1,5];Laviosa[6];Xiao[2])。Laviosa[6]以词频为语言标志,发现了翻译语言中实意词与功能词的比率较低,高频词重复率高以及常用词词形变化少等特点。Xiao[2]以词汇密度、连接词和被动结构等为语言标志,在很大程度上验证了Laviosa[6]的研究结果,并发现英译汉中汉语译文较母语汉语使用了更多的连接词和被动结构,为明晰化和规范化的假设提供了依据。
但是,大多数先前的翻译共性研究没有考虑到搭配也可能导致译文的明晰化、简化和规范化。自Firth[7]提出“由词之结伴可知其词”这一著名论断,并将搭配作为一个术语正式引入语言学研究已有五十多年。尽管如此,如Gries[8]所述,词汇搭配的研究迄今并没有走到尽头,在语言研究中仍具有较强的生命力。从这个意义上讲,词汇搭配研究不仅可以着眼于其界定方式、研究范畴、计量手段、方向性(directionality)等,而且还可以在更大维度(dimensionality)的数据中探讨搭配在语言输出中所起的作用。Feng et al.[9]对Ellis[10]和Wray[11]提出的母语(L1)搭配和二语(L2)搭配习得的差异性研究作了综述,并在Paradis[12]对隐性知识与显性知识区分的基础上,提出了翻译文本中搭配作用的理论模型。
该模型从形态和语义等角度显示了词汇搭配与翻译共性的辩证关系,并根据这个理论模型推导出了如下公式:

该公式表明在母语源语文本转化为非母语目标语文本的翻译过程中,合理使用目标语中的词汇搭配,有利于形成结构、意义完整的翻译单元(translation unit),从而降低翻译共性的约束,使译文更加贴近母语目标语的表达。反之,搭配使用不恰当则不利于形成有效的翻译单元,以至于将翻译共性带进译文,使译文读起来生搬硬套。此外,Feng et al.[9]强调搭配的使用受语域(register)制约,不同语域可能显现出不同词汇搭配分布模式。
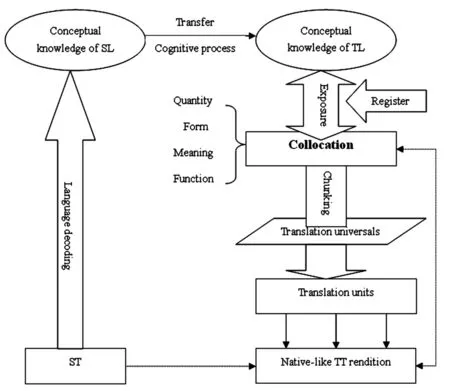
图1 翻译文本中词汇搭配作用[9]
二元词块(Bigram)这一术语源于N元语法(N-gram)模型,是自然语言处理研究领域中的一个重要概念。在N-gram模型中,第N个词出现的概率条件及语境意义取决于前面N-1个词所提供的词汇信息,对第N个词的出现及词性界定具有强大的约束作用。当N取值为2时,即为二元语法模型。换言之,二元词块也可以理解为两个词项之间的连续性搭配,其形态构成可以表示为s=w1w2,故文本中所有可能的二元组集合可以概括为如下公式:
公式2:S={s1,s2,s3,…sn}。
研究二元词块形态分布特征同样有可能找到翻译共性的实验性依据。因此,本文主要根据Feng et al.[9]提出的翻译文本中词汇搭配作用理论模型,采用基于语料库的研究方法,以二元词块为研究对象,以文体为控制变量,通过语际对比(Contrastive Interlanguage Analysis)对两个自建商务英语语料库(The Translational English Corpus of Commercial Translation from Chinese,汉英商务翻译英语语料库,以下简称TECCTC;The Native English Corpus of Commercial Discourse,母语商务英语语料库,以下简称NECCD)中二元词块的不同形式分布模式进行分析,并试图揭示出汉英商务翻译文本与母语商务英语文本相比,二元词块使用上搭配强度较弱,呈现出“简化”的趋势,从而发现搭配强度(collocability)与翻译共性假设中译文简化之间的关系。
二、研究设计
1. 二元词块搭配强度的界定
二元词块的形态研究以词项之间的线性共现为界定标准(参见Sinclair 1991),考查的是词项之间的组合(syntagmatic)关系[13],通常以“组合稳固性”作为不同搭配强度(collocability)二元词块的区分依据。因此,本研究以搭配强度为语言标志对比研究汉英商务翻译英语语料库和母语商务英语语料库之间二元词块形态分布的区别性特征,从而发现翻译文本中搭配行为的特点。
根据Sinclair[14]的研究框架,从搭配强度角度将二元词块分为自由组合(free combination)、粘着搭配(bound collocation)和成语(idiom),并逐一对其进行界定:
自由组合(free combination):其意义等于组成单词字面意义的机械相加,搭配强度最弱,允许组成单词最大限度地相互选择(例如check details、do things);
粘着搭配(bound collocation):其意义等于组成单词字面意义的机械相加,搭配强度较强,允许组成单词在有限的范围相互选择(例如promote growth、budget deficit);
成语(idiom):其意义不等于组成单词字面意义的机械相加,搭配强度最强,不允许组成单词相互选择(例如catch up、bull market)。
语料库中二元词块在语言标志中不同类别的比例显示出该语料库的搭配分布特征。从形态角度讲,如在译文中过多使用自由组合而较少使用粘着搭配或成语,则表明词汇搭配的习得及使用是以单个词为单位[11],区别于母语者“程式化”(formulaic)使用搭配的方式,可能会造成译文简化[9]。因此,翻译语言中所呈现出搭配分布的区别性特征就是造成翻译共性的重要因素。
2. 语料来源
目前已建成的商务英语语料库包括CANBEC(the Cambridge and Nottingham Spoken Business English Corpus),WCWBE(the Wolverhampton Corpus of Written Business English)以及BNC(the British National Corpus)的商务文本部分等。诸如此类的语料库(及子库)在一定程度上满足了学术研究的需要,为自然语言处理提供了大量真实语言数据。然而,就本研究而言,这些商务英语语料库存在三方面弊端:a.没有提供翻译语料;b.收集年限以及语料库规模有限;c.某些语料库不公开或为有偿使用。因此,本文采用两个自建商务英语语料库,即TECCTC和NECCD。汉英商务翻译英语语料库TECCTC作为目标语料库,其语料收集自2000年到2010年间在中国大陆地区发表的权威商务文件、期刊、条例、新闻等的英文译文。其出处为中国商务部、中国证监会、国家外汇管理局、中国日报、新华社等权威机构和媒体。母语商务英语语料库NECCD作为参照语料库,其语料收集自2000年到2010年间发表的商务英文文献、期刊、条例、新闻等,出处为美国商会、英国商会、纽约时报、路透社等权威机构和媒体,语料收集覆盖了英语的主要地理和国家变体。这两个语料库在长度、语料类型、语料收集期限、语料保密性等方面都具有较强可比性。所用语料为了研究需要均无赋码,两个语料库具体统计数据见表1:

表1 NECCD和TECCTC具体统计数据
3. 数据收集及语料分析
本研究采用Perl(5.16.3.1604版本)软件进行编程来提取语料库中的二元词块。Perl是基于文本且适合词块提取及处理的计算机语言,为语言研究人员提供了一个强大的、自由灵活的语言数据处理平台,在自然语言处理方面可满足不同研究的需要[15]。数据提取采用统计手段,即只提取显示出统计显著性的词对。因此,编程过程中将互信息(Mutual Information)和似然率(Log-likelihood)计算公式导入程序,只有同时满足互信息值≥3,似然率值≥3.84的二元词块才被程序提取并作为研究对象。此外,还设计了两个过滤方案,即形态过滤和语义过滤,去除了一些句法或者语义不完整的词对,如in a,yuan and,be dropping等。最终得到NECCD中二元词块形符(bigram token)数为101,932,二元词块类符(bigram type)数为6,363。TECCTC中搭配形符为111,447个,搭配类符为3,869个。
三、结果分析:汉英商务翻译中二元词块形态分布特征
本文根据搭配强度采用“由强至弱”的方法提取不同强度的搭配,即先找出搭配强度最大的成语,其次找出相对强度大的粘着搭配,最后剩下的即为自由组合。两个语料库中二元词块形态分布结果列于下表中:

表2 二元词块形态分布
表2显示,两个语料库中二元词块形态分布模式差异很大。从形符角度看,NECCD中的粘着搭配为74021个,占总搭配形符的72.62%;而TECCTC中的粘着搭配为56847,占51.01%。自由组合的使用情况则正好相反,NECCD为23497个,占23.05%;而TECCTC为51194,占45.94%。从类符角度看,两个语料库中搭配分布的区别则更加明显。NECCD中的粘着搭配为5196个,占总搭配类符的81.64%;而TECCTC仅为1,818,占46.98%。NECCD中的自由组合为992个,占15.6%;而TECCTC为1950,占50.39%。实验结果表明,相对母语商务英语文本中的搭配使用情况而言,汉英商务翻译文本中呈现出过多的自由组合,而粘着搭配和成语则表现为输出不足。为了加强比较结果的可靠性,分别对三组数据进行了卡方检验(自由度=1,信度95%),结果列于表3。

表3 TECCTC和NECCD中三类二元词块的卡方检验
表3显示,从形符角度看,所得卡方值分别为1.224e4、1.047e4和2.447e2,均大于临界值3.84(参见Manning & Schütze[16]);从类符角度看,卡方值分别为1.421e3、1.342e3和0.156,自由组合和粘着搭配所得值大于临界值。该结果表明汉英商务翻译与母语商务英语比较中,除了成语类符,其余类别均表现出显著性差异。但需要注意的是,成语类符在两个语料库中占比率较小(≤3%),基本不影响整体比较结果。此外,NECCD中出现的搭配类型总体上也少于TECCTC(3869-6363)。本研究借鉴了Biber et al.[17]计算语篇词汇密度时采用的语篇形符-类符比(type-token ratio,简称TTR)的公式TTR=100×形符/类符,并用此公式计算搭配密度:

根据公式3,分别计算了TECCTC和NECCD两个语料库中的搭配密度,发现汉英翻译文本中的比值为3.47,远低于母语英语文本中的比值6.25。加之,汉英商务翻译文本中的搭配输出较母语商务英语文本,呈现出过多使用自由组合、粘着搭配和成语则输出不足的趋势。综合以上结果,汉英商务翻译文本中的搭配输出过多依赖、重复使用了自由组合,即搭配使用仍是以单个词的形态与意义为驱动,在很大程度上没有将搭配视为形态与意义的统一体,因而没有像母语者一样以‘程式化序列’(formulaic sequence)的方式进行搭配输出。这一发现验证了Wray[11]的研究结论,第二语言使用者的搭配使用依赖于“组词成对”,而母语者的搭配使用则是“程式化序列的整体输出”。从翻译共性的角度来说,这也为译文趋简化的共性提供了依据。为了更加直观反映出两个语料库的对比结果,利用SPSS(SPSS 19.0版本)统计分析软件对三组搭配数据做了对应分析(correspondence analysis),其结果如下:

图2 两个语料库中二元词块搭配强度对应分析
图2清晰反映出二元词块类别与形符数目及类符数目在不同语料库之间的关系,即相关则近,非相关则远。TECCTC中二元词块输出无论是形符还是类符都非常接近自由组合;而NECCD中的词块输出则离自由组合较远,反而接近粘着搭配和成语。该结果再次验证了如上卡方检验的有效性。因此,依据Baker[1]提出的译文简化假设以及Feng et al.[9]提出的译文中词汇搭配作用理论模型,可以得出以下结论:与母语商务英语文本相比,汉英商务翻译文本中的搭配输出过多依赖、重复使用了自由组合,而粘着搭配及成语的使用尚显不足,因此使译文呈简化的趋势,进而使得汉英商务翻译文本中显现出翻译共性。
四、应用举例与讨论
统计结果表明导致简化原因之一,在于翻译文本中较低的二元词块形符-类符比。为了提供更多译文简化的依据,笔者又对两个语料库中高-低频词块比做了进一步调查。本研究借鉴了Laviosa[6]和Xiao[2]等研究中对高频词汇的界定,采用0.1%作为临界值来提取高频词块。其结果如下:

表4 NECCD和TECCTC高-低频词块比
表4显示出TECCTC中高频词块的数目远大于NECCD,因而其累计比例也远高于NECCD。统计高频词块重复率是考量词块类型的单一性程度,从其结果可以清楚看到,汉英商务翻译文本中重复使用的二元词块类型比率较母语商务英语文本高出28.45%。高-低频词块比例是考量词块类型多样性的程度,两个语料库之间的差异尤为显著,说明汉英商务翻译中二元词块输出不仅依靠某个类别的搭配,而且在很大程度上忽视了一些母语者在商务英语中常用的搭配。本研究考查了两个语料库中所有包含call一词的搭配来例证以上结果。
TECCTC中包含call一词的二元词块只有call auction这1个类符,共计8个频次,例句如下:
(1)…the actual opening price formed aftercall auctionwill be higher than [the]ex-rights price,and vice versa.
TECCTC中其余包含call的搭配都没有显示出统计显著性(例如call on和call for),因而没有列入研究对象。
与之相比,NECCD中含call一词的二元词块有12个类符,共计225个频次,包括call option、call centre、call conference、covered call、naked call、duty call、bull call、margin call等。在这些搭配中,call的意义有时只能通过搭配关系才能体现,例如bull call、call option、covered call、margin call等,例句如下:
(2)Using cash as acall optionin this case generated an extra 26%of return.
(3)...have recommended creating abull callspread position in Microsoft and writingcovered callson GameStop.
诸如此类的词块是构成粘着搭配和成语的重要组成部分,在母语商务英语中使用频率较高。显然,从此例可见汉英商务翻译中缺乏此类的搭配,换言之,没有达到母语的水平,因而导致在该研究中某些词块没有出现统计显著性,进而体现在词块类型单一化、简单化。这一发现不仅对翻译共性研究中的简化假设提供了支持性依据,而且暗示了导致译文简化的原因在于搭配的作用,即汉英商务翻译文本中英语词汇搭配的使用,注重词汇而忽视词块的形态、意义的整体性,并割裂了词块学习与语境的关系,导致词汇搭配往往是“拼凑”而成。这不仅降低了目标语文本中搭配使用的有效性,而且使译文中的搭配偏离母语规则,使目标文本带有一些偏离母语目标语的区别性特征。
五、结束语
翻译共性引起了国内外众多语言学和翻译学研究人员的密切关注,他们从多个角度加以论述来支持或反对这一假设,特别是近年来利用语料库语言学的研究方法在平均句长、被动结构等方面做出了很多有益的尝试。本文采用基于语料库的研究方法,从二元词块形态分布的角度,为支持翻译共性这一假设提供了实验性依据。通过对比汉英商务翻译语料库和母语商务英语语料库中的词块分布模式,得出如下结论:a.与母语商务英语相比,汉英商务翻译中过多使用了自由组合,造成粘着搭配或者成语的输出不足;b.词块形符-类符比值较低,造成搭配类型整体上单一化,使译文呈现简单化趋势;c.实验数据支持了Baker[1]的翻译共性假设,并在一定程度上验证了Feng et al.[9]提出的翻译文本中词汇搭配作用理论模型的有效性、可行性及准确度。
本文研究结果对汉英翻译、英语学习者语料,以及英语教学等多方面都具有一定的理论与实践意义。本文揭示出非母语英语使用者在词块使用上,仍然存在较大的问题,主要体现在使用词块靠“拼凑”单词,忽视词块的形式和意义等特征,在一定程度上没有合理地将词块用于合理的语境。这反映出汉英译者往往片面追求词汇量,而忽视词与词之间的搭配关系,并且割裂了词汇搭配与语境之间的关系。因此,对比分析翻译语言和母语中的词块使用情况,有助于二语英语使用者认识到搭配在翻译语言中的一些特征,并参照相应母语搭配分布模式尽可能规避翻译共性,使英语译文更加贴近其母语目标语表达。基于二元语法模型的研究还有利于教师改进词汇教学模式、注重词块输出和数据挖掘,从而更好地指导英语教学及翻译培训。
猜你喜欢
艺术启蒙(2023年2期)2023-11-03 17:07:38
杂文月刊(2019年14期)2019-08-03 09:07:20
中国工程科学(2017年3期)2017-09-05 09:40:54
广东教育·综合(2017年7期)2017-07-27 11:20:30
高中生·天天向上(2016年10期)2016-11-23 09:02:08
外语教学理论与实践(2016年1期)2016-06-11 05:51:46
疯狂英语(双语世界)(2016年4期)2016-06-05 08:37:16
疯狂英语(双语世界)(2016年4期)2016-06-05 08:37:16
中学生英语(2015年48期)2015-08-15 00:50:34
语言与翻译(2014年1期)2014-07-10 13:06:14
